







 本文详细介绍了Java中的File类,包括构造器、路径分类、路径分隔符以及常用方法,如创建、删除、重命名文件。接着探讨了IO流的基本概念、分类和体系结构,强调了字节流和字符流的区别,以及输入输出流的使用。文章进一步讲解了文件字符流和字节流的读写操作,以及如何使用RandomAccessFile进行随机访问文件。最后提到了NIO(New IO)中的Path、Paths、Files类的使用,以及BIO、NIO和AIO的区别。
本文详细介绍了Java中的File类,包括构造器、路径分类、路径分隔符以及常用方法,如创建、删除、重命名文件。接着探讨了IO流的基本概念、分类和体系结构,强调了字节流和字符流的区别,以及输入输出流的使用。文章进一步讲解了文件字符流和字节流的读写操作,以及如何使用RandomAccessFile进行随机访问文件。最后提到了NIO(New IO)中的Path、Paths、Files类的使用,以及BIO、NIO和AIO的区别。
Java IO流
一、File类的使用
1. File类的理解
-
File类的一个对象,代表一个文件或一个文件目录(俗称:文件夹)。
-
java.io.File类:
文件和文件目录路径的抽象表示形式,与平台无关。 -
File类中涉及到关于文件或文件目录的新建、删除、重命名、修改时间、文件大小等方法,但
File类没有涉及到写入或读取文件内容的操作。如果需要写入或读取文件内容的操作,必须使用 IO流(输入/输出流)来完成。 -
想要在Java程序中表示一个真实存在的文件或目录,那么必须有一个File对象,但是Java程序中的一个File对象,可能没有一个真实存在的文件或目录。 -
后续File类的对象常会作为参数传递到流的构造器中,指明读取或写入的"终点"。
2. File的实例化
2.1 常用构造器
-
File(String filePath)
以filePath为路径创建File对象,
可以是绝对路径和相对路径,如果filePath是相对路径,则默认当前路径在系统属性user.dir中存储。绝对路径:是一个固定路径,从盘符开始相对路径:是相对于某个位置开始
-
File(String parent,String child)
以parent为父路径,child为子路径创建File对象(child子路径可以是文件或文件目录)
-
File(File parent,String childPath)
根据一个父File对象和子文件路径创建File对象
代码示例:
@Test
public void test1() {
//构造器1
File file1 = new File("hello.txt");
File file2 = new File("E:\\workspace\\JavaSenic\\day8\\hello.txt");
System.out.println(file1);//==> hello.txt
System.out.println(file2);//==> E:\workspace\JavaSenic\day8\hello.txt
//构造器2
File file3 = new File("E:\\workspace\\JavaSenior\\day8", "hello.txt");
System.out.println(file3);//==> E:\workspace\JavaSenior\day8\hello.txt
File file4 = new File("E:\\workspace", "JavaSenior");
System.out.println(file4);//==> E:\workspace\JavaSenior
//构造器3
File file5 = new File(file3, "hi.txt");
System.out.println(file5);//==> E:\workspace\JavaSenior\day8\hello.txt\hi.txt
}
2.2 路径分类
- 相对路径:相较于某个路径下,指明的路径。
- 绝对路径:包含盘符在内的文件或文件目录的路径。
说明:
- IDEA中:
- 如果使用JUnit中的单元测试方法测试,相对路径即为当前Module下。
- 如果使用main()测试,相对路径即为当前的Project下。
- Eclipse中:
- 不管使用单元测试方法还是使用main()测试,相对路径都是当前的Project下。
2.3 路径分隔符
-
路径中的每级目录之间用一个
路径分隔符隔开。不同操作系统路径分隔符也不一样。 -
windows和DOS系统默认使用“\”来表示
-
UNIX和URL使用“/”来表示
-
Java程序支持跨平台运行,因此路径分隔符要慎用。 -
为了解决这个隐患,File类提供了一个常量:
public static final String separator。根据操作系统,动态的提供分隔符。举例:
