






 本文详细介绍Scrapy框架中FilesPipeline和ImagesPipeline的使用方法,包括下载文件和图片的流程,自定义文件命名规则,以及如何生成图片缩略图。
本文详细介绍Scrapy框架中FilesPipeline和ImagesPipeline的使用方法,包括下载文件和图片的流程,自定义文件命名规则,以及如何生成图片缩略图。
FilesPipeline和ImagesPipeline
Scrapy框架内部提供了两个Item Pipeline,专门用于下载文件和图片:
- FilesPipeline
- ImagesPipeline
我们可以将这两个Item Pipeline看作特殊的下载器,用户使用时只需要通过item的一个特殊字段将要下载文件或图片的URL传递给它们,它们会自动将文件或图片下载到本地,并将下载结果信息存入到item的另一个特殊字段,以便用户在导出文件中查阅。
FilesPipeline
FilesPipeline的工作流如下:
1. 在spider中爬取要下载的文件链接,将其放置于item中的file_urls。
2. spider将其返回并传送至pipeline链。
3. 当FilesPipeline处理时,它会检测是否有file_urls字段,如果有的话,会将url传送给scarpy调度器和下载器。
4. 下载完成之后,会将结果写入item的另一字段files,files包含了文件现在的本地路径(相对于配置FILE_STORE的路径)、文件校验和checksum、文件的url
FilesPipeline的使用非常简单,我通过一个爬取实例来介绍怎样使用它。
爬取网站: matplotlib
matplotlib是一个非常著名的Python绘图库,在matplotlib网站上提供了许多应用例子代码。
网址:https://matplotlib.org/examples/index.html
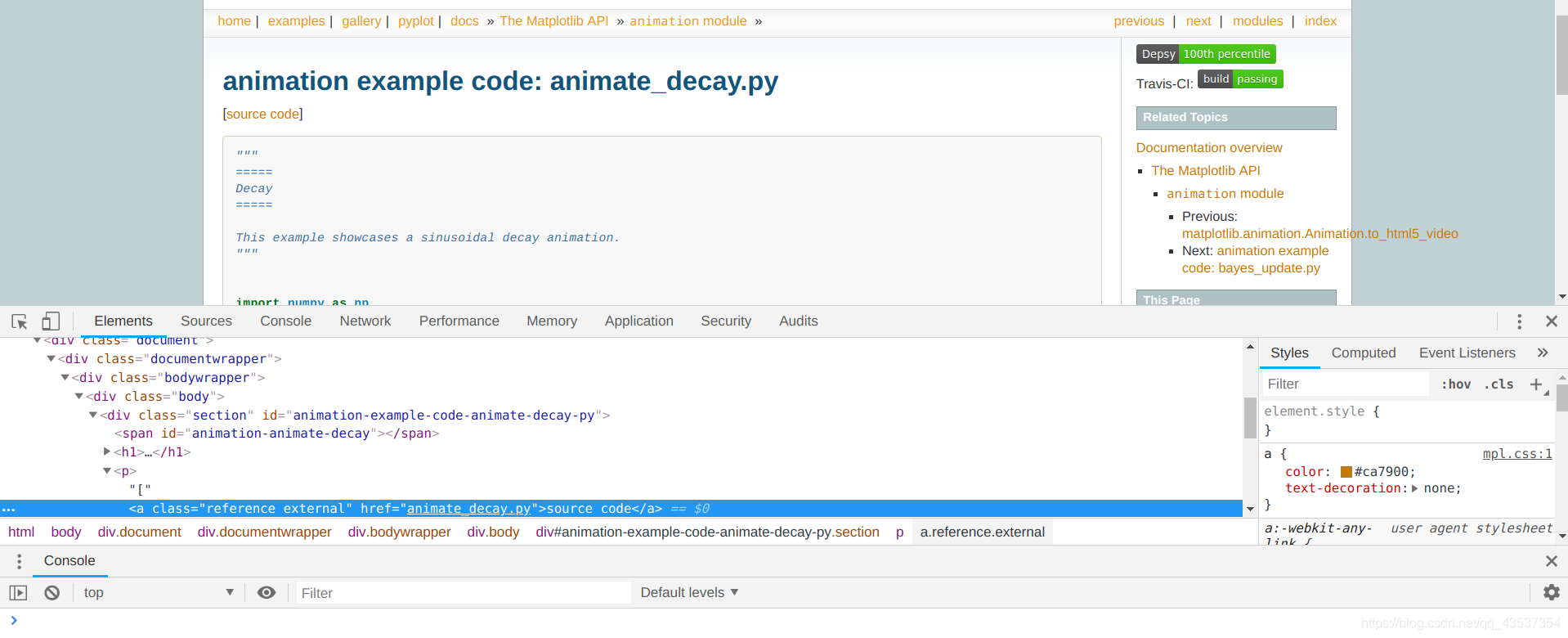
进入每一个例子中,找到下载例子源码文件的下载地址
<a class="reference external">
我们以下四步4步完成该项目
1. 创建Scrapy项目,并使用scrapy genspider命令创建Spider
2. 在settings.py中启用FilesPipeline,并指定下载目录
3. 实现ExampleItem
4. 实现ExamplesSpider
在settings.py中启用FilespPipeline,并指定下载目录。
ITEM_PIPELINES = {
'scrapy.pipelines.files.FilesPipeline':1 #通常将其置于其他Item Pipeline之前
}
