










 本文介绍了如何在大数据平台上使用Java连接HiveServer2进行元数据服务配置,特别是metastore服务的开启,并讨论了Hive的Map Join实现,包括如何减少MapReduce运行及利用虚拟列进行数据操作。
本文介绍了如何在大数据平台上使用Java连接HiveServer2进行元数据服务配置,特别是metastore服务的开启,并讨论了Hive的Map Join实现,包括如何减少MapReduce运行及利用虚拟列进行数据操作。
大数据平台–Hive入门4
——使用Java连接Hiveserver2
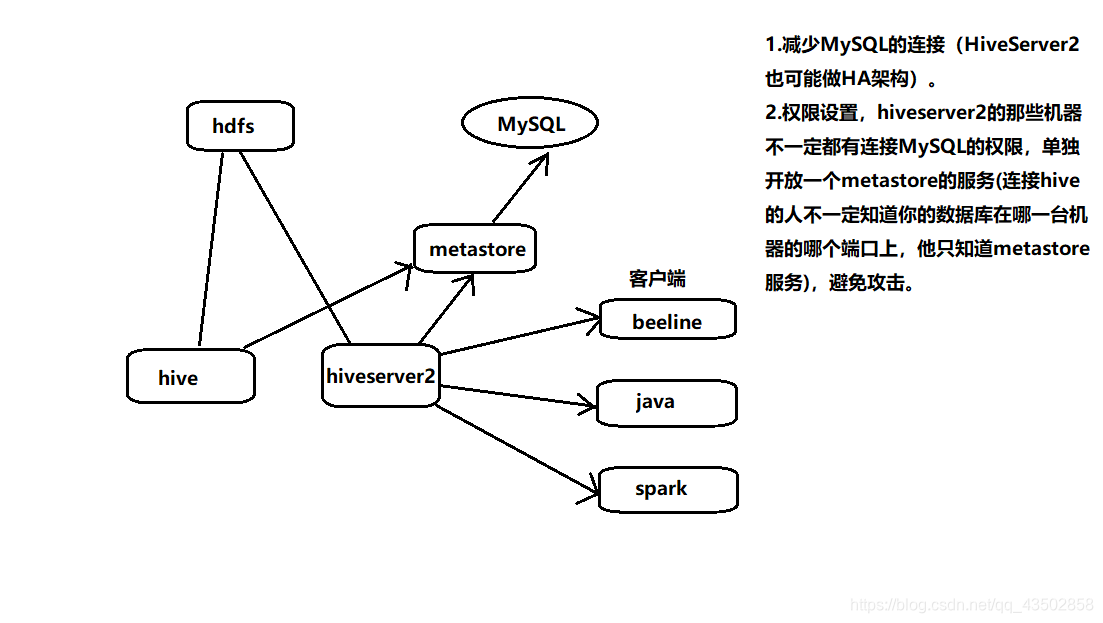
metastore 元数据服务
- 减少mysql连接(hiveserver2也可能是HA架构)
- 权限设置
hiveserver2通过连接metastore服务连接mysql。
配置metastore服务
hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.142.91:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>971102</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://pseudo:9083</value>
</property>
</configuration>
开启metastore服务
hive --service metastore
#后台开启metastore服务
nohup hive --service metastore &
查看9083端口
[root@pseudo ~]# netstat -nlp | grep 9083
tcp 0 0 0.0.0.0:9083 0.0.0.0:* LISTEN 12756/java
如何查看RunJar的具体信息
[root@pseudo ~]# jps -ml
13168 org.apache.hadoop.util.RunJar /opt/software/hive/hive-1.2.1/lib/hive-service-1.2.1.jar org.apache.hive.service.server.HiveServer2 --hiveconf hive.aux.jars.path=file:///opt/software/hive/hive-1.2.1/lib/accumulo-core-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/accumulo-fate-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/accumulo-start-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/accumulo-trace-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/activation-1.1.jar,file:///opt/software/hive/hive-1.2.1/lib/ant-1.9.1.jar,file:///opt/software/hive/hive-1.2.1/lib/ant-launcher-1.9.1.jar,file:///opt/software/hive/hive-1.2.1/lib/antlr-2.7.7.jar,file:///opt/software/hive/hive-1.2.1/lib/antlr-runtime-3.4.jar,file:///opt/software/hive/hive-1.2.1/lib/apache-log4j-extras-1.2.17.jar,file:///opt/software/hive/hive-1.2.1/lib/asm-commons-3.1.jar,file:///opt/software/hive/hive-1.2.1/lib/asm-tree-3.1.jar,file:///opt/software/hive/hive-1.2.1/lib/avro-1.7.5.jar,file:///opt/software/hive/hive-1.2.1/lib/bonecp-0.8.0.RE
9841 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager
13459 sun.tools.jps.Jps -ml
9988 org.apache.hadoop.yarn.server.nodemanager.NodeManager
12948 org.apache.hadoop.util.RunJar /opt/software/hive/hive-1.2.1/lib/hive-service-1.2.1.jar org.apache.hadoop.hive.metastore.HiveMetaStore
13284 org.apache.hadoop.util.RunJar /opt/software/hive/hive-1.2.1/lib/hive-beeline-1.2.1.jar org.apache.hive.beeline.BeeLine
9397 org.apache.hadoop.hdfs.server.namenode.NameNode
9525 org.apache.hadoop.hdfs.server.datanode.DataNode
9687 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
13034 org.apache.hadoop.util.RunJar /opt/software/hive/hive-1.2.1/lib/hive-cli-1.2.1.jar org.apache.hadoop.hive.cli.CliDriver --hiveconf hive.aux.jars.path=file:///opt/software/hive/hive-1.2.1/lib/accumulo-core-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/accumulo-fate-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/accumulo-start-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/accumulo-trace-1.6.0.jar,file:///opt/software/hive/hive-1.2.1/lib/activation-1.1.jar,file:///opt/software/hive/hive-1.2.1/lib/ant-1.9.1.jar,file:///opt/software/hive/hive-1.2.1/lib/ant-launcher-1.9.1.jar,file:///opt/software/hive/hive-1.2.1/lib/antlr-2.7.7.jar,file:///opt/software/hive/hive-1.2.1/lib/antlr-runtime-3.4.jar,file:///opt/software/hive/hive-1.2.1/lib/apache-log4j-extras-1.2.17.jar,file:///opt/software/hive/hive-1.2.1/lib/asm-commons-3.1.jar,file:///opt/software/hive/hive-1.2.1/lib/asm-tree-3.1.jar,file:///opt/software/hive/hive-1.2.1/lib/avro-1.7.5.jar,file:///opt/software/hive/hive-1.2.1/lib/bonecp-0.8.0.RELEASE.jar,
