1.创建项目
scrapy startproject Naruto
cd Naruto2.创建爬虫文件
scrapy genspider naruto http://www.4399dmw.com/huoying/renwu/3.项目结构
4.修改配置(settings)
ROBOTSTXT_OBEY = False robots协议改为False
LOG_LEVEL = 'ERROR' # 输出日志
ITEM_PIPELINES = {
# 'NaRuTo.pipelines.NarutoPipeline': 300,
'NaRuTo.pipelines.MysqlPileLine': 300,
} # 管道
5.爬虫文件(spiders下面的naruto)
import scrapy
from NaRuTo.items import NarutoItem
class NarutoSpider(scrapy.Spider):
name = 'naruto'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.4399dmw.com/huoying/renwu/']
def parse(self, response):
# 解析出子页面的url
href = response.xpath('//*[@id="iga"]/li/a/@href').extract()
# 因为里面有重复的url,利用set方法去重
new_href = list(set(href))
for url in new_href:
# 拼接成完整的url连接
in_url = 'http://www.4399dmw.com' + url
try:
# 请求传参,将request继续交给scrapy引擎自动爬取并通过回调函数返回结果
yield scrapy.Request(url=in_url,
callback=self.parse_content)
except Exception as e:
print('请求失败:', e)
# 处理详情页数据
def parse_content(self, response):
# div_list = response.xpath('//*[@id="j-lazyimg"]/div[2]/div[1]/div[2]/div/div/div[2]')
# for div in div_list:
# 姓名
name = response.xpath('//*[@id="j-lazyimg"]/div[2]/div[1]/div[2]/div/div/div[2]/div[1]/h1/text()').extract_first()
# 详情
detail = response.xpath('//*[@id="j-lazyimg"]/div[2]/div[1]/div[2]/div/div/div[2]/div[1]/p[1]/text()').extract_first()
# 个人介绍
introduce = response.xpath('//*[@id="j-lazyimg"]/div[2]/div[1]/div[2]/div/div/div[2]/div[2]/p//text()').extract()
# 把爬取到的字符串里面的什么u3000替换为空(我也不知道是啥)
new_introduce = ''.join(introduce).replace('\u3000', '').replace('\xa0', '')
# 把爬取到的内容封装到字典里面
all_data = {
"name": name,
"detail": detail,
"introduce": new_introduce
}
# 实例化NarutoItem()
item = NarutoItem()
item['name'] = all_data['name']
item['detail'] = all_data['detail']
item['introduce'] = all_data['introduce']
# 把item传入到管道(pipelines)
yield item6.item.py
import scrapy
class NarutoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 忍者姓名
detail = scrapy.Field() # 发布详情
introduce = scrapy.Field() # 忍者介绍7.管道(pipelines)
import pymysql
class MysqlPileLine(object):
conn = None
cursor = None
def open_spider(self, spider):
# 连接MySQL
self.conn = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
password='***********',
db='naruto',
charset='utf8'
)
def process_item(self, item, spider):
# 游标
self.cursor = self.conn.cursor()
insert_sql = 'insert into all_naruto_data values ("%s", "%s", "%s")' % (item['name'], item['detail'], item['introduce'])
try:
# 提交sql
self.cursor.execute(insert_sql)
self.conn.commit()
except Exception as e:
print('插入失败:', e)
self.conn.rollback()
return item
# 关闭连接
def close_spider(self, spider):
self.cursor.close()
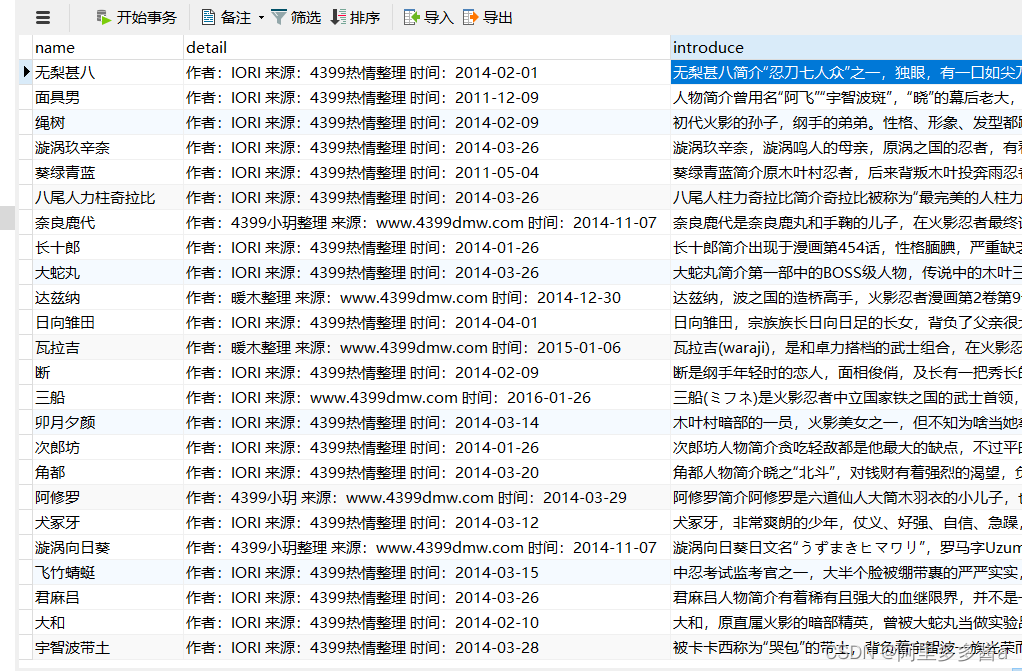
self.conn.close()7.忍者数据(一部分)







 该博客介绍了如何使用Python的Scrapy爬虫框架抓取4399动漫网的忍者信息,包括姓名、详情和介绍,并通过自定义的MysqlPipline将数据存储到MySQL数据库中。爬虫处理了URL去重、请求失败的异常以及内容中的特定字符替换。
该博客介绍了如何使用Python的Scrapy爬虫框架抓取4399动漫网的忍者信息,包括姓名、详情和介绍,并通过自定义的MysqlPipline将数据存储到MySQL数据库中。爬虫处理了URL去重、请求失败的异常以及内容中的特定字符替换。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











