







密码学的实验,参考 (照抄)了https://blog.youkuaiyun.com/jankingmeaning/article/details/84778668
分享出来供大家学习讨论,最后哈希出来的值应该是和在线工具结果一样的。
目录
MD5 (MD:message digest,消息摘要)简介
1990年10月, 著名密码学家R. L. Rivest在MIT(Massachusetts Institute of Technology)提出了一种Hash函数,作为RFC 1320 (RFC:互联网研究和开发机构工作记录)公开发表,称为MD4. MD5是MD4的改进版本, 于1992年4月作为RFC 1321公开发表
具有以下特性:
- 直接构造:不依赖任何密码系统和假设条件
- 算法简介
- 计算速度快
- 适合32位计算机软件实现
- 倾向于使用低端结构
MD5 算法实现
MD5算法的输入可以是任意长度的消息x,对输入消息按512位的分组为单位进行处理,输出128位的散列值MD(x)。整个算法分为五个步骤
步骤1:增加填充位
- 在消息x右边增加若干比特,使其长度与448模512同余。也就是说,填充后的消息长度比512的某个倍数少64位。
- 即使消息本身已经满足上述长度要求,仍然需要进行填充。例如,若消息长为448,则仍需要填充512位使其长度为960位。
- 填充位数在1到512之间。填充比特的第一位是1,其它均为0。
步骤2:附加消息长度值
用64位表示原始消息x的长度,并将其附加在步骤1所得结果之后。若填充前消息长度大于264,则只使用其低64位。填充方法是把64比特的长度分成两个32比特的字,低32比特字先填充,高32比特字后填充。
步骤1与步骤2一起称为消息的预处理
- 经预处理后,原消息长度变为512的倍数
- 设原消息x经预处理后变为消息
Y=Y0 Y1… YL-1,
其中Yi(i =0,1,…,L-1)是512比特
步骤3:初始化MD缓冲区
-
MD5算法的中间结果和最终结果都保存在128位的缓冲区里,缓冲区用4个32位的寄存器表示。
-
4个缓冲区记为A、B、C、D,其初始值为下列32位整数(16进制表示):
A = 01 23 45 67
B = 89 ab cd ef
C = fe dc ba 98
D = 76 54 32 10
采用小端的存储方式为
A = 0x67452301L;
B = 0xefcdab89L;
C = 0x98badcfeL;
D = 0x10325476L;
步骤4: 以512位的分组(16个字)为单位处理消息
步骤4是MD5算法的主循环,它以512比特作为分组,重复应用压缩函数HMD5,从消息Y的第一个分组Y0开始,依次对每个分组Yi进行压缩,直至最后分组YL-1,然后输出消息x的Hash值。可见,MD5的循环次数等于消息Y中512比特分组的数目L。
其主要流程如下图:
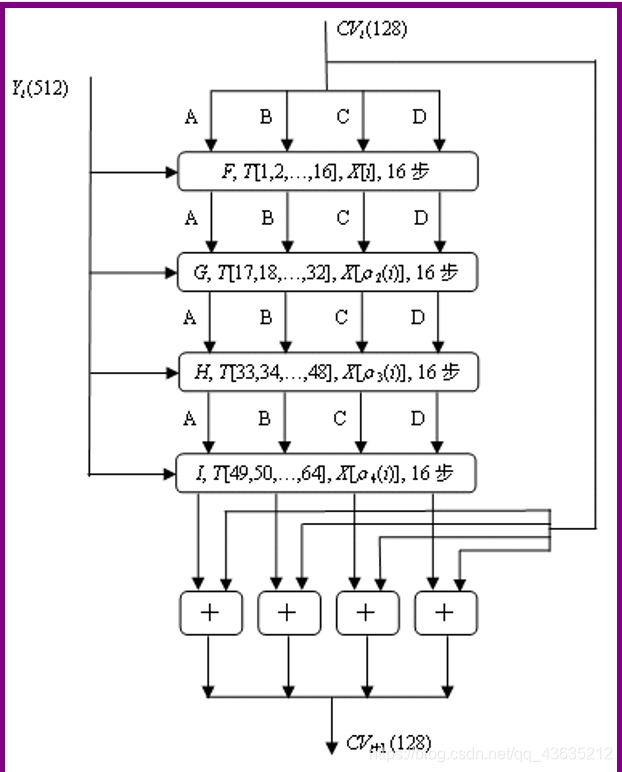
注:加法是指缓冲区中的4个字与CVi中对应的4个字分别模23^2相加
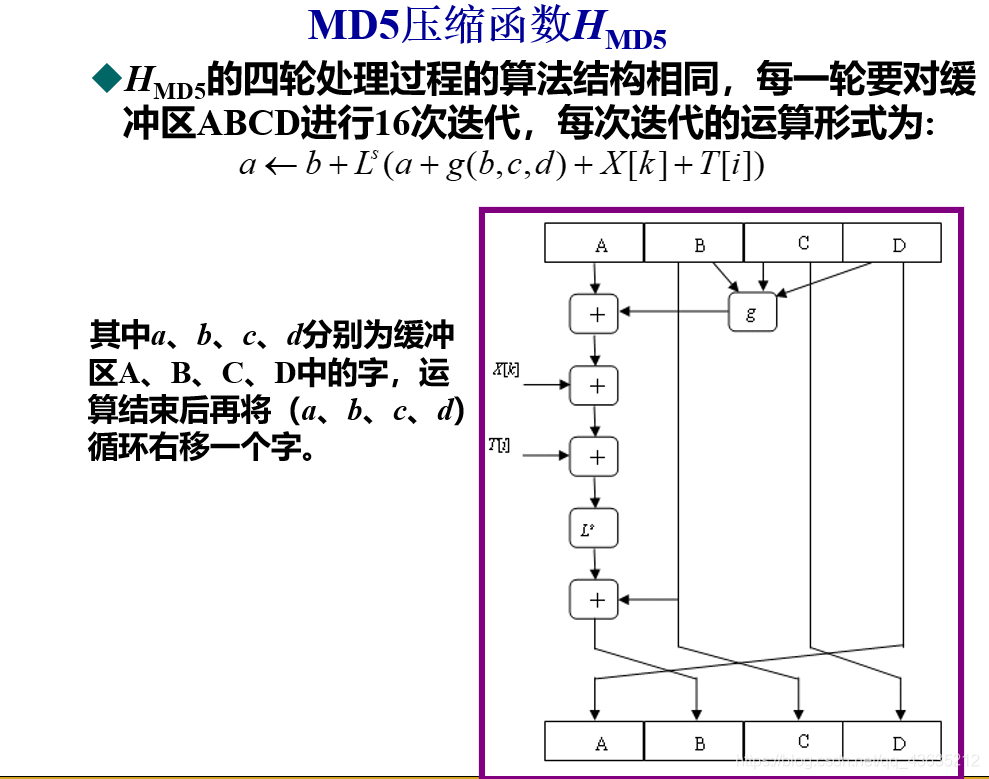
基本逻辑函数g
每一轮使用一个基本逻辑函数g,每个基本逻辑函数的输入是三个32位的字,输出是一个32位的字,它执行位逻辑运算,即输出的第n位是其三个输入的第n位的函数
轮数与所使用的逻辑函数对应关系如下图:

字组X
把当前处理的512比特的分组Yi依次分成16个32比特的字, 分别记为X[0,1,…,15]。在每一轮的16步迭代中, 每一步迭代使用一个字,迭代步数不同使用的字也不相同. 因此, 16步迭代恰好用完16个字。
对于不同轮处理过程,使用16字的顺序不一样,详情见下表:
| 轮次 | 使用字顺序 |
|---|---|
| 第一轮 | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 |
| 第二轮 | 1, 6, 11, 0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12 (1+5i mod 16) |
