







 本文介绍了Python爬虫的基础知识,包括使用requests库进行HTTP请求,lxml库进行数据筛选,以及如何保存爬取的数据。并通过实战代码展示了单页面爬取和多页面循环爬取的方法。
本文介绍了Python爬虫的基础知识,包括使用requests库进行HTTP请求,lxml库进行数据筛选,以及如何保存爬取的数据。并通过实战代码展示了单页面爬取和多页面循环爬取的方法。
python爬虫学习(二):基本的库和简单实战
1.请求信息:requests
-
requests.get(url,header=header)向服务器发送GET请求
-
requests.post(url,header=header)向服务器发送POST请求
-
示例代码get:
import requests url = "https://down.freembook.com/mixc/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0', } demo = requests.get(url,headers=headers) print(demo.status_code) print(demo.text) print(demo.content)
-
示例代码post:
import requests url = "https://down.freembook.com/mixc/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0', } params = { "_token": "P1o8Fz9ZOAuBojBsNGNfPa9vivr5PqRBUFwstL8I", "mobile": '15263819410', "password": "15263819410", "remember": "1" } demo = requests.post(url,data=params,headers=headers)说明:
-
header里面可以装浏览器型号,cookie等信息,伪装成浏览器是最简单的反爬虫方法
-
url是要爬取的地址
-
demo.text输出HTML源码,demo.content是输出二进制文件,保存的时候常用到
-
post多一个参数是data,里面携带参数发送给服务器,开发过网站的很容易理解
-
requests方法还可以设置session等,是一种登录机制
-
2.数据筛选lxml:
有很多的数据筛选库,我初学时用的时BeautifulSoup和re,现在觉得不好学,最好理解和好用的我认为是lxml库
-
安装
pip install lxml -
lxml使用的是XPath语法
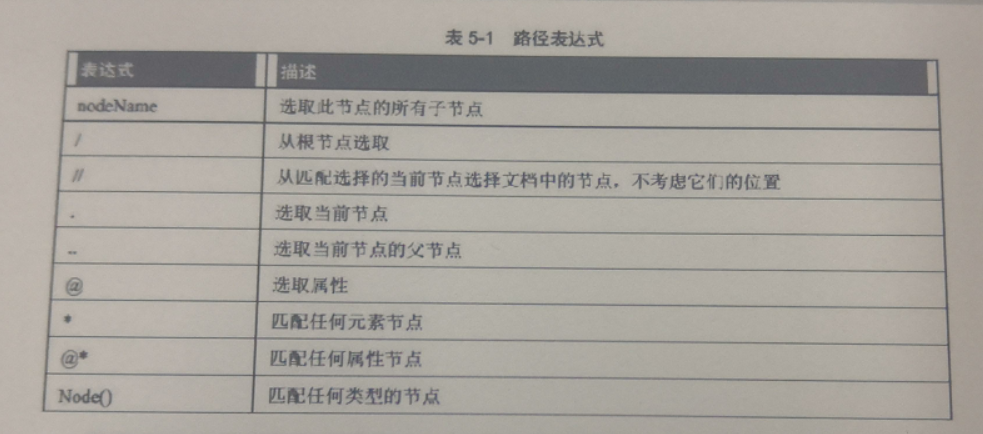

-
示例代码:
import requests from lxml import etree demo = requests.get(url,headers=headers) demo_address = etree.HTML(demo.text).xpath('//a/@href')#获取所有a标签下的href地址
会了这两个库就可以写简单的爬虫了,但是要理解dom树,还有python数据类型。
3.保存数据
-
主要以二进制文件的形式保存,高级一写的是保存在数据库里
-
示例代码:
demo4 = requests.get(new_url_3, headers=headers) f = open('D:\\' + str(j) + '.mobi', 'wb') # 将下载到的图片数据写入文件 f.write(demo4.content) f.close()
4.实战代码:
-
单页面爬取并保存:
