




文章目录
前言
本章节主要描述GCC后端常见的几种优化。
一、指令优化
1. GCC中常见优化
- fold-const-call.cc 实现了常量折叠
- builtins.cc/buitins.def 实现了通用内联函数
1.1 寄存器的分配
- reginfo.cc
- init_reg_sets 初始化目标机器的硬件寄存器堆
- 定义subreg,参考init_subregs_of_mode(),比如在E extension下限值寄存器的使用。
- ira.cc[h]
- 这个文件涉及了整数寄存器分配算法,
FIRST_VIRTUAL_REGISTER和LAST_VIRTUAL_REGISTER用于定义伪寄存器,宏REG_ALLOC_ORDER用来定义寄存器的分配顺序 Short * reg_renumber用于映射伪寄存器到真实寄存器,会被local allocator和global allocator多次修改
- 这个文件涉及了整数寄存器分配算法,
- ira-color.cc 寄存器染色算法
- reload.cc
- 在reload过程中,首先将分配了硬件寄存器的伪寄存器用硬件寄存器替代;同时,这个过程会检查每条指令中的寄存器是否符合指令对寄存器类的要求,如果不符合则产生mov指令解决这个问题;然后试图用栈指针寄存器替代其它指针寄存器,减少寻址中寄存器的开销;最后,这个过程通过插入load、store指令处理在全局寄存器分配中欧溢出到存储器的伪寄存器,在每次引用伪寄存器的地方插入load指令,每次重新对该伪寄存器复制的地方插入store指令。
二、流水优化/指令调度
1.流水线优化配置
1.1 流水线特征描述
流水线特征包括了定义指令latency、保留执行单元、指令对之间的latency、定义不同的流水单元等。
- 定义自动机
格式:(define_automaton names)
这里可以定义多个name,这些name会被定义的CPU单元所使用。 - 定义单挑指令的latency和保留执行单元
格式:(define_insn_reservation insn_name default_latency condtion regexp)
(define_insn_reservation "generic_alu" 1
(and (eq_attr "tune" "generic")
(eq_attr "type" "unknown,const,arith,shift,slt,multi,auipc,nop,logical,move,bitmanip,min,max,minu,maxu,clz,ctz,cpop"))
"alu")
(define_insn_reservation "generic_load" 3
(and (eq_attr "tune" "generic")
(eq_attr "type" "load,fpload"))
"alu")
- insn_name 和define_bypass 相关
- 针对不同的target,TARGET_SCHED_ADJUST_COST用于改变默认的latency
- condition定义什么样的RTL指令适用该规则
- regexp描述该指令用于什么样的运算单元
- 定义指令对之间的执行单元
格式:(define_bypass number out_insn_name in_insn_name [guard])
(define_bypass 1 "cpu1_load_*, cpu1_store_*" "cpu1_load_*")
- NUMBER 定义了两条指令对之间的latency,其反应了一条指令in_insn_name 需要等待另一条指令out_insn_name 的结果产生
- guard是一个可选字符串,给出了一个C函数名称,该函数定义了一个附加的处理过程
- 定义不同的流水线单元
格式:(define_cpu_unit unit_name)
