







 本文详细介绍了Redis中的常用数据结构如String、List、Hash、Set和Sorted Set的API及应用场景。重点讨论了Bitmap在统计用户登录天数和活动大库存货优化中的应用,以及Redis的优化机制,如原子性操作、二进制安全和内存管理。同时,提到了List作为双向链表实现的栈和队列功能,以及Hash在点赞、收藏等场景的应用。
本文详细介绍了Redis中的常用数据结构如String、List、Hash、Set和Sorted Set的API及应用场景。重点讨论了Bitmap在统计用户登录天数和活动大库存货优化中的应用,以及Redis的优化机制,如原子性操作、二进制安全和内存管理。同时,提到了List作为双向链表实现的栈和队列功能,以及Hash在点赞、收藏等场景的应用。
本章讲解的是redis的常用API和常见的场景,如下图所示
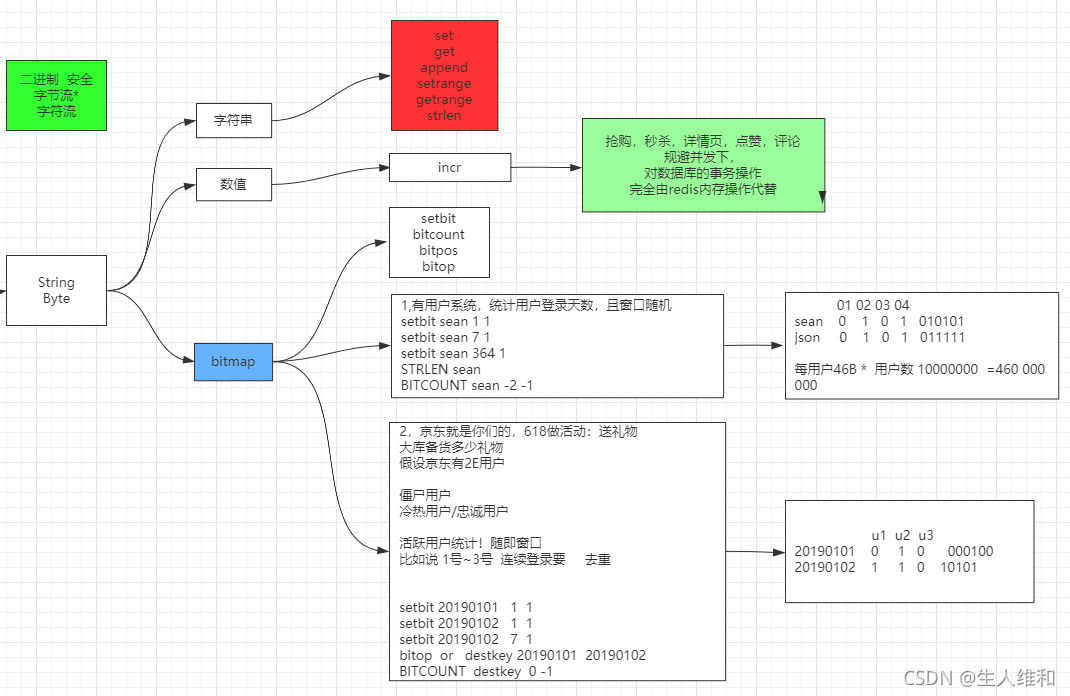
一、string
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tAPvxPQa-1638175993971)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128202540989.png)]](https://i-blog.csdnimg.cn/blog_migrate/2eeb0e4c1947f781094fd552743ea1ff.png)
1.字符串(值的基本操作)
1.set(NX|XX)方法
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mTv3fgFD-1638175993977)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/1638000624143.png)]](https://i-blog.csdnimg.cn/blog_migrate/1ef26e5f21381f7f6307086bce6e012e.png)
- 默认 有key覆盖,没key就创建
NX Only set the key if it does not already exist. -只能新建 - XX Only set the key if it already exist. -只能更新
2.mset和mget
msetnx(原子性操作)
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7GnrCeu8-1638175993980)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/1638000926518.png)]](https://i-blog.csdnimg.cn/blog_migrate/abcca4db945dc270c1a7cdfbf8514875.png)
3.append
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ygPvd8gu-1638175993982)(redis的value类型解析.assets/1638001173047.png)]](https://i-blog.csdnimg.cn/blog_migrate/3947ddb7ec1ea55f27a0af92ffcbe507.png)
4.setrange和getrange
-
正反向索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IsO9ZKpy-1638175993982)(redis的value类型解析.assets/1638001545120.png)]](https://i-blog.csdnimg.cn/blog_migrate/1b5c4d3c592826e4ff56fff7e8f0d715.png)
setrange中如果set的value值长度大于原来的值,会改变key长度并添加
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vfsWSNIU-1638175993983)(redis的value类型解析.assets/1638002224112.png)]](https://i-blog.csdnimg.cn/blog_migrate/215c8099817ac63646810e41ef3b5e5b.png)
