






 本文介绍了两种在MapReduce中实现Join的方法。第一种是Map Join,通过准备数据,自定义数据类型并编写MapReduce代码来完成。第二种是Reduce Join,利用小文件加载到缓存,构建映射关系map来实现Join操作。
本文介绍了两种在MapReduce中实现Join的方法。第一种是Map Join,通过准备数据,自定义数据类型并编写MapReduce代码来完成。第二种是Reduce Join,利用小文件加载到缓存,构建映射关系map来实现Join操作。
Join On MapReduce
第一种实现(Map Join)
思路:
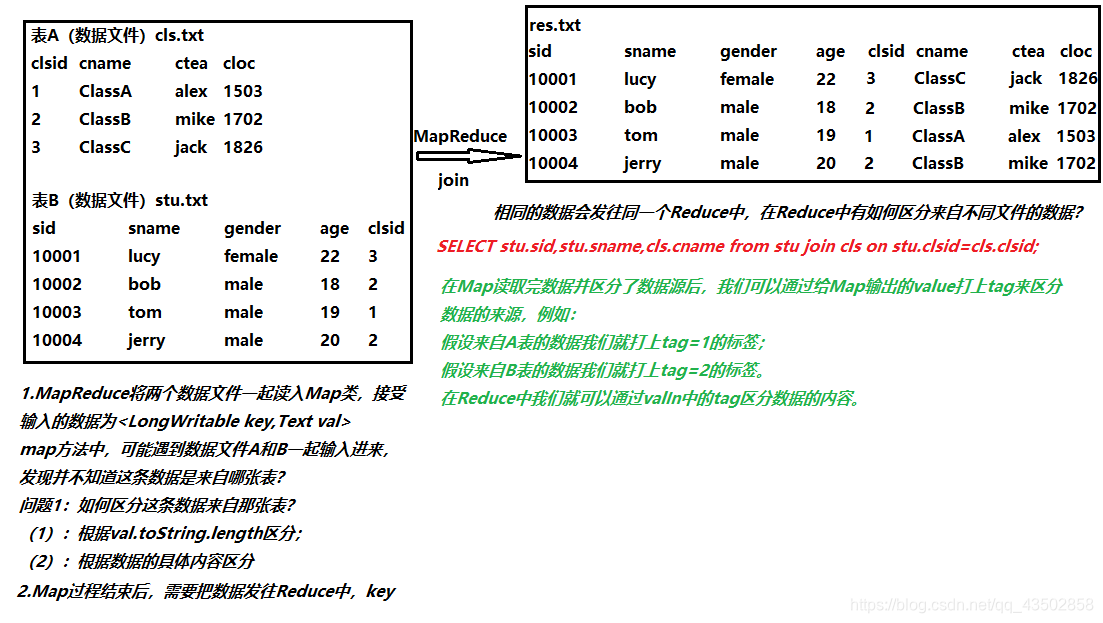
准备数据:
cls.txt
CLassA,Alex,R108,1
ClassB,Mike,R115,2
ClassC,Jack,R121,3
ClassD,Nike,R206,4
stus.txt
1001,Tomm,male,20,3
1002,Lucy,female,18,2
1003,Mark,male,19,1
2001,Json,male,21,3
3001,Rose,female,20,2
2002,Bobb,male,21,4
2003,Bill,male,20,3
3002,Jame,male,21,1
2004,Vick,male,20,2
3003,Winn,female,18,4
1004,York,male,20,2
3004,Nora,female,18,4
编写代码:
1.自定义数据类型用以储存tag标签和输出数据
package com.nike.hadoop.mapred.join02;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class CuWritable implements Writable {
private int tag;
private String data;
public CuWritable() {
}
public CuWritable(int tag, String data) {
this.tag = tag;
this.data = data;
}
public int getTag() {
return tag;
}
public void setTag(int tag) {
this.tag = tag;
}
public String getData() {
return data;
}
public void setData(String data) {
this.data = data;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(tag);
dataOutput.writeUTF(data);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.tag = dataInput.readInt();
this.data = dataInput.readUTF();
}
}
2.MapReduce的具体实现
package com.nike.hadoop.mapred.join02;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class JoinMap01 extends Mapper<LongWritable, Text,Text,CuWritable> {
private Text keyOut = new Text();
private CuWritable cu = new CuWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
keyOut.set(strs[strs.length-1]);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < strs.length-1; i++) {
sb.append(strs[i]+"\t");
}
if (strs.length==5){
cu.setTag(1);
}else{
cu.setTag(2);
}
cu.setData(sb.toString());
context.write(keyOut,cu);
}
}
package com.nike.hadoop.mapred.join02;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class JoinReduce01 extends Reducer<Text,CuWritable,Text,Text> {
private Text valOut = new Text();
@Override
protected void reduce(Text key, Iterable<CuWritable> values, Context context) throws IOException, InterruptedException {
List<String> sList = new ArrayList<>();
String clsInfo = null;
for (CuWritable val : values) {
if (val.getTag()==1){
sList.add(val.getData());
}else{
clsInfo = val.getData();
}
}
for (String s : sList) {
valOut.set(s+clsInfo);
context.write(key,valOut);
}
}
}
package com.nike.hadoop.mapred.join02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JoinRun01 {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
Job job = Job.getInstance(conf);
job.setJarByClass(JoinRun01.class);
job.setMapperClass(JoinMap01.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CuWritable.class);
job.setReducerClass(JoinReduce01.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.setInputPaths(job,
new Path("file:///C:\\Users\\Administrator\\Desktop\\stus.txt"),
new Path("file:///C:\\Users\\Administrator\\Desktop\\cls.txt"));
Path outPath = new Path("file:///C://Users/Administrator/Desktop/join0001");
FileSystem system = outPath.getFileSystem(conf);
