







1.1 高效公式
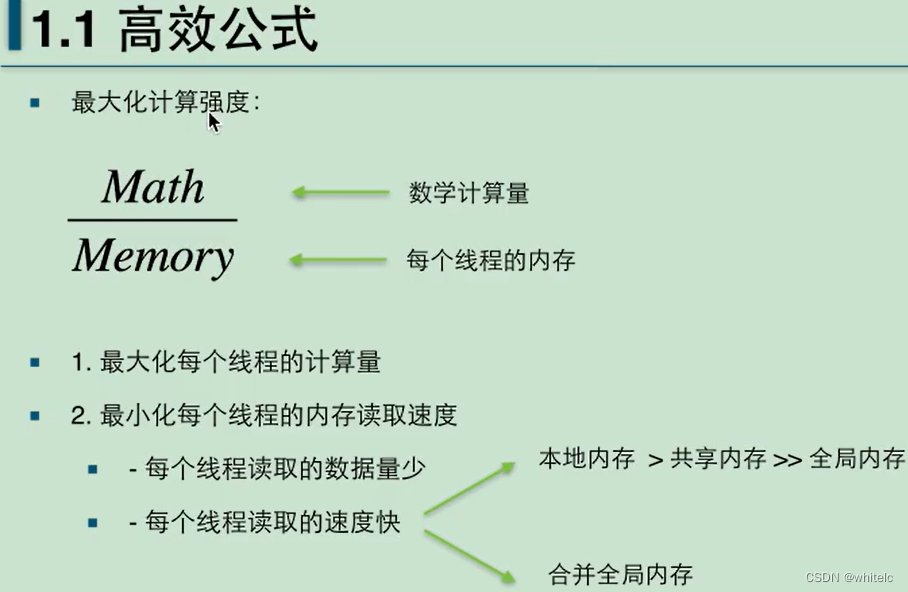 要么增大数据量,要么减少每个线程的内存(每个线程读取的数据量变少,每个线程的读取数据的速度变快(转变存储方式,对读取慢的地方做优化–合并全局内存))
要么增大数据量,要么减少每个线程的内存(每个线程读取的数据量变少,每个线程的读取数据的速度变快(转变存储方式,对读取慢的地方做优化–合并全局内存))
1.2 合并全局内存
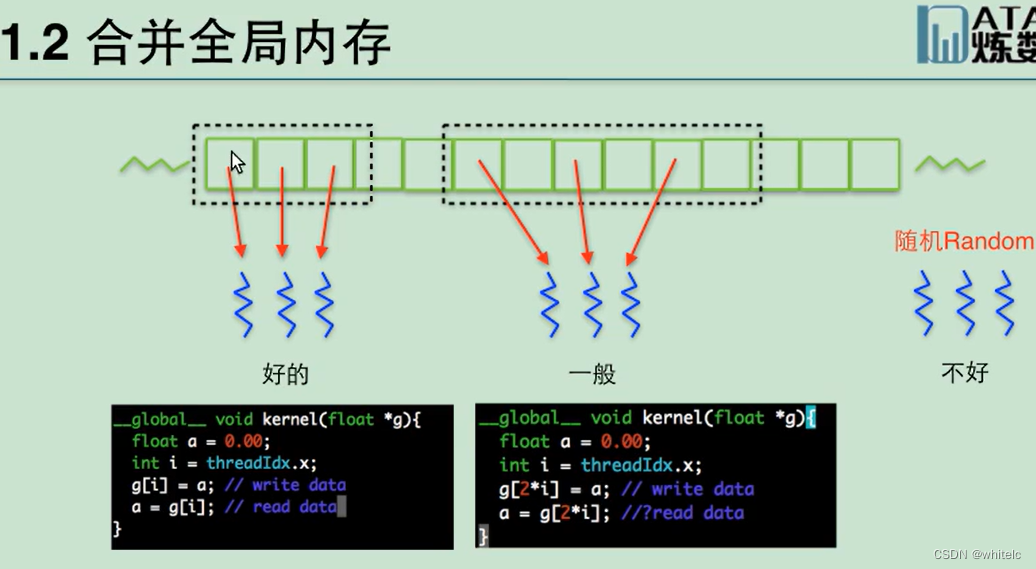 一个线程读取一个数据,读取数据的方式有三种
一个线程读取一个数据,读取数据的方式有三种
- 数组是连续的,按照顺序读----
