







一、知识蒸馏核心理论:让巨人哺育新生
1.1 知识蒸馏的本质
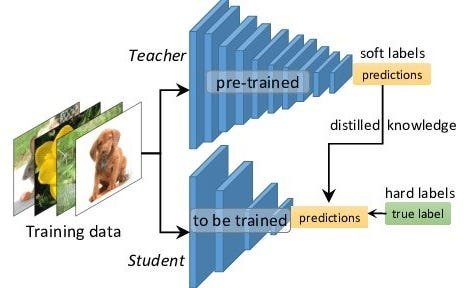
知识蒸馏(Knowledge Distillation, KD)是一种模型压缩技术,通过训练小型学生模型(Student)来模仿大型教师模型(Teacher)的行为。其核心思想可概括为:
其中:
教师软化输出
1.2 知识的三阶表现形式
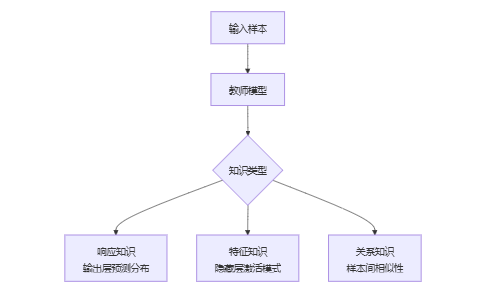
数学表示:
- 响应知识:
- 特征知识:
- 关系知识:
二、Transformer蒸馏技术路线演进
2.1 蒸馏架构全景
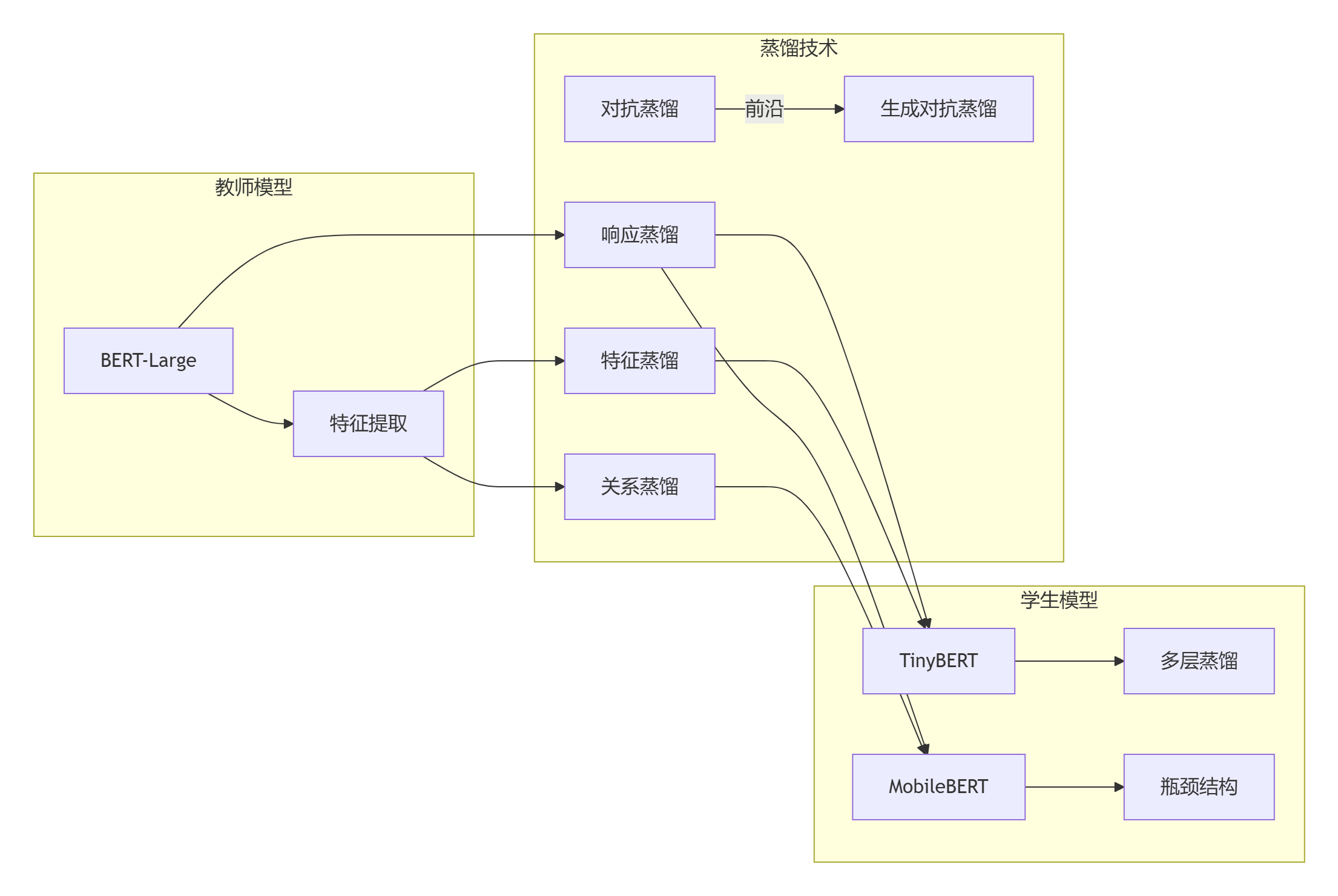
三、TinyBERT:四维蒸馏的艺术
3.1 创新性的蒸馏框架
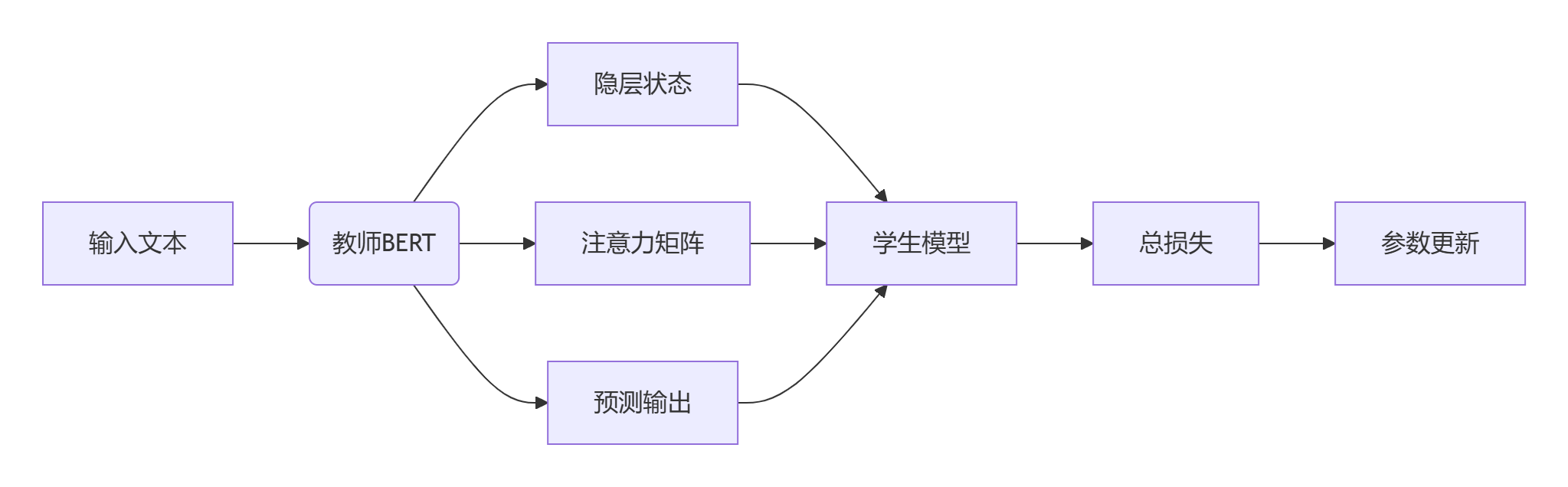
3.2 数学实现细节
特征蒸馏损失:
其中:
注意力蒸馏损失:
整体损失函数:
3.3 PyTorch实现核心
class TinyBERTDistillLoss(nn.Module):
def __init__(self, alpha=0.5, temp=5.0, feat_weights=None):
super().__init__()
self.alpha = alpha
self.temp = temp
self.feat_weights = feat_weights or [1.0] * 12
def forward(self, student_outputs, teacher_outputs, labels):