FILES_STORE = 'example_src' #下载目录
在items.py中,设置file_urls字段和files字段
file_urls = scrapy.Field()
files = scrapy.Field()
爬取每一个例子中的源码下载地址就无需阐述了,直接上代码。
import scrapy
from scrapy.http import Request
from ..items import MatplotlibExampleItem
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['matplotlib.org']
start_urls = ['https://matplotlib.org/examples/index.html']
def parse(self, response):
#每一个例子的网址
urls = response.xpath('//li[@class="toctree-l2"]/a/@href').extract()
for url in urls:
url = 'https://matplotlib.org/examples/' + url
yield Request(url = url, callback = self.parse_example)
def parse_example(self, response):
#进入例子中的source code的网址
href = response.xpath('//a[@class="reference external"]/@href').extract()[0]
#构造完整的url
url = response.urljoin(href)
item = MatplotlibExampleItem()
item['file_urls'] = [url]
yield item
在Spider解析一个包含文件下载链接的页面时,将所有下载的文件所需要的url地址收集到一个列表,赋给item的file_urls字段。FilesPipeline在处理每一项item时,会读取item[‘file_urls’],对其中的每一个url进行下载。
注意!!!
item['file_urls'] = [url]
#ImagesPipeline传入的url地址必须是一个list,不然会有Missing scheme in request url报错
下载完成之后,会将结果写入item的另一字段files,files包含了文件现在的本地路径(相对于配置FILE_STORE的路径)、文件校验和checksum、文件的url

运行爬虫后得到结果:
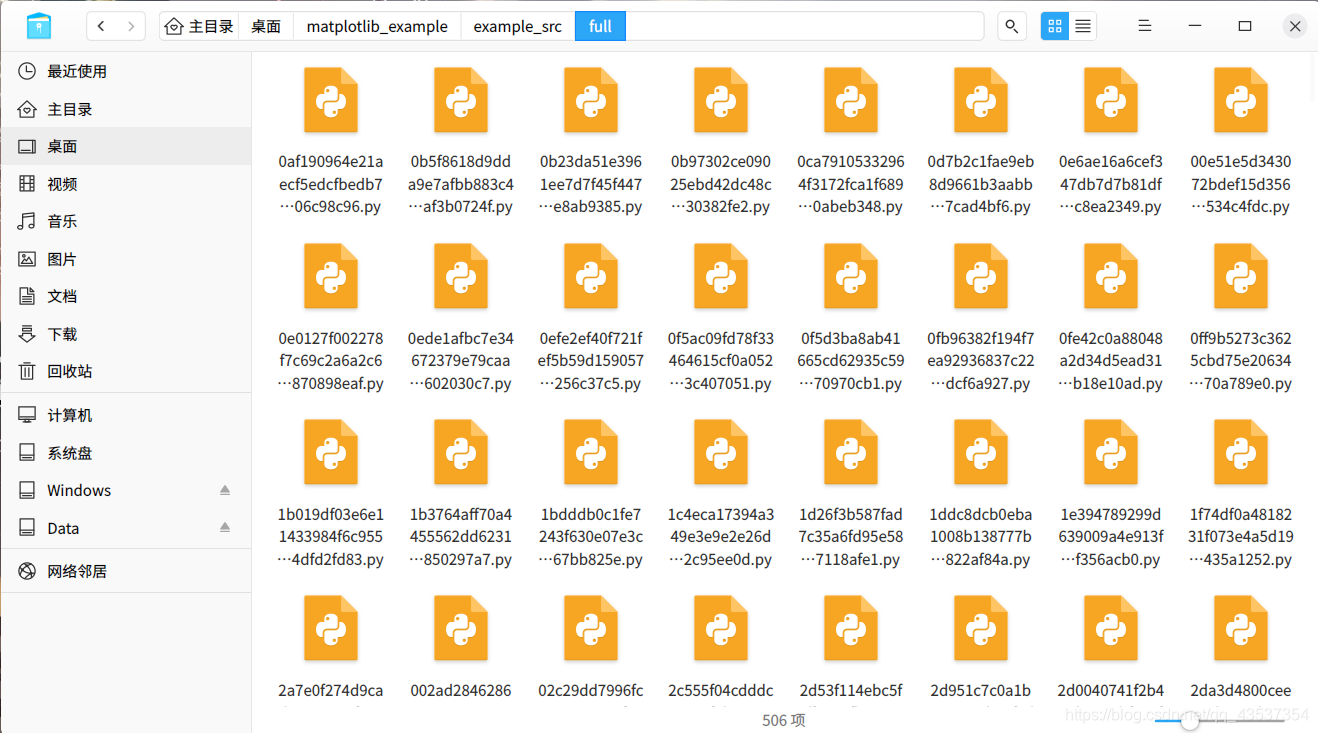
