




🚀 优质资源分享 🚀
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
你好呀,我是歪歪。
我最近其实在思考一个问题:
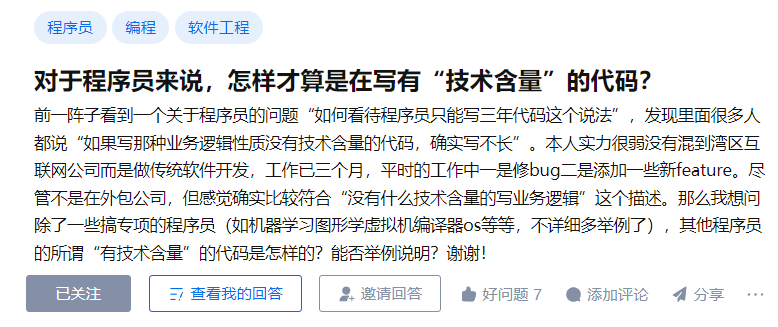
对于程序员来说,怎样才算是在写有“技术含量”的代码?
为什么会想起思考这个看起来就很厉(装)害(逼)的问题呢?
因为这就是知乎上的一个问题:
https://www.zhihu.com/question/37093538
第一次看到这个问题的时候,我很快的就划过去了,完全就没有关注这个问题。但是就是看了那么一眼,这个问题就偶尔不经意间在脑海中浮现出来。
然后隔了一段时间,中午刷知乎的时候这个问题又冒出来了。
好巧不巧,也是那天中午,我看到了这样的一个面试题:

看到这个面试题的第一眼,我就想起了 Dubbo 服务中的一个预热功能。
在结合知乎这个问题,我当时就觉得:Dubbo 服务的预热源码在我看来就是一个“有技术含量”的代码呀。
这一块功能编码确实一点也不复杂,主要是能体现出编码的人对于 JVM 和 RPC 方面的“内功”,能够意识到,由于 JVM 的编译特点,再加上 Dubbo 在架构中充当着 RPC 框架的角色,所以为了服务最大程度上的稳定,可以在编码的层面做一定的服务预热。
但是写完相关回答之后,从评论区来看,基本上是清一色的吐槽,说我举得这个例子和问题相悖。
比如我截取点赞最高的两个评论:

看完这些吐槽之后,我觉得这些吐槽是有道理的,我的例子举得确实不好,非常的片面。
为了更好的引出这个话题,我先搬运并扩充一下我当时的回答吧。
顺便也算是回答一下刚刚说的那个面试题。
服务预热
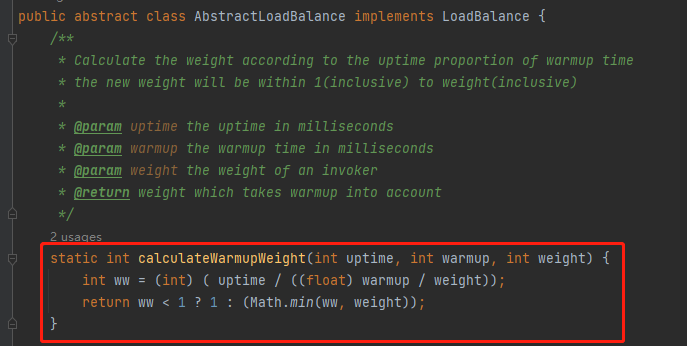
下面这个方法,只有两行,但是这就是 Dubbo 服务预热功能的核心代码:
org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance#calculateWarmupWeight
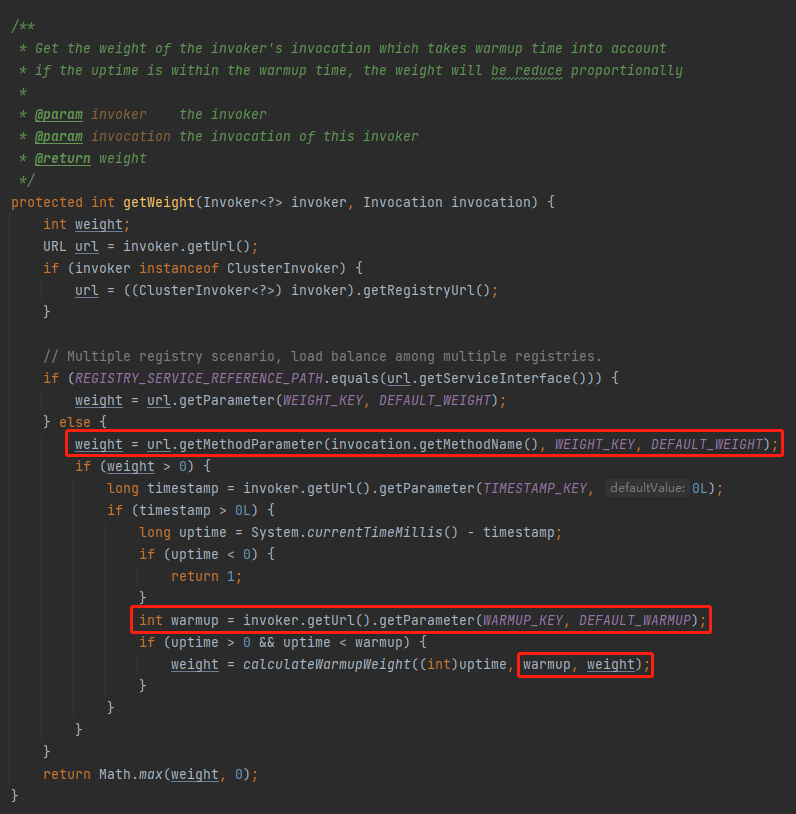
看一下这个方法在框架里面调用的地方:
当我们不指定参数的情况下,入参 warmup 和 weight 是有默认值的:
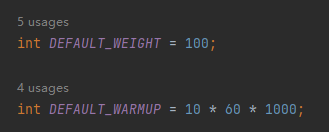
也就是在用默认
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









