










 本文深入探讨JavaScript中的正则表达式,通过RegExp对象创建、常用方法如test()和exec(),以及各种元字符和限定符的使用。文章介绍了直接量字符、字符类、贪婪与非贪婪表达式、分组和断言等核心概念,提供了丰富的实例帮助理解。
本文深入探讨JavaScript中的正则表达式,通过RegExp对象创建、常用方法如test()和exec(),以及各种元字符和限定符的使用。文章介绍了直接量字符、字符类、贪婪与非贪婪表达式、分组和断言等核心概念,提供了丰富的实例帮助理解。
正则表达式
目前,正则表达式已经在很多软件中得到广泛的应用,包括linux,unix和HP等操作系统;以及PHP,Java,C#,JS等开发环境中。另外在许多应用软件,移动端中,都可以看到正则表达式的影子。
本文主要分享用以描述“文本模式”的正则表达式语法。正则表达式中的String和RegExp中的方法会在之后的文章与大家分享。
但由于要充分理解本文中的案例,本文简单介绍涉及一些RegExg中的方法,希望读者留意。
文章目录
正则表达式(regular expression)是一个描述字符串匹配模式的对象。它具有以下几个主要功能:
- 正则表达式可以从字符串中查找满足需要的数据
- 正则表达式可以从字符串中获取满足需要的数据
- 正则表达式可以从字符串中替换满足需要的数据
在JS中定义一个正则表达式
在JavaScript中,正则表达式用RegExp对象来表示,可以使用RegExp()构造函数来创建RegExp对象
- 字面量定义
/…/ 以 / 开头,/ 结尾,中间内容为正则表达式。即正则表达式直接量定义为包含在一对斜杠之间的字符。
let regex = /[abc]/; //创建一个新的RegExp对象,并将其赋值给regex变量
- 使用new RegExp 对象定义
let regex = new RegExp("[abc]"); //此代码可以将一个字符串转成正则表达式
或
let regex = new RegExp(/[abc]/);
RegExp中的两个常用方法
- text():返回一个boolean值,代表是否匹配(匹配成功返回true,否则返回false)
let str = "abcdefg";
let regex = /[abc]/;
console.log(regex.test(str));//匹配成功,返回结果为true
- exec():exec()会返回一个数组,数组中索引号为0的元素是整个正则表达式匹配的内容。若不匹配,返回值为null
let str = "abcdefg";
let regex = /[abc]/;
console.log(regex.exec(str));//匹配成功,返回结果为abc
索引大于0的数据,代表的是正则表达式中子表达式(分组匹配的内容)
exec()有如下属性:
- index: 代表 匹配的元素的索引位置
- groups : 用来获取 命名捕获分组 匹配的数据
- input : 原始字符串
正则表达式中的直接量字符
| 字符 | 匹配 |
|---|---|
| \o | NUL字符(\u0000) |
| \t | 制表符(\u0009) |
| \n | 换行符(\u000A) |
| \v | 垂直制表符(\u000B) |