5.strlen
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X3t4ectl-1638175993984)(redis的value类型解析.assets/1638002458992.png)]](https://i-blog.csdnimg.cn/blog_migrate/57c4236f6f42b74f6737bd773a675d3c.png)
2.数值
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r0FZHtH0-1638175993985)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128202557080.png)]](https://i-blog.csdnimg.cn/blog_migrate/887ac857141c024326607f48362e3f0d.png)
1.redis的优化机制
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UXotfaK7-1638175993986)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128151649493.png)]](https://i-blog.csdnimg.cn/blog_migrate/fcfc770919506cb6101c9d6c0fa78ff5.png)
(1) type
对于每个key都有一个type
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pe83hBZw-1638175993988)(redis的value类型解析.assets/1638003274165.png)]](https://i-blog.csdnimg.cn/blog_migrate/642f6251f5c34c4d05af3bf966920628.png)
命令是哪个分组的,set之后的value就是哪个类型的
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T9dLy845-1638175993989)(redis的value类型解析.assets/1638003845796.png)]](https://i-blog.csdnimg.cn/blog_migrate/7e51455e543a394097412a104f8715fa.png)
(2)encoding
随着不同的api操作encoding会改变
1.int
这里的set进去的string类型的k2的encoding是int类型,因为它的value是一个数值99,所以通过判断encoding类型我们还可以进行数值对应的api操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZdQdRtJw-1638175993990)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128151433771.png)]](https://i-blog.csdnimg.cn/blog_migrate/613d8c431d5d436fd8f8e3c8d054985b.png)
2.embstr
3.raw
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ycHgsGws-1638175993991)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128154528738.png)]](https://i-blog.csdnimg.cn/blog_migrate/77a0c7b0e119122104758ecacc692c6d.png)
(3)原子性操作
mgetset原子性操作,通过一个命令进行一次通信,减少了一次通信该过程,减少了IO
(4)二进制安全
流分为字节流和字符流.
