







计算机里只有数字,计算机软件里的一切都是用数字来表示,屏幕上显示的一个个字符也不例外。
最开始计算机是在美国使用,当时所用到的字符也就是现在键盘上的一些符号和少数几个特殊的符号,每一个字符都用一个数字来表示,一个字节所能表示的数字范围内(0~255)足以容纳所有的字符,实际上表示这些字符的数字的字节最高位(bit)都为0,也就是说这些数字都在0~127之间,如字符a对应数字97,字符b对应数字98等,这种字符与数字对应的编码固定下来后,这套编码规则被称为ASCII码(美国标准信息交换码),如下图所示。

随着计算机在其他国家的逐渐应用和普及,许多国家都把本地的字符集引入了计算机,这大大地扩展了计算机中字符的范围。一个字节所能表示的数字范围(仅仅256个字符)是不能容纳所有的中文汉字的(注:《汉语大字典》收字共54678个)。
中国大陆将每一个中文字符都用两个字节的数字来表示(这样,在理论上,可以表示256×256=65536个汉字,够汉字用了!),在这个编码机制里,原有的ASCII码字符的编码保持不变,仍用一个字节表示。 为了将一个中文字符与两个ASCII码字符相区别,中文字符的每个字节的最高位(bit)都为1,中国大陆为每一个中文字符都指定了一个对应的数字(由于两个字节的最高位都被占用,所以两个字节所能表示的汉字数量理论数为:27×27=16384,有些偏僻的汉字就没有被编码,从而计算机就无法显示和打印),并作为标准的编码固定了下来,这套编码规则称为GBK(国标扩展码,GBK就是“国标扩”的汉语拼音首字母)。
后来又在GBK的基础上对更多的中文字符(包括繁体)进行了编码,新的编码系统就是GB 2312,而GBK则是GB 2312的子集(事实上,GB 2312 也仅仅收录 6763 个常用汉字,仅仅适用于简体中文字)。使用中文的国家和地区很多,同样的一个字符,如“中国”的“中”字,在中国大陆地区的编码是十六进制的D6D0,而在中国台湾地区的编码则是十六进制的A4A4,台湾地区对中文字符集的编码规则称为BIG5(大五码),如下图所示。

在一个国家的本地化系统中出现的一个字符,通过电子邮件传送到另外一个国家的本地化系统中,看到的就不是那个原始字符了,而是另外那个国家的一个字符或乱码。
这是因为计算机里面并没有真正的字符,字符都是以数字的形式存在的,通过邮件传送一个字符,实际上传送的是这个字符对应的编码数字,同一个数字在不同的国家和地区代表的很可能是不同的符号。如十六进制的D6D0在中国大陆的本地化系统中显示为“中”这个符号,但在伊拉克的本地化系统中就不知道对应的是一个什么样的伊拉克字符了,反正人们看到的不是“中”这个符号。各个国家和地区都使用各自不同的本地化字符编码,这严重制约了国家和地区间在计算机使用和技术方面的交流。
为了解决各个国家和地区使用各自不同的本地化字符编码带来的不便,人们将全世界所有的符号进行了统一编码,称之为Unicode编码。所有的字符不再区分国家和地区,都是人类共有的符号,如“中国”的“中”这个符号,在全世界的任何一个角落始终对应的都是一个十六进制的数字4E2D。如果所有的计算机系统都使用这种编码方式,在中国大陆的本地化系统中显示的“中”这个符号,发送到德国的本地化系统中,显示的仍然是“中”这个符号,至于那个德国人能不能认识这个符号,就不是计算机所要解决的问题了。
Unicode编码的字符都占用两个字节的大小,也就是说全世界所有的字符个数不会超过2的16次方(65536)。
Unicode一统天下的局面暂时还难以形成,在相当长的一段时期内,人们看到的都是本地化字符编码与Unicode编码共存的景象。既然本地化字符编码与Unicode编码共存,那就少不了涉及两者之间的转换问题,而Java中的字符使用的都是Unicode编码,Java技术在通过Unicode保证跨平台特性的前提下也支持了全扩展的本地平台字符集,而显示输出和键盘输入则都是采用的本地编码。
除了上面讲到的GB 2312/GBK和Unicode编码外,常见的编码方式还有:
ISO 8859-1编码:国际通用编码,单一字节编码,理论上可以表示出任意文字信息,但对双字节编码的中文表示,需要转码;
UTF编码:结合了ISO 8859-1和Unicode编码所产生的适合于现在网络传输的编码。考虑到Unicode编码不兼容ISO 8859-1编码,而且容易占用更多的空间:因为对于英文字母,Unicode也需要两个字节来表示。所以Unicode不便于传输和存储。因此而产生了UTF编码,UTF编码兼容ISO 8859-1编码,同时也可以用来表示所有语言的字符,但UTF编码是不等长编码,每一个字符的长度从1~6个字节不等。一般来讲,英文字母还是用一个字节表示,而汉字则使用三个字节。此外,UTF编码还自带了简单的校验功能。
那么清楚了编码之后,就需要来解释什么叫乱码:编码和解码不统一。
那么如果要想在开发之中处理乱码,那么首先就需要知道在本机默认的编码是什么。通过下面的程序,来看一下到底什么是字符乱码问题。在这里使用String类中的get Bytes()方法,对字符进行编码转换。
【示例1】
package com.xy.io;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class EncodingDemo {
public static void main(String[] args) throws Exception {
// 将字符串通过getBytes()方法,编码为GB2312
byte[] b = "大家一起来学Java语言".getBytes();
OutputStream out = new FileOutputStream(new File("d:" + File.separator + "encoding.txt"));
out.write(b);
out.close();
}
}
【结果】