| 第三轮 | 5, 8, 11, 14, 1, 4, 7, 10, 13, 0, 3, 6, 9, 12, 15, 2 (5+3i mod 16) |
| 第四轮 | 0, 7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9 (7i mod 16) |
常数表T
常数表T包括64个32位常数。T[i] = 2^32 × abs(sin(i)) 的整数部分。

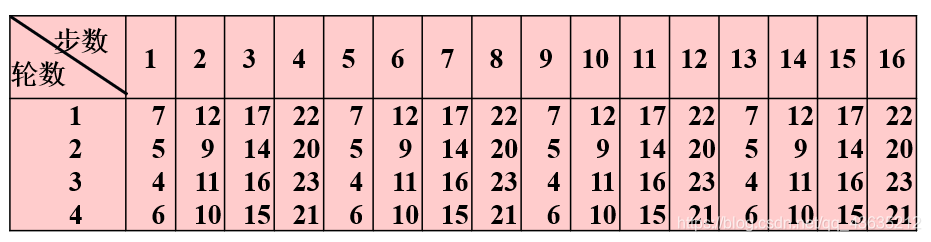
循环左移位数LS
Ls(v)表示对32位的变量v循环左移s位。s的值与轮数和迭代步数有关。
步骤5:输出散列值
代码实现
import java.util.Locale;
public class MD5 {
static String resultMessage = "";
//四个寄存器的初始值,采用小端存储
static final long A = 0x67452301L;
static final long B = 0xefcdab89L;
static final long C = 0x98badcfeL;
static final long D = 0x10325476L;
//缓冲区A,B,C,D
private static long[] buff = {A, B, C, D};
//表示X[k]中的的k取值,决定第i轮循环,第j次迭代中应该使用消息分组中的哪个字
static final int k[][] = {
{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15},
{1, 6, 11, 0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12}, //1+5i mod 16
{5, 8, 11, 14, 1, 4, 7, 10, 13, 0, 3, 6, 9, 12, 15, 2}, //5+3i mod 16
{0, 7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9}}; //7i mod 16
//常数表T,64个32位常数
static final long T[][] = {
{0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821},
{0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a},
{0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665},
{0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391}};
//循环左移位数s与轮数和迭代步数的关系
static final int LS[][] = {
{7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22},
{5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20},
{4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23},
{6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21}};
/**
* md5哈希
*
* @param msg
*/
public static String md5(String msg) {
byte[] bytes = msg.getBytes(); //转化为字节数组
int byteCount = bytes.length; //字的个数
long bitCount = (long) byteCount << 3; //比特位数
