







 Hadoop MapReduce V2是一种编程模型,用于大规模数据集的并行运算。Map阶段将输入数据映射成中间键值对,Reduce阶段则对相同键的数据进行归约计算。MRv2改进了旧版的架构,减轻了JobTracker的负担,提高了资源管理的效率,降低了计算调度与资源管理的耦合。
Hadoop MapReduce V2是一种编程模型,用于大规模数据集的并行运算。Map阶段将输入数据映射成中间键值对,Reduce阶段则对相同键的数据进行归约计算。MRv2改进了旧版的架构,减轻了JobTracker的负担,提高了资源管理的效率,降低了计算调度与资源管理的耦合。
Hadoop MapReduce V2
MapReduce介绍
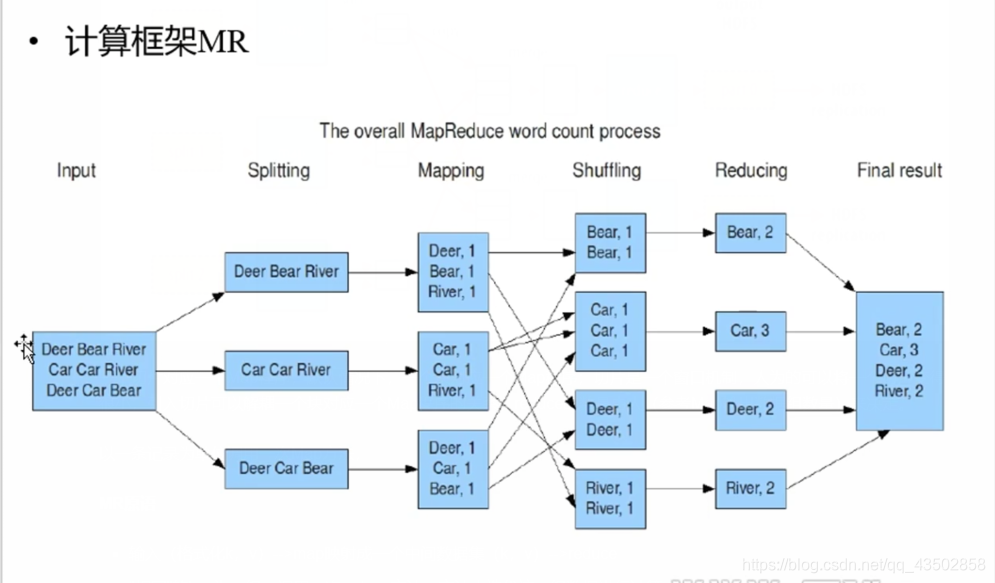
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)“和"Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。