redis传输走的是字节流,只要双方有一致的编解码,数据就不会破坏,不会影响数据的存储
set k1 99
那么它会事先判断能否数字计算,如果能encoding就是int类型
下次调用加减的时候就可以少进行一次判断,提高性能,但他底层还是二进制进行加减的
如下图,分别在k2和k3中存入了UTF8和GBK格式的’中’,启动客户端不加–raw的话就默认为asscii码,加了就是本地的编码
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HzhU7UEH-1638175993992)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128155633153.png)]](https://i-blog.csdnimg.cn/blog_migrate/fc027231b18fd5e5ad78c39c541b783c.png)
2.APi
(1).incr,incrby和incrbyfloat
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I9EQMxdN-1638175993993)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128152434516.png)]](https://i-blog.csdnimg.cn/blog_migrate/1cf024127dab7ff67bed7f7896c07b66.png)
(2).decr,decrby
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HOPCLhyt-1638175993993)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128152528523.png)]](https://i-blog.csdnimg.cn/blog_migrate/faff4525224a2fa08c2e0cd070752f95.png)
3.bitmap(重要)
bitmap算得上redis的核心了,常见场景如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eDyeIiwE-1638175993994)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128202637232.png)]](https://i-blog.csdnimg.cn/blog_migrate/480f0b90337a9a6041e2e714e80aa7b8.png)
1.常见场景
-
场景一:有用户系统,统计用户登录天数,且窗口随机(在某个范围内统计用户登录的天数)
解决方式1 : 通过mysql存表查询获取
解决方式2 : 通过redis操作解决(计算速度快,节省磁盘空间)
指令: 1.设置天数 setbit sean 1 1 setbit sean 7 1 setbit sean 364 1 strlen sean // 长度 2.统计某个范围的天数(一个字节代表能表示8天) bitcount sean -2 -1 通过上述设置可得到结果在redis存储 日期(第几天): 1 2 3 4 5 6 7 8 9 10 ... jack 0 1 0 1 0 1 0 1 0 1 ... tom 1 1 0 1 0 1 1 0 0 0 ... -
场景二:618做活动送礼物,大库备货多少礼物?假设有2亿用户
账号存在僵尸用户(冷热用户/忠诚用户)
步骤:
-
统计活跃用户(随机窗口)
比如统计 2-3号都登陆的, 连续登录要去重
key为天数,bit每一位代表一个用户,做或预算之后在统计
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9sCUqMsO-1638175993995)(redis的value类型解析.assets/1638154213403.png)]](https://i-blog.csdnimg.cn/blog_migrate/9b00cfa6b543932490fd9f64c20dd614.png)
-
2.API
1.setbit
基于redis的二进制安全,进行的二进制位图操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PBzYkIFp-1638175993996)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128200037607.png)]](https://i-blog.csdnimg.cn/blog_migrate/3a9cfe294e9ca74bb29a8a46f5e334f2.png)
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mKb0TnjU-1638175993997)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128195726893.png)]](https://i-blog.csdnimg.cn/blog_migrate/f82919286cee8a06a1a16bcaf9281171.png)
2.bitpos
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Q12XzbeL-1638175993999)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128201701012.png)]](https://i-blog.csdnimg.cn/blog_migrate/66cac59fbfd31cd7c081ccf4e4d00b65.png)
3.bitcount
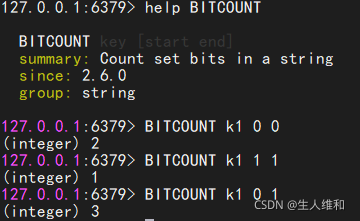
4.bittop
可以进行位操作
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IefRY0wr-1638175993999)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128202002296.png)]](https://i-blog.csdnimg.cn/blog_migrate/792f1d8b31ef1f83745cf4280746f132.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A6IpE3u9-1638175994000)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211128202257417.png)]](https://i-blog.csdnimg.cn/blog_migrate/640eecde483a9a01dbd1424007571964.png)
二、list
1.结构设计
key上面有head和tail指针,可以通过key进行快速的访问
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JHKGGn6W-1638175994001)(redis的value类型解析.assets/1638154598316.png)]](https://i-blog.csdnimg.cn/blog_migrate/3007b5e2451acb93cbfcecf137d2e168.png)
相当于一个双向链表可以实现栈,队列等命令
