






 本文介绍了SQL数据库设计的基本原则,包括遵循第三范式设计表,以及表与表之间的关系。接着,详细讲解了DDL语句,如创建、删除和修改表,并强调了约束的重要性。还探讨了视图和索引的作用,视图作为虚拟表用于权限管理和简化查询,而索引则提升查询速度。此外,文章还详细阐述了事务的概念,包括ACID特性、隔离级别及事务管理。最后,简述了DML操作(插入、更新、删除)和数据截断,以及序列的创建、使用和删除。
本文介绍了SQL数据库设计的基本原则,包括遵循第三范式设计表,以及表与表之间的关系。接着,详细讲解了DDL语句,如创建、删除和修改表,并强调了约束的重要性。还探讨了视图和索引的作用,视图作为虚拟表用于权限管理和简化查询,而索引则提升查询速度。此外,文章还详细阐述了事务的概念,包括ACID特性、隔离级别及事务管理。最后,简述了DML操作(插入、更新、删除)和数据截断,以及序列的创建、使用和删除。
1. 表设计
-
前提
设计表首先应该按需遵循三范式。三范式: 1NF-->列不可再分最小原子(避免重复);在第一范式(1NF)中表的每一行只包含一个实例的信息。 2NF-->主键依赖(确定唯一);第二范式(2NF)就是非主属性非部分依赖于主键。 3NF-->消除传递依赖(建立主外键关联,拆分表);第三范式(3NF)就是属性不依赖于其它非主属性。 目的:避免数据重复冗余。 -
表的设计
1.确定表名 。 2.确定字段名,类型 +约束(主键 外键 非空 默 检查认 唯一)。 字段类型: number char varchar2 date 其中char(n): 不可变字符,字符数必须为n个。 varchar2(n): 可变字符,字符数<=n; 约束:constraints 主键:唯一标识一条记录(唯一并且非空)。 唯一:唯一。 非空:不能为空。 默认:当没给值时使用给定一个默认值。 检查:自定义的规则。 外键:参考其他表(自己)的某个(某些)字段。 涉及到两张表: 1.父表|主表 。 2.子表|从表: 子表中添加一个外键字段,关联主表的主键字段。 注意:外键字段的值只能为主表中主键字段已有的值。 -
表与表之间的关系
一对一关系: (例如:用户表 身份证信息表) 主外键关联关系 一对多|多对一: (例如:班级表 学生表) 主外键关联关系: 在多的一方设置外键,关联一的一方的主键。 多对多: (例如:订单与商品 学生与选课) 中间表: 定义两张表的关联关系。
2. DDL
数据定义语言。
create表创建
drop删除表
alter修改表结构
-
表创建
表名必须唯一,如果存在 ,必须删除。语法: create table 表名( 字段名 类型(长度) 约束, ...其他字段.... ..约束........ ); 创建: 1.创建表(不加约束)。 2.创建表(同时创建约束+默认名称)。 3.创建表(同时创建约束+指定名称):在字段的后面指定约束名直接添加。 4.创建表(同时创建约束+指定名称):在结构结束之前为当前表中指定字段添加约束。 -
已有表中拷贝结构
1.拷贝已有表的全部数据: create table 表名 as select 字段列表 from 已有表 where 1!=1 2.拷贝已有表的部分数据: create table 表名 as select 字段列表 from 已有表 where 条件 -
表删除
先删除从表,再删除主表 ;同时删除约束。语法:drop table 表名 (cascade constraints)。 主外键关系下的两张表的删除: 删除从表: 直接删除:drop table 从表名 删除主表: 不能直接删除 1)先删除所有从表,再删除主表。 2)删除主表的同时级联删除主外键约束:drop table 主表名cascade constraints -
表修改
1.修改表名: rename to 2.修改列名: alter table 表名 rename column to 3.修改类型: alter table 表名 modify(字段 类型) 4.修改约束: 先删除 后添加 5.添加列: alter table 表名 add 字段 类型 6.删除列: alter table 表名 drop column 字段 -
约束