//windows和DOS系统 File file1 = new File("E:\\io\\test.txt"); //UNIX和URL File file = new File("E:/io/test.txt"); //java提供的常量File.separator File file = new File("E:"+File.separator+"io"+File.separator+"test.txt");
3. File类的常用方法
3.1 File类的获取功能
-
public String getAbsolutePath():获取绝对路径
-
public String getPath() :获取路径
-
public String getName() :获取名称
-
public String getParent():获取上层文件目录路径。若无,返回null
-
public long length() :获取文件长度(即:字节数)。不能获取目录的长度。
-
public long lastModified() :获取最后一次的修改时间,毫秒值
如下的两个方法适用于文件目录: -
public String[] list() :获取指定目录下的所有文件或者文件目录的名称数组
-
public File[] listFiles() :获取指定目录下的所有文件或者文件目录的File数组
代码示例:
@Test
public void test2(){
File file1 = new File("hello.txt");
File file2 = new File("d:\\io\\hi.txt");
System.out.println(file1.getAbsolutePath());//E:\Java\day08\hello.txt
System.out.println(file1.getPath());//hello.txt
System.out.println(file1.getName());//hello.txt
System.out.println(file1.getParent());
System.out.println(file1.length());
System.out.println(new Date(file1.lastModified()));
System.out.println();
System.out.println(file2.getAbsolutePath());// d:\io\hi.txt
System.out.println(file2.getPath());// d:\io\hi.txt
System.out.println(file2.getName());// hi.txt
System.out.println(file2.getParent());// d:\io
System.out.println(file2.length());
System.out.println(file2.lastModified());
}
@Test
public void test3(){
File file = new File("D:\\workspace_idea1\\JavaSenior");
String[] list = file.list();
for(String s : list){
System.out.println(s);
}
System.out.println();
File[] files = file.listFiles();
for(File f : files){
System.out.println(f);
}
}
3.2 File类的重命名功能
- public boolean renameTo(File dest):把文件重命名为指定的文件路径
- 注意:file1.renameTo(file2)为例:要想保证返回true,需要file1在硬盘中是存在的,且file2不能在硬盘中存在。
代码示例:
@Test
public void test4(){
File file1 = new File("hello.txt");//hello.txt存在
File file2 = new File("D:\\hi.txt");//hi.txt不存在
boolean renameTo = file2.renameTo(file1);
System.out.println(renameTo);//true, 再执行一遍就是flase
//执行效果file1存在,file2不存在,执行后返回true,并且hello.txt删除了,而hi.txt则新建出来并且内容是hello.txt中的内容。(把原文件移动到指定路径,包括其内容,只是文件名字改变为指定的)
}
3.3 File类的判断功能
- public boolean isDirectory():判断是否是文件目录
- public boolean isFile() :判断是否是文件
- public boolean exists() :判断是否存在
- public boolean canRead() :判断是否可读
- public boolean canWrite() :判断是否可写
- public boolean isHidden() :判断是否隐藏
代码示例:
@Test
public void test5(){