0: jdbc:hive2://pseudo:10000> select * from emp;
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| emp.empno | emp.ename | emp.job | emp.mgr | emp.hiredate | emp.sal | emp.comm | emp.deptno |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
| 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
+------------+------------+------------+----------+---------------+----------+-----------+-------------+--+
14 rows selected (0.723 seconds)
0: jdbc:hive2://pseudo:10000> select * from dept;
+--------------+-------------+-----------+--+
| dept.deptno | dept.dname | dept.loc |
+--------------+-------------+-----------+--+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------------+-------------+-----------+--+
4 rows selected (0.151 seconds)
配置减少MapReduce的运行
#查看hive.fetch.task.conversion属性;
0: jdbc:hive2://pseudo:10000> set hive.fetch.task.conversion;
+----------------------------------+--+
| set |
+----------------------------------+--+
| hive.fetch.task.conversion=more |
+----------------------------------+--+
1 row selected (0.016 seconds)
#该属性的可选属性值有none,minimal,more;
#该属性设置为none则任何sql全跑MapReduce。
虚拟列:
INPUT__FILE__NAME:查看数据源
BLOCK__OFFSET__INSIDE__FILE:查看当前记录在文件源中的偏移量
0: jdbc:hive2://pseudo:10000> select empno,INPUT__FILE__NAME from db_emp.emp;
+--------+---------------------------------------------------------------+--+
| empno | input__file__name |
+--------+---------------------------------------------------------------+--+
| 7369 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7499 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7521 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7566 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7654 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7698 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7782 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7788 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7839 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7844 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7876 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7900 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7902 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
| 7934 | hdfs://pseudo:9000/user/hive/warehouse/db_emp.db/emp/emp.txt |
+--------+---------------------------------------------------------------+--+
14 rows selected (0.17 seconds)
0: jdbc:hive2://pseudo:10000> select empno,BLOCK__OFFSET__INSIDE__FILE from db_emp.emp;
+--------+------------------------------+--+
| empno | block__offset__inside__file |
+--------+------------------------------+--+
| 7369 | 0 |
| 7499 | 44 |
| 7521 | 97 |
| 7566 | 149 |
| 7654 | 194 |
| 7698 | 249 |
| 7782 | 294 |
| 7788 | 339 |
| 7839 | 385 |
| 7844 | 429 |
| 7876 | 480 |
| 7900 | 524 |
| 7902 | 567 |
| 7934 | 612 |
+--------+------------------------------+--+
14 rows selected (0.077 seconds)
Java连接HiveServer2
pom.xml
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-service -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