约束是一个个的对象。约束的禁用与启用: 禁用:ALTER TABLE 表名 disable constraint 字段名; 启用:ALTER TABLE 表名 enable constraint 字段名; 约束的删除: 删除:ALTER TABLE 表名 drop constraint 字段名 cascade;
3. 视图与索引
-
视图view
建立在结果集与表之间的虚拟表。语法: 创建:create or replace view 视图名 as select语句 [with read only]; with read only:只读不能修改。 删除:drop view 视图名 分类: 物理视图: 真是存储数据。 逻辑视图: 不会真是存储数据,数据来资源数据源 。 -
作用
1.简化:select 查询语句。 2.重用:封装select语句 命名。 3.隐藏:内部细节。 4.区分:相同数据不同查询。 -
权限问题
1.前提:create view -->组 connect resource dba 2.授权: -->sqlplus /nolog a)、sys登录 conn sys/123456@orcl as sysdba b)、授权: grant dba to scott; 回收: revoke dba from scott; c)、重新登录 -
索引
提高查询效率,相当于目录。主键|唯一: 唯一索引。 语法: 创建:create index 索引名 on表名 (字段列表...) 删除:drop index 索引名 注意: 1.索引是透明的,一个字段上是否添加了索引对字段的使用没有任何影响。 2.大数据量前提下,做查询才会提高效率,如果频繁做增删,反而会降低效率,索引也是数据库的对象之一,需要维护。 3.唯一性较好,少量修改,大量查询适合添加索引。 4.oracle数据库自动为主键添加索引。
4. 事务
事务是指作为单个逻辑工作单元执行的一组相关操作。这些操作要求全部完成或者全部不完成。
目的:为了保证数据的安全有效。
-
事务的特点(ACID)
1.原子性(Atomic):事务中所有数据的修改,要么全部执行,要么全部不执行。 2.一致性(Consistence):事务完成时,要使所有所有的数据都保持一致的状态,换言之:通过事务进行的所有数据修改,必须在所有相关的表中得到反映。 3.隔离性(Isolation):事务应该在另一个事务对数据的修改前或者修改后进行访问。 4.持久性(Durability):保证事务对数据库的修改是持久有效的,即使发生系统故障,也不应该丢失。 -
事务的隔离级别
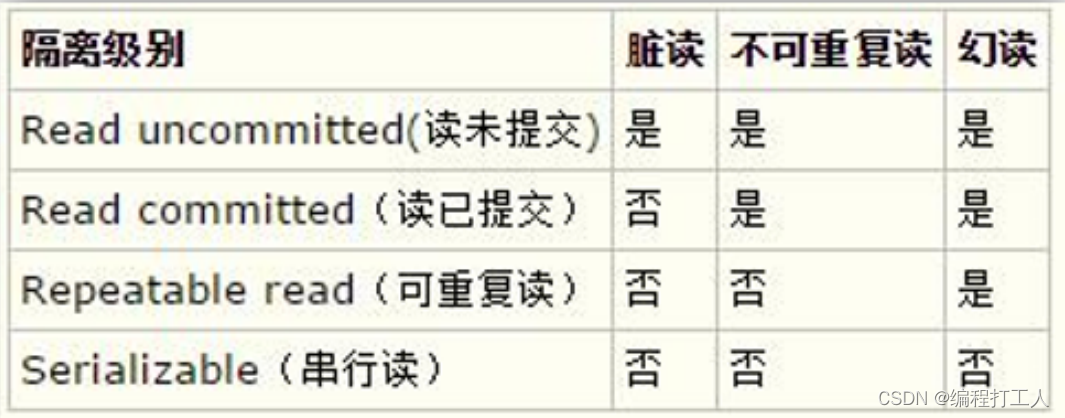
1.丢失更新:两个事务同时存储, 一个存储 100 , 一个存储 200,最终可能至存储了 200 或者 100,那另一个的更新就没成功,即结果不为预想的 300。 2.脏读:事务 T1 更新了一行数据,还没有提交所做的修改,T2 读取更新后的数据,T1回滚,T2 读取的数据无效,这种数据称为脏读数据。 3.不可重复读:事务 T1 读取一行数据,T2 修改了 T1 刚刚读取的记录,T1 再次查询,发现与第一次读取的记录不相同,称为不可重复读。 4.幻读:事务 T1 读取一条带 WHERE 条件的语句,返回结果集,T2 插入一条新纪录,恰好也是 T1 的WHERE 条件,T1 再次查询,结果集中又看到 T2 的记录,新纪录就叫做幻读。 注意: 1.Oracle 默认的隔离级别是 read committed。 2.Oracle 支持上述四种隔离级别中的两种:read committed 和 serializable。除此之外, Oralce 中还定义Read only 和 Read write 隔离级别。 1)Read only:事务中不能有任何修改数据库中数据的操作语句,是 Serializable 的一个子集。 2)Read write:它是默认设置,该选项表示在事务中可以有访问语句、修改语句,但不经常使用。 -
事务的开启
执行DML中的insert delete update默认开启事务。 -
事务的结束