一个切片对应一个Map程序,默认情况下,一个块对应一个Map程序;切片是一个窗口机制,人为的可以将一个切片变得很小,引入切片可以解耦一个块对应一个Map程序的关系。reduce的数量由人(参考Map输出数据组数量)来决定。
以一条记录为单位调用一次Map方法,
MR原语
- 输入(格式化k,v)–>map映射成一个中间数据集(k,v)–>reduce
- "相同"的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
-
- 排序,比较
- 遍历,计算
MapReduce架构概念
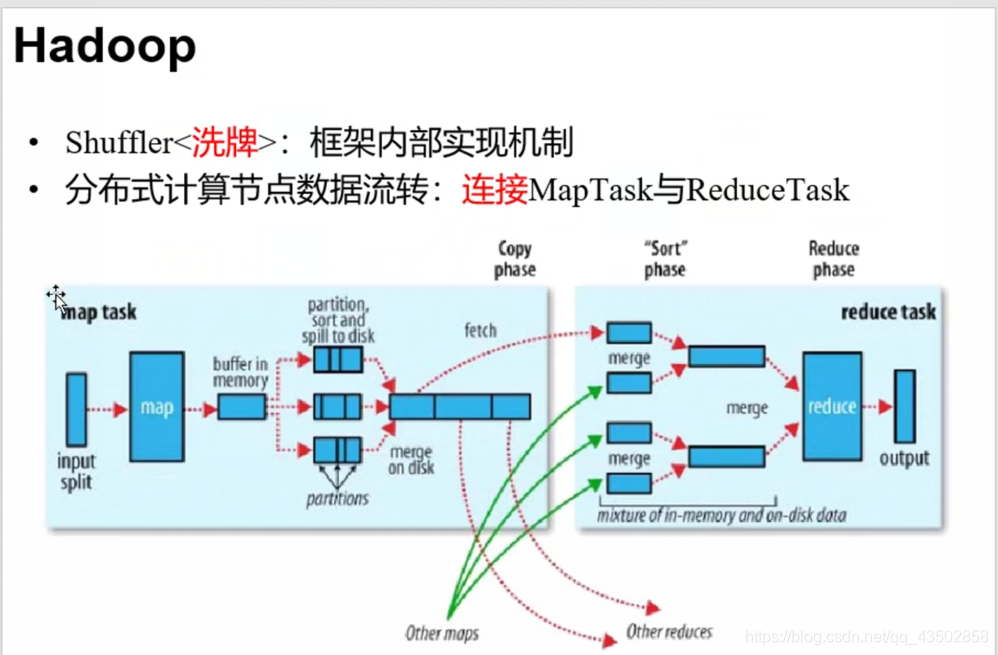
Map:
- 读懂数据
- 映射为KV模型
- 并行分布式
- 计算向数据移动
Reduce:
- 数据全量/分量加工
- Reduce中可以包含不同的key
- 相同的key汇聚到一个Reduce方法中
- 相同的Key调用一次reduce方法
-
- 排序实现key的汇聚
K,V使用自定义数据类型
- 作为参数传递,节省开发成本,提高程序自由度
- Writable序列化:使分布式程序数据交互
- Comparable比较器:实现具体排序(字典序,数字序等)
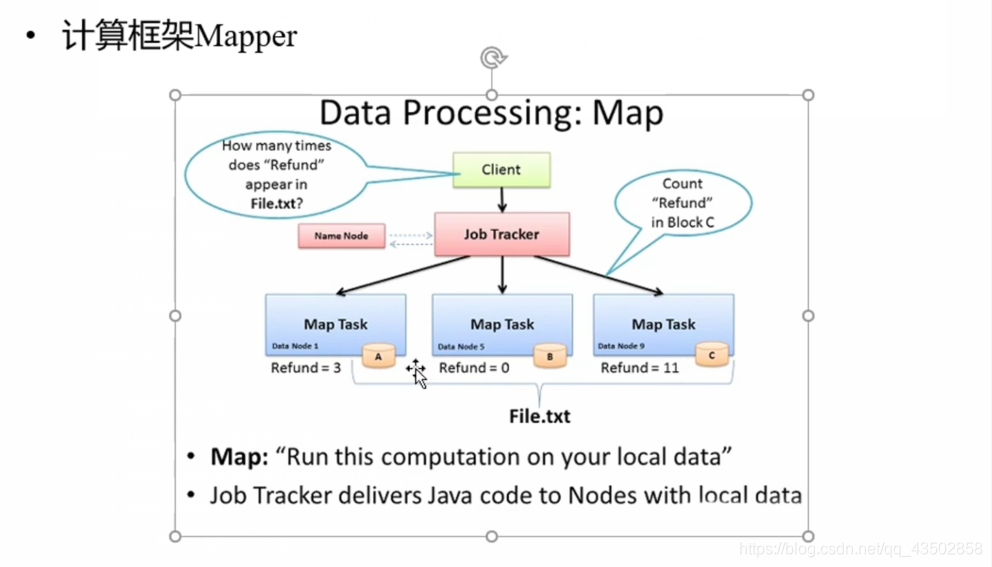
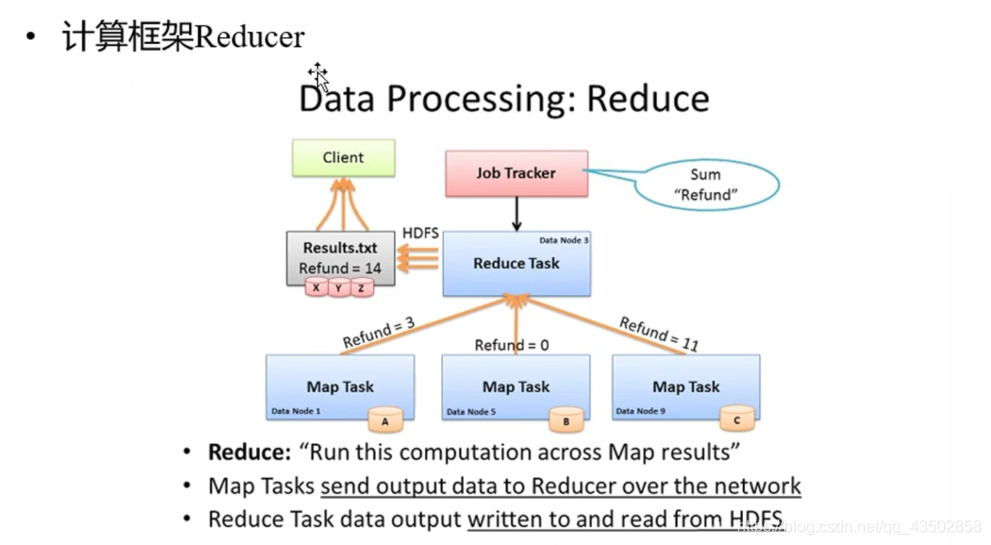
MRv1角色:
- JobTracker
-
- 核心,主,单点
- 调度所有的作业
- 调控整个集群的资源负载
- TaskTracker
-
- 从,自身节点资源管理
- 和JobTracker心跳,汇报资源,获取Task
- Client
-
- 作业为单位
- 规划作业计算分布
- 提交作业资源到HDFS
- 最终提交作业到JobTracker
- 弊端:
-
- JobTracker:负载过重,单点故障
- 资源管理与计算调度强耦合,其他计算框架需要重复实现资源管理
- 不同框架对资源不能全局管理

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