if (system.exists(outPath)){
system.delete(outPath,true);
}
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,outPath);
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
程序运行结果:
1 3002 Jame male 21 CLassA Alex R108
1 1003 Mark male 19 CLassA Alex R108
2 1004 York male 20 ClassB Mike R115
2 2004 Vick male 20 ClassB Mike R115
2 3001 Rose female 20 ClassB Mike R115
2 1002 Lucy female 18 ClassB Mike R115
3 2003 Bill male 20 ClassC Jack R121
3 2001 Json male 21 ClassC Jack R121
3 1001 Tomm male 20 ClassC Jack R121
4 3004 Nora female 18 ClassD Nike R206
4 3003 Winn female 18 ClassD Nike R206
4 2002 Bobb male 21 ClassD Nike R206
第二种实现(Reduce Join)
思路:
基于两份数据中的有一份数据文件较小,我们可以将两份数据中较小的那份数据加载到缓存中,并由此生成一个“外键”作为key映射关系map,并由此map实现join。
编写代码
package com.nike.hadoop.mapred.join;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class JoinMap extends Mapper<LongWritable, Text,Text, Text> {
private Map<String,String> map = new HashMap<>();
private Text valOut = new Text();
private Text keyOut = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] files = context.getCacheFiles();
String path = files[0].getPath();
BufferedReader br = new BufferedReader(new FileReader(path));
String line = null;
while ((line=br.readLine())!=null){
String[] strs = line.split(",");
StringBuilder sb = new StringBuilder();
for (int i = 0; i < strs.length-1; i++) {
sb.append(strs[i]+"\t");
}
map.put(strs[strs.length-1],sb.toString());
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] strs = line.split(",");
String clsinfo = map.get(strs[strs.length-1]);
//System.out.println(strs[0]+"\t"+proinfo);
StringBuilder sb = new StringBuilder();
for (int i = 0; i < strs.length-1; i++) {
sb.append(strs[i]+"\t");
}
if (clsinfo != null);{
sb.append(clsinfo);
}
keyOut.set(strs[strs.length-1]);
valOut.set(sb.toString());
context.write(keyOut,valOut);
}
}
package com.nike.hadoop.mapred.join;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class JoinRun {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
Job job = Job.getInstance(conf);
String proinfo = "file:///C:\\Users\\Administrator\\Desktop\\cls.txt";
job.addCacheFile(new Path(proinfo).toUri());
job.setJarByClass(JoinRun.class);
job.setMapperClass(JoinMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job,new Path("file:///C:\\Users\\Administrator\\Desktop\\stus.txt"));
Path outPath = new Path("file:///C://Users/Administrator/Desktop/join0002");
FileSystem system = outPath.getFileSystem(conf);
if (system.exists(outPath)){
system.delete(outPath,true);
}
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job,outPath);
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
程序运行结果:
1 3002 Jame male 21 CLassA Alex R108
1 1003 Mark male 19 CLassA Alex R108
2 1004 York male 20 ClassB Mike R115
2 2004 Vick male 20 ClassB Mike R115
2 3001 Rose female 20 ClassB Mike R115
2 1002 Lucy female 18 ClassB Mike R115
3 2003 Bill male 20 ClassC Jack R121
3 2001 Json male 21 ClassC Jack R121
3 1001 Tomm male 20 ClassC Jack R121
4 3004 Nora female 18 ClassD Nike R206
4 3003 Winn female 18 ClassD Nike R206
4 2002 Bobb male 21 ClassD Nike R206

















 392
392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









