




 本文详细介绍了Python中的变量类型、格式化输出、条件判断、随机数生成、字符串操作、列表元组字典等数据结构的常用方法,以及函数、推导式和文件操作等内容。
本文详细介绍了Python中的变量类型、格式化输出、条件判断、随机数生成、字符串操作、列表元组字典等数据结构的常用方法,以及函数、推导式和文件操作等内容。
文章目录
变量类型
int、float、布尔型、str、list、tuple、set、dict,用type(变量)就能得到变量类型
输出
格式化输出
常用符号 :%s,用于字符串;%d,用于整数;%f,用于浮点数;
用法示例:
name = '张三'
print('我叫%s' %name)
其中%s也可用f表达式代替,两者对比如下
name = '张三'
age = 18
print('我叫%s,今年%s岁' %(name,age))
print(f'我叫{name},今年{age}岁')
%d可以写成例如%03d,此时如果变量位数不足3位会在前面补0
%f如果想限制小数位数可以写成例如%.2f
输入
变量名 = input(“提示语”)
常用转换数据类型的函数:
int(x)
float(x)
str(x)
eval(str) 用来计算在字符串中的有效python表达式,并返回一个对象
tuple(s) 将序列s转换为一个元组
list(s) 将序列s转换为一个列表
其中eval是将字符串转换回原来的类型
# eval()
str1 = '1'
str2 = '1.1'
str3 = '(1,2,3)'
str4 = '[1,2,3]'
print(eval(str1))
print(eval(str2))
print(eval(str3))
print(eval(str4))
条件
python里面用的条件语句为if elif else,形式为
if 条件:
语句
条件写法拓展,例如
age >= 18 and age <= 60 可以简化为18 <= age <=60
随机数
import random
num = random.randint(0,2) //包含[0,2]
print(num)
三目运算符
a = 1
b = 2
c = a if a > b else b
print(c)
字符串
切片
语法:序列[开始位置下标:结束位置下标:步长]
不包含结束位置下标对应的数据,正负整数均可
步长是选取间隔,正负整数均可,步长默认为1
str = '012345678'
print(str[2:5]) #2-5,步长为1
print(str[2:5:2]) #2-5,步长为2
print(str[:5]) #5位置之前的全部输出
print(str[2:]) #从2位置开始后面全部输出
print(str[:]) #全部输出
print(str[::-1]) #倒序输出
print(str[-4:-1])
print(str[-1:-4:-1]) #某一部分倒序输出
常用操作方法
查找
find():检测某个子串是否包含在这个字符串中,如果在返回这个子串的位置下标,否则返回-1,当然开始和结束位置下标可以省略
rfind():同find,不过是从右向左查找
index():同find,但如果查找失败会报错
rindex():从右向左查
count():统计某个子串出现的次数
修改
replace():替换,一般是replace(旧子串,新子串,替换次数)
split():分割,返回一个列表,也可以限定次数
join():用一个字符或子串合并字符串,即是将多个字符串合并为一个新的字符串
capitalize():将字符串第一个字符转换成大写
title():将字符串每个单词首字母转换成大写
lower():将字符串中大写转小写
upper():将字符串中小写转大写
lstrip():删除字符串左侧空白字符
rstrip():删除字符串右侧空白字符
strip():删除字符串两侧空白字符
ljust():返回一个原字符串左对齐,并使用指定字符(默认空格)填充至对应长度的新字符串
rjust():返回一个原字符串右对齐,并使用指定字符(默认空格)填充至对应长度的新字符串
center():返回一个原字符串居中对齐,并使用指定字符(默认空格)填充至对应长度的新字符串
判断
startswith():检查字符串是否是以指定子串开头,是则返回True,否则返回False。如果设置开始和结束位置下标,则在指定范围内检查
endswith():检查字符串是否是以指定子串结尾,是则返回True,否则返回False。如果设置开始和结束位置下标,则在指定范围内检查
isalpha():如果字符串至少有一个字符并且所有字符都是字母则返回True,否则返回False
isdigit():如果字符串只包含数字则返回True否则返回False
isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False
isspace():如果字符串中只包含空白,则返回True,否则返回False。
列表
常用函数
查找
index():返回指定数据所在位置的下标
count():统计指定数据在当前列表中出现的次数
len():访问列表长度,即列表中数据的个数
判断是否存在:in、not in
增加
append():列表结尾追加数据
extend():列表结尾追加数据,如果数据是一个序列,则将这个序列的数据逐一添加到列表
insert():指定位置新增数据
删除
del,可以删除整个列表,也可以删除列表的某个下标值
pop(),不写下标表示删除最后一个数据
remove(),移除列表中某个数据的第一个匹配项
clear(),清空列表
修改
可以直接修改列表某个下标的值
reverse():逆置
sort():排序,可以加一个参数reverse,True表示降序,False表示升序
复制
copy()
元组
特点:定义元组使用小括号,且逗号隔开各个数据,数据可以是不同的数据类型