【示例2】:设置文件字符编码
package com.xy.io;
public class SetEncodingDemo {
public static void main(String[] args) {
/* 该方法返回一个属性Properties对象,
* 类Properties继承自Hashtable类,
* 而Hashtable类用于put()方法。
* 该方法的原型是put(K key, V value),
* 其功能是在hash表中将特定的键值(key)映射为特定的值(value)。
* 在这里,是将键file. encoding(文件编码)映射值为"GB2312"。
*/
System.getProperties().put("file.encoding", "GB2312");
}
}
执行 【示例2】 后,再运行 【示例3】 ,修改后的程序如下:
package com.xy.io;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
public class SetEncodingDemo2 {
public static void main(String[] args) throws IOException {
// 将字符串通过getBytes()方法,编码成ISO8859-1
byte[] b = "大家一起来学Java语言".getBytes("ISO8859-1");
OutputStream out = new FileOutputStream(new File("d:" + File.separator + "encoding.txt"));
out.write(b);
out.close();
}
}
【结果】
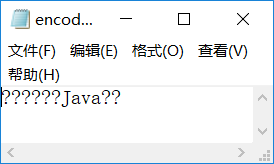
由上图可以看到,非英文部分的字符,输出结果出现了乱码,这就是本节要讨论的字符编码问题。之所以会产生这样的问题,是因为在运行这段代码之前,先运行了 【示例2】 程序,此程序主要是用来设置JDK环境的编码问题,所以乱码问题主要是由于JDK设置环境所引起的,为什么呢?读者可以运行下面的程序,观察其输出就可以发现问题。
【示例4】
package com.xy.io;
public class GetEncoding {
public static void main(String[] args) {
System.getProperties().list(System.out);
}
}
【结果】
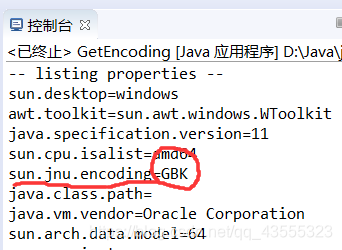
【示例4】 中,获取系统的属性,并用list()方法全部输出。从输出结果可以看到,在环境变量之中有一个file.encoding=GBK,这清楚地表明了所使用的是GBK编码,而修改过的 【示例3】 程序中的:
byte[] b = "大家一起来学Java语言".getBytes("ISO8859-1") ;
在这里将字符串“大家一起来学Java语言”的编码换成了ISO8859-1编码。 ISO 8859-1 通常叫做Latin-1,属于单字节编码,最多能表示的字符范围是0~255,其适用于拉丁语系,很明显,ISO 8859-1编码表示的字符范围很窄,无法表示双字节编码的中文字符,所以就造成了 【示例3】 里的中文字符的乱码问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