# 响应蒸馏
s_logits, s_features = student_outputs
t_logits, t_features = teacher_outputs
soft_loss = F.kl_div(
F.log_softmax(s_logits / self.temp, dim=-1),
F.softmax(t_logits / self.temp, dim=-1),
reduction='batchmean'
) * (self.temp ** 2)
# 特征蒸馏
feat_loss = 0
for i, (s_feat, t_feat) in enumerate(zip(s_features, t_features)):
# 可学习适配器
adapter = nn.Linear(s_feat.size(-1), t_feat.size(-1)).to(s_feat.device)
feat_loss += self.feat_weights[i] * F.mse_loss(adapter(s_feat), t_feat)
# 真实标签损失
hard_loss = F.cross_entropy(s_logits, labels)
return self.alpha * hard_loss + (1 - self.alpha) * (soft_loss + feat_loss)
四、MobileBERT:瓶颈结构的革命
4.1 架构创新设计
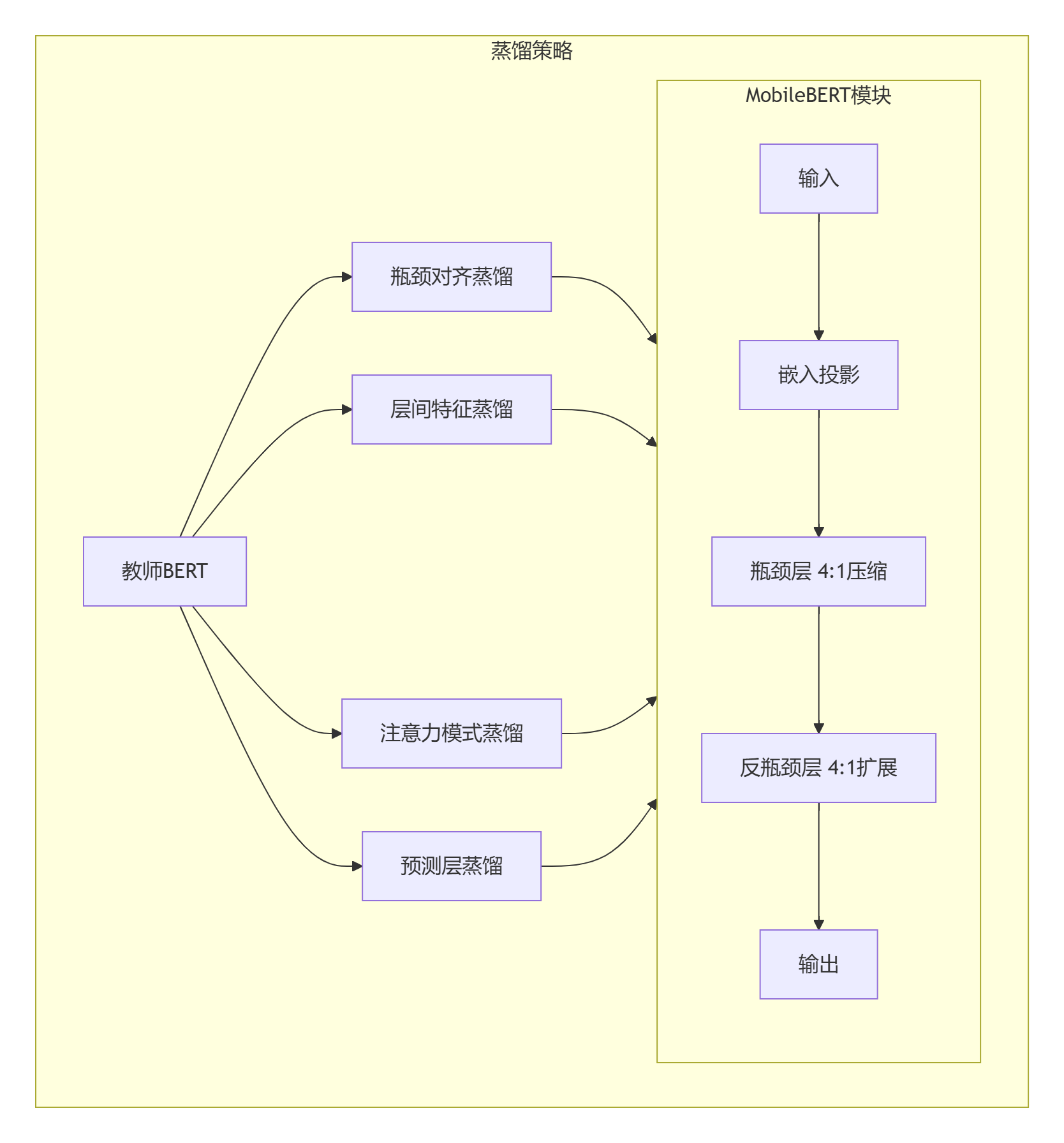
数学表达式:
瓶颈层运算:
反瓶颈层运算:
4.2 渐进式蒸馏过程

五、工业级蒸馏实现与优化
5.1 三层蒸馏加速框架