File file1 = new File("hello.txt");
file1 = new File("hello1.txt");
System.out.println(file1.isDirectory());
System.out.println(file1.isFile());
System.out.println(file1.exists());
System.out.println(file1.canRead());
System.out.println(file1.canWrite());
System.out.println(file1.isHidden());
System.out.println();
File file2 = new File("d:\\io");
file2 = new File("d:\\io1");
System.out.println(file2.isDirectory());
System.out.println(file2.isFile());
System.out.println(file2.exists());
System.out.println(file2.canRead());
System.out.println(file2.canWrite());
System.out.println(file2.isHidden());
}
3.4 File类的创建功能
创建硬盘中对应的文件或文件目录:
- public boolean createNewFile() :创建文件。若文件存在,则不创建,返回false
- public boolean mkdir() :创建文件目录。如果此文件目录存在,就不创建了。如果此文件目录的上层目录不存在,也不创建。
- public boolean mkdirs() :创建文件目录。如果此文件目录存在,就不创建了。如果上层文件目录不存在,一并创建。
注意事项:如果创建的文件或者文件目录没有写盘符路径,默认在项目路径下。
代码示例:
@Test
public void test6() throws IOException {
File file1 = new File("hi.txt");
if(!file1.exists()){
//文件的创建
file1.createNewFile();
System.out.println("创建成功");
}else{//文件存在
file1.delete();
System.out.println("删除成功");
}
}
@Test
public void test7(){
//文件目录的创建
File file1 = new File("d:\\io\\io1\\io3");
boolean mkdir = file1.mkdir();
if(mkdir){
System.out.println("创建成功1");
}
File file2 = new File("d:\\io\\io1\\io4");
boolean mkdir1 = file2.mkdirs();
if(mkdir1){
System.out.println("创建成功2");
}
//要想删除成功,io4文件目录下不能有子目录或文件
File file3 = new File("D:\\io\\io1\\io4");
file3 = new File("D:\\io\\io1");
System.out.println(file3.delete());
}
3.5 File类的删除功能
删除磁盘中的文件或文件目录
-
public boolean delete():删除文件或者文件夹
-
删除注意事项:Java中的删除不走回收站。
要删除一个文件目录,请注意该文件目录内不能包含文件或者文件目录。
4. 内存解析
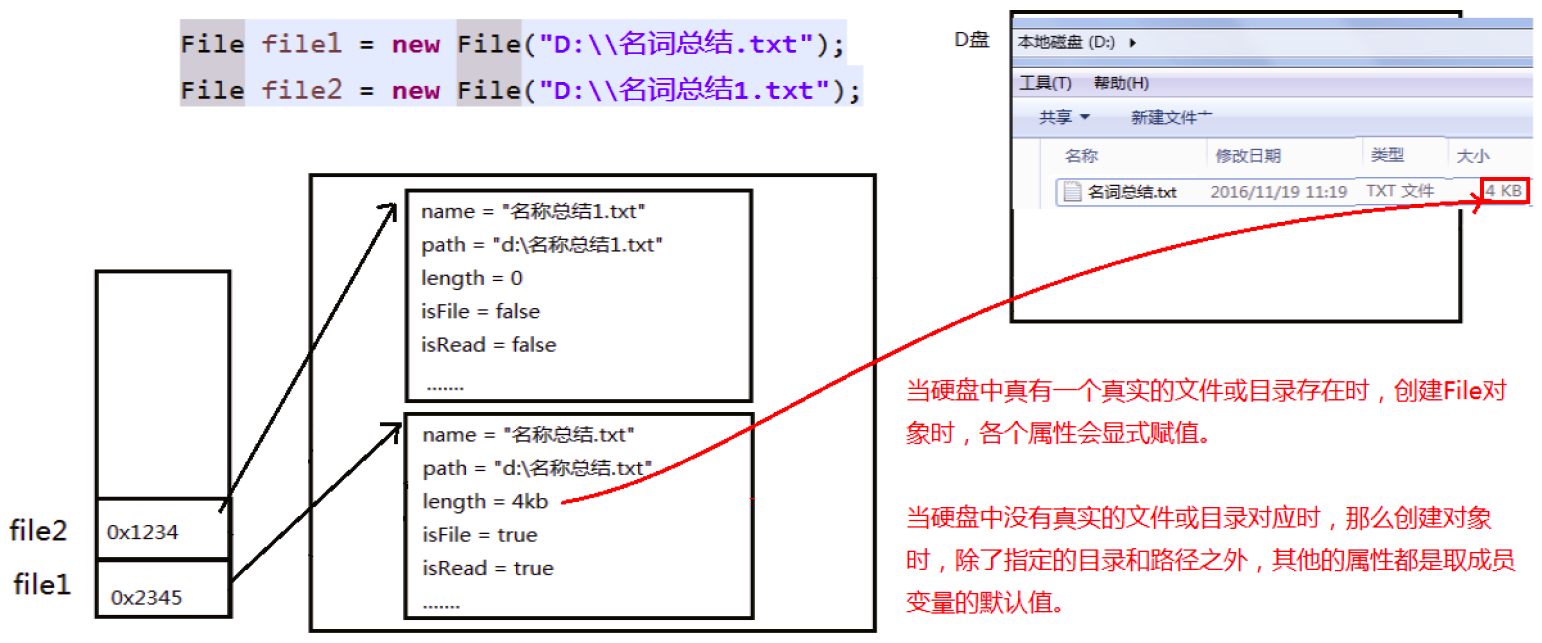
5. 小练习
利用File构造器,new一个文件目录file :
(1)在其中创建多个文件和目录
(2)编写方法,实现删除fle中指定文件的操作
@Test
public void test1() throws IOException {
File file = new File("E:\\io\\io1\\hello.txt");
//创建一个与file同目录下的另外一个文件,文件名为:haha.txt
File destFile = new File(file.getParent(),"haha.txt");
boolean newFile = destFile.createNewFile();
if(newFile){
System.out.println("创建成功!");
}
}
判断指定目录下是否有后缀名为jpg的文件,如果有,就输出该文件名称
public class FindJPGFileTest {
@Test
public void test1(){
File srcFile = new File("d:\\code");
String[] fileNames = srcFile.list();
