 正则表达式详解
正则表达式详解








 本文深入探讨了正则表达式的概念及其在计算机科学中的应用,详细解析了各种符号的含义和使用场景,如、[abc]、d等,并通过实例展示了如何使用正则表达式进行字符串操作。
本文深入探讨了正则表达式的概念及其在计算机科学中的应用,详细解析了各种符号的含义和使用场景,如、[abc]、d等,并通过实例展示了如何使用正则表达式进行字符串操作。
正则表达式
正则表达式,又称为正规表示法、常规表示法计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。在很多文本编译器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
正则表达式用于操作字符串数据
正则表达式实现qq格式校验
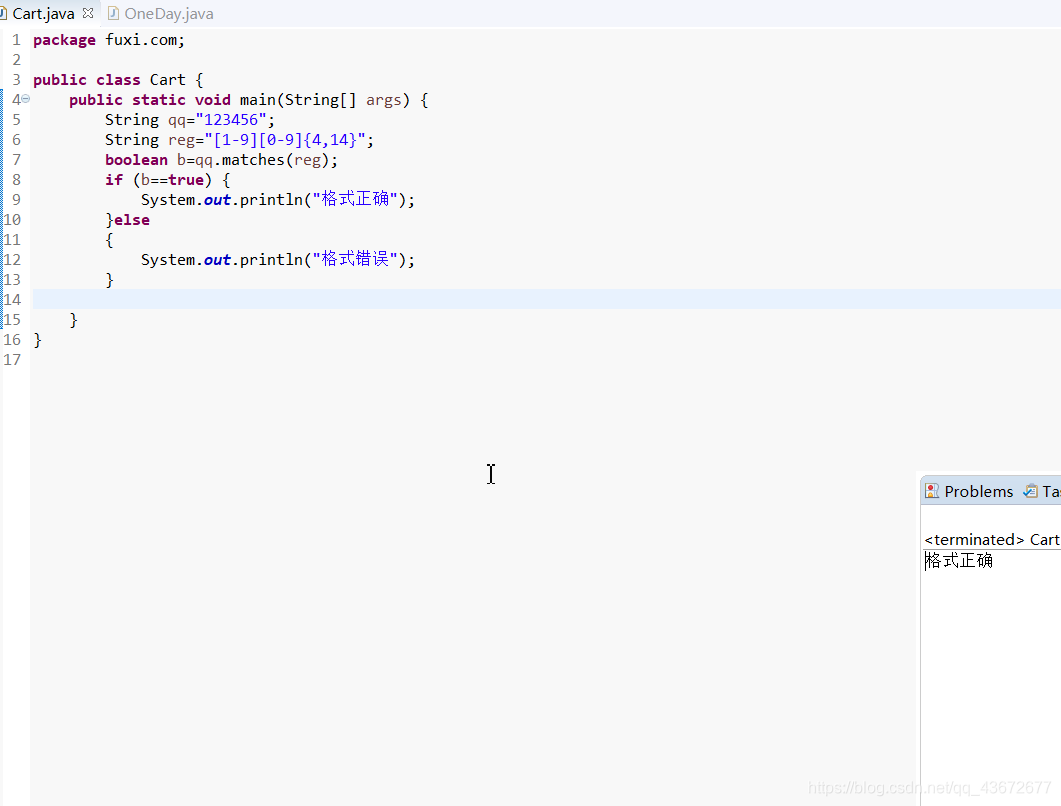
符号
- \匹配反斜线字符
- \r匹配回车符
- \t匹配制表符
- \f匹配换页符
- \n匹配换行符
- [abc]匹配abc中的一个
- [^abc]匹配除了abc中的一个
- [a-z]匹配指定范围内的任意一个字符,例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符