import requests from lxml import etree def getspider(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0' } response = requests.get(url, headers=headers,) listpassages=[] if response.status_code == 200: print("网页抓取成功") response.encoding="utf-8"#观察网页编码方式进行编码 response=response.text element = etree.HTML(response) passages = element.xpath(".//dd[@id='contents']//text()") for passage in passages: listpassages.append(passage) return listpassages def save_text(texts): f=open("F:\Python Document\story_1.txt","w",encoding="utf-8") for text in texts: f.write(text) f.close() def main(): url="https://www.23us.so/files/article/html/32/32983/15413313.html" listpassages=getspider(url) save_text(listpassages) # print(len(listpassages)) # print(listpassages[]) # for passage in listpassages: # print(passage) main()这是某小说网站一个单页面,是很早以前对爬虫有点门道时候写的
-
利用for循环爬取大量数据:
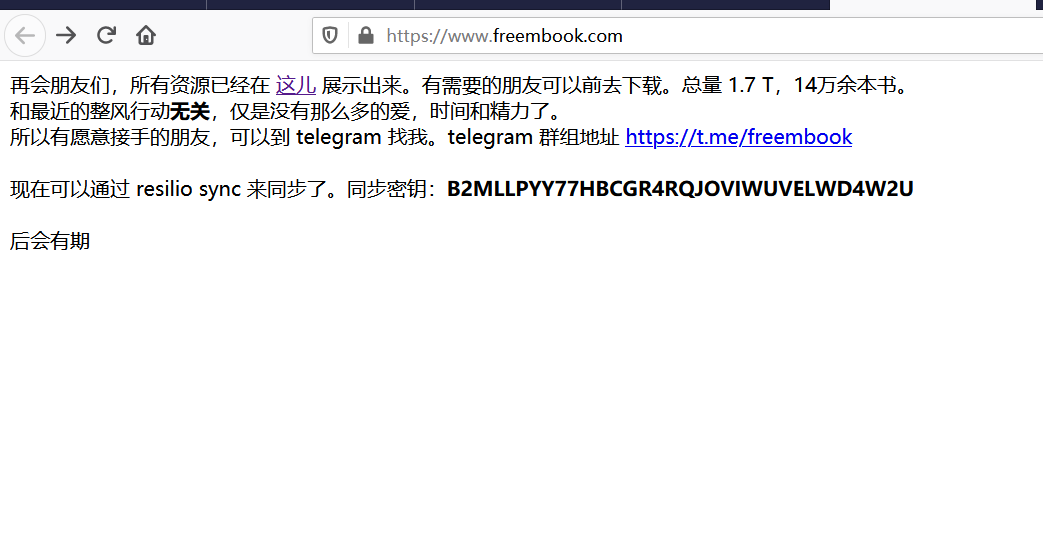
import requests from lxml import etree url = "https://down.freembook.com/mixc/" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:71.0) Gecko/20100101 Firefox/71.0', } demo = requests.get(url,headers=headers) demo_address = etree.HTML(demo.text).xpath('//a/@href') j=0 print("开始") for mydemo_address in demo_address[1:]:#58完成 new_url_1 = url + mydemo_address demo2 = requests.get(new_url_1) demo2_address = etree.HTML(demo2.text).xpath('//a/@href') new_url_2 = new_url_1 + demo2_address[1] demo3 = requests.get(new_url_2, headers=headers) demo3_address = etree.HTML(demo3.text).xpath('//a/@href') new_url_3 = new_url_2 + demo3_address[3] demo4 = requests.get(new_url_3, headers=headers) f = open('D:\\' + str(j) + '.mobi', 'wb') # 将下载到的图片数据写入文件 f.write(demo4.content) f.close() print("第" + str(j) + "本下载完成") j = j+1这是写这篇博客的前几天写了,爬虫兴趣来了顺便整理了一下自己的爬虫笔记。此时一些免费电子书网站处在风口浪尖,有很多的都关闭了,我在到处找kindle电子书,发现了这个网站,就顺便重拾我的爬虫来爬一波,站长人太好了!