for(String fileName : fileNames){
if(fileName.endsWith(".jpg")){
System.out.println(fileName);
}
}
}
@Test
public void test2(){
File srcFile = new File("d:\\code");
File[] listFiles = srcFile.listFiles();
for(File file : listFiles){
if(file.getName().endsWith(".jpg")){
System.out.println(file.getAbsolutePath());
}
}
}
/*
* File类提供了两个文件过滤器方法
* public String[] list(FilenameFilter filter)
* public File[] listFiles(FileFilter filter)
*/
@Test
public void test3(){
File srcFile = new File("d:\\code");
File[] subFiles = srcFile.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".jpg");
}
});
for(File file : subFiles){
System.out.println(file.getAbsolutePath());
}
}
}
遍历指定目录所有文件名称,包括子文件目录中的文件。
拓展1:并计算指定目录占用空间的大小
拓展2:删除指定文件目录及其下的所有文件
public class ListFileTest {
public static void main(String[] args) {
// 递归:文件目录
/** 打印出指定目录所有文件名称,包括子文件目录中的文件 */
//1.创建目录对象
File file = new File("E:\\test");
//2.打印子目录
printSubFile(file);
}
/**
* 递归方法遍历所有目录下的文件
*
* @param dir
*/
public static void printSubFile(File dir) {
//打印子目录
File[] files = dir.listFiles();
for (File f : files) {
if (f.isDirectory()) {//如果为文件目录,则递归调用自身
printSubFile(f);
} else {
System.out.println(f.getAbsolutePath());//输出绝对路径
}
}
}
// 拓展1:求指定目录所在空间的大小
// 求任意一个目录的总大小
public long getDirectorySize(File file) {
// file是文件,那么直接返回file.length()
// file是目录,把它的下一级的所有大小加起来就是它的总大小
long size = 0;
if (file.isFile()) {
size += file.length();
} else {
File[] allFiles = file.listFiles();// 获取file的下一级
// 累加all[i]的大小
for (File f : allFiles) {
size += getDirectorySize(f);//f的大小
}
}
return size;
}
/**
* 拓展2:删除指定的目录
*/
public void deleteDirectory(File file) {
// 如果file是文件,直接delete
// 如果file是目录,先把它的下一级干掉,然后删除自己
if (file.isDirectory()) {
File[] allFiles = file.listFiles();
//递归调用删除file下一级
for (File f : allFiles) {
deleteDirectory(f);
}
} else {
//删除文件
file.delete();
}
}
}
二、IO流概述
1. 简述
- IO是Input/Output的缩写,I/O技术是非常实用的技术,用于
处理设备之间的数据传输。如读/写文件,网络通讯等。 - Java程序中,对于数据的输入输出操作以 “流(stream)” 的方式进行。
- Java.IO包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过
标准的方法输入或输出数据。
2. 流的分类
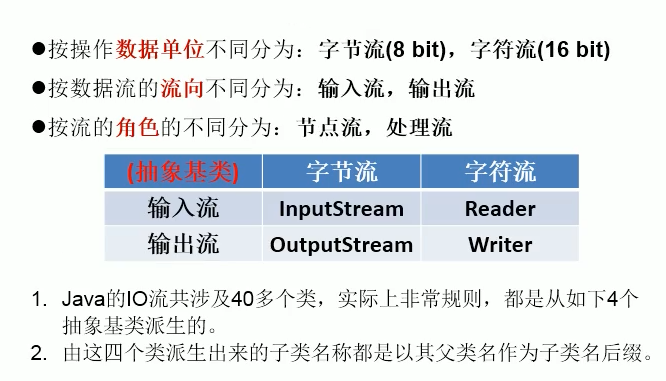
(1)按操作数据单位:字节流、字符流
-
对于文本文件(.txt,.java,.c,.cpp),使用字符流处理
-
对于非文本文件(.jpg,.mp3,.mp4,.avi,.doc,.ppt,…),使用字节流处理
(2) 按数据的流向:输入流、输出流
-
输入流input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