- [A-Z]匹配指定范围内的任意一个字符,例如,“[A-Z]”可以匹配“A”到“Z”范围内的任意大写字母字符
- [a-d[m-p]]匹配[a-d m-p]并集 //abcd mnop中的一个
- [a-z&&[^bc]]匹配[ad-z]范围内的任意字符 //但不能取bc
- [a-z&&1]匹配[a-l q-z]范围内任意字符 //取a-z中的任意但不取mnop
- [a-z&&[def]]匹配def交集中的任意字符
- . 匹配除\r\n之外的任何单个字符
- \d 匹配一个数字字符。等价于[0-9]
- \D匹配一个非数字字符。等价于[^0-9]
- \s匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]
- \S匹配任何可见字符。等价于[^\f\n\r\t\v]
- \w 匹配单词字符:等价于[a-zA-Z_0-9]
- \W匹配任何非单词字符。等价于[^A-Za-z0-9_]
- ^ 匹配输入字符串的开始位置
- $ 匹配输入字符串的结束位置
- \b匹配一个单词边界,也就是指单词和空格间的位置
- \B匹配费单词边界
- ? 匹配一次或一次都没有
- *匹配0次或多次
- +匹配1次或多次
- {n}匹配恰好n次
- {n,}至少匹配n次
- {n,m}匹配至少n次,但不能超过m次
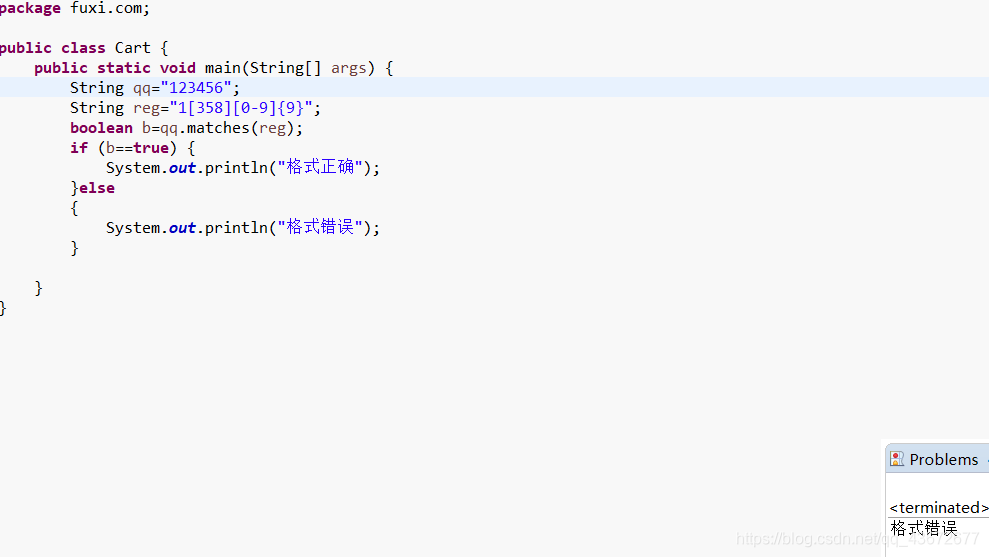