(define_cpu_unit "sifive_7_A" "sifive_7")
(define_cpu_unit "sifive_7_B" "sifive_7")
(define_insn_reservation "sifive_7_load" 3
(and (eq_attr "tune" "sifive_7")
(eq_attr "type" "load"))
"sifive_7_A")
(define_insn_reservation "sifive_7_branch" 1
(and (eq_attr "tune" "sifive_7")
(eq_attr "type" "branch"))
"sifive_7_B")
这里定义的流水单元结合define_insn_reservation让指令绑定在特定的单元上,并且可以指定多个单元
考虑到一个超标量CPU可以发出三条指令(两个整数insn和一个浮点insn),但只能完成两个insn。对此定义如下的功能单元
(define_cpu_unit "i0_pipeline, i1_pipeline, f_pipeline")
(define_cpu_unit "port0, port1")
- 定义指令的延迟槽(delay slot)
格式:(define_delay test [delay-1 annul-true-1 annul-false-1 delay-2 annul-true-2 annul-false-2 ...] )
1.2 编译器看待冲突问题(冲突带来的延迟)
- 数据依赖
用常量来定义两条指令之间的数据依赖造成的延迟 - Reservation dependency(resource dependency)
由于两条指令共享处理器资源,如bus、内部寄存器、功能单元等资源依赖造成的延迟,分为三类:- 真依赖(True Dependency):真依赖也称为读后写(Read After Write,RAW)依赖。当一个指令需要读取另一个指令刚刚写入的数据时,就存在真依赖。这种依赖关系是最常见的数据依赖类型。例如,指令A写入一个寄存器,而指令B需要读取该寄存器的值。为了保证正确的执行顺序,指令B必须在指令A之后执行。
- 反依赖(Anti-dependency):反依赖也称为写后读(Write After Read,WAR)依赖。当一个指令需要在另一个指令读取数据之前写入相同的数据时,就存在反依赖。这种依赖关系通常发生在寄存器重命名等技术被使用的情况下。例如,指令A读取一个寄存器的值,而指令B需要在指令A读取之前将相同的寄存器写入新的值。为了保证正确的执行顺序,指令B必须在指令A之前执行。
- 输出依赖(Output Dependency):输出依赖也称为写后写(Write After Write,WAW)依赖。当一个指令需要在另一个指令写入数据之前写入相同的数据时,就存在输出依赖。这种依赖关系通常发生在多个指令同时写入相同的目标位置时。例如,指令A和指令B都需要写入同一个寄存器。为了保证正确的执行顺序,指令B必须在指令A之后执行。
特定CPU的优化配置
调度优化
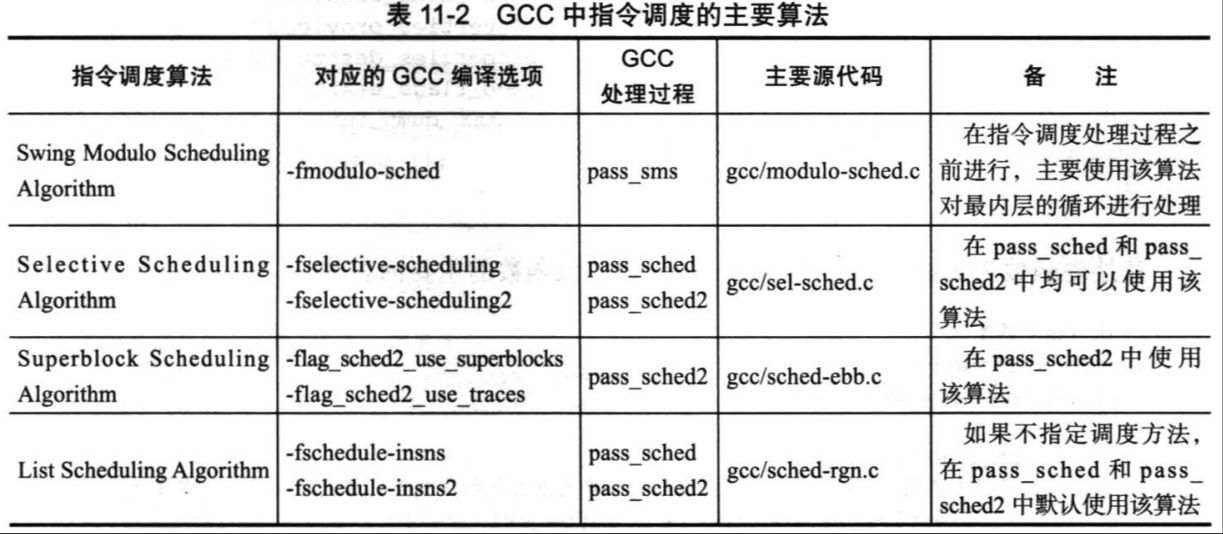
pass_sms,pass_sched,pass_sched2和pass_sched_fusion是GCC中的四种指令调度pass,后面三个pass的默认核心函数都是schedule_insn()
void schedule_insns (void) {
rgn_setup_common_sched_info ();
rgn_setup_sched_infos ();
......
/* Schedule every region in the subroutine. */
for (rgn = 0; rgn < nr_regions; rgn++)
if (dbg_cnt (sched_region))
schedule_region (rgn);
......