-
输出流output:将程序(内存)数据输出到磁盘、光盘等存储设备中。
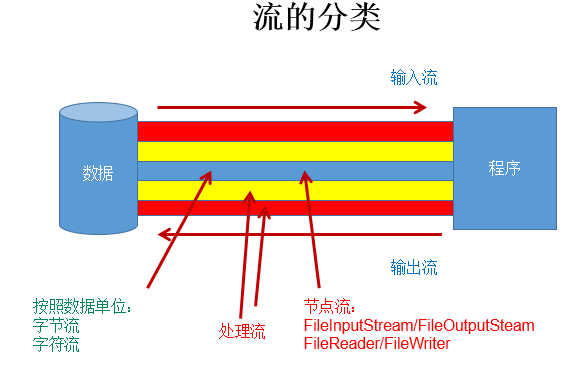
(3)按流的角色:节点流、处理流
- 节点流:直接从数据源或目的地读写数据。

- 处理流:不直接连接到数据源或目的地,而是“连接”在已存在的流(节点流或处理流)之上,通过对数据的处理为程序提供更为强大的读写功能。(就是“套接”在已有的流上)

图示:
3. IO流的体系结构
3.1 总体分类
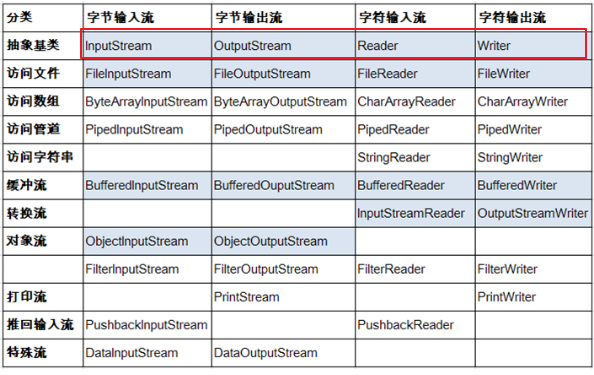
红框为抽象基类,蓝框为常用IO流
3.2 常用的几个IO流结构
| 抽象基类 | 节点流(或文件流) | 缓冲流(处理流的一种) |
|---|---|---|
| InputStream | FileInputStream (read(byte[] buffer)) | BufferedInputStream (read(byte[] buffer)) |
| OutputSteam | FileOutputStream (write(byte[] buffer,0,len) | BufferedOutputStream (write(byte[] buffer,0,len) / flush() |
| Reader | FileReader (read(char[] cbuf)) | BufferedReader (read(char[] cbuf) / readLine()) |
| Writer | FileWriter (write(char[] cbuf,0,len) | BufferedWriter (write(char[] cbuf,0,len) / flush() |
3.3 常用节点流和处理流
(1) 常用节点流
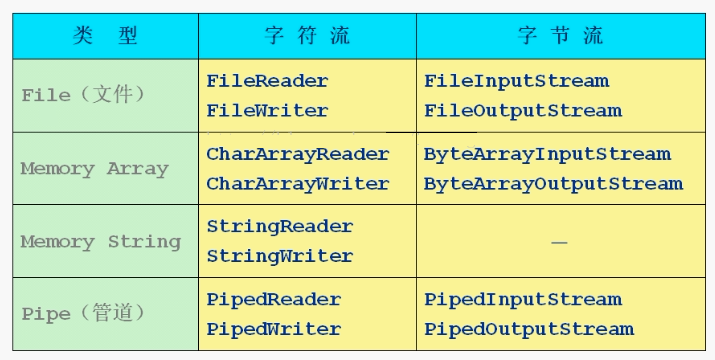
-
File文件流:对文件进行读、写操作 :FileReader、FileWriter、FileInputStream、FileOutputStream。 -
字符串:对字符串进行处理的节点流: StringReader、 StringWriter -
数组:对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组): ByteArrayInputStream 、ByteArrayOutputStream、 CharArrayReader 、CharArrayWriter 。 -
Pipe管道流:实现管道的输入和输出(进程间通信): PipedReader与PipedWriter、PipedInputStream与PipedOutputStream。
(2) 常用处理流

缓冲流:在读入或写出时,对数据进行缓存,避免频繁读写硬盘:BufferedReader与BufferedWriter、BufferedInputStream与BufferedOutputStream。滤流:在数据进行读或写时进行过滤:FilterReader与FilterWriter、FilterInputStream与FilterOutputStream。转换流:实现字节流和字符流之间的转换InputStreamReader、OutputStreamWriter。对象流:ObjectInputStream、ObjectOutputStream。数据流:按基本数据类型读、写(处理的数据是Java的基本类型(如布尔型,字节,整数和浮点数)):DataInputStream、DataOutputStream 。计数流:在读入数据时对行记数 :LineNumberReader、LineNumberInputStream。预读流:通过缓存机制,进行预读 :PushbackReader、PushbackInputStream。打印流:包含方便的打印方法 :PrintWriter、PrintStream。
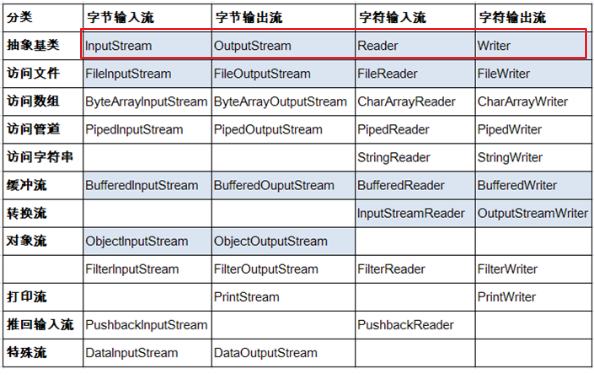
3.4 抽象基类的说明:
| 抽象基类 | 字节流 | 字符流 |
|---|---|---|
| 输入流 | InputSteam | Reader |
| 输出流 | OutputSteam | Writer |
- 说明:Java的lO流共涉及40多个类,实际上非常规则,都是从如下4个抽象基类派生的。
- 由这四个类派生出来的子类名称都是以其父类名作为子类名后缀。
3.4.1 InputSteam & Reader
- InputStream和Reader是所有输入流的基类。
- InputStream(典型实现:FileInputStream)
- int read()
- int read(byte[] b)
- int read(byte[] b,int off,int len)
- Reader(典型实现:FileReader)
- int read()
- int read(char[] c)
- int read(char[] c,int off,int len)
