









正则化层-BatchNorm2d
引入正则化的目的:研究表明,正则化层的引入能够加快神经网络的训练速度。
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
该层使用简单,仅需考虑第一个参数 num_features。参数设置为输入数据的通道数即可。
#简单示例:
m = nn.BatchNorm2d(100)
# Without Learnable Parameters
m = nn.BatchNorm2d(100, affine=False)
input = torch.randn(20, 100, 35, 45)
output = m(input)

线形层
线性网络调参过程:
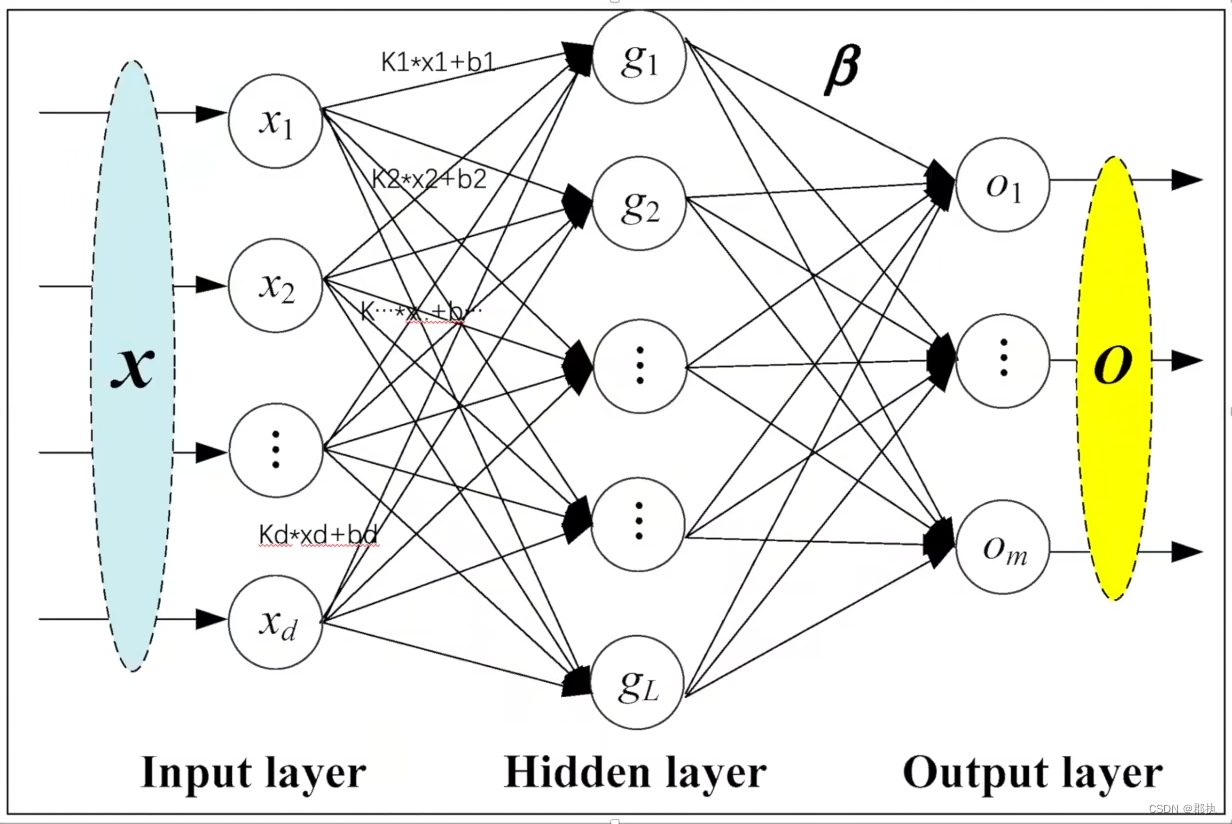
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
- in_features (int) – 输入的维度大小(形状大小)
- out_features (int) – 输出的维度大小(形状大小)
- bias (bool) – False, 没有偏执。
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../DataSet/dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, 64)
class MyModule(nn.Module):
def __init__(self):
super().__init__()
# 定义网络层接受的数据大小,输出的数据大小。拿一个具体规格的工具。像32号扳手一样
self.Linear = nn.Linear(196608, 10)
def forward(self, input):
output = self.Linear(input)
return output
mymodule = MyModule()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
input = torch.reshape(imgs, (1, 1, 1, -1))
# 用于数据的展平 n维度变成一维度 和上面改变形状的功能一样。
# input = torch.flatten(imgs)
print(input.shape)
output = mymodule(input)
print(output.shape)
break
结果:
torch.Size([64, 3, 32, 32])
torch.Size([1, 1, 1, 196608])
torch.Size([1, 1, 1, 10])
切换后:
torch.Size([64, 3, 32, 32])
torch.Size([196608])
torch.Size([10])

Dropout层
能够随机使一些inputsut数据进行随机的变成0;有定的P的概率。主要为了防止过拟合,主要用于NLP。
torch.nn.Dropout2d(p=0.5, inplace=False)
- p (float, optional)参数p为数据失活概率是多少!。

















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









