






 本文介绍了Java中ForkJoin的相关知识,它可将任务划分成小任务让多线程并行执行,使用递归算法和分治思想,核心是工作窃取。还给出了ForkJoin的使用步骤和代码示例,并比较了普通For循环、ForkJoin和Stream并行流求1~10亿总和的效率,结果是Stream流>for循环>ForkJoin。
本文介绍了Java中ForkJoin的相关知识,它可将任务划分成小任务让多线程并行执行,使用递归算法和分治思想,核心是工作窃取。还给出了ForkJoin的使用步骤和代码示例,并比较了普通For循环、ForkJoin和Stream并行流求1~10亿总和的效率,结果是Stream流>for循环>ForkJoin。
1. ForkJoin简介
ForkJoin的作用是将一个任务划分成多个小任务,让多个线程去并行执行一个任务,在一些高并发的场景可能会用到
ForkJoin框架提供了一个ForkJoinPool (ForkJoin线程池),当任务没有指定线程的时候,就会使用默认的ForkJoin线程池
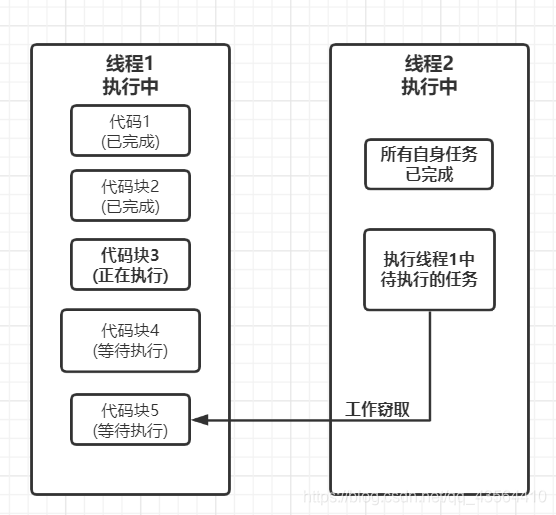
ForkJoin使用了递归算法和分治思想,Forkjoin需要在多核cpu下才会奏效,因为使用的是并行处理的方式,核心思想是工作窃取
工作窃取
当一个线程执行完任务后,去窃取其他线程的任务做
2. ForkJoin的使用
使用步骤
(1) 创建一个任务类继承 RecursiveTask抽象类,并重写里面的compute() 方法,在compute()中使用递归算法、分治思想
(2) 在主方法中的操作
① 创建ForkJoin线程池(new ForkJoinPool())
② 将任务提交给线程池 ForkJoinTask sumbit = forkJoinPool.summit();
③ 获取结果 (submit.get())
代码示例
(求1~10亿总和的值)
//(1) 继承RecursiveTask抽象类,重写compute()方法(使用递归算法)
public class MyForkJoinTask extends RecursiveTask<Long>{
//记录线程开始的值
private Long startValue;
//记录结束的值
private Long endValue;
//最小拆分的值
private Long MAX = 100_0000L;
MyForkJoinTask(Long startValue,Long endValue){
this.startValue = startValue;
this.endValue = endValue;
}
@Override
protected Long compute() {
Long res=0L;
//如果拆分的值小于max了,则开始任务
if(endValue-startValue<MAX){
// System.out.println("任务开始的值:"+startValue+"====任务结束的值:"+endValue);
res = 0L;
for (long i = startValue; i < endValue; i++) {
res+=i;
}
}
//如果拆分的值比max大,则继续拆分
else {
//将前一半的任务给joinTask1
MyForkJoinTask joinTask1 = new MyForkJoinTask(startValue,(startValue+endValue)/2);
//将后一半任务给joinTask2
MyForkJoinTask joinTask2 = new MyForkJoinTask((startValue+endValue)/2,endValue);
//同时开启任务线程1和线程2
invokeAll(joinTask1,joinTask2);
return joinTask1.join()+joinTask2.join();
}
return res;
}
//2. 主方法中使用ForkJoin
public static void main(){
//获取开始时间
long start = System.currentTimeMillis();
Long res=0L;
//(1) 创建ForkJoin的线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
//(2) 开启任务
ForkJoinTask<Long> submit = forkJoinPool.submit(new MyForkJoinTask(1L, 10_0000_0000L));
try {
//(3) 获取结果
res = submit.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("ForkJoin方式的结果是:"+res);
System.out.println("花费的时间是:"+(end-start));
}
}
3. 三种方式的效率比较
比较求1~10亿总和的运行时间
(1) 普通方式(For循环)
public static void normal(){
//获取开始时间
long start = System.currentTimeMillis();
long res=0;
for (int i = 0; i < 10_0000_0000; i++) {
res+=i;
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("普通方式的结果是:"+res);
System.out.println("花费的时间是:"+(end-start));
System.out.println("==============");
}
(2) ForkJoin
public static void forkJoin(){
//获取开始时间
long start = System.currentTimeMillis();
Long res=0L;
//1. 创建ForkJoin的线程池
ForkJoinPool forkJoinPool = new ForkJoinPool();
//2. 开启任务
ForkJoinTask<Long> submit = forkJoinPool.submit(new MyForkJoinTask(1L, 10_0000_0000L));
try {
//3.获取结果
res = submit.get();
// System.out.println("结果是:"+res);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("ForkJoin方式的结果是:"+res);
System.out.println("花费的时间是:"+(end-start));
System.out.println("========================");
}
(3) Stream并行流
public static void testStream(){
Long start = System.currentTimeMillis();
//parallel表示并行运算 Long::sum调用Long下的求和方法
Long res = LongStream.range(0,10_0000_0000L).parallel().reduce(0,Long::sum);
Long end= System.currentTimeMillis();
System.out.println("stram流方式的结果是:"+res);
System.out.println("花费的时间是:"+(end-start));
}
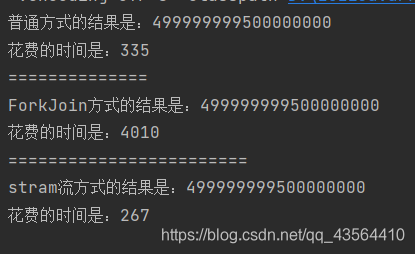
运行效率 Stream流>for循环>ForkJoin
可能是算法不好导致ForkJoin比for循环慢,不大理解这一点

















 2337
2337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









