






hive 2.x和 hive 3.x的UDTF在实现时,虽然继承的抽象类GenericUDTF只要求实现process()、close()两个方法,但是实际Hive或Spark调用运行时又会出现如下报错:
>>> [2025-02-17 21:21:16][INFO ][SparkServerlessJobLauncher]: JobRun state changed, To Failed
Process Output>>> Exception in thread "main" org.apache.spark.sql.AnalysisException: No handler for UDF/UDAF/UDTF 'com.alibaba.dt.hive.udtf.StringSplitAnn': java.lang.IllegalStateException: Should not be called directly; line 15 pos 0 at org.apache.hadoop.hive.ql.udf.generic.GenericUDTF.initialize(GenericUDTF.java:72)
Process Output>>> at org.apache.hadoop.hive.ql.udf.generic.GenericUDTF.initialize(GenericUDTF.java:56)
Process Output>>> at org.apache.spark.sql.hive.HiveGenericUDTF.outputInspector$lzycompute(hiveUDFs.scala:235)
Process Output>>> at org.apache.spark.sql.hive.HiveGenericUDTF.outputInspector(hiveUDFs.scala:235)
Process Output>>> at org.apache.spark.sql.hive.HiveGenericUDTF.elementSchema$lzycompute(hiveUDFs.scala:243)
Process Output>>> at org.apache.spark.sql.hive.HiveGenericUDTF.elementSchema(hiveUDFs.scala:243)
Process Output>>> at org.apache.spark.sql.hive.HiveUDFExpressionBuilder$.makeHiveFunctionExpression(HiveSessionStateBuilder.scala:195)
Process Output>>> at org.apache.spark.sql.hive.HiveUDFExpressionBuilder$.$anonfun$makeExpression$1(HiveSessionStateBuilder.scala:161)
Process Output>>> at org.apache.spark.util.Utils$.withContextClassLoader(Utils.scala:240)
Process Output>>> at org.apache.spark.sql.hive.HiveUDFExpressionBuilder$.makeExpression(HiveSessionStateBuilder.scala:155)
Process Output>>> at org.apache.spark.sql.catalyst.catalog.SessionCatalog.$anonfun$makeFunctionBuilder$1(SessionCatalog.scala:1506)