我把这个代码搞到了服务器上面运行
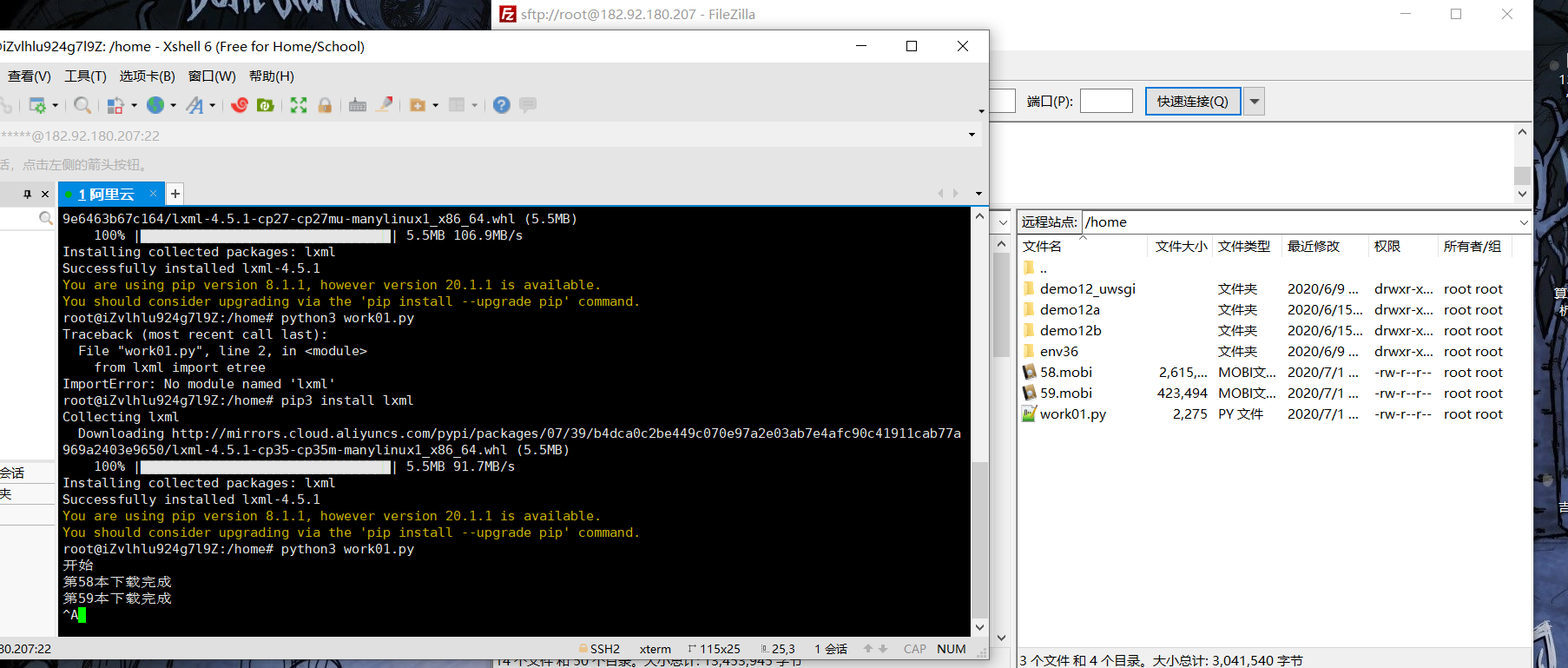
下载了九百多本就没有下载了,很有些慢,要用到多线程。在现在看来,可以不用去学threading库,直接用爬虫框架Scrapy,上面集成了很多库。
5.总结与感悟:
- 自己第一开始学爬虫的时候很懵,在脑海里没有url要是字符串,是传进来的参数,还有爬取到的数据是个列表,然后要用for循环遍历。自己得到最多的结果是一个空列表,然而自己还不知道怎么搞,感觉那个时候好傻。
- 最后学学放放逐渐有了概念,也会解决一定的问题,那是自己学爬虫的目标是爬取快手视频,然后自己在这个上面耗了很长的时间,因为那是我觉得没什么好爬的数据,最后爬不成功就放弃了。
- 为了这个自己看了模拟登录,通过验证码等反扒机制,看到多线程多进程都没用上,前两个的反扒需要有一定的经验和基础,当时的我只是学学没有成功,而且当时想要一簇就成。摸索点门道出来就像直接搞,结果是入坑了,坑了好长时间什么都不想搞。
- 然后再放放看看贴子,终于有种方法了,fiddler抓包工具,贴别坑的是网上那种前篇一律的那个教程,我最后找到了一个博主写的教程,也是fiddler,我学习最后成功了,但是一次只能爬取二十条视频,然后又要粘贴复制,还是没有达到自己的预期效果。
- 然后就是终极方案了,可见皆可爬的selenium,当时自己已经很有些基础了,会用这个库自动输入提取码来获取百度网盘资源。这次想着一点一点来,其趋势也还好,我成功的可以点击自己的主页,点击进入主播主页然后点击视频,也可以获取视频播放页面的源码。但是,但是就偏偏没有视频链接地址,那个浏览器上面可看到的.mp4文件地址却再爬取的源码上面没有。
- 现在觉得估计是请求的数据,数据没有渲染到dom树上就我就爬完了。当时遇到selenium安装问题,打开的页面没有登录信息等问题等,很多问题,再解决这些问题和学习过程中自己的能力有不少的提升。
- 自己还学了scrapy框架的,以为这个很厉害的爬虫框架可以解决自己的问题。但是爬虫主要的是分析网页源码,然后再是写代码,用都没有用就没搞了,现在要充型学一波了。
