







1、三叉链表
在二叉链表的基础上增加了一个指向双亲的指针域。

2、三叉链表的结点数据类型声明
template<class T>
struct Node
{
T data;
Node<T> * lchild, *rchild,*parent;
};
3、树—二叉树
1.兄弟加线。
2.保留双亲与第一孩子连线,删去与其他孩子的连线。
3.顺时针转动,使之层次分明。
树的前序遍历等价于二叉树的前序遍历!
树的后序遍历等价于二叉树的中序遍历!
4、森林—二叉树
⑴ 将森林中的每棵树转换成二叉树;
⑵ 从第二棵二叉树开始,
依次把后一棵二叉树的根结点作为前一棵二叉树根结点的右孩子,
当所有二叉树连起来后,此时所得到的二叉树就是由森林转换得到的二叉树。
5、二叉树—树或森林
⑴ 加线——若某结点x是其双亲y的左孩子,则把结点x的右孩子、右孩子的右孩子、……,都与结点y用线连起来;
⑵ 去线——删去原二叉树中所有的双亲结点与右孩子结点的连线;
⑶ 层次调整——整理由⑴、⑵两步所得到的树或森林,使之层次分明。
6、森林的遍历
森林有两种遍历方法:
⑴前序(根)遍历:前序遍历森林即为前序遍历森林中的每一棵树。
⑵后序(根)遍历:后序遍历森林即为后序遍历森林中的每一棵树。
7、叶子结点的权值:对叶子结点赋予的一个有意义的数值量。
8、

9、哈夫曼树:给定一组具有确定权值的叶子结点,带权路径长度最小的二叉树。
哈夫曼树的特点:
- 权值越大的叶子结点越靠近根结点,而权值越小的叶子结点越远离根结点。
- 只有度为0(叶子结点)和度为2(分支结点)的结点,不存在度为1的结点.
哈夫曼算法基本思想:
⑴ 初始化:由给定的n个权值{w1,w2,…,wn}构造n棵只有一个根结点的二叉树,从而得到一个二叉树集合F={T1,T2,…,Tn};
⑵ 选取与合并:在F中选取根结点的权值最小的两棵二叉树分别作为左、右子树构造一棵新的二叉树,这棵新二叉树的根结点的权值为其左、右子树根结点的权值之和;
⑶ 删除与加入:在F中删除作为左、右子树的两棵二叉树,并将新建立的二叉树加入到F中;
⑷ 重复⑵、⑶两步,当集合F中只剩下一棵二叉树时,这棵二叉树便是哈夫曼树。
10、哈夫曼算法的存储结构

