







LeetCode链接:二叉树
1 树的遍历
1.1 树的前中后序遍历
略
1.2 树的层序遍历
思想:BFS,
典例 层序遍历取一层
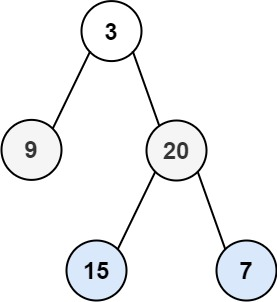
Input: root = [3,9,20,null,null,15,7]
Output: [[3],[9,20],[15,7]]
关键点:普通的 BFS 按照层序输出即可,如何按照不同的层次将其放入不同的vector 中?
思路: 在普通的层序遍历中,我们出队一个元素,然后将其子结点入队,如果要按照层次分开,那么还需要加入一个 level 域用来标记节点的层次。
现有一种方法: 我们一次性取出一层的结点。
我们可以用广度优先搜索解决这个问题。
我们可以想到最朴素的方法是用一个二元组 (node, level) 来表示状态,它表示某个节点和它所在的层数,每个新进队列的节点的 level 值都是父亲节点的 level 值加一。最后根据每个点的 level 对点进行分类,分类的时候我们可以利用哈希表,维护一个以 level 为键,对应节点值组成的数组为值,广度优先搜索结束以后按键 level 从小到大取出所有值,组成答案返回即可。
考虑如何优化空间开销:如何不用哈希映射,并且只用一个变量 node 表示状态,实现这个功能呢?
我们可以用一种巧妙的方法修改广度优先搜索:
首先根元素入队,当队列不为空的时候
求当前队列的长度 s_i
依次从队列中取 s_i 个元素进行拓展,然后进入下一次迭代。
它和普通广度优先搜索的区别在于,普通广度优先搜索每次只取一个元素拓展,而这里每次取 s_i 个元素。在上述过程中的第 ii 次迭代就得到了二叉树的第 ii 层的 s_i 个元素。
代码:
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector <vector <int>> ret;
if (!root) {
return ret;
}
queue <TreeNode*> q;
q.push(root);
while (!q.empty()) {
int currentLevelSize = q.size();
ret.push_back(vector <int> ());
for (int i = 1; i <= currentLevelSize; ++i) {
auto node = q.front(); q.pop();
ret.back().push_back(node->val);
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
}
return ret;
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/solution/er-cha-shu-de-ceng-xu-bian-li-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2 运用递归解决问题
两种思想
二叉树的递归中有两种思想:
1.自上而下:先序思想,先处理根节点,再考虑什么参数往下传;
2.自下而上:后序思想,先递归到终点( 叶或空),先获得左右子树的某些性质,再做判断。
例如:获得一颗树的最大深度的两种解法。
1.自上而下:根节点深度设为 1,设置一个参数保存当前深度,一直向下递归,直至叶子节点,判断是否需要更新最大值。
int answer; // don't forget to initialize answer before call maximum_depth
void maximum_depth(TreeNode* root, int depth) {
if (!root) {
return;
}
if (!root->left && !root->right) {
answer = max(answer, depth);
}
maximum_depth(root->left, depth + 1);
maximum_depth(root->right, depth + 1);
}
2.自下而上:空节点的深度为 0,先获得左右子树的深度,该节点的深度 = max(left,right) + 1,这样一直返回到根节点去。
int maximum_depth(TreeNode* root) {
if (!root) {
return 0; // return 0 for null node
}
int left_depth = maximum_depth(root->left);
int right_depth = maximum_depth(root->right);
return max(left_depth, right_depth) + 1; // return depth of the subtree rooted at root
}
典例 判断对称树
判断一棵树是否是对称的。
思路:显然,“自上而下”,首先判断根节点是否是相同的,然后递归判断左右子树是否相同。
class Solution {
public:
bool check(TreeNode *p, TreeNode *q) {
if (!p && !q) return true;
if (!p || !q) return false;
return p->val == q->val && check(p->left, q->right) && check(p->right, q->left);
}
bool isSymmetric(TreeNode* root) {
return check(root, root);
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/symmetric-tree/solution/dui-cheng-er-cha-shu-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
典例 和为定值的路径
求树中一条从根到叶子的路径,该路径上的数值和恰等于 x。
DFS:
方法一:以 当前和 sum 作为参数。
方法二:以 剩余值 作为参数
BFS:
方法三:
既然都要遍历所有的结点,那么也可以采用BFS的方式。
设置两个队列,分别保存 “当前值” 和 “当前和”,当出队元素为叶节点时判断即可。
class Solution {
public:
bool hasPathSum(TreeNode *root, int sum) {
if (root == nullptr) {
return false;
}
queue<TreeNode *> que_node;
queue<int> que_val;
que_node.push(root);
que_val.push(root->val);
while (!que_node.empty()) {
TreeNode *now = que_node.front();
int temp = que_val.front();
que_node.pop();
que_val.pop();
if (now->left == nullptr && now->right == nullptr) {
if (temp == sum) {
return true;
}
continue;
}
if (now->left != nullptr) {
que_node.push(now->left);
que_val.push(now->left->val + temp);
}
if (now->right != nullptr) {
que_node.push(now->right);
que_val.push(now->right->val + temp);
}
}
return false;
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/path-sum/solution/lu-jing-zong-he-by-leetcode-solution/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3 二叉树常见题目总结
典例 中序后序序列建树
没得说。
TreeNode* create(vector<int>& inorder, vector<int>& postorder,int inL,int inR,int postL,int postR){
if(inL > inR) return NULL;
// 首先,在中序序列找到根节点的位置
int k;
for( k = inL;k <= inR;++k){
if(inorder[k] == postorder[postR]) break;
}
// 创建根节点
TreeNode* root = new TreeNode(postorder[postR]);
int numLeft = k - inL; // 左子树的个数
//递归构造左右子树
root->left = create(inorder,postorder,inL,k-1,postL,postL+numLeft-1);
root->right = create(inorder,postorder,k+1,inR,postL+numLeft,postR-1);
return root;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
return create(inorder,postorder,0,inorder.size()-1,0,postorder.size()-1);
}
典例 寻找LCA
寻找最近公共祖先LCA。
方法一****递归。
重点:
1.LCA的判断方法
2.自底向上的递归方法
显然,本题要寻找最近(深度最深)的公共祖先,则应当采用“自底向上”的思想,先获得左右子树的性质,再做判断。
那么,重点就变成了应当获取左右子树的什么性质?
回顾LCA应当满足的条件:
1.p/q 分列在 root 的两侧;
2.root = = p, q 在root 的左子树或右子树中;
3.root = = q, p 在 root 的左子树或右子树中;
那么递归函数 froot 的返回值就可以设置为:以 root 为根的树是否包含了 p或q?如此,判断 LCA 的条件就变成了:
- froot->left = = true && froot->right = = true
- root->val = = p->val && ( froot->left = = true || froot->right = = true )
- root->val = = q->val && ( froot->left = = true || froot->right = = true )
如果满足上述条件,就找到了 LCA,记录答案退出递归。若不满足,则返回该子树是否包含了 p 或 q ?即:
return froot->left|| froot->right || root->val = = p->val || root->val = = q->val
/ 最近祖先节点: 其是p,q的共同祖先节点,但其孩子不是
// 既然是最近,第一反应是从下向上的递归,先递归到底部,在向上返回的过程中进行判断
// 判断以 root 为根的树,是否包含了 p 或 q
TreeNode* ans;
bool myfind(TreeNode* root,TreeNode* p,TreeNode* q){
if(root == NULL) return false;
// 先获得子树的性质
// 判断子树是否包含了 p 或 q
bool left = myfind(root->left,p,q);
bool right = myfind(root->right,p,q);
// 1.左右子树都包含了,说明分列在 root 两端,又由于是自顶向上,则一定是 LCA
if(left && right ){
ans = root;
return true;
}
// 2.
if(root->val == p->val && (left || right)){
ans = root;
return true;
}
// 3.