int leftByte = byteCount % 64; //按64字节分组后,剩余的字节
byte[] last = new byte[64]; //最后512位
for (int i = 0; i < leftByte; i++) { //先填充剩余的字节
last[i] = bytes[byteCount - leftByte + i];
}
int preGroupCount = byteCount / 64; //这些分组可以直接进行压缩
for (int i = 0; i < preGroupCount; i++) {
H(divide2X(bytes, i * 64));
}
/**
* 进行填充
*/
if (leftByte == 56) { //如果消息本身已经满足模512余448,则再填充512位,此时还需迭代两组
//第一组,从leftByte开始填充80,00....直至64字节
last[leftByte] = (byte) 0x80;
for (int i = leftByte + 1; i < 64; i++) {
last[i] = (byte) 0x00;
}
//压缩
H(divide2X(last, 0));
//第二组,先填充00,00...至56字节,再附加消息长度
for (int i = 0; i < 56; i++) {
last[i] = (byte) 0x00;
}
//附加消息长度,取长度的最后后64位(即long类型的长度),先填充低32比特再填充高32比特
for (int i = 0; i < 8; i++) {
last[56 + i] = (byte) (bitCount & 0xFFL);
bitCount >>= 8; //右移一个字节
}
//压缩
H(divide2X(last, 0));
} else if (leftByte < 56) { //模512小于448则只需将最后一组填充到448位,此时只需迭代最后一组
//填充80,00,00....直至56字节
last[leftByte] = (byte) 0x80;
for (int i = leftByte + 1; i < 56; i++) {
last[i] = (byte) 0x00;
}
//最后8字节填充消息长度,先低32位再高32位
for (int i = 0; i < 8; i++) {
last[56 + i] = (byte) (bitCount & 0xFFL);
bitCount >>= 8; //右移一个字节
}
//压缩
H(divide2X(last, 0));
} else { //模512大于448,填充后还需迭代两组
//先填充80,00,00...至满64字节
last[leftByte] = (byte) 0x80;
for (int i = leftByte + 1; i < 64; i++) {
last[i] = (byte) 0x00;
}
//压缩
H(divide2X(last, 0));
//最后一组,先填充00,00,00...至56字节
for (int i = 0; i < 56; i++) {
last[i] = (byte) 0x00;
}
//最后8字节填充消息长度,先低32位再高32位
for (int i = 0; i < 8; i++) {
last[56 + i] = (byte) (bitCount & 0xFFL);
bitCount >>= 8; //右移一个字节
}
//压缩
H(divide2X(last, 0));
}
//将Hash值转换成十六进制的字符串
//前面采用的是小端方式,这里需要转化回来
for (int i = 0; i < 4; i++) {
//解决缺少前置0的问题
resultMessage += String.format("%02x", buff[i] & 0xFF) +
String.format("%02x", (buff[i] & 0xFF00) >> 8) +
String.format("%02x", (buff[i] & 0xFF0000) >> 16) +