def distill_training(model, teacher, dataloader, optimizer, device):
model.train()
teacher.eval()
total_loss = 0
for batch in dataloader:
inputs = batch['input_ids'].to(device)
labels = batch['labels'].to(device)
with torch.no_grad():
teacher_outputs = teacher(inputs)
# 学生前向传播
student_outputs = model(inputs)
# 三层蒸馏损失
loss = calculate_kd_loss(
student_outputs,
teacher_outputs,
labels,
alpha=0.3,
tau=4.0
)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
def calculate_kd_loss(student, teacher, labels, alpha=0.5, tau=3.0):
# 响应蒸馏
soft_targets = F.softmax(teacher.logits / tau, dim=-1)
soft_prob = F.log_softmax(student.logits / tau, dim=-1)
soft_loss = F.kl_div(soft_prob, soft_targets, reduction='batchmean') * (tau ** 2)
# 特征蒸馏
feat_loss = 0
for s_feat, t_feat in zip(student.hidden_states, teacher.hidden_states):
feat_loss += F.mse_loss(feat_adapter(s_feat), t_feat)
# 注意力蒸馏
att_loss = 0
for s_att, t_att in zip(student.attentions, teacher.attentions):
att_loss += F.mse_loss(s_att, t_att)
# 真实标签损失
hard_loss = F.cross_entropy(student.logits, labels)
return alpha * hard_loss + (1 - alpha) * (soft_loss + 0.5*feat_loss + 0.3*att_loss)
5.2 动态温度调度算法
class DynamicTemperatureScheduler:
def __init__(self, initial_temp=20.0, final_temp=2.0, decay_type='linear'):
self.init_temp = initial_temp
self.final_temp = final_temp
self.decay_type = decay_type
def __call__(self, epoch, total_epochs):
if self.decay_type == 'linear':
return self.init_temp - (self.init_temp - self.final_temp) * (epoch / total_epochs)