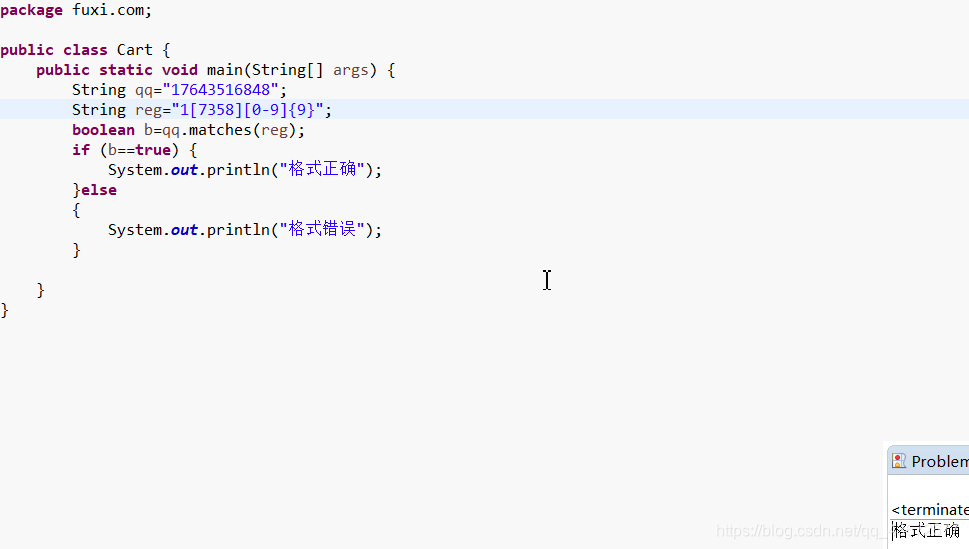
匹配手机号是否正确
切割字符串使用String类中的split方法
String str1=“wang_yu_hang”;
String str2="zhao fei ";
String str3=“tang.chun.lai”;
String [ ] strarr1=str1.split("_");
String [ ] strarr2=str2.split(" +");
String [ ] strarr3=str3.split("\\.");
for(String str:strarr1){
System.out.println(str);
}
System.out.println("----------------------------------");
for (String str : strarr2) {
System.out.println(str);
}
System.out.println("----------------------------------");
for (String str : strarr3) {
System.out.println(str);
按需求截取去掉3个或三个以上的重复字符
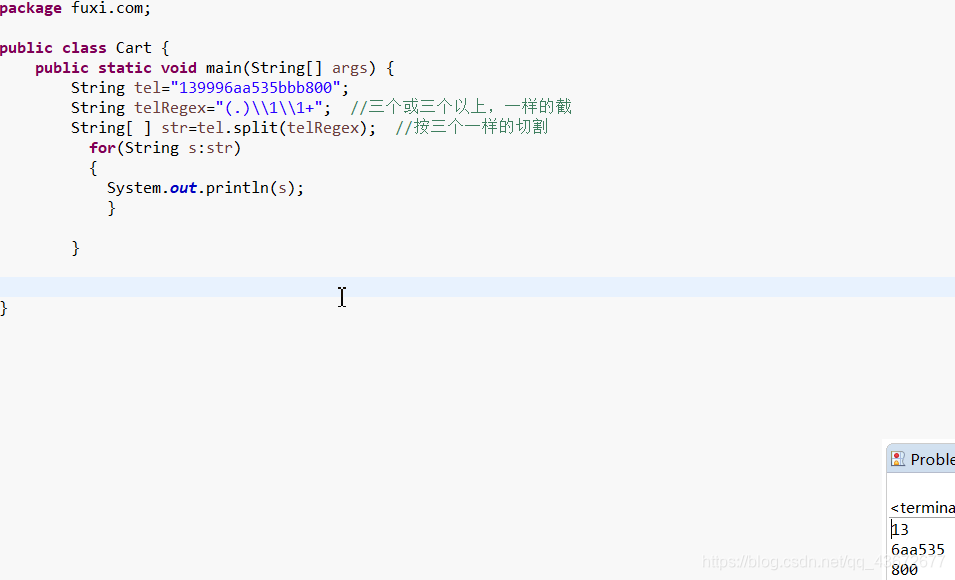