这时我们发现每个文件名称都是一串数字字母,这些数字字母是下载文件url的sha1散列值,这种命名方式可以防止重名的文件相互覆盖,但是这样文件名太不直观,我们可以在pipelines.py实现MyFilesPipeline,通过覆写FilesPipeline源码中的file_path方法来实现所期望的命名规则,
如https://matplotlib.org/examples/(pyplots/boxplot_demo.py)可用括号中的部分作为路径实现重命名。代码如下:
from scrapy.pipelines.files import FilesPipeline
from urllib.parse import urlparse
from os.path import basename, dirname, join
#os.path.dirname()方法 去掉文件名,返回目录
#os.path.basename()方法 返回path最后的文件名
class MyFilesPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None):
path = urlparse(request.url).path
return join(basename(dirname(path)), basename(path))
修改配置文件,使用MyFilesPipeline替代FilesPipeline:
ITEM_PIPELINES = {
# 'scrapy.pipelines.files.FilesPipeline':1,
'matplotlib_example.pipelines.MyFilesPipeline':1,
}
重新运行爬虫;
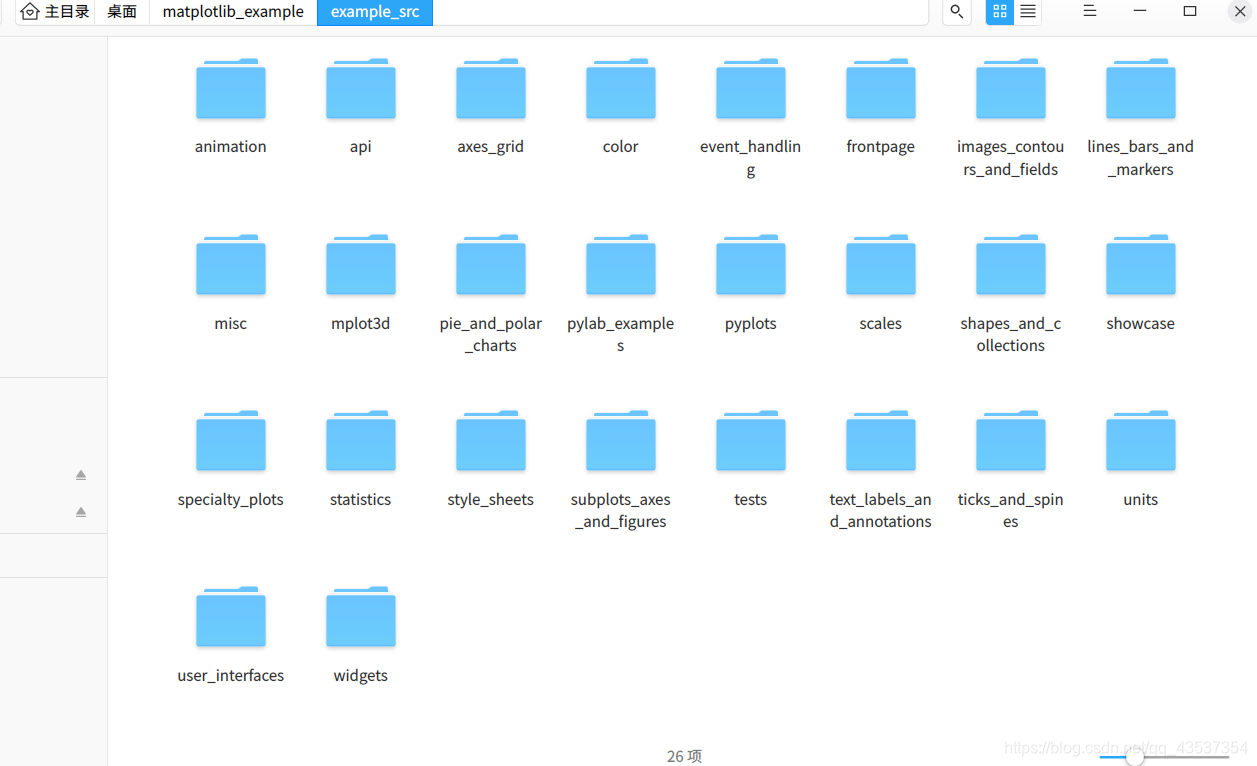
阅读Scrapy官方文档,我们可以知道实现自定义媒体管道可以通过覆写get_media_requests()函数和item_completed()函数实现。
import scrapy
def get_media_requests(self, item, info):
for file_url in item['file_urls']:
yield scrapy.Request(file_url)
此函数中需要把 file_url 取出并构建为 scrapy.Request 请求对象并返回,每一个请求都将触发一次下载图片的操作。
from scrapy.exceptions import DropItem
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