Process Output>>> at org.apache.spark.sql.catalyst.analysis.SimpleFunctionRegistryBase.lookupFunction(FunctionRegistry.scala:233)
Process Output>>> at org.apache.spark.sql.catalyst.analysis.SimpleFunctionRegistryBase.lookupFunction$(FunctionRegistry.scala:227)
Process Output>>> at org.apache.spark.sql.catalyst.analysis.SimpleFunctionRegistry.lookupFunction(FunctionRegistry.scala:299)
提示就是会调用initialize()方法,而且还特别搞笑的调用到了一个@Deprecated的initialize默认实现。
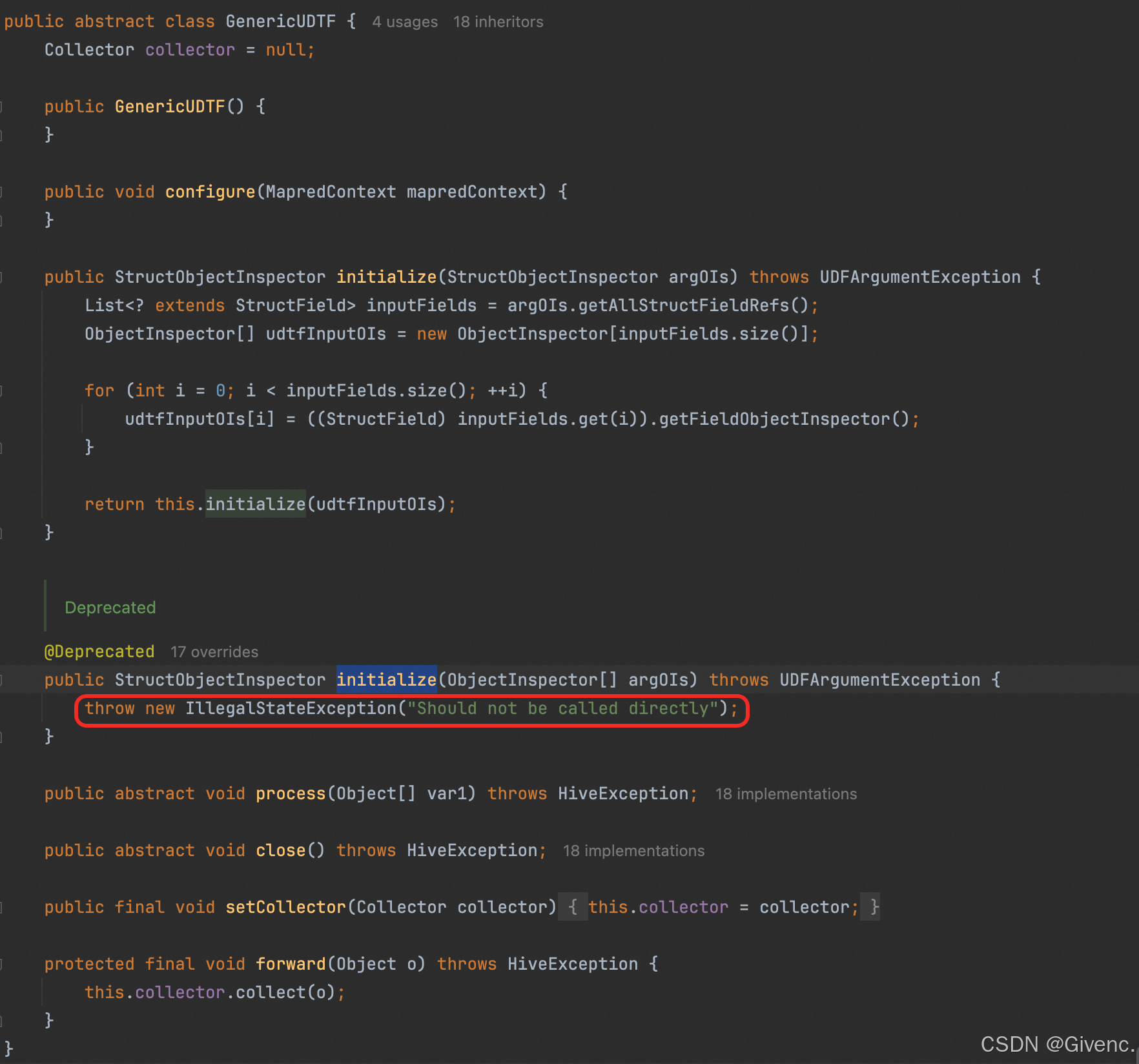
本质上,initialize的作用有2个:①检查输入参数的合法性;②定义输出结果的类型和数量。所以还是自己实现一下吧,笑死🤣
// initialize必须要实现,指定输出结构(虽然没有要求实现,但实际会调用)
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
// 定义2个入参,检查入参数量
if(argOIs.length != 2){
throw new UDFArgumentException("ExplodeStringUDTF takes exactly two argument.");
}
// 方法1:判断参数类型是否正确-比如STRING
PrimitiveObjectInspector.PrimitiveCategory arg1 = ((PrimitiveObjectInspector)argOIs[0]).getPrimitiveCategory();
PrimitiveObjectInspector.PrimitiveCategory arg2 = ((PrimitiveObjectInspector)argOIs[1]).getPrimitiveCategory();
if (!(arg1.equals(PrimitiveObjectInspector.PrimitiveCategory.STRING))) {
throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \"" +
arg1.name() + "\" " + "is found" + "\n" + argOIs[0].getClass().getSimpleName());
}
if (!(arg2.equals(PrimitiveObjectInspector.PrimitiveCategory.STRING))) {
throw new UDFArgumentTypeException(0, "\"array\" expected at function STRUCT_CONTAINS, but \""
+ arg2.name() + "\" " + "is found" + "\n" + argOIs[1].getClass().getSimpleName());
}
// 定义输出结构
ArrayList<String> fieldNames = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNames.add("info");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}

















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