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xxlZV6jh-1638175994001)(redis的value类型解析.assets/1638154981515.png)]](https://i-blog.csdnimg.cn/blog_migrate/2394d5634dcf2aaed1215352c7c116fa.png)
2.API
1.lpush和rpush
2.lpop和rpop
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hGiIqYH6-1638175994002)(redis的value类型解析.assets/1638155697036.png)]](https://i-blog.csdnimg.cn/blog_migrate/71aaaff0829af9397463f414e8e91597.png)
3.lrange和rrange(array)
这里的l是指的list的意思,相当于是查找list指定索引的数据(redis有正反索引所以查找更快速)
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OKSMUeRf-1638175994003)(redis的value类型解析.assets/1638155886884.png)]](https://i-blog.csdnimg.cn/blog_migrate/9b8a53d389d15e470b0a0805756c1633.png)
4.lindex和lset(array)
单个索引获取元素
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GhDc3bC4-1638175994003)(redis的value类型解析.assets/1638156194292.png)]](https://i-blog.csdnimg.cn/blog_migrate/0301b1944e34bc1ae1ea0a105ed571ab.png)
5.lrem和linsert
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PO25gGYC-1638175994004)(redis的value类型解析.assets/1638156671341.png)]](https://i-blog.csdnimg.cn/blog_migrate/ed3321aaf78a78743e1dc7fd4c8546c8.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GgyK5nUt-1638175994005)(redis的value类型解析.assets/1638158201777.png)]](https://i-blog.csdnimg.cn/blog_migrate/0dbe3b83d58f22c420733e22a96b8a4e.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1ymbdpml-1638175994006)(redis的value类型解析.assets/1638158371343.png)]](https://i-blog.csdnimg.cn/blog_migrate/3a4fdc7570c5d7a0ee0feee3a32aed12.png)
删除k3中后面两个a:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eJoxTRNK-1638175994007)(redis的value类型解析.assets/1638167112710.png)]](https://i-blog.csdnimg.cn/blog_migrate/da9d58c2ff9cb4dfcfa4b323079396fb.png)
6.llen和ltrim
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Svt9kMaX-1638175994008)(redis的value类型解析.assets/1638170880938.png)]](https://i-blog.csdnimg.cn/blog_migrate/cd1e79c3867fd03a7b885a37d1d6d630.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QfmY0MQZ-1638175994009)(redis的value类型解析.assets/1638170861034.png)]](https://i-blog.csdnimg.cn/blog_migrate/f6be80cc1eb358286f98649336feccc4.png)
7.blpop,brpop,brpoplpush
阻塞的单播队列:
client1:
blpop key1 0
之后就会一直阻塞知道获取到key(可自定义超时时间)
client2:
blpop key1 0
client3:
blpush key1 1 ->执行之后client1获取到
blpush key1 1 ->执行之后client2获取到
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JVmyO8pV-1638175994010)(redis的value类型解析.assets/1638168037040.png)]](https://i-blog.csdnimg.cn/blog_migrate/61eba473281392453bb94c3dd50e56b0.png)
三、hash
- hash的引入原因:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mBt5PMXs-1638175994010)(redis的value类型解析.assets/1638172713521.png)]](https://i-blog.csdnimg.cn/blog_migrate/6770cdf7041d88dae6b08754c6a1e1a4.png)
1.常用场景
- 点赞,收藏,详情页(对filed进行数值的计算)
2.API
1.hset和hget
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SlfJYHRW-1638175994013)(redis的value类型解析.assets/1638172803779.png)]](https://i-blog.csdnimg.cn/blog_migrate/faedec7d9c77822f602ede4de04f032d.png)
2.hkeys,hvals,hgetall
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fnv5kLDp-1638175994013)(redis的value类型解析.assets/1638173078107.png)]](https://i-blog.csdnimg.cn/blog_migrate/7fdde04c214aae4e138cd29f6ad4f21a.png)
3.hincrby,hincrbyfloat
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K8Govcy0-1638175994014)(redis的value类型解析.assets/1638173743122.png)]](https://i-blog.csdnimg.cn/blog_migrate/2ae68f73881bac899f53fac2e6ec368c.png)
四、set
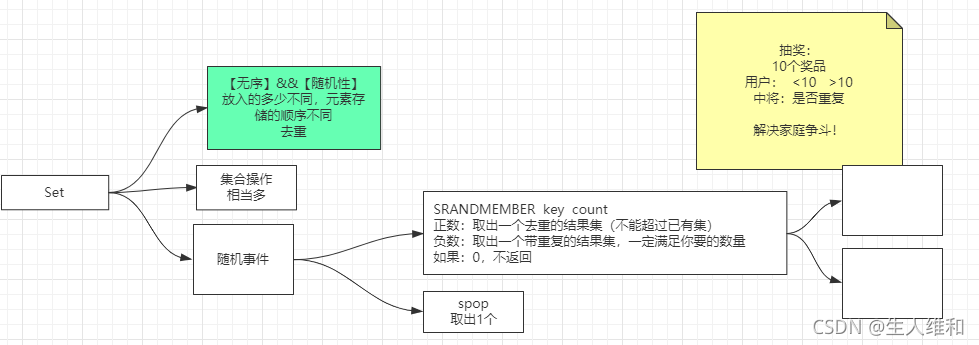
1.特性
- 无序
- 随机
- 去重
- 放入的多少不同,元素存储的顺序不同
2.常用场景
-
场景1:随机抽10个奖品?