- 程序中打开的文件IO资源不属于内存里的资源,垃圾回收机制无法回收该资源,所以应该显式关闭文件IO资源。
- FileInputStream从文件系统中的某个文件中获得输入字节。FileInputStream用于读取非文本数据之类的原始字节流。要读取字符流,需要使用 FileReader。
InputSteam:
-
int read()
从输入流中读取数据的下一个字节。返回0到255范围内的int字节值。如果因为已经到达流末尾而没有可用的字节,则返回值-1。
-
int read(byte[] b)
从此输入流中将最多b.length个字节的数据读入一个byte数组中。如果因为已经到达流末尾而没有可用的字节,则返回值-1.否则以整数形式返回实际读取的字节数。
-
int read(byte[] b,int off,int len)
将输入流中最多len个数据字节读入byte数组。尝试读取len个字节,但读取的字节也可能小于该值。以整数形式返回实际读取的字节数。如果因为流位于文件末尾而没有可用的字节,则返回值-1。
-
public void close throws IOException
关闭此输入流并释放与该流关联的所有系统资源。
Reader:
-
int read()
读取单个字符。作为整数读取的字符,范围在0到65535之间(0x00-0xffff)(2个字节的 Unicode码),如果已到达流的末尾,则返回-1。
-
int read(char[] cbuf)
将字符读入数组。如果已到达流的末尾,则返回-1。否则返回本次读取的字符数。
-
int read(char[] cbuf,int off,int len)
将字符读入数组的某一部分。存到数组cbuf中,从off处开始存储,最多读len个字符。如果已到达流的末尾,则返回-1。否则返回本次读取的字符数。
-
public void close throws IOException
关闭此输入流并释放与该流关联的所有系统资源
3.4.2 OutputSteam & Writer
- OutputStream和Writer也非常相似:
- void write(int b/int c);
- void write(byte[] b/char[] cbuf);
- void write(byte[] b/char[] buff,int off,int len);
- void flush();
- void close();需要先刷新,再关闭此流
- 因为字符流直接以字符作为操作单位,所以 Writer可以用字符串来替换字符数组,即以 String对象作为参数
- void write(String str);
- void write(String str,int off,int len);
- FileOutputStream从文件系统中的某个文件中获得输出字节。FileOutputstream用于写出非文本数据之类的原始字节流。要写出字符流,需要使用 FileWriter
OutputStream:
-
void write(int b)
将指定的字节写入此输出流。 write的常规协定是:向输出流写入一个字节。要写入的字节是参数b的八个低位。b的24个高位将被忽略。即写入0~255范围的
-
void write(byte[] b)
将b.length个字节从指定的byte数组写入此输出流。write(b)的常规协定是:应该与调用wite(b,0,b.length)的效果完全相同。
-
void write(byte[] b,int off,int len)
将指定byte数组中从偏移量off开始的len个字节写入此输出流。
-
public void flush()throws IOException
刷新此输出流并强制写出所有缓冲的输出字节,调用此方法指示应将这些字节立即写入它们预期的目标。
-
public void close throws IOException
关闭此输岀流并释放与该流关联的所有系统资源。
Writer:
-
void write(int c)
写入单个字符。要写入的字符包含在给定整数值的16个低位中,16高位被忽略。即写入0到65535之间的 Unicode码。
-
void write(char[] cbuf)
写入字符数组
-
void write(char[] cbuf,int off,int len)
写入字符数组的某一部分。从off开始,写入len个字符
-
void write(String str)
写入字符串。
-
void write(String str,int off,int len)
写入字符串的某一部分。
-
void flush()
刷新该流的缓冲,则立即将它们写入预期目标。
-
public void close throws IOException
关闭此输出流并释放与该流关联的所有系统资源
4. 输入、输出标准化过程
4.1 输入过程:
① 创建File类的对象,指明读取的数据的来源。(要求此文件一定要存在)
② 创建相应的输入流,将File类的对象作为参数,传入流的构造器中
③ 具体的读入过程:创建相应的byte[] 或 char[]。