当一个单独项目中的所有图片请求完成时(要么完成下载,要么因为某种原因下载失败), ImagesPipeline.item_completed() 方法将被调用。其中的results参数是get_media_requests()函数请求下载后返回的结果,下面是 results 参数的一个典型值:
[(True,
{'checksum': '2b00042f7481c7b056c4b410d28f33cf',
'path': 'full/7d97e98f8af710c7e7fe703abc8f639e0ee507c4.jpg',
'url': 'http://www.example.com/images/product1.jpg'}),
(True,
{'checksum': 'b9628c4ab9b595f72f280b90c4fd093d',
'path': 'full/1ca5879492b8fd606df1964ea3c1e2f4520f076f.jpg',
'url': 'http://www.example.com/images/product2.jpg'}),
(False,
Failure(...))]
我们也可以通过get_media_requests()函数,在每一个Request请求中加入meta参数将item中的信息传入file_path(self, request, response=None, info=None)进行文件重命名。
file_path()参数中的request就是get_media_requests()发出的请求
ImagesPipeline
图片也是文件,所以下载图片本质上也是下载文件,ImagesPipeline是FilesPipeline的子类,在使用上很相似,只是在items.py和setting.py中有所区别。
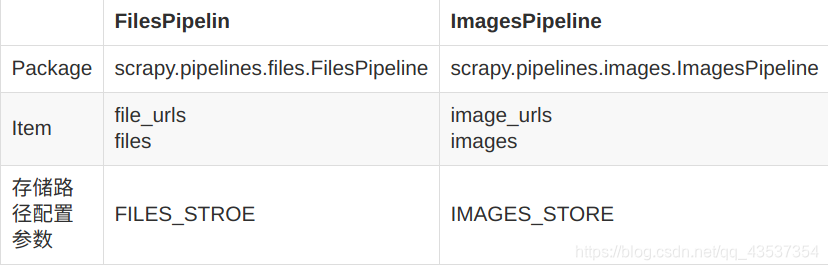
除此之外还有一些其他功能:
- 为图片生成缩略图
在setting.py中设置,以字典的格式,其中每一个值都是缩略图的尺寸。
IMAGES_THUMBS = {'big': (270, 270),
'small':(50, 50),
}
此时每下载一张图片,本地会出现3张图片(一张原图,两张缩略图)
- 过滤掉尺寸过小的照片
在setting.py中设置,IMAGES_MIN_WIDTH和IMGAES_MIN_HEIGHT分别指定图片最小的宽和高。开启后如果图片有一项小于下列数值就会被抛弃。
IMAGES_MIN_WIDTH = 110
IMGAES_MIN_HEIGHT = 110

















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