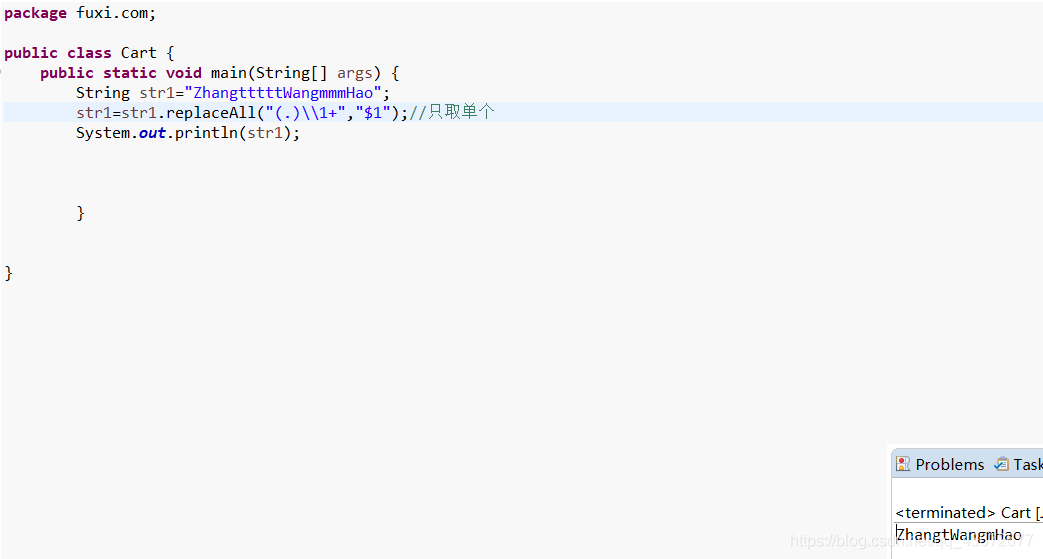
替换字符串
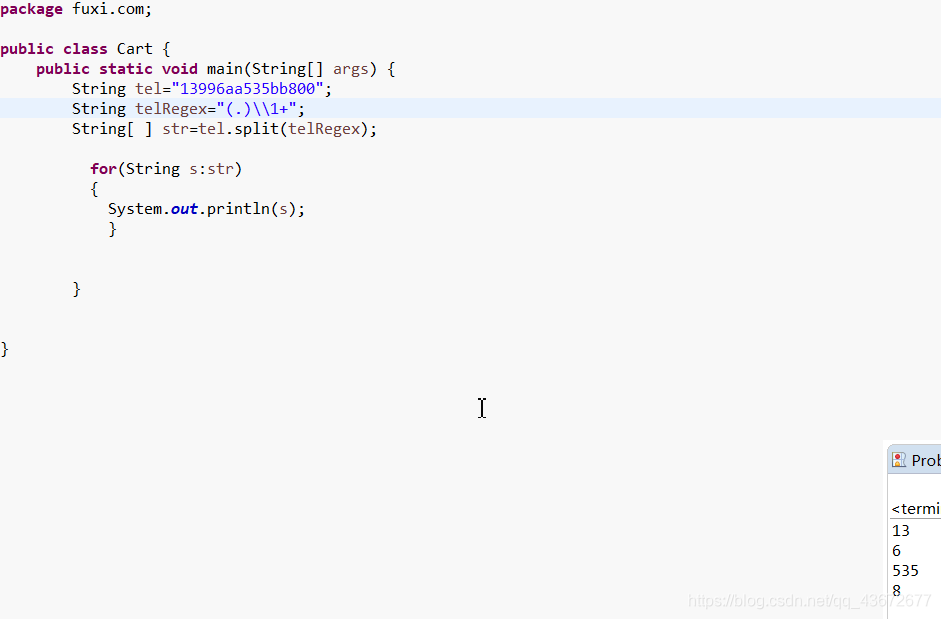
只取单个
获取
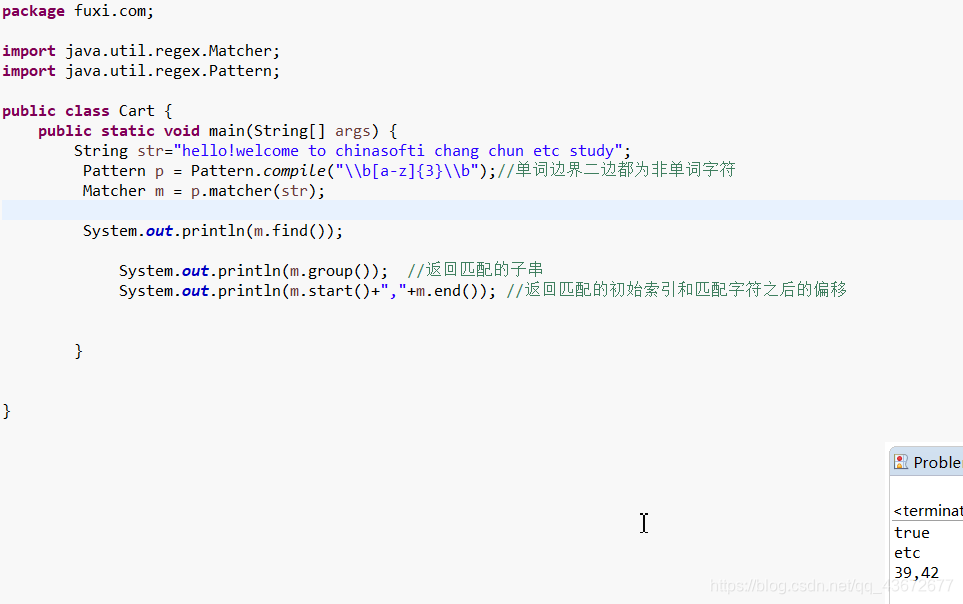
其实使用的是java.util.regex.pattern类
java.util.regex.Matcher类
Matcher类中的常用方法
public boolean find()尝试查找与该模式匹配的输入序列的下一个子序列
public String group()返回由以前匹配操作所匹配的输入子序列。
public int start()返回以前匹配的初始索引。
public int end() 返回最后匹配的字符之后的偏移量。
find()方法是部分匹配,是查找输入串中与模式匹配的子串,如果该匹配的串有组还可以使用group()函数。
matches()是全部匹配,是将整个输入串与模式匹配,如果要验证一个输入的数据是否为数字类型或其他类型,一般要用matches()。
m-p ↩︎

















 3110
3110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