- 固定步长读取,比如每隔两个读一个
- 随机读取,在任意位置开始获取数据
下面代码显示,假设g是全局内存,threadIdx.x是当前的线程号,意思是,当前线程号是多少就读取这个对应的数组,线程号连续所以读取的数据是连续的。
尽量让总的数据量和线程号挂钩去读取
1.3 避免线程发散
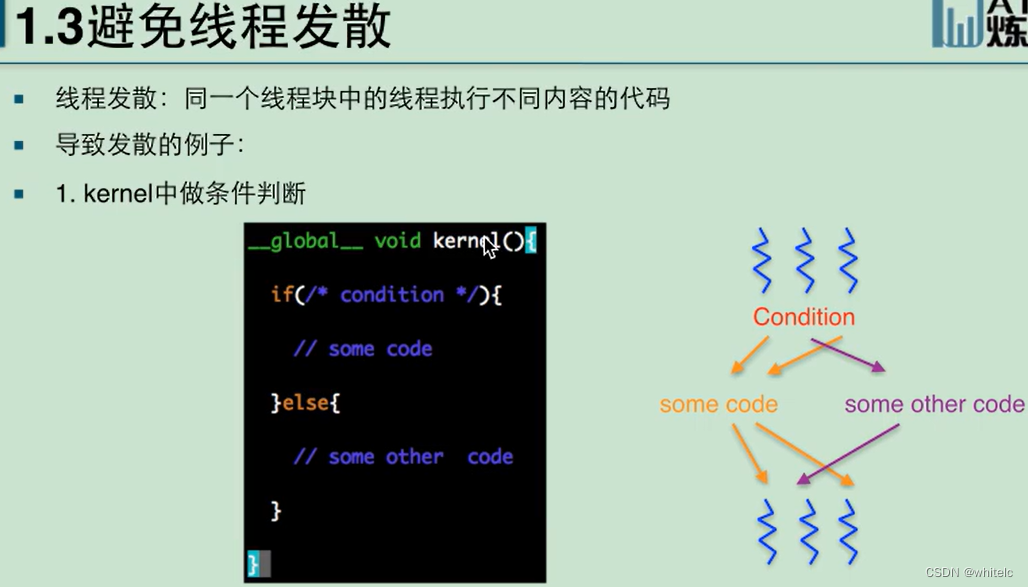
一个kernel中的所有线程都跑完才叫做运行结束,决定最后速度的是,执行时间最慢的那个
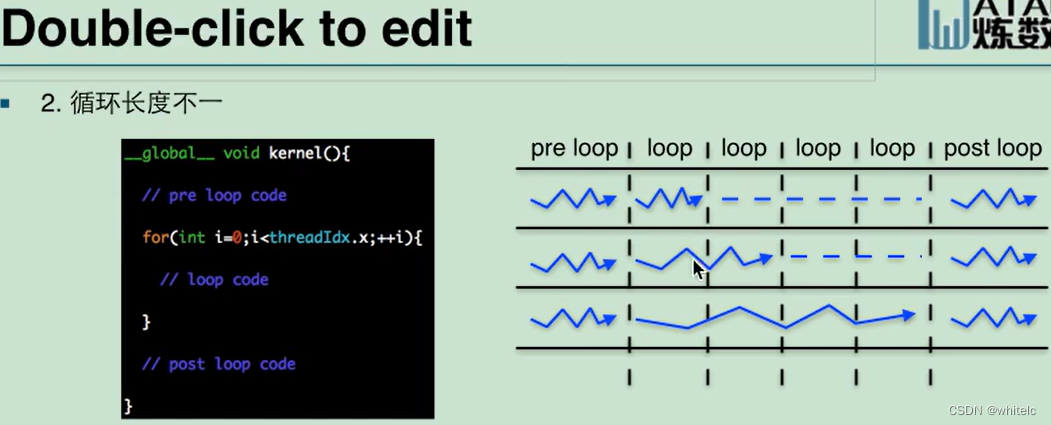
每个线程执行的次数不一样,一号线程执行一次loop,二号线程执行两次loop.