- 估计是有些执着,实在没办法了,自己再大一的暑假手动下载,有事没事就检查元素,复制,粘贴,下载,下载了有四万多个视频,六十多G还是一百二十多G,现在保存再自己的网盘,真的累死了非常浪费时间,坚持了一个月多一点。然而不是什么都没学到,我学了一波python的图形化界面库thinkter,写了个下载的小程序,输入网址就可以开始下载,好了就可以清空。当时还以为thinkter是个第三方库,怎么也搞不到,还准备不用这个库的。
- 现在是大二暑假了,寒假和暑假对接上来了,还是很怀恋去年那个时候,但是自己也把电脑搞成了ubuntu系统,说不完游戏,结果一搜linux上面有什么游戏,下载了个像帝国时代那样及时战略的游戏,玩得爽歪歪。真是笑了,后来换成win10后还想网那个游戏,却找不到了,下载的帝国时代不是那个画质,不一样就没玩了,感觉还真很很怀恋,也真香。
- 自己按照自己的python路线学习,然后就是网站后端开发django,遇到了不少问题,后来知道了前后端分离,又学了波Vue,然后与服务器部署,自己有了自己的网站“星星的博客小屋”,也终于有点拿得出手的东西,自己学着学那却没有学出什么名堂,成绩又是摸爬滚打,挣扎再及格线那里的那种。
- 自己之前还想着用爬取的视频用来练手做个视频网站,然后还有安卓软件,现在知道了那些视频服务器根本放不下,也体验了什么是1Mb/s的带宽,个人网站也越做越不知道它的意义了,不知道自己要不要继续部署再服务器上,毕竟还是再耗钱的,而自己只是对别人说“我有自己的个人网站,用vue+django前后端分离建的”
- 不想再搞网站了,然后准备这个暑假学学硬件51单片机等,前天投了一下图像算法工程师的简历,结果是没有面试机会,虽然会python但是没有相关的知识和经历,推荐我python后端之类的实习,而且建议我重点学习一个方向。
- 确实应该重点学习一个方向,但是我觉得那样很没有乐趣,而且深入学习不是网上找点免费教程就可以学好的。所以这个暑假TensorFlow和51单片机一起学,我吉他甩了一下把那个便宜的变调摔坏了,然后自己破费买了个好的变调夹,想好好学学吉他。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