struct element
{ int weight;
int lchild, rchild, parent;
};
伪代码:
1.数组huffTree初始化,所有元素结点的双亲、左
右孩子都置为-1;
2. 数组huffTree的前n个元素的权值置给定值w[n];
3. 进行n-1次合并
3.1 在二叉树集合中选取两个权值最小的根结点,
其下标分别为i1, i2;
3.2 将二叉树i1、i2合并为一棵新的二叉树k(初值为n;依次递增);
void HuffmanTree(element huffTree[ ], int w[ ], int n ) {
for (i=0; i<2*n-1; i++) {
huffTree [i].parent= -1;
huffTree [i].lchild= -1;
huffTree [i].rchild= -1;
}
for (i=0; i<n; i++)
huffTree [i].weight=w[i];
for (k=n; k<2*n-1; k++) {
Select(huffTree, &i1, &i2);
huffTree[k].weight=huffTree[i1].weight+huffTree[i2].weight;
huffTree[i1].parent=k;
huffTree[i2].parent=k;
huffTree[k].lchild=i1;
huffTree[k].rchild=i2;
}
}
11、哈夫曼树应用——哈夫曼编码
前缀编码:一组编码中任一编码都不是其它任何一个编码的前缀 。
前缀编码保证了在解码时不会有多种可能。
12、线索二叉树
线索:将二叉链表中的空指针域指向前驱结点和后继结点的指针被称为线索;
线索化:使二叉链表中结点的空链域存放其前驱或后继信息的过程称为线索化;
线索二叉树:加上线索的二叉树称为线索二叉树。
线索二叉树的存储结构:线索链表
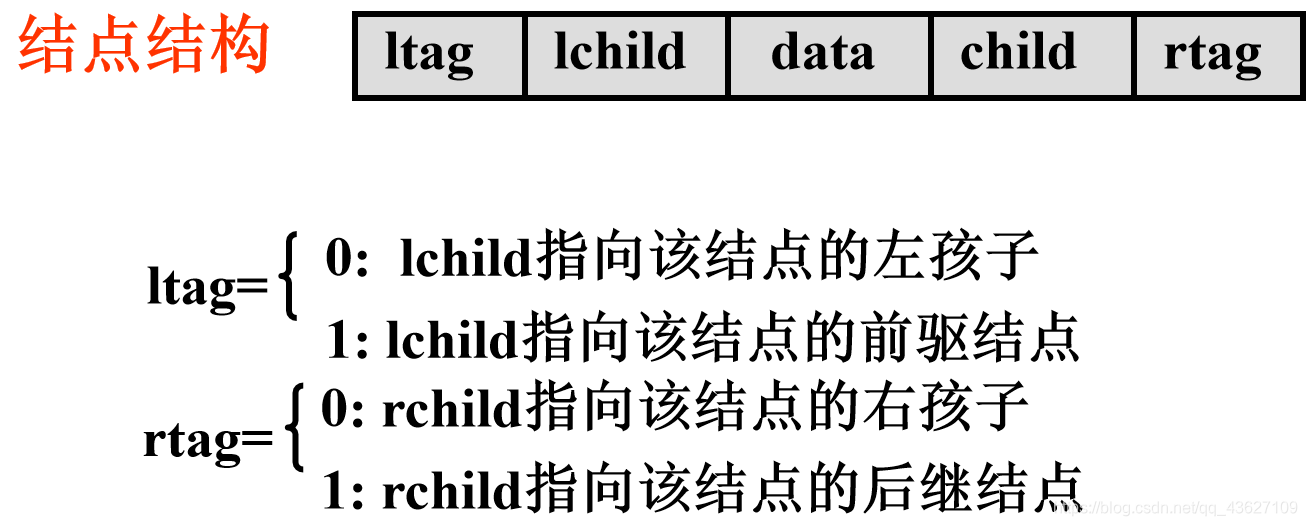
enum flag {Child, Thread};
template <class T>
struct ThrNode
{
T data;
ThrNode<T> *lchild, *rchild;
flag ltag, rtag;
};
二叉树的遍历方式有4种,故有4种意义下的前驱和后继,相应的有4种线索二叉树:
⑴ 前序线索二叉树
⑵ 中序线索二叉树
⑶ 后序线索二叉树
⑷ 层序线索二叉树
- 声明
template <class T>
class InThrBiTree{
public:
InThrBiTree();
~ InThrBiTree( );
ThrNode *Next(ThrNode<T> *p);
void InOrder(ThrNode<T> *root);
private:
ThrNode<T> *root;
ThrNode<T> * Creat();
void ThrBiTree(ThrNode<T> *root);
};
- 构造函数
建立线索链表,实质上就是将二叉链表中的空指针改为指向前驱或后继的线索,而前驱或后继的信息只有在遍历该二叉树时才能得到。
template <class T>ThrNode<T>* InThrBiTree<T>::Creat( ){
ThrNode<T> *root;
T ch;
cout<<"请输入创建一棵二叉树的结点数据"<<endl;
cin>>ch;
if (ch=="#") root = NULL;
else{
root=new ThrNode<T>;
root->data = ch;
root->ltag = Child; root->rtag = Child;
root->lchild = Creat( );
root->rchild = Creat( );
}
return root;
}
- 中序线索化二叉树
中序线索二叉树的构造方法:
中序线索化根结点的左子树;
对根结点进行线索化;
中序线索化根结点的右子树;
template <class T> void ThrBiTree<T>::ThrBiTree (ThrNode<T>*root) {
if (root==NULL) return; //递归结束条件
ThrBiTree(root->lchild);
if (!root->lchild){ //对root的左指针进行处理
root->ltag = Thread;
root->lchild = pre; //设置pre的前驱线索
}
if (!root->rchild) root->rtag = Thread;
if(pre != NULL){
if (pre->rtag==Thread) pre->rchild = root;
}
pre = root;
ThrBiTree(root->rchild);
}
- 建立
ThrNode<T>* pre = NULL
template <class T>
InThrBiTree<T>::InThrBiTree( )
{
//ThrNode<T>* pre = NULL;
this->root = Creat( );
ThrBiTree(root);
}
13、线索链表的遍历算法:中序遍历中序线索树
结点后继的确定
一个结点的右指针如果是线索,则右指针就是下一个要遍历的结点,
如果右指针不是线索,则它的中序后继是其右子树的“最左”结点
遍历何时停止?
一个节点的右指针==NULL
template <class T>
void InThrBiTree<T>::InOrder(ThrNode<T> *root){
ThrNode<T>* p = root;
if (root==NULL) return;
while (p->ltag==Child) { p = p->lchild; }
cout<<p->data<<" ";
while (p->rchild!=NULL) {
p = Next(p);
cout<<p->data<<" ";
}
cout<<endl;
}
14、

















 1820
1820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