④ 关闭流资源
说明:程序中出现的异常需要使用try-catch-finally处理。
4.2 输出过程:
① 创建File类的对象,指明写出的数据的位置。(不要求此文件一定要存在)
② 创建相应的输出流,将File类的对象作为参数,传入流的构造器中
③ 具体的写出过程:write(char[]/byte[] buffer,0,len)
④ 关闭流资源
说明:程序中出现的异常需要使用try-catch-finally处理。
5. 流的关闭顺序
- 先关外层流,再关内层流(即一般指先关处理流,再关节点流)
- 关闭外层流的同时,内层流也会自动的进行关闭。所以内层流的关闭,可以省略。
三、文件流的使用
(节点流的一种)
1. 文件字符流的使用
FileReader 和 FileWriter
1.1 文件的输入
从文件中读取到内存(程序)中。 (文件 —>内存/程序)
注意点:
- read()的理解:返回读入的一个字符。如果达到文件末尾,返回-1
- 异常的处理:为了保证流资源一定可以执行关闭操作。需要使用try-catch-finally处理
- 读入的文件一定要存在,否则就会报FileNotFoundException。
步骤:
- 建立一个流对象,将已存在的一个文件加载进流 FileReader fr = new FileReader(new File(“hello. txt”));
- 创建一个临时存放数据的数组 char[] ch = new char[1024];
- 调用流对象的读取方法将流中的数据读入到数组中。 fr.read(ch);
- 关闭资源。 fr.close();
代码示例:
@Test
public void testFileReader1() {
FileReader fr = null;
try {
//1.File类的实例化
File file = new File("hello.txt");//hello.txt内容为hello123
//2.FileReader流的实例化
fr = new FileReader(file);
//3.读入的操作
//read(char[] cbuf):返回每次读入cbuf数组中的字符的个数。如果达到文件末尾,返回-1
char[] cbuf = new char[5];
int len;
while((len = fr.read(cbuf)) != -1){
/***方式一***/
//错误写法,因为第二次123覆盖第一次内容中的前三个,即123lo,所以最终读出:hello123lo
for(int i = 0,i<cbuf.length;i++){
System.out.print(cbuf[i]);
}
//正确写法
for(int i = 0,i<len;i++){
System.out.print(cbuf[i]);
}
/***方式二**/
//错误写法,最后读取出来是hello123lo,正确的应该是hello123
String str = new String(cbuf);
//正确写法:把一个数组cbuf从0取到len,取出来之后转换成String类型
String str = new String(cbuf,0,len);
System.out.print(str);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fr != null){
//4.资源的关闭
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
1.2 文件的输出
从内存(程序)写出到硬盘文件中。(内存/程序 —>文件)
注意点:
-
输出操作,对应的File是可以不存在的,并不会报异常。
(1) File如果不存在,在输出的过程中,会自动创建此文件,并写入相应内容。
(2) File如果存在:
① 如果流使用的构造器是:FileWriter(file,flase) /FileWriter(file),会对原有文件内容进行覆盖
② 如果流使用的构造器是:FileWriter(file,true) ,不会对原有文件内容进行覆盖,而是在原有文件内容上进行追加。
步骤:
- 创建流对象,建立数据存放文件 File Writer fw = new File Writer(new File(“Test.txt”))
- 调用流对象的写入方法,将数据写入流 fw.write(“HelloWord”)
- 关闭流资源,并将流中的数据清空到文件中。 fw.close();
代码示例:
@Test
public void testFileWriter() {
FileWriter fw = null;
try {
//1.提供File类的对象,指明写出到的文件
File file = new File("hello1.txt");
//2.提供FileWriter的对象,用于数据的写出
fw = new FileWriter(file,false);
//3.写出的操作
fw.write("I have a dream!\n");
fw.write("you need to have a dream!");