如果定义的元组只有一个数据,那么这个数据后面也最好添加逗号,否则数据类型就是唯一的数据的数据类型
查找
index():与列表、字符串的index方法相同
count():统计某个数据在当前元组出现的次数
len():统计元组中数据的个数
修改
元组内的直接数据如果修改会立即报错,但如果元组里面有列表,修改列表里的数据则是支持的
字典
增/改:字典序列[key] = 值
如果key存在则修改这个key对应的值;如果key不存在则新增此键值对
删:del() / del:删除字典或删除字典中指定键值对
清空字典:clear()
查:字典序列[key],如果key存在,则返回对应的值,否则就报错
get():字典序列.get(key,默认值),如果当前查找的key不存在则返回第二个参数(默认值),如果省略第二个参数,则返回None
keys():返回字典的所有键
values():返回字典的所有键对应的值
items():返回包含键值对的可迭代对象,而且是用元组来包含键值对
遍历字典的键值对
dict = {'name':'Tom','age':20,'gender':'男'}
for key,value in dict.items():
print(f'{key} = {value}')
集合
增加数据
add()
因为集合有去重功能,所以当向集合内追加的数据是已有数据的话,则不进行任何操作
update(),追加的数据是序列
删除数据
remove(),删除集合中的指定数据,如果数据不存在则报错
discard(),删除集合中的指定数据,如果数据不存在也不会报错
pop(),随机删除集合中某个数据,并返回这个数据
判断是否存在
in、not in
公共操作
运算符
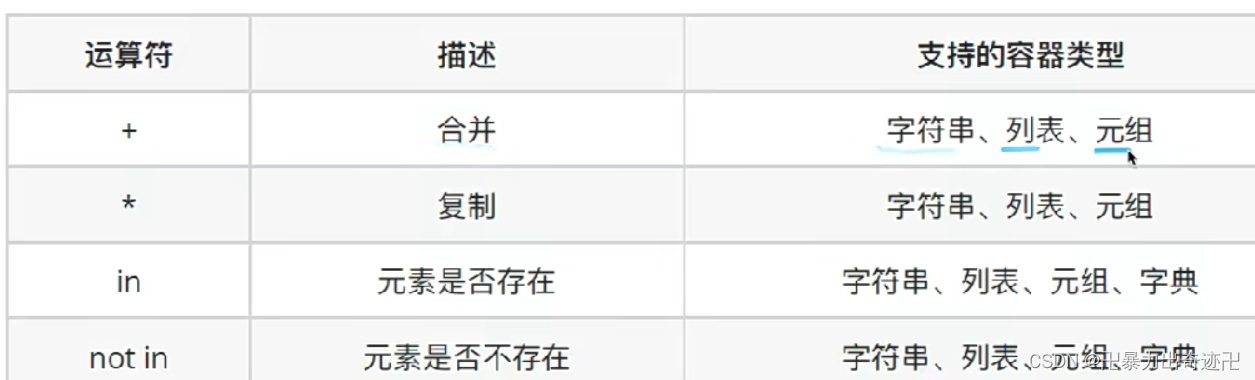
公共方法

其中enumerate()可以用一个start参数来设置遍历数据的下标的起始值,默认为0,使用形式为enumerate(可遍历对象,start=0)
容器类型转换
tuple():将某个序列转换成元组
list():将某个序列转换成列表
set():将某个序列转换成集合
推导式
列表推导式
用一个表达式创建一个有规律的列表或控制一个有规律的列表
list = [i for i in range(10)]
print(list)
创建0-10的偶数列表
#法一:range()步长实现
list1 = [i for i in range(0,10,2)]
print(list1)
#法二:if实现
list2 = [i for i in range(10) if i % 2 == 0]
print(list2)
多个for循环实现列表推导式
例如:创建一个列表[(1,0),(1,1),(1,2),(2,0),(2,1),(2,2)]
list3 = [(i,j) for i in range(1,3) for j in range(3)]
print(list3)
字典推导式
dict1 = {i:i**2 for i in range(1,5)}
print(dict1)
将两个列表合并为一个字典
list4 = ['name','age','gender']
list5 = ['Tom',20,'man']
dict2 = {list4[i]:list5[i] for i in range(len(list4))}
print(dict2)
提取字典中目标数据
counts = {'MBP':268,'HP':125,'DELL':201,'Lenovo':199,'acer':99}
count1 = {key:value for key,value in counts.items() if value >= 200}
print(count1)
集合推导式
list6 = [1,1,2]
set = {i ** 2 for i in list6}
print(set)
函数
定义函数
def 函数名(参数):
代码
调用函数:函数名(参数)
如何修改全局变量:先global a,然后再a = 某个值
函数返回值
return 某个值
也可以返回多个值,比如 return 1,2,返回的默认是元组类型
return 后面可以连接列表、元组或字典
函数参数
位置参数:函数调用传递参数的顺序要和定义时参数的顺序一致
关键字参数:函数调用,通过“键=值”形式加以指定,能够消除参数定义的顺序要求
另外,函数调用时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
def user_info(name,age,gender):
print(f'名字是{name},年龄是{age},性别是{gender}')
user_info('Rose',age=20,gender='女')
user_info('小明',gender='男',age=16)
缺省参数
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值,所有位置参数必须出现在默认参数前
不定长参数
不定长参数也叫可变参数。用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。此时,可用包裹位置参数,或者包裹关键字参数,来进行参数传递
包裹位置传递
def user_info(*args):
print(args)
user_info('TOM')
user_info('TOM',18)
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是包裹位置传递
包裹关键字传递
def user_info(**kwargs):
print(kwargs)
user_info(name='TOM',age=18,id=110)
交换两个变量的值的简便方法
a,b = 1,2
print(a)
print(b)
a,b = b,a