| \f | 换页符(\u000C) |
| \r | 回车符(\u000D) |
| \xnn | 由十六进制数nn指定的拉丁字符,例如\x0A等价于\n |
| \uxxxx | 由十六进制数xxxx指定的Unicode字符,例如\u0009等价于\t |
| \cX | 控制字符^X,例如,\cJ等价于换行符\n |
正则表达式中的字符类
-
abc :匹配abc字符串
-
[]:中括号中可以写多个任意字符,代表只匹配一个字符,且字符顺序也是任意的
例如:[abc]:代表可以匹配abc中三个子母中任意的一个字符
【小结】abc与[abc]的区别:
直接写abc,则代表匹配’abc’这个字符串,也就是说,只有当被匹配的字符串中出现连续且顺序不变的‘abc’时,才能够匹配成功;
加上中括号,则代表只要被匹配的字符串中出现‘a’,‘b’,'c’任意一个时,就会匹配成功。
例如:
let str1 = "qwerasdf";
let str2 = "abcdefg";
let regex1 = \[abc]\;
let regex2 = \abc\;
console.log(regex1.test(str1));//匹配成功,结果为true
console.log(regex2.test(str2));//匹配成功,结果为true
console.log(regex2.test(str1));//尝试匹配str1,匹配失败,因为str1中无连续abc字符集
-
-:中划线代表Acra码中连续的字符
例如: [a-z]:代表小写字母中的任意一个
[A-Z]:代表大写字母中的任意一个
[a-zA-Z]:匹配所有的字母
[0-9]:匹配所有的数字
-
[^ ]:中括号中以^开头,代表 非
例如: [^0-9] :匹配出数字之外的所有字符
-
\d:匹配任意一个数字,等价于[0-9]
\D:匹配任意一个非数字,等价于【^0-9】
-
\w:匹配字母、数字和下划线中任意一个字符串 [a-zA-Z0-9_]
\W:匹配除了字母、数字和下划线中任意一个字符串 【^a-zA-Z0-9_】
-
\s:匹配任意一个空白字符(换行符,空格以及Tab制表符)
\S:匹配任意一个非空白字符
-
.:匹配除换行符之外的任意一个字符
-
X{n}:正则表达式匹配多个字符的方法,n代表个数
例如:/[a-z]{3}/ //可以匹配3个元素
X{n,}:至少匹配n个元素 //无法匹配,返回null
X{n,m}:至少匹配n个元素,最多匹配m个元素 //无法匹配,返回null
贪婪表达式
贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配
- X*:代表匹配0到多个元素,等价于X{0,}
- X+:代表匹配1到多个元素,等价于X{1,}
- X?:代表最多匹配1个元素,等价于X{0,1}
非贪婪表达式,在贪婪表达式后添加一个 ?
非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配
- X*?:代表匹配0到多个元素
- X+?:代表至少匹配1个元素
- X??:代表最多匹配1个元素
【小结】什么是贪婪模式和非贪婪模式
先看一个例子
源字符串:aa< div>test1</ div>bb< div>test2</ div>cc
