







 本文深入探讨了Node.js中的模块加载过程,包括路径分析、文件定位和编译执行三个阶段。核心模块和文件模块的加载机制有所区别,核心模块可直接从内存加载,而文件模块需要动态查找。路径分析涉及相对和绝对路径,文件定位时,若找不到文件会尝试查找目录并处理package.json。模块编译针对不同扩展名采取不同策略,如.js、.node和.json。Node.js通过缓存提高二次加载效率,并在编译时对模块内容进行包装,确保变量的安全和独立。
本文深入探讨了Node.js中的模块加载过程,包括路径分析、文件定位和编译执行三个阶段。核心模块和文件模块的加载机制有所区别,核心模块可直接从内存加载,而文件模块需要动态查找。路径分析涉及相对和绝对路径,文件定位时,若找不到文件会尝试查找目录并处理package.json。模块编译针对不同扩展名采取不同策略,如.js、.node和.json。Node.js通过缓存提高二次加载效率,并在编译时对模块内容进行包装,确保变量的安全和独立。
在node中模块的引入一般需要3个阶段
- 路径分析
- 文件定位
- 编译执行
在node中模块又分为两种,node自己的模块叫核心模块,还有一种是用户编写的模块叫文件模块,部分核心模块在node源代码的编译过程中就编译成了二进制执行文件,在node进程启动时就会直接加载到内存中,所以这部分核心模块可以省去文件定位和编译执行两个步骤, 而文件模块需要在运行时动态加载,需要完整的路径分析,文件定位和编译执行过程
模块加载过程
优先从文件中加载
不论是核心模块还是文件模块require()方法对相同模块的二次加载都是采用缓存优先的方式,不同之处是核心模块的缓存检查要优先于文件模块的缓存检查
路径分析和文件定位
因为标识符有几种形式,对于不同的标识符,模块的查找和定位有不同程度上的差异
模块标识符分析
require()方法需要接受一个标识符来作为参数,基于这样一个标识符进行模块查找,模块标识在node中主要分为几类
1. 核销模块,如http,fs,path等
2. . 或者… 开头的相对文件路径
2. 已/开头的绝对路径文件模块
4.非路径形式的文件模块,如自定义的connect模块
核心模块
核心模块的优先级是仅次于缓存加载的,是其加载过程最快的,如果试图加载一个和核心模块标识符相同的自定义模块,那是不会成功的,比如自己编写一个http文件模块,要想加载成功,就必须用其他不同的标识符或者换文件路径的方式
路径形式的文件模块
已.和…或/开头的标识符,这里都被当做文件模块来处理,在分享文件模块时,require()方法会将路径转为真实的路径,已真实路径作索引,将编译执行后的结构放入缓存中,使得后面的加载时更快.由于文件模块给node指明了文件的位置,所以在查找的过程中可以节约大量时间,其加载速度慢于核心模块
自定义模块
自定义模块是指非核心模块,也不是以路径形式的标识符,他是一个特殊的文件模块,可能是一个文件或者是一个包的形式,这种模块在查找时最费时,所以也是最慢的一种
文件定位
从缓存加载的优化使得二次引入时,不在进行路径分析,文件定位和编译执行的过程,大大提高了再次加载模块的效率
文件扩展名的分分析
require()方法在方法标识符的过程中,会有标识符中不包括文件扩展名的情况,如果有这种情况,node会按照js,json,node的次序补足扩展尝试.