- 用户数量是否小于奖品数量
- 用户中奖是否重复
-
解决
srandmember key count
-
正数:取出一个去重的结果集(不能超过已有集,也就是一个人最多中一件礼物)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YU6Fj7Yy-1638239499195)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129201925402.png)]](https://i-blog.csdnimg.cn/blog_migrate/2eef849e87ed7f237851235f6a46156a.png)
-
负数:取出一个带重复的结果集,一定要满足你要的数量(一个人可以中多件礼物)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-APCZVj3r-1638239499198)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129201954441.png)]](https://i-blog.csdnimg.cn/blog_migrate/aedefb8559aed67a9ea3dae6767d81d6.png)
-
0:不返回
-
3.API
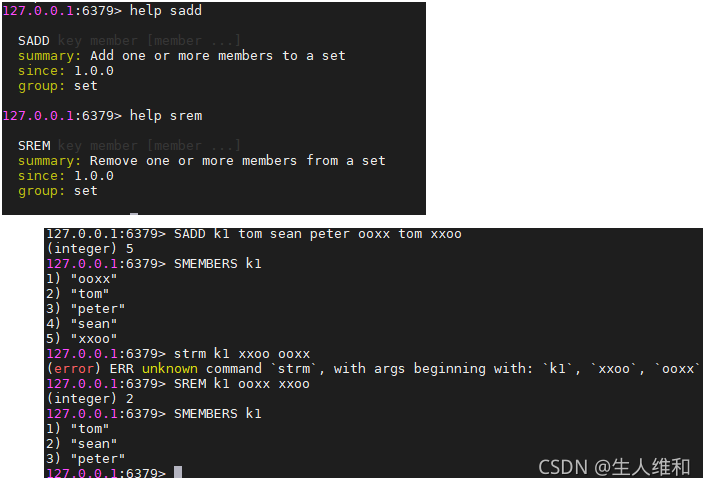
1.sadd(去重),srem,smembers
2.sinter,sinterstore(交集)
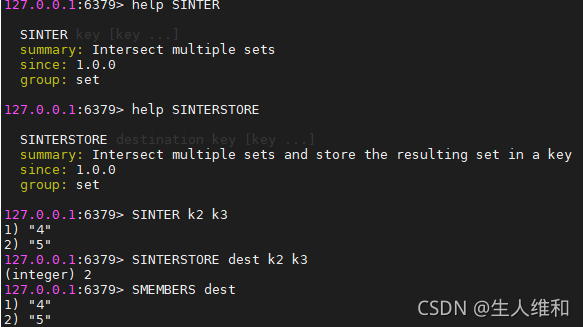
3.sunion,sunionstore(并集且去重)
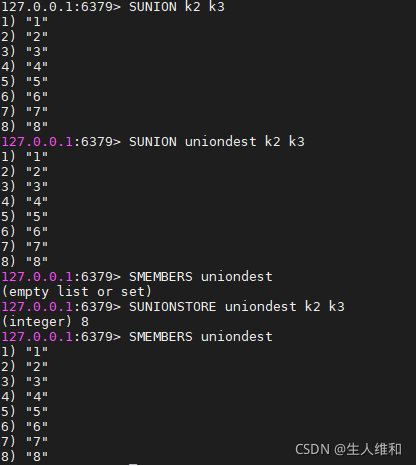
4.sdiff,sdiffstore(差集)
以第一个为基准,没有左右之分
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hBfDCXhK-1638239499205)(redis的value类型解析.assets/1638178523331.png)]](https://i-blog.csdnimg.cn/blog_migrate/31fba2f061de5447f89d21febb1f20c4.png)
5.srandmember,spop
-
srandmember
整数-随机不重复
负数-随机重复
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VbelLYC4-1638239499206)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129203224465.png)]](https://i-blog.csdnimg.cn/blog_migrate/045cbb68287ca6750524ad314b818750.png)
-
spop
随机弹出
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-x9Viq6P4-1638239499207)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129203208056.png)]](https://i-blog.csdnimg.cn/blog_migrate/20ce539ca70d72b723b5be31195791cd.png)
五、sorted_set
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GLZ7UQs8-1638239499208)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129205139379.png)]](https://i-blog.csdnimg.cn/blog_migrate/fce0ab8b4b2255c99da438ed80d93305.png)
1.概念
可以自定义进行排序,redis通过score来进行判断如何排序,
默认是左小右大顺序维护,且是实时的
也存在正反索引,都为1 则按照字典序来排列
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZWMKZLRp-1638239499209)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129211537765.png)]](https://i-blog.csdnimg.cn/blog_migrate/5a266a787a0ff01bccc64b9a54a2e165.png)
2.问题
排序是怎么实现的,增删改查的速度怎么样?
skip list (跳跃表)