if(root->val == q->val && (left || right)){
ans = root;
return true;
}
return left || right || root->val == p->val || root->val == q->val;
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
myfind(root,p,q);
return ans;
}
方法二,染色路径,首先遍历根节点,记录下所有节点的父节点
// 利用父节点,从 p 开始向上走,并用一个数据结构记录路径
// 再从 q 向上走,遇到的第一个被访问节点就是 LCA
// 方法一,首先遍历根节点,记录下所有节点的父节点
// 利用父节点,从 p 开始向上走,并用一个数据结构记录路径
// 再从 q 向上走,遇到的第一个被访问节点就是 LCA
map<int,TreeNode*> fa;
map<int,bool> vis;
// 遍历设置父节点
void dfs(TreeNode* root){
if(root == NULL) return;
if(root->left != NULL) {
fa[root->left->val] = root;
dfs(root->left);
}
if(root->right != NULL){
fa[root->right->val] = root;
dfs(root->right);
}
}
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
fa[root->val] = NULL;
dfs(root);
while(p != NULL){
vis[p->val] = true;
p = fa[p->val];
}
while(q != NULL){
if(vis[q->val]) return q;
q = fa[q->val];
}
return NULL;
}
典例 二叉树序列化与反序列化
题目:给出一颗二叉树,将其转换为序列,再用这个序列构建出原来的二叉树。
步骤:
1.二叉树转换成序列字符串(以LeetCode的序列为参考) => BFS;
2.将序列字符串转换成 vector 数组,(便于操作);
3.用 数组 建立二叉树(难点)=> BFS。
思路:
1.层序遍历,并生成字符串,用 “,” 作为分隔;
2.用 string 的 find 方法,读取 “,”,构造出 vector 数组;
3.用 数组 建立二叉树过程如下:
1)创建一个<TreeNode*>队列,创建根节点并加入;
2)创建一个指针指向 vector 数组,起始位置为 1;
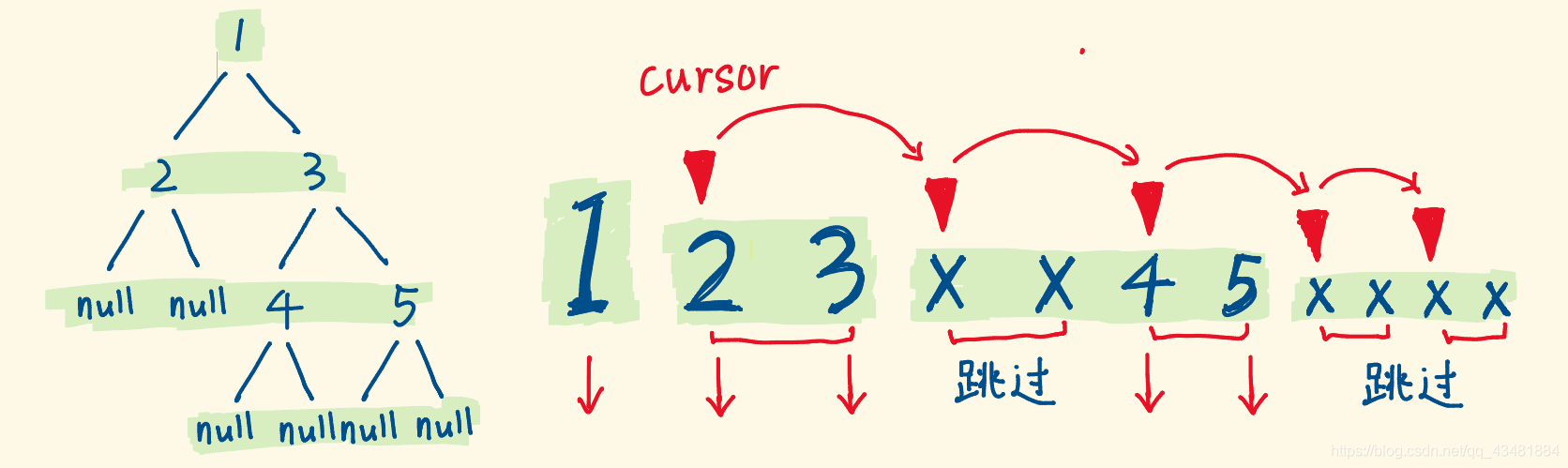
参照 LeetCode 方法构造的字符串,特点是会给出非空节点的左右孩子,那么左右孩子是成对出现的。可以使用两个指针,分别指向两个孩子。执行过程模拟如下:
队列 : [ 1, ]
数组:[1,2,3,X,X,4,5]
指针指向: 2 ,3
此时出队一个节点 “1” 作为 now ,创建左孩子节点,链到now 上,入队;创建右孩子节点,链到 now 上,并入队。
两个指针移动。
队列 : [ 2,3, ]
数组:[1,2,3,X,X,4,5]
指针指向: X ,X
此时的队首为 “2”,指针指向的恰好是 “2” 的左右孩子,继续上述步骤。由于 null 没有左右孩子,则不需要插入孩子的操作,又在构造节点时默认将左右域置为空,所以也没有链接的操作,即不做任何操作。
队列 : [ 3, ]
数组:[1,2,3,X,X,4,5]
指针指向: 4 ,5
数组遍历完毕,构造结束。
将上述过程总结如下:
- 构造一个队列,创建根节点并入队。创建一个指针,指向 “1”。(一次进行两次操作,就相当于有两个指针。)
- 出队一个元素,目前指针所指就是队首的两个孩子。若为空,则不做任何操作;若不空,创建左右节点,链接到队首,并入队,作为下一次迭代的根节点。
- 数组遍历完毕,构造结束。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