<version>1.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.thrift/libfb303 -->
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libfb303</artifactId>
<version>0.9.0</version>
<type>pom</type>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.thrift/libthrift -->
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libthrift</artifactId>
<version>0.9.0</version>
<type>pom</type>
</dependency>
<!-- https://mvnrepository.com/artifact/log4j/log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.6.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-logging/commons-logging -->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.0.4</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
测试代码:
package com.nike.demo01;
import java.sql.*;
import java.util.logging.Logger;
/**
* Java连接Hiveserver2
* 四要素
* driver url user pwd
* driver:
* 1.hiveserver:org.apache.hadoop.hive.jdbc.HiveDriver
* 2.hiveserver2:org.apache.hive.jdbc.HiveDriver
*
*/
public class HiveServer2Demo01 {
private static String driver = "org.apache.hive.jdbc.HiveDriver";
private static String url = "jdbc:hive2://pseudo:10000/db_emp";
private static String userName = "root";
private static String passwd = "";
static {
try {
Class.forName(driver);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static Connection getHiveConn() throws SQLException {
Connection conn = DriverManager.getConnection(url, userName, passwd);
return conn;
}
public static void main(String[] args) {
try {
Connection hiveConn = getHiveConn();
String sql = "select * from emp";
PreparedStatement ps = hiveConn.prepareStatement(sql);
ResultSet rs = ps.executeQuery();
while (rs.next()){
int empno = rs.getInt(1);
String ename = rs.getString(2);
String job = rs.getString(3);
int mgr = rs.getInt(4);
String hiredate = rs.getString(5);
double salary = rs.getDouble(6);
double comm = rs.getDouble(7);
int deptno = rs.getInt(8);
System.out.println(empno+"\t"+ename+"\t"+job+"\t"+mgr+"\t"+hiredate+"\t"+salary+"\t"+comm+
"\t"+deptno);
}
rs.close();
ps.close();
hiveConn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
[root@pseudo ~]# hdfs dfs -put a.txt /tmp/
[root@pseudo ~]# hdfs dfs -ls /tmp/
Found 3 items
-rw-r--r-- 1 root supergroup 42 2019-06-30 01:19 /tmp/a.txt
drwx------ - root supergroup 0 2019-06-29 22:49 /tmp/hadoop-yarn
drwx-wx-wx - root supergroup 0 2019-06-30 01:12 /tmp/hive
package com.nike.demo01;
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
//replace "hive" here with the name of the user the queries should run as
Connection con = DriverManager.getConnection("jdbc:hive2://pseudo:10000/default", "hive", "");
Statement stmt = con.createStatement();
String tableName = "testHiveDriverTable";
stmt.execute("drop table if exists " + tableName);
stmt.execute("create table " + tableName + " (key int, value string)");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
// load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line
String filepath = "/tmp/a.txt";
sql = "load data inpath '" + filepath + "' into table " + tableName;
System.out.println("Running: " + sql);
stmt.execute(sql);
// select * query
sql = "select * from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + "\t" + res.getString(2));
}
// regular hive query
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
Hive的Map Join的实现