-
类平衡树
-
平均值相对最优
-
插入步骤
比如我们插入一个x33
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3YbZKYDw-1638239499209)(redis的value类型解析.assets/1638239410323.png)]](https://i-blog.csdnimg.cn/blog_migrate/0a6967ea4bad60d7a159ed67b7082d94.png)
3.API
1.zadd,zrange
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i5aM0079-1638239499210)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129211845952.png)]](https://i-blog.csdnimg.cn/blog_migrate/c8a86f67d683464d5edcc50a7deefc3d.png)
2.zrangebyscore,zrevrange
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sHZiJCcr-1638239499211)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129211946576.png)]](https://i-blog.csdnimg.cn/blog_migrate/2ffaa421ff13d0fe0b3e0633c92bcfc4.png)
从小到大取出前两个: zrange k1 0 1
从大到小取出前两额: zrevrange k1 0 1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TqIArDvJ-1638239499212)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129212415472.png)]](https://i-blog.csdnimg.cn/blog_migrate/cbc8d0ec0cbe9ce65a0f8e7521f8b4a4.png)
3.zsocre,zrank
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-woloJn0i-1638239499213)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129212747620.png)]](https://i-blog.csdnimg.cn/blog_migrate/33470e73c8755617f118341fad3412f8.png)
4.zincrby
-
场景
歌曲排行榜,实时榜单,倒序
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FDToh7MC-1638239499214)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129221416280.png)]](https://i-blog.csdnimg.cn/blog_migrate/637da01f1ebf458961c154661c6c0daf.png)
5.zunionstore
- 如果不加权重和聚合函数,默认走的是权重都为1,且聚合函数为sum求和
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-22wFG9K4-1638239499215)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129222611683.png)]](https://i-blog.csdnimg.cn/blog_migrate/58f670cdea6b0aa241086857cf50e59b.png)
-
如果加上权重,不加聚合,相当于走默认的求和,权重相当于是对于原值的比例
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3M8XeNPN-1638239499216)(redis%E7%9A%84value%E7%B1%BB%E5%9E%8B%E8%A7%A3%E6%9E%90.assets/image-20211129222931630.png)]](https://i-blog.csdnimg.cn/blog_migrate/6a64a7318dc3597a1ba15975548128ce.png)

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