String.format("%02x", (buff[i] & 0xFF000000) >> 24);
}
return resultMessage;
}
/**
* MD5压缩函数
*
* @param X 字组X,16个,每个32位,共512位
*/
private static void H(long[] X) {
long temp;
//取出缓存器中的值
long a = buff[0], b = buff[1], c = buff[2], d = buff[3];
//四轮循环
for (int i = 0; i < 4; i++) {
//16次迭代
for (int j = 0; j < 16; j++) {
//模2^32加法
a = (a + g(i, b, c, d) + X[k[i][j]] + T[i][j]) & 0xffffffffL;
//循环左移 >>> 无符号右移,高位不分正负均补0
a = ((a << LS[i][j]) & 0xffffffffL) | ((a >>> (32 - LS[i][j])) & 0xffffffffL);
//加上b
a = (a + b) & 0xffffffffL;
//将abcd循环右移一个字
temp = a;
a = d;
d = c;
c = b;
b = temp;
}
}
//将本组结果写入缓存区
buff[0] = (buff[0] + a) & 0xffffffffL;
buff[1] = (buff[1] + b) & 0xffffffffL;
buff[2] = (buff[2] + c) & 0xffffffffL;
buff[3] = (buff[3] + d) & 0xffffffffL;
}
//4轮循环中使用的生成函数(轮函数)g
private static long g(int i, long b, long c, long d) {
switch (i) {
case 0:
return (b & c) | ((~b) & d);
case 1:
return (b & d) | (c & (~d));
case 2:
return b ^ c ^ d;
case 3:
return c ^ (b | (~d));
default:
return 0;
}
}
//从bytes的index开始取512位,生成字组X
private static long[] divide2X(byte[] bytes, int start) {
//存储一整个分组,就是512bit,数组里每个是32bit,就是4字节,为了消除符号位的影响,所以使用long
long[] X = new long[16];
for (int i = 0; i < 16; i++) {
//每个32bit由4个字节拼接而来
//小端的从bytes数组中到生成32位的字
X[i] = byte2unsignedInt8(bytes[4 * i + start]) |
(byte2unsignedInt8(bytes[4 * i + 1 + start])) << 8 |
(byte2unsignedInt8(bytes[4 * i + 2 + start])) << 16 |
(byte2unsignedInt8(bytes[4 * i + 3 + start])) << 24;
}
return X;
}
// 将byte转化为无符号8位整数
private static long byte2unsignedInt8(byte b) {
return b < 0 ? b & 0x7f + 128 : b;
}
public static void main(String[] args) {
System.out.println(md5("hash").toUpperCase(Locale.ROOT));
}
}

















 526
526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