select /*+MAPJOIN(a)*/ a.*,b.* from dept a join emp b on a.deptno = b.deptno;
小表自动选择Map Join
set hive.auto.convert.join=true;
/*默认值:false,该参数为true时,Hive自动对左边的表进行统计,若是小表就加入内存,即对小表使用Map Join*/
/*小表阈值:默认值为25M*/
set hive.mapjoin.smalltable.filesize=25000000;
/*map join做group by操作时,可以使用多大内存来存储数据,若数据太大则不会保存在内存里*/
set hive.mapjoin.followby.gby.localtask.max.memory.usage;
/*默认值:0.55*/
/*设置本地任务可以使用内存的百分比*/
set hive.mapjoin.localtask.max.memory.usage;
/*默认值:0.90*/
0: jdbc:hive2://pseudo:10000> select a.*,b.* from dept a join emp b on a.deptno = b.deptno;
INFO : Execution completed successfully
INFO : MapredLocal task succeeded
INFO : Number of reduce tasks is set to 0 since there's no reduce operator
INFO : number of splits:1
INFO : Submitting tokens for job: job_1561780423781_0004
INFO : The url to track the job: http://pseudo:8088/proxy/application_1561780423781_0004/
INFO : Starting Job = job_1561780423781_0004, Tracking URL = http://pseudo:8088/proxy/application_1561780423781_0004/
INFO : Kill Command = /opt/software/pseudo/hadoop-2.7.3/bin/hadoop job -kill job_1561780423781_0004
INFO : Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
INFO : 2019-06-30 04:34:34,062 Stage-3 map = 0%, reduce = 0%
INFO : 2019-06-30 04:34:43,639 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 1.66 sec
INFO : MapReduce Total cumulative CPU time: 1 seconds 660 msec
INFO : Ended Job = job_1561780423781_0004
+-----------+-------------+-----------+----------+----------+------------+--------+-------------+---------+---------+-----------+--+
| a.deptno | a.dname | a.loc | b.empno | b.ename | b.job | b.mgr | b.hiredate | b.sal | b.comm | b.deptno |
+-----------+-------------+-----------+----------+----------+------------+--------+-------------+---------+---------+-----------+--+
| 20 | RESEARCH | DALLAS | 7369 | SMITH | CLERK | 7902 | 1980-12-17 | 800.0 | NULL | 20 |
| 30 | SALES | CHICAGO | 7499 | ALLEN | SALESMAN | 7698 | 1981-2-20 | 1600.0 | 300.0 | 30 |
| 30 | SALES | CHICAGO | 7521 | WARD | SALESMAN | 7698 | 1981-2-22 | 1250.0 | 500.0 | 30 |
| 20 | RESEARCH | DALLAS | 7566 | JONES | MANAGER | 7839 | 1981-4-2 | 2975.0 | NULL | 20 |
| 30 | SALES | CHICAGO | 7654 | MARTIN | SALESMAN | 7698 | 1981-9-28 | 1250.0 | 1400.0 | 30 |
| 30 | SALES | CHICAGO | 7698 | BLAKE | MANAGER | 7839 | 1981-5-1 | 2850.0 | NULL | 30 |
| 10 | ACCOUNTING | NEW YORK | 7782 | CLARK | MANAGER | 7839 | 1981-6-9 | 2450.0 | NULL | 10 |
| 20 | RESEARCH | DALLAS | 7788 | SCOTT | ANALYST | 7566 | 1987-4-19 | 3000.0 | NULL | 20 |
| 10 | ACCOUNTING | NEW YORK | 7839 | KING | PRESIDENT | NULL | 1981-11-17 | 5000.0 | NULL | 10 |
| 30 | SALES | CHICAGO | 7844 | TURNER | SALESMAN | 7698 | 1981-9-8 | 1500.0 | 0.0 | 30 |
| 20 | RESEARCH | DALLAS | 7876 | ADAMS | CLERK | 7788 | 1987-5-23 | 1100.0 | NULL | 20 |
| 30 | SALES | CHICAGO | 7900 | JAMES | CLERK | 7698 | 1981-12-3 | 950.0 | NULL | 30 |
| 20 | RESEARCH | DALLAS | 7902 | FORD | ANALYST | 7566 | 1981-12-3 | 3000.0 | NULL | 20 |
| 10 | ACCOUNTING | NEW YORK | 7934 | MILLER | CLERK | 7782 | 1982-1-23 | 1300.0 | NULL | 10 |
+-----------+-------------+-----------+----------+----------+------------+--------+-------------+---------+---------+-----------+--+
14 rows selected (37.872 seconds)

















 3284
3284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