目录分析和包
在分析过程中,require通过分析文件扩展没有找到对应的文件但是找到了一个目录,这时node就会把目录当做一个包来处理,首先去目录下的package.json中取出main对应的文件进行定位,如果没有main 或者压根就没有package,json文件,那么会默认用index当默认文件名,然后依次的是index.js,index.json,index.node,如果没有定位到就会进入下一个模块路径找,如果还是没有,那么就会抛出异常
模块编译
在node中,每个文件模块都有一个对象,它的定义如下
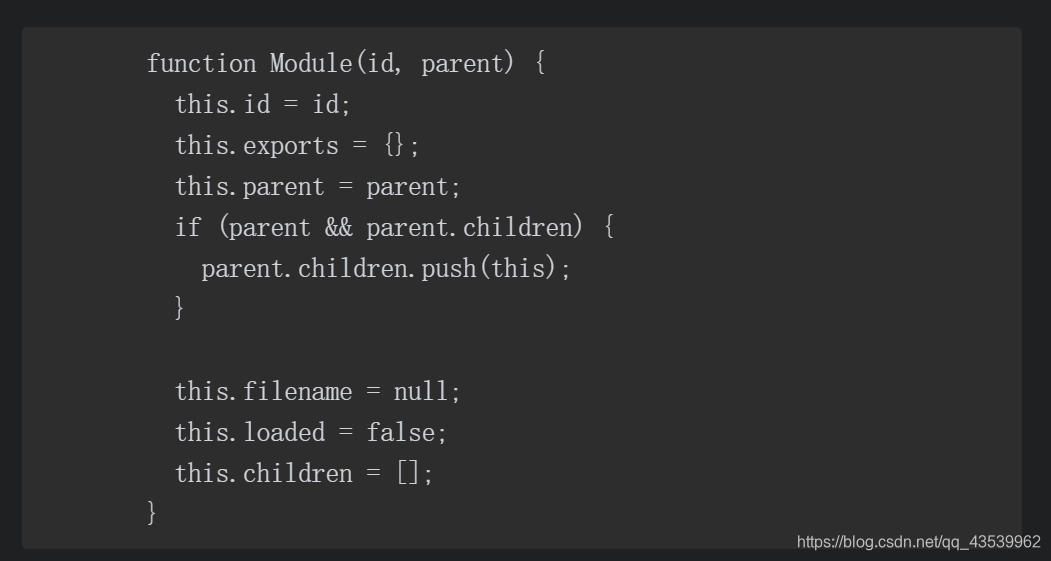
编译和执行是引入文件模块的最后一个阶段。定位到具体的文件后,Node会新建一个模块对象,然后根据路径载入并编译。对于不同的文件扩展名,其载入方法也有所不同
* .js文件。通过fs模块同步读取文件后编译执行。
* .node文件。这是用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。
*. json文件。通过fs模块同步读取文件后,用JSON.parse()解析返回结果。
* 其余扩展名文件。它们都被当做.js文件载入。
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。通过在代码中访问require.extensions可以知道系统中已有的扩展加载方式
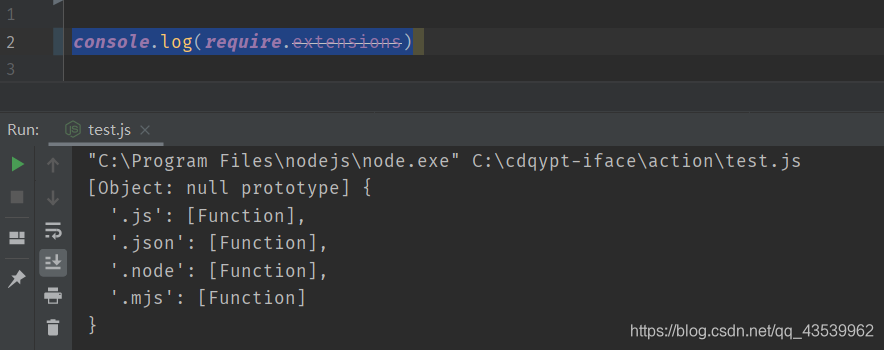
JavaScript模块的编译
每个模块文件中存在着require、exports、module这3个变量,但是它们在模块文件中并没有定义,那么从何而来呢?甚至在Node的API文档中,我们知道每个模块中还有__filename、__dirname这两个变量的存在,它们又是从何而来的呢?如果我们把直接定义模块的过程放诸在浏览器端,会存在污染全局变量的情况。事实上,在编译的过程中,Node对获取的JavaScript文件内容进行了头尾包装。在头部添加了(function (exports, require, module, __filename, __dirname){\n,在尾部添加了\n});。一个正常的JavaScript文件会被包装成如下的样子:

json编译
Node利用fs模块同步读取JSON文件的内容之后,调用JSON.parse()方法得到对象,然后将它赋给模块对象的exports,以供外部调用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