正则表达式一:< div>.*</ div>
匹配结果一:< div>test1</ div>bb< div>test2</ div>
正则表达式二:< div>.*?</ div>
匹配结果二:< div>test1</ div>(这里指的是一次匹配结果,所以没包括< div>test2</ div>)
根据上面的例子,从匹配行为上分析一下,什是贪婪与非贪婪模式。
正则表达式一采用的是贪婪模式,在匹配到第一个“</ div>”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串,匹配到第二个“</ div>”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“< div>test1</ div>bb< div>test2</ div>”。当然,实际的匹配过程并不是这样的,后面的匹配原理会详细介绍。
仅从应用角度分析,可以这样认为,贪婪模式,就是在整个表达式匹配成功的前提下,尽可能多的匹配,也就是所谓的“贪婪”,通俗点讲,就是看到想要的,有多少就捡多少,除非再也没有想要的了。
正则表达式二采用的是非贪婪模式,在匹配到第一个“</ div>”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“< div>test1</ div>”。
仅从应用角度分析,可以这样认为,非贪婪模式,就是在整个表达式匹配成功的前提下,尽可能少的匹配,也就是所谓的“非贪婪”,通俗点讲,就是找到一个想要的捡起来就行了,至于还有没有没捡的就不管了。
贪婪表达式涉及的知识有很多且很复杂,对此知识有兴趣的读者可以移步这里(举例部分引用了此篇文章部分内容)
限定符(^和$)
^:如果出现在正则的第一个位置,则代表以……开头
$:如果出现在正则的最后一个位置,则代表以……结尾
举例:获取以a开头且以b结尾的字符集
let str = "aqwerasdfb";//以a开头以b结尾的字符串
let regex = /^a.*b$/;
console.log(regex.exec(str))//结果:"aqwerasdfb"
选择符(|)
|:代表逻辑或
例如,/|ab|cd|ef/可以匹配出字符串"ab",字符串"cd",还可以匹配出字符串"ef"
【注意】:选择项的尝试匹配次序是从左到右,直到发现了匹配项。如果左边的选择项匹配,就忽略右面的匹配项。因此,当正则表达式/a|ab/匹配字符串"ab"时,他只能匹配第一个字符a。
分组符(())
():代表分组,组从左到右查询,且以左括号 ( 来判断。用()括住的数据成功提取后可以通过exec()方法返回。
它一般有两个作用:
-
把单独项组合成子表达式,以便可以像处理一个独立单元那样用|,*,+等对单元内的项进行处理。
-
在完整的模式中定义子模式。当匹配成功时,可以抽出并查看括号内的子模式相匹配的部分。
引用(\num)
\num:引用第num组匹配的内容。num从1开始。
【注意】:num是一个数字
let str = `我们是'中国'人`;
let regexStr = /(["'])(.+)\1/;
console.log(regexStr.exec(str));
输出结果:

组
