






 该实验通过希尔排序和选择排序对固定大小的数组进行排序,利用C语言计时器评估性能。结果显示,希尔排序(O(nlogn))在时间复杂度上优于选择排序(O(n^2)),实验验证了希尔排序的效率优势。
该实验通过希尔排序和选择排序对固定大小的数组进行排序,利用C语言计时器评估性能。结果显示,希尔排序(O(nlogn))在时间复杂度上优于选择排序(O(n^2)),实验验证了希尔排序的效率优势。
实验目的:
主观判断一个算法的性能可以通过算法的时间复杂度和空间复杂度来估计。现在要编写一程序来验证我们对代码性能的预测是否准确。
实验内容:
以希尔排序和选择为例,我们首先随机生成固定大小的数组,然后分别用两者算法对其进行生成以及排序处理,然后通过程序运行时间来判断筛算法性能。
以下为代码内容:
/*
Function :dc_ex1
Author :杭师小龙马
BuildDate:2019-9-6
Version :1.0
*/
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
#define MAX_SIZE 10 //数组大小
#define CYCLE_TIME 10000 //排序次数
clock_t start, stop;
double duration_select, duration_shell;//排序用时
int *Init_Array(); //随机生成数组并返回
void Select_Sort(int *array); //将输入的数组进行一次选择排序
void Shell_Sort(int *array); //将输入的数组进行一次希尔排序
int main() {
int time_select = CYCLE_TIME;
int time_shell = CYCLE_TIME;
int *array;
start = clock(); //计时起点
while (time_select--) { //执行指定次数的选择排序
array = Init_Array();
Select_Sort(array);
}
stop = clock(); //计时终点
//计算排序总用时
duration_select = ((double)(stop - start)) / CLOCKS_PER_SEC;
start = clock(); //计时起点
while (time_shell--) { //执行指定次数的希尔排序
array = Init_Array();
Shell_Sort(array);
}
stop = clock(); //计时终点
//计算排序总用时
duration_shell = ((double)(stop - start)) / CLOCKS_PER_SEC;
printf("选择排序随机%d位数组%d次的用时为%f,希尔排序的用时为%f。\n",
MAX_SIZE, CYCLE_TIME, duration_select, duration_shell);
return 0;
}
int *Init_Array() { //随机生成数组并返回
//定义一个数组指针并为其申请空间
int *array;
array = (int *)malloc(sizeof(int) * MAX_SIZE);
//用随机函数随机赋值
srand(time(NULL));
for (int i = 0; i < MAX_SIZE; i++) {
array[i] = rand();
}
//返回数组地址
return array;
}
void Select_Sort(int *array) { //将输入的数组进行一次选择排序
int temp, min;
for (int i = 0; i < MAX_SIZE - 1; i++) { //每次循环取数组中的下一位数字
min = i; //最小标记先给第i个数字
for (int j = i + 1; j < MAX_SIZE; j++) { //每次循环依次取第i位后面的数字
if (array[j] < array[min]) { //第i位和第j位较小的获得最小标记
min = j;
}
}
//第i位和最小标记的位交换位置
temp = array[i];
array[i] = array[min];
array[min] = temp;
}
}
void Shell_Sort(int *array) { //将输入的数组进行一次希尔排序
int j, temp, gap; //gap为步长
for (gap = MAX_SIZE / 2; gap >= 1; gap /= 2) { // 步长初始化为数组长度的一半,每次遍历后步长减半
for (int i = gap; i < MAX_SIZE; i += gap) { //对步长为gap的元素进行插入排序
temp = array[i]; //记录array[i]的值
j = i - gap; //j初始化为i的前一个元素(与i相差gap长度)
while (j >= 0 && array[j] > temp) {//当j小于0即array[i]是第一位或者array[j]比第i位小跳出循环
array[j + gap] = array[j]; //将在array[i]前且比temp的值大的元素向后移动一位
j -= gap;
}
array[j + gap] = temp;
}
}
}
实验结果:
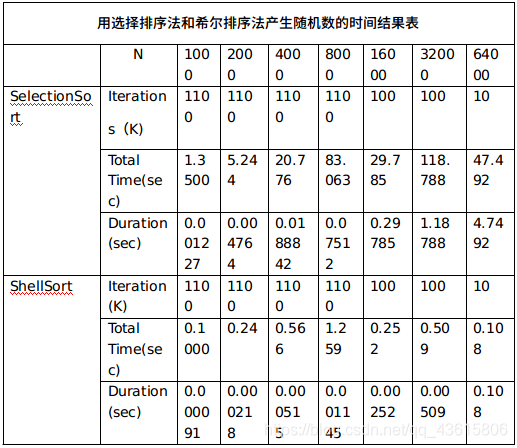
由两种算法的代码可知选择排序的时间复杂度是O(n^2),而希尔排序的时间复杂度是O(nlogn),显然希尔排序法更快。而由实验结果也可知希尔排序法的效率要远高于选择排序。实验预测成立。
备忘录:
C语言计时器的运用:
//开头声明:
#include<time.h>
clock_t start, stop;
//计时部分:
start = clock(); //计时起点
测量的代码
stop = clock(); //计时终点
//计算排序总用时:
time= ((double)(stop - start)) / CLOCKS_PER_SEC;
随机数生成函数:
int rand():返回值为随机值,参数为空,通过 rand 函数就会产生一个随机数。
void srand(unsigned int seed):返回值为空, 就是设置随机种子的,当我们不设置随机种子的时候,默认设置的种子为 1,也就是srand(1)。
//原代码随机整数生成:
#include<stdlib.h>
srand(time(NULL));
for (int i = 0; i < MAX_SIZE; i++) {
array[i] = rand();
}
希尔排序的理解:
多次的,范围逐渐扩大的直接插入排序。直接排序后会使数组部分有序,多次后不断扩大有序范围,最后逐渐使整个数组有序。

















 1778
1778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









