




对数据库的三种操作:
库操作,表操作,字段操作
数据库操作:
1、新增数据库:
Create database 数据库的名称 [库选项]
举例:
Create database students charset utf8;
库选项:用来约束数据库,分为两个选项,
字符集设定:
charset/character set 具体字符集(数据存储的编码格式)
常用字符集:GBK和UTF-8
校对集设定:collate 具体校对集(数据比较的规则)
注意事项:
双中划线,单行注释,也可以用#来表示
数据库不能使用关键字或者保留字,报错之后会报告大概的位置(静默模式)
如果非要使用关键字或者保留字,那么必须加上单引号在关键字上
关于创建中文名称的数据库:
解决方案:告诉服务器当前的中文的字符集是什么
set names gbk;
create database 中国 charset utf8;
2、查看数据库:
show databases;
查看指定的数据库:模糊查询
show databases like 'pattern';
举例:
show databases like 's%';(查询以s开头的数据库)
注意:转义字符
查看数据库创建语句
show create database 数据库名称;
更新数据库:
数据库的名称是不可以修改的
数据库的修改仅限库选项:字符集和校对集(校对集依赖于字符集)
alter database 数据库名称 [库名称];
举例:
alter database 数据库名称 charset GBK;
3、删除数据库:
drop databases 数据库名称;
删除数据库语句后发生了什么?
1、在数据库内部看不到对应的数据库
2、在对应的数据库存储的文件夹内,数据库名字对应的文件夹也删除、
(级联删除:里面的数据表全部被删除,删除不可逆)
表操作
表与字段密不可分
新增数据表:
create table [if noe exists] 表名(
字段名字 数据类型,
字段名字 数据烈性 -- 最后一行不需要逗号)[表选项];
if not exists:如果表名不存在,那么就存在,那么就创建,否则不执行创建代码,:检查功能
表选项:控制表的表现
字符集:charset/character set 具体字符集; – 保证表中数据存储的字符集
校对集:collate 具体校对集;
存储引擎:engine 具体的存储引擎
举例:
create table if not exists student(
name varchar(10),
gender varchar(10),
number varchar(10)
age int)charset utf8;
任何一个表的设计都必须指定一个数据库
指定数据库的两种方式:
方式一:
隐士的指定表所属数据库:先进入到某个数据库环境,创建的表默认是本数据库中的数据表
查询正在使用的数据库:
select database;
使用数据库:
use 数据库名称;
方式二:(提前指定数据库的名称)
create table [if noe exists] 数据库名字.表名(
字段名字 数据类型,
字段名字 数据烈性 -- 最后一行不需要逗号)[表选项];
当创建数据表的sql指令执行之后发生了什么?
1、指定数据库下已经存在的表
2、在数据库对应额文件夹下,会产生对应表的结构文件(跟存储引擎有关系)
数据表
1、 查看数据表:
1、查看所有表:
show tables;
模糊匹配举例:
查看以s结尾的表:
show tables like '%s'; (效率低)
2、查询表的创建信息:
show create table 表的名称;
show create table 表名\G -- 可以清楚结构,自动换行
show create table 表名\g -- 与上方的查询方式一致,不会自动换行
3、查询表结构:查看表中的字段信息(/代表的是或的意思,采用任何一个命令都可以
Desc/describe/show columns from 表名;
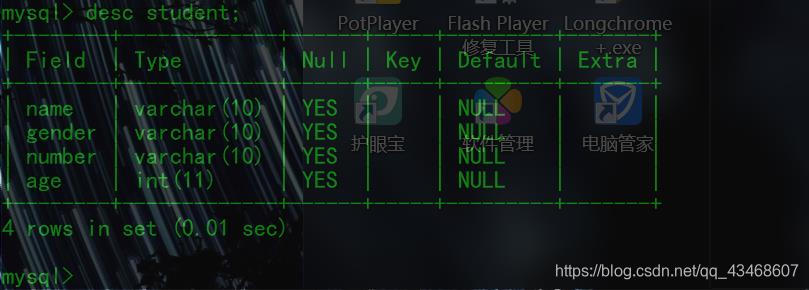
Type:字段的类型:数据类型
Null:列属性:是否允许为NUll(空)
Key:索引类型(PRI),UNI唯一键等
Default:列属性:默认值:大部分字段默认为NUll
Extra:列属性:扩充(额外的),描述
2、修改数据表:
表本身存在,还包含字段,表修改分为:表本身和修改字段
1、修改表本身:表名和表选型
修改表名:rename 老表 to 新表名;
2、修改表选项:字符集
alter table 表名 表选项;
举例:
alter table 表名 charset = GBK;
3、删除数据表:
drop table 表名;
drop table 表名1,表名2,表名3。。。。。; -- 可以一次性删除多张表
修改字段
字段操作很多:新增,修改,重命名,删除
1、新增字段:
Alter table 表名[column] 字段名 数据类型 [位置];
举例:
alert table 表名 [add column] id int first;
2、修改字段
alter table 表名 modify 字段名 数据类型 [属性] [位置];
举例:
alter table 表名 modify 字段名 数据类型 (after id); -- 在id字段后的后面
重命名字段:
alater table 表名 change 老字段 新字段 数据类型 [属性] [位置];
3、删除字段
alter table 表名 drop 字段名
添加数据
有两种方案,
方案一:
给全表字段插入数据,不需要指定字段列表:要求数据的值出现的顺序必须与表中设计的字段出现的顺序一致,凡是非数值数据,都需要使用引号(建议是单引号)包裹
Insert into 表名 values(值列表)[,(值列表)]; -- 可以一次性插入多条记录
强调:与数据类型与位置一一对应
方案二:给部分字段插入数据,需要选定字段列表,字段列表出现的顺序与字段的顺序无关;但是值列表的孙旭必须与选定的字段的顺序一致;
insert into 表名 (字段列表) value (值列表)[,(值列表)];
中文数据问题
本质是字符集问题,计算机只识别二进制:人类更多是识别符号,需要有个二进制与字符的对应关系(字符集)
查看所有字符集:show character set;
服务器是万能,什么字符集都在支持
解决方法一:
查看服务器默认的对外处理的字符集:show variables like ‘character_set%’;
一个汉字=两个字节=16bit
如上图client客户端的字符集是gbk;改变服务器,默认为接受字符集的value
改变客户端的字符集为gbk:
set character_set_client = gbk;
数据来源是服务器,解析数据是客户端(客户端只识别GBK)
如果服务器给的数据是utf8,三个字节一个汉字,二gbk是两个字节一个汉字,所以永远都是乱码
修改服务器给定数据的字符集为gbk
set character_set_results = gbk;
上面的方法是当前执行有效,重启失效
设置服务器对客户端的字符集的认识:可以使用快捷方法:set names 字符集
举例:set names gbk
connection连接层:是字符集转变的中间者,如果同意了效率更高,不统一也没为题
Web乱码问题
动态网站由三部分构成:浏览器,apache服务器(PHP),数据库服务器,三个部分都有自己的字符集(中文),数据需要在三个部分之间来回传递,很容易产生乱码
解决方法:统一编码(三码合一):
但是事实上不可能:浏览器是用户管理(根本不可能控制)
但是必须要解决这个问题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