- (?< key >\d+):命名捕获组。将\d+匹配的内容赋给key,可以通过exec().groups来进行获取
- ?: :非捕获组。()会分组会形成子表达式,非捕获组不会提取出子表达式。
举例:
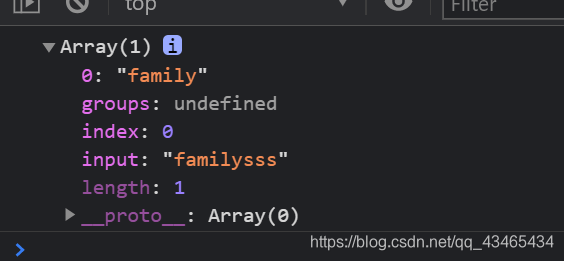
regex = /famil(?:y|ies)/
var s11 = "familysss" ;
console.log(regex.exec(s11))
输出结果:
断言
此部分内容引用了优快云作者nodebetacat文中的一些案例
原文链接:https://blog.youkuaiyun.com/qq_34456362/article/details/80617581
-
正向确定断言:?=
-
正向否定断言:?!
-
反向确定断言:?<=
-
反向否定断言:?<!
正向确定断言的意思是,被匹配内容只有在指定字符串前面才能匹配,格式为/被匹配内容(?=后面必须跟的内容)/
例如你要替换掉字符串中数字跟着百分号的部分
var before = "aaa123%ad121dfakm".replace(/\d+(?=%)/g,'');
最终before的内容为aaa%ad121afakm,这里要注意断言部分不会被替换掉哦。
正向否定断言的意思和正向确定断言正相反,被匹配的内容只有不在指定字符串前面才能被匹配。
还是上面那个例子,你要替换带字符串中不在百分号之前数字
var notbefore = "aaa123%ad121dfakm".replace(/\d{0,}(?!%)/g,'');
结果notbefore最终是aaa3%addfakm,虽然其他位置的数字被替换掉了,但是123%最终12部分也被替换掉了,怎么办呢?依旧使用正向否定断言进行限制
var notbefore = "aaa123%ad121dfakm".replace(/(\d{0,}(?!%))(?!\d)/g,'');
最终结果为 aaa123%addfakm 这是我们最终想要的格式
接下来是反向确定断言
反向确定指的是被匹配内容只有在指定内容之后才会被匹配到
这里举一个例子,例如你要替换掉冒号后面的斜杠为单斜杠
var after = 'http://aaa//wrwrw//12323//'.replace(/(?<=:)\/+/g,'/')
这里最终after的结果就是 http:/aaa//wrwrw//12323// 冒号后面的双斜杠被替换成单斜杠了
反向否定断言则正相反,被匹配的内容只有不在指定内容之后才会被匹配到
依旧是上面那个例子,你要替换掉不跟在冒号后面的多斜杠为单斜杠
var notafter = 'http://aaa//wrwrw//12323//'.replace(/(?<!:)\/+/g,'/')
最终notafter的结果为http://aaa/wrwrw/12323/
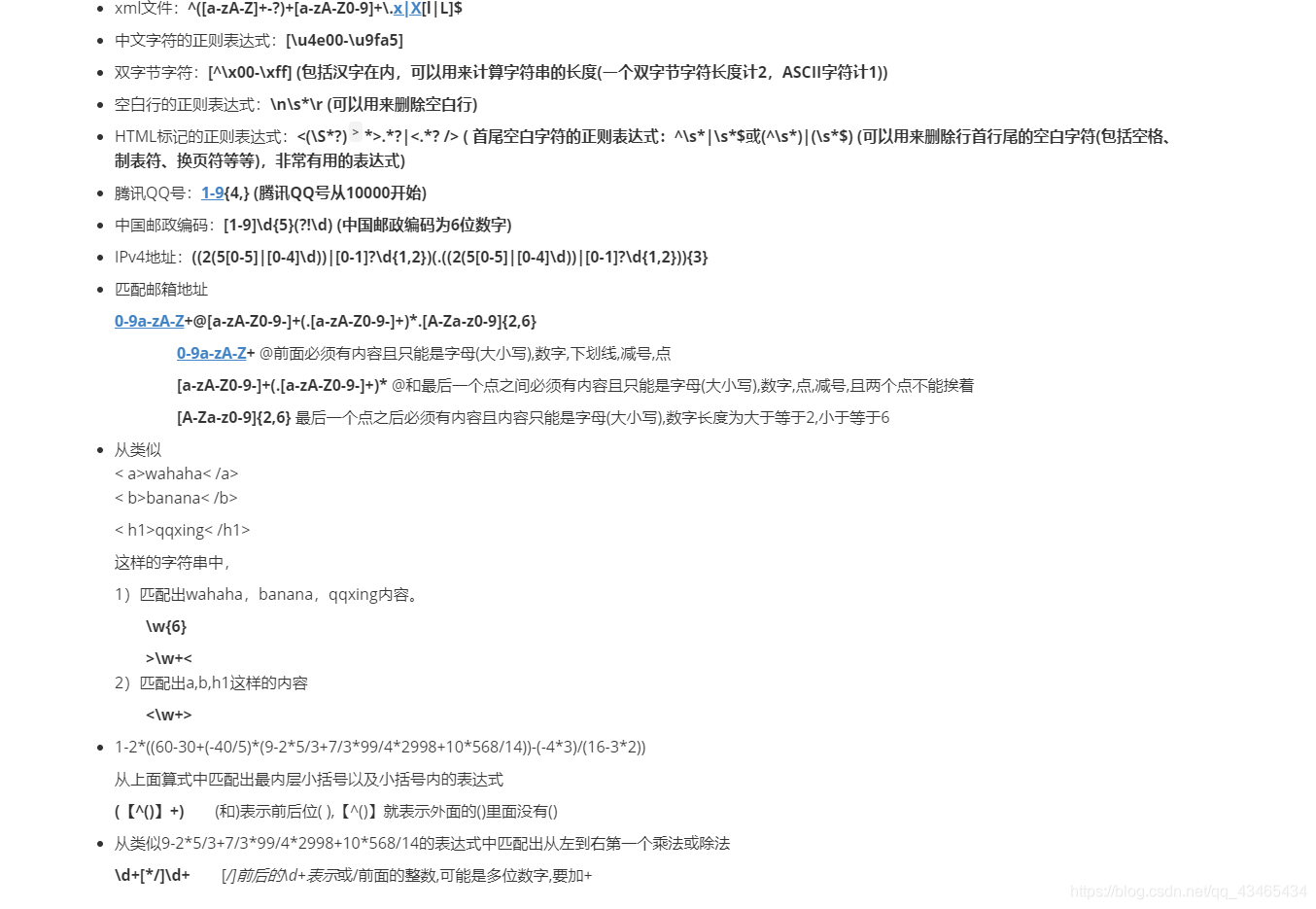
常用正则表达式



参考书籍
《JavaScript高级程序设计(第四版)》
《JavaScript权威指南(第三版)》
《正则表达式手册》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