1.成功: 1)正常执行完成的 DDL 语句:create、alter、drop。 2)正常执行完 DCL 语句 GRANT、REVOKE。 3)正常退出的 SQLPlus 或者 SQL Developer 等客户端。 4)如果人工要使用隐式事务,SET AUTOCOMMIT ON (只针对一个连接)。 5)手动提交:使用 commit。 2.失败: 1)rollback,手动回滚。 2)非法退出,意外的断电。 注意: rollback只能对未提交的数据撤销,已经Commit 的数据是无法撤销的,因为 commit 之后已经持久化到数据库中。
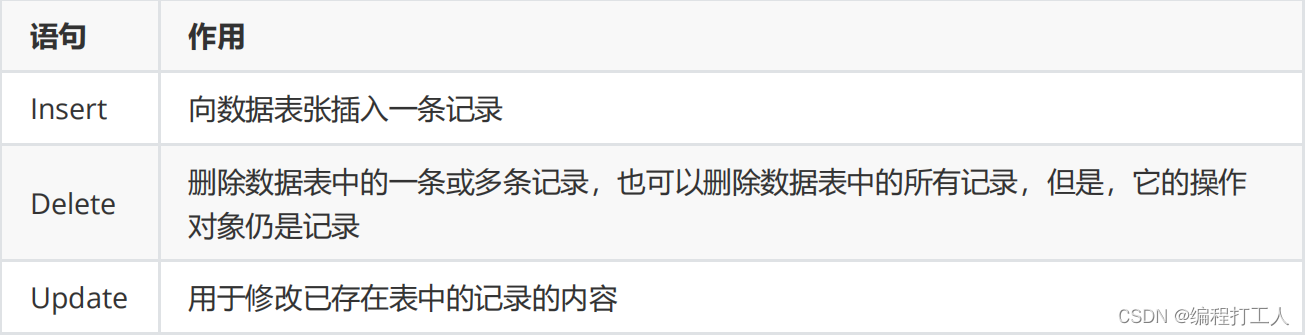
5. DML
DML(Data Manipulation Language 数据操控语言)用于操作数据库对象中包含的数据,也就是说操作的单位是记录。
-
insert
添加记录时需要满足以下条件: 1.类型 长度 兼容: 字段 兼容值。 2.值满足约束 :主键 (唯一+非空) 非空(必填) 唯一(不重复 ) 默认(没有填写使用默认值) 检查(满足条件),外键(参考主表主键列的值)。 3.个数必须相同: 指定列,个数顺序与列相同;没有指定,个数与表结构的列个数和顺序相同 (null也得占位,没有默认值)。 添加语法: 1.insert into 表名 values(值列表); 2.insert into 表(指定列) values(值列表); 3.insert into 表名 select 查询列 from 源表 where 过滤数据; 4.insert into 表(指定列) select 查询列 from 源表 where 过滤数据; -
update
要求: 1.记录存在。 2.类型 长度 兼容: 字段 兼容值。 3.个数相同。 语法: 1.update 表名 set 字段=值 [,....] where 过滤行记录; 2.update 表名 set (字段列表) =(select 字段列表 from 源表 where 过滤源表记录) where 更新记录的条件手动更改字段值: -
delete
说明: 1.delete 可以删除指定部分记录,删除全部记录。 2.记录上存在主外键关联时,删除存在关联的主表的记录时,注意参考外键约束, 约束强制不让删除,则先删除从表,再删除主表。 语法: 1.delete from 表名:删除一张表中所有数据。 2.delete from 表名 where 行过滤条件:满足条件的数据删除。 删除主外键约束关系下的两张表中的数据: 1.从表中的数据可以直接正常删除。 2.删除主表中数据 : 1)主表中没有被从表引用的数据,可以直接删除。 2)主表中已被从表引用的数据,不能直接删除。 解决方案: 1.删除从表中引用了当前主表数据的那些从表删除,然后再删除当前主表数据->默认 2.删除主表数据的同时,为从表所有引用了当前主表数据的那些从表数据的外键字段设置为null。 需要为从表中外键字段设置约束的时候 on delete set null 3.删除主表数据的同时,直接删除从表所有引用了当前主表数据的那些从表数据。 需要为从表中外键字段设置约束的时候 on delete cascade
6. 截断数据
truncate: 截断所有的数据 ,如果截断的是主表,结构不能存在外键关联,截断数据同时从结构上检查。
-
截断数据truncate与删除数据delete区别
1.truncate -->ddl ,不涉及事务,就不能回滚 delete -->dml ,涉及事务,可以回滚 。 2.truncate 截断所有的数据 。 delete 可以删除全部 或者部分记录 。 3.truncate从结构上检查是否存在主外键,如果存在,不让删除。 delete从记录上检查是否存在主外键,如果存在,按参考外键约束进行删除。
7. 序列
注意:
1.工具 ,管理流水号。
2.管理类似主键字段的值,数值型的,有变化规律的。
3.序列没有与表与字段绑定,序列的 删除不影响之前的使用 。
4.第一次使用序列需要先获取下一个最新值。
-
创建
create sequence 序列名 start with 起始值 increment by 步进; -
使用
当前值 序列名.currval 最新值 序列名.nextval -
删除
drop sequence 序列名;

















 3524
3524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