}
指令调度状态机
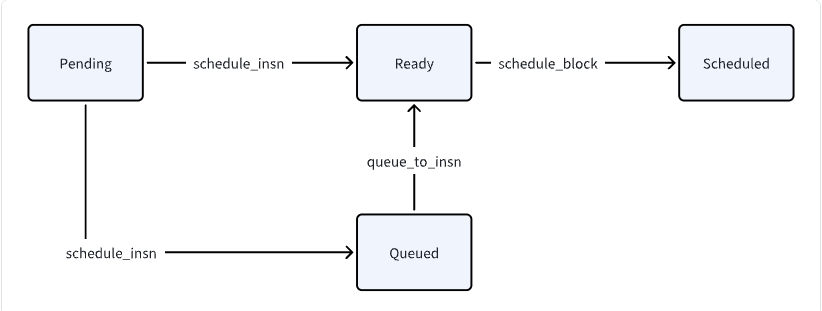
在调度过程中,一条指令通常处于四种状态中的一种:
- P: the “Pending” set of insns which can not be scheduled until their dependencies have been satisfied.
- Q: the “Queued” set of insns that can be scheduled when sufficient time has passed.
- R: the “Ready” list of unscheduled, uncommitted insns.
- S: the “Scheduled” list of insns.
The transition (R->S) is implemented in the scheduling loop inschedule_block' when the best insn to schedule is chosen. The transitions (P->R and P->Q) are implemented inschedule_insn’ as insns move from the ready list to the scheduled list.
The transition (Q->R) is implemented in ‘queue_to_insn’ as time passes or stalls are introduced.
获取流水线配置信息
(genattrtab.cc)包含查询某些内部属性的函数集合,如Tune属性:
/* Check that attribute NAME is used in define_insn_reservation condition
EXP. Return true if it is. */
static bool check_tune_attr (const char *name, rtx exp);
/* Try to find a const attribute (usually cpu or tune) that is used
in all define_insn_reservation conditions. */
static bool find_tune_attr (rtx exp);
genautomata.cc包含了处理define_automaton和define_insn_reservation等模板的函数集合:
/* The function creates DFA(s) for fast pipeline hazards recognition
after checking and simplifying IR of the description. */
static void create_automata (void);
/* Process a DEFINE_INSN_RESERVATION.
This gives information about the reservation of cpu units by an
insn. We fill a struct insn_reserv_decl with information used
later by `expand_automata'. */
static void gen_insn_reserv (md_rtx_info *info);
......
#define GET_CPU_UNIT_CODE_FUNC_NAME "get_cpu_unit_code"
#define CPU_UNIT_RESERVATION_P_FUNC_NAME "cpu_unit_reservation_p"
#define INSN_HAS_DFA_RESERVATION_P_FUNC_NAME "insn_has_dfa_reservation_p"
......
计算指令间依赖关系
(sched-deps.cc)
/* Find a dependency between producer PRO and consumer CON.
Use dependency [if available] to check if dependency is present at all.
Search through resolved dependency lists if RESOLVED_P is true.
If the dependency or NULL if none found. */
dep_t
sd_find_dep_between (rtx pro, rtx con, bool resolved_p)
{
if (true_dependency_cache != NULL)
/* Avoiding the list walk below can cut compile times dramatically
for some code. */
{
int elem_luid = INSN_LUID (pro);
int insn_luid = INSN_LUID (con);
if (!bitmap_bit_p (&true_dependency_cache[insn_luid], elem_luid)
&& !bitmap_bit_p (&output_dependency_cache[insn_luid], elem_luid)
&& !bitmap_bit_p (&anti_dependency_cache[insn_luid], elem_luid)
&& !bitmap_bit_p (&control_dependency_cache[insn_luid], elem_luid))
return NULL;
}
return sd_find_dep_between_no_cache (pro, con, resolved_p, NULL);
}
schedule_block
/* This records the actual schedule. It is built up during the main phase
of schedule_block, and afterwards used to reorder the insns in the RTL. */
static vec<rtx_insn *> scheduled_insns;
/* A structure that holds local state for the loop in schedule_block. */
struct sched_block_state
{
/* True if no real insns have been scheduled in the current cycle. */
bool first_cycle_insn_p;
/* True if a shadow insn has been scheduled in the current cycle, which
means that no more normal insns can be issued. */
bool shadows_only_p;
/* True if we're winding down a modulo schedule, which means that we only
issue insns with INSN_EXACT_TICK set. */
bool modulo_epilogue;
/* Initialized with the machine's issue rate every cycle, and updated
by calls to the variable_issue hook. */
int can_issue_more;
};
总结
GCC中的优化总体来说比较规整,定义也都比较方便(普遍是可以通过宏定义来完成)。

















 1337
1337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