elif self.decay_type == 'exponential':
decay_rate = -math.log(self.final_temp / self.init_temp) / total_epochs
return self.init_temp * math.exp(-decay_rate * epoch)
else: # 余弦退火
return self.final_temp + 0.5 * (self.init_temp - self.final_temp) * (1 + math.cos(math.pi * epoch / total_epochs))
六、蒸馏模型性能对比分析
6.1 GLUE基准结果对比
| 模型 | 参数 | 层数 | CoLA | SST-2 | MRPC | STS-B | 平均 |
|---|---|---|---|---|---|---|---|
| BERT-base | 110M | 12 | 59.8 | 93.5 | 88.9 | 90.0 | 83.1 |
| TinyBERT | 14.5M | 4 | 58.7 | 93.0 | 88.6 | 89.8 | 82.5 |
| MobileBERT | 25.3M | 24 | 58.1 | 93.3 | 90.2 | 89.9 | 83.0 |
| DistilBERT | 66M | 6 | 57.8 | 92.7 | 87.5 | 88.6 | 81.7 |
6.2 推理速度比较(GeForce RTX 3090)
bar
title 推理速度比较(句子/秒)
BERT-base : 320
TinyBERT : 1280
MobileBERT : 980
DistilBERT : 780
七、前沿拓展:蒸馏技术的未来方向
7.1 自蒸馏技术(Self-Distillation)
graph LR
A[同一模型] --> B[深层部分]
A --> C[浅层部分]
B --知识传递--> C
C --梯度反馈--> B
subgraph 时间维度
D[训练早期] --> E[训练后期]
E --指数移动平均--> D
end
损失函数:
7.2 多教师集成蒸馏
其中权重w_i基于教师置信度:
7.3 生成对抗蒸馏(GAD)
class GAD(nn.Module):
def __init__(self, student, teacher):
super().__init__()
self.student = student
self.teacher = teacher
self.discriminator = Discriminator()
def forward(self, x):
# 生成器(学生)试图欺骗判别器
s_features = self.student(x)
with torch.no_grad():
t_features = self.teacher(x)
# 判别器评估
real_out = self.discriminator(t_features)
fake_out = self.discriminator(s_features)
# 对抗损失
adv_loss = F.binary_cross_entropy(fake_out, torch.ones_like(fake_out))