2 cuda各种内存的代码使用
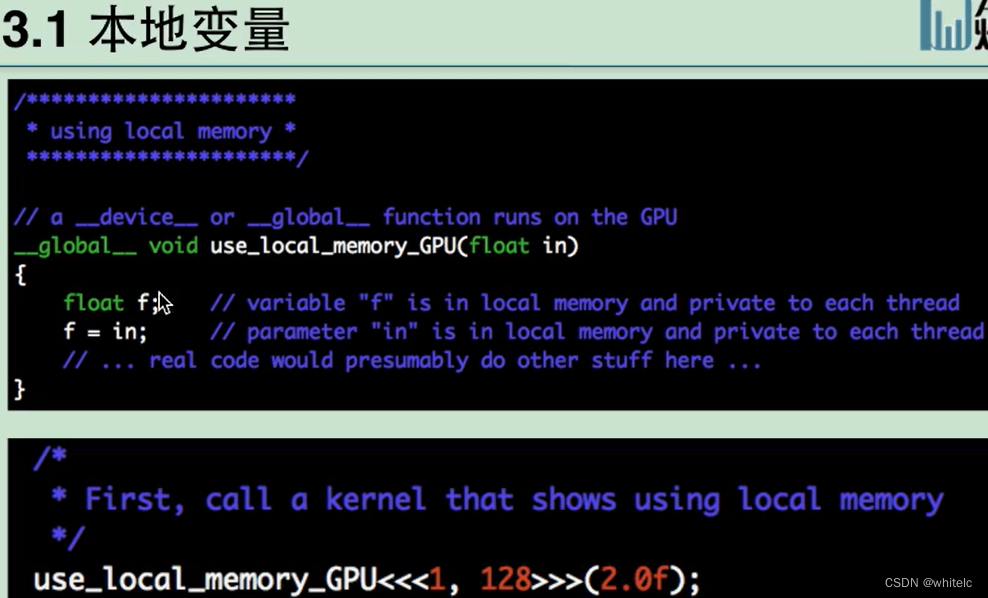
本地变量,直接在kernel里面定义初始化,使用
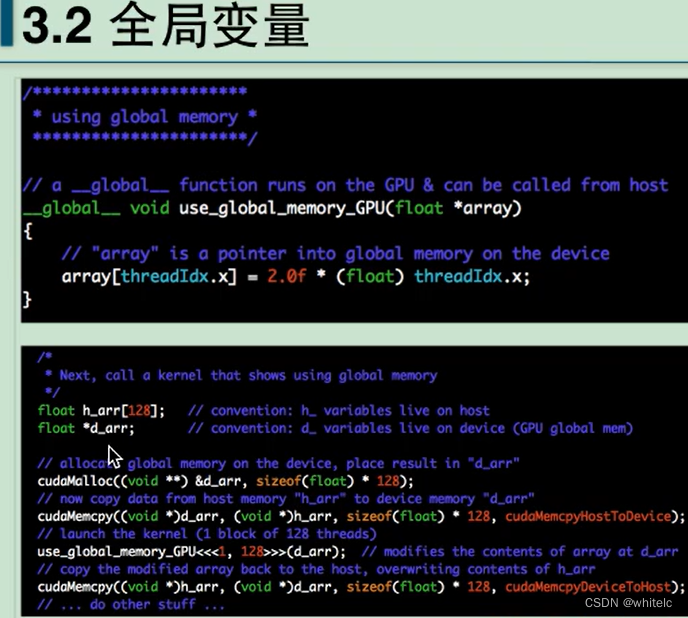
全局变量都是使用指针去执行的,必须进行数据copy
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









