






书生·浦语第五课
《LMDeploy 量化部署 LLM-VLM 实践》
链接:https://www.bilibili.com/video/BV1tr421x75B/?vd_source=7809d8a73aa5f844d7fb22527d673684
课堂笔记
-
模型部署痛点
部署到cpu?gpu?tpu?集群?移动端?
大模型参数量巨大,前向推理的计算量巨大
 内存开销巨大,需要大显存
内存开销巨大,需要大显存
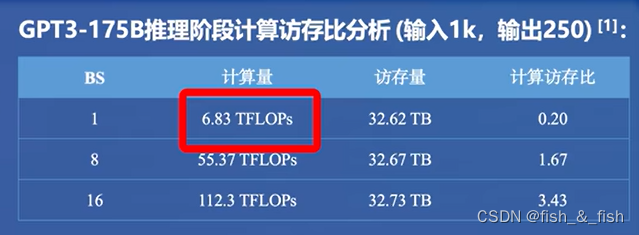
 访存密集,硬件计算速度远快于显存带宽
访存密集,硬件计算速度远快于显存带宽
 部署后使用的请求是动态的:请求量请求时间请求量不确定
部署后使用的请求是动态的:请求量请求时间请求量不确定 -
大模型部署常用方法
模型剪枝(pruning):移除不必要的组件,去除冗余参数。结构化剪枝(LLM-Pruner)[移除连接或者分层结构,一次性针对整组权重]、非结构化剪枝(Sparse、LoRAPrune、Wanda)[移除个别参数,将其余阈值的参数设置乘0]
知识蒸馏:教师学生网络(上下文学习(ICL)、思维链(CoT)、指令跟随(IF))
量化(quantization):将浮点数转换成整数或者其他离散形式。量化感知训练(QAT:LLM-QAT,量化目标集成到模型训练中)、量化感知微调(QAF:PEQA、QLoRA,微调时量化)、训练后量化(PTQ:LLM.int8、AWQ) -
LMDeploy
三个核心功能:模型高校推理、模型量化压缩、服务化部署
作业
配置 LMDeploy 运行环境
 使用原生Transformer库运行模型,非常慢
使用原生Transformer库运行模型,非常慢

 使用LMDeploy,非常快
使用LMDeploy,非常快


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