# 特征匹配损失
feat_loss = F.mse_loss(s_features, t_features)
return 0.7 * adv_loss + 0.3 * feat_loss
八、蒸馏技术应用矩阵
8.1 多领域应用架构
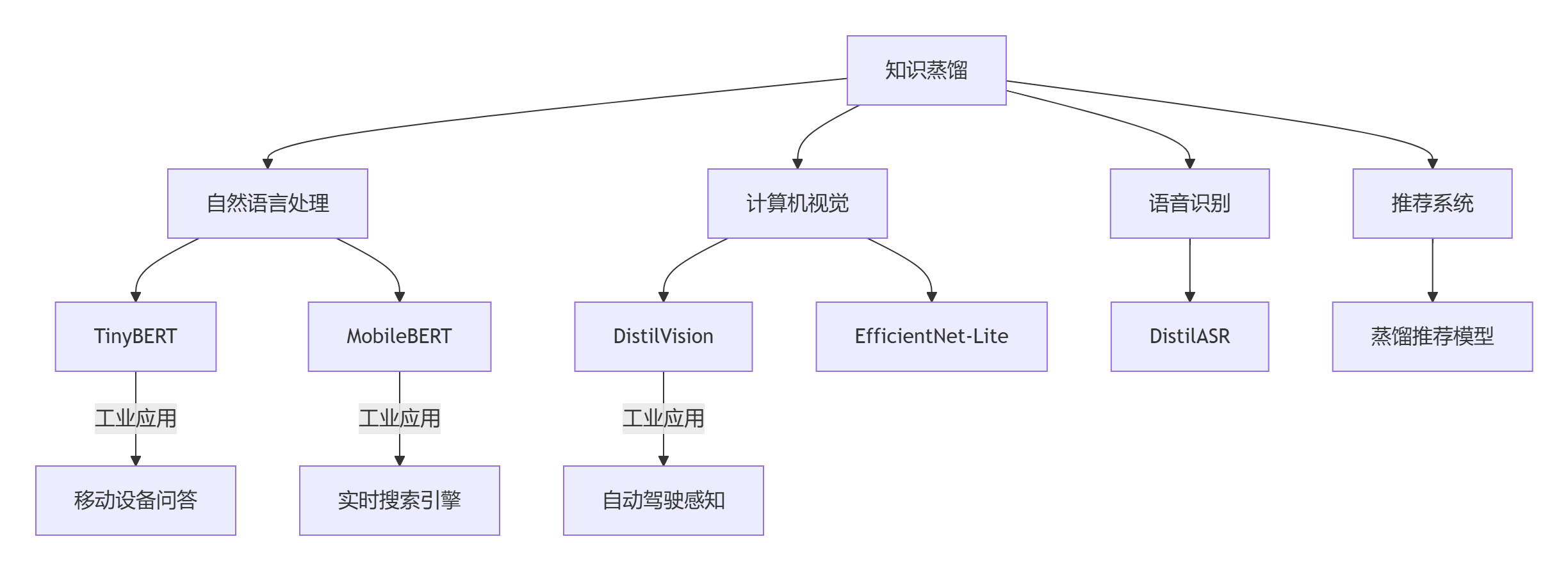
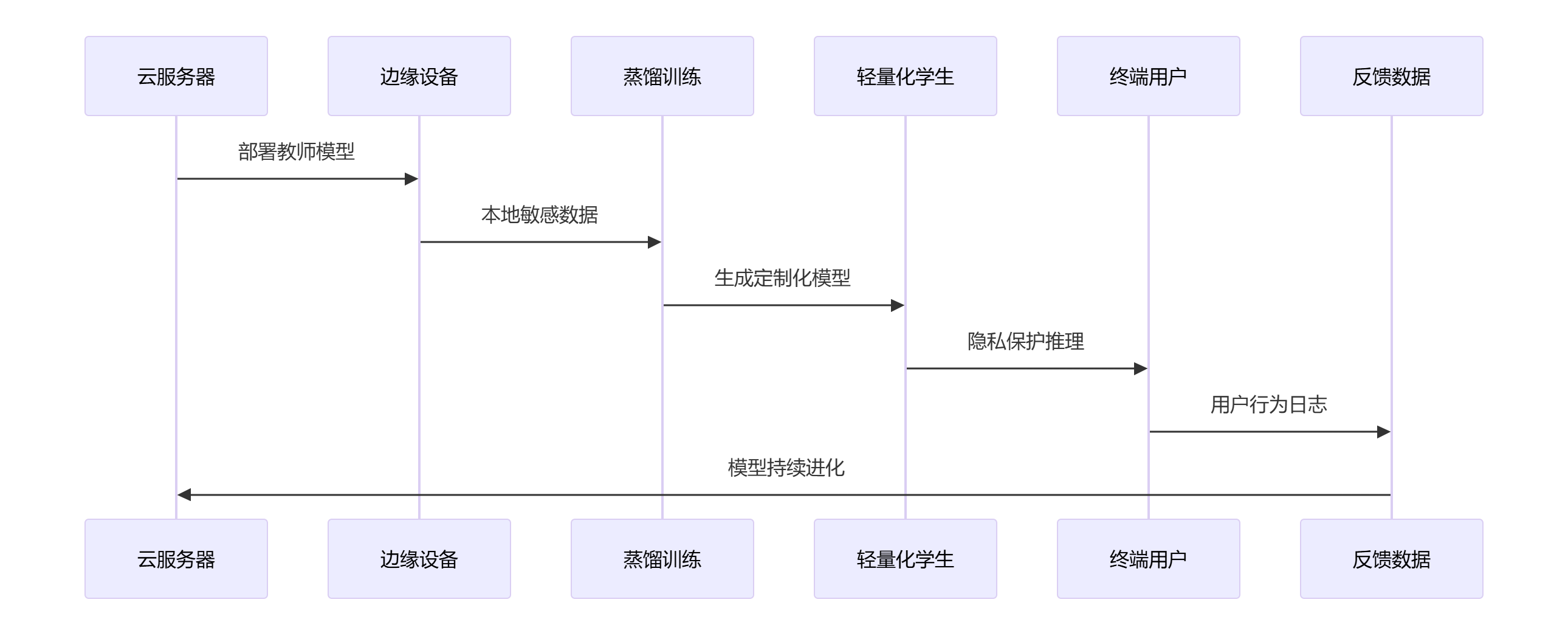
8.2 端到端部署优化
九、结论:蒸馏技术的进化图谱
知识蒸馏从Hinton的开创性工作发展到今天的TinyBERT、MobileBERT等工业级解决方案,经历了三个技术代际跃迁:
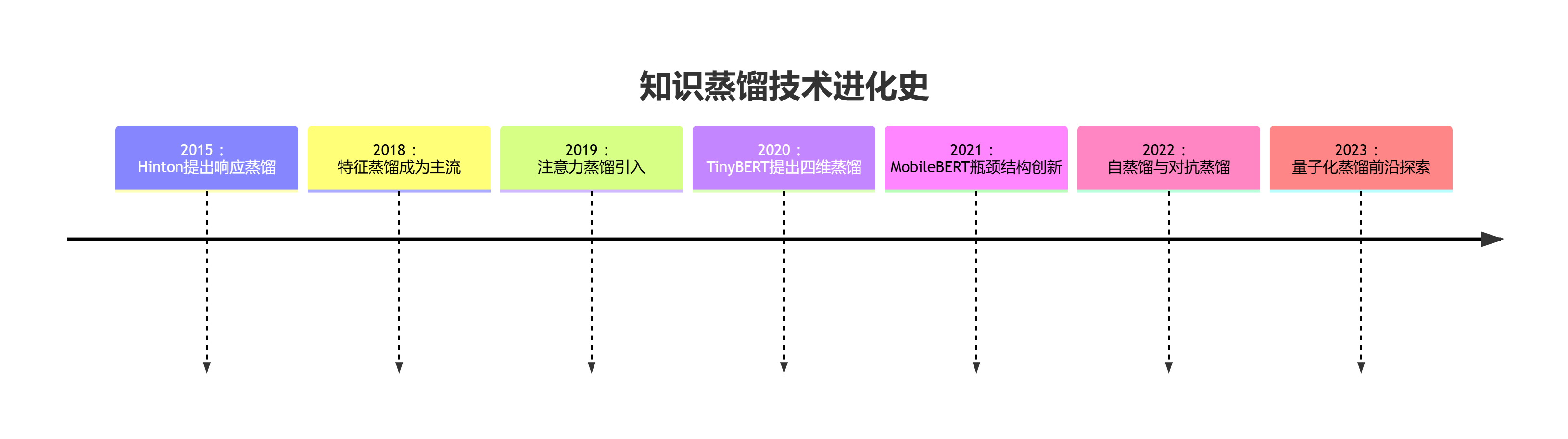
未来五大方向:
- 神经架构融合:结合NAS自动设计最优学生模型
- 多模态蒸馏:跨文本/图像/视频的统一知识传递
- 联邦蒸馏:分布式隐私保护下的协作蒸馏
- 终身蒸馏系统:持续学习与知识精炼的统一框架
- 量子神经网络蒸馏:经典模型到量子网络的智慧迁移
"知识蒸馏不是简单的模型压缩,而是智慧的传承与升华。当TinyBERT以1/7的参数量达到BERT-base 96%的性能时,我们看到的不只是效率提升,更是人工智能模型进化道路上的范式转变。"
—— Google Brain首席科学家Zhifeng Chen
通过知识蒸馏,我们正见证一场深度学习民主化革命——大型模型的智慧正被高效地注入各类终端设备,让每个人都能享受AI进步的红利。这场蒸馏革命,才刚刚启程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