print(a)
print(b)
lambda表达式
主要用于简化函数代码
lambda 参数列表 : 表达式
其中参数可有可无,能接收任何数量的参数但只能返回一个表达式的值
函数与lambda表达式对比示例:计算a+b
#函数实现
def add(a,b):
return a + b
result = add(1,2)
print(result)
#lambda表达式实现
fn1 = lambda a,b : a + b
print(fn1(1,2))
带判断的lambda表达式
fn2 = lambda a, b : a if a > b else b
print(fn2(1000,500))
lambda表达式解决列表排序问题
students = [
{'name':'TOM','age':20},
{'name':'ROSE','age':19},
{'name':'Jack','age':22}
]
#按name值升序排列
students.sort(key=lambda x:x['name'])
print(students)
#按name值降序排列
students.sort(key=lambda x:x['name'],reverse=True)
print(students)
#按age值升序排列
students.sort(key=lambda x : x['age'])
print(students)
内置函数
abs():绝对值计算
round():对数字进行四舍五入
map(func,lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表/迭代器返回
list1 = [1,2,3,4,5]
def func(x):
return x ** 2
result = map(func,list1)
print(result)
print(list(result))
reduce(func,lst),其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累积计算
reduce()传入的参数func必须接收2个参数
例如:计算list1序列中各个数字的累加和
import functools
list1 = [1,2,3,4,5]
def func(a,b):
return a+b
result = functools.reduce(func,list1)
print(result)
filter()
filter(func,lst)函数用于过滤序列,过滤掉不符合条件的元素,返回一个filter对象。如果要转换为列表,可以用list()来转换
list1 = [1,2,3,4,5,6,7,8,9,10]
def func(x):
return x % 2 == 0
result = filter(func,list1)
print(result)
print(list(result))
文件操作
打开,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
open(name,mode)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)
mode:设置打开文件的模式(访问模式):只读、写入、追加等
#打开
f = open('test.txt','w')
#读写操作 write() read()
f.write('aaa')
#关闭close()
f.close()
文件函数
读取
read()
文件对象.read(num)
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
readlines()
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素
readline()
readline()一次读取一行内容
f = open('test.txt')
content = f.readline()
print(f'第一行:{content}')
content = f.readline()
print(f'第二行:{content}')
f.close()
seek()
用来移动文件指针
文件对象.seek(偏移量,起始位置)
起始位置:
0:文件开头
1:当前位置
2:文件结尾
文件备份
old_name = input('请输入要备份的文件名:')
index = old_name.rfind('.')
#有效文件名才备份
if index > 0:
postfix = old_name[index:]
new_name = old_name[:index]+'[备份]'+postfix
print(new_name)
old_f = open(old_name,'rb')
new_f = open(new_name,'wb')
while True:
content = old_f.read(1024);
if(len(content) == 0):
break
new_f.write(content)
old_f.close()
new_f.close()
另一种文件操作函数
import os
文件重命名:os.rename(目标文件名,新文件名)
删除文件:os.remove(目标文件名)
文件夹操作函数
创建文件夹:os.mkdir(文件夹名字)
删除文件夹:os.rmdir(文件夹名字)
获取当前目录:os.getcwd()
改变默认目录:os.chdir(目录)
例如在aa目录里创建bb目录
os.chdir(‘aa’)
os.mkdir(‘bb’)
获取目录列表:os.listdir(目录)

















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