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.流资源的关闭
if(fw != null){
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
1.3 小练习
实现文本文件的复制操作
@Test
public void testFileReaderFileWriter() {
FileReader fr = null;
FileWriter fw = null;
try {
//1.创建File类的对象,指明读入和写出的文件
File srcFile = new File("hello.txt");
File destFile = new File("hello2.txt");
//不能使用字符流来处理图片等字节数据
// File srcFile = new File("狗.jpg");
// File destFile = new File("狗1.jpg");
//2.创建输入流和输出流的对象
fr = new FileReader(srcFile);
fw = new FileWriter(destFile);
//3.数据的读入和写出操作
char[] cbuf = new char[5];
int len;//记录每次读入到cbuf数组中的字符的个数
while((len = fr.read(cbuf)) != -1){
//每次写出len个字符
fw.write(cbuf,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.关闭流资源
try {
if(fw != null)
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if(fr != null)
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
2. 文件字节流的使用
FileInputSteam 和 FileOutputSteam
文件字节流操作与字符流操作类似,只是实例化对象操作和数据类型不同。
注意点:
- 对于文本文件(.txt,.java,.c,.cpp),使用字符流处理
- 对于非文本文件(.jpg,.mp3,.mp4,.avi,.doc,.ppt,…),使用字节流处理
代码示例:
//使用字节流FileInputStream处理文本文件,可能出现乱码。
@Test
public void testFileInputStream() {
FileInputStream fis = null;
try {
//1. 造文件
File file = new File("hello.txt");
//2.造流
fis = new FileInputStream(file);
//3.读数据
byte[] buffer = new byte[5];
int len;//记录每次读取的字节的个数
while((len = fis.read(buffer)) != -1){
String str = new String(buffer,0,len);
System.out.print(str);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fis != null){
//4.关闭资源
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
小练习
实现图片文件复制操作
@Test
public void testFileInputOutputStream() {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
//1.创建File对象
File srcFile = new File("狗.jpg");
File destFile = new File("狗2.jpg");
//2.创建操流
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
//3.复制的过程
byte[] buffer = new byte[5];
int len;
while((len = fis.read(buffer)) != -1){
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.关闭流
if(fos != null){
//
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
3. 注意点
- 定义路径时,可以用“/”或“\”。
- 输出操作,对应的File可以不存在的。并不会报异常。
- File对应的硬盘中的文件如果不存在,在输出的过程中,会自动创建此文件。
- File对应的硬盘中的文件如果存在:
- 如果流使用的构造器是:FileWriter(file,false) / FileWriter(file):对原有文件的覆盖。
- 如果流使用的构造器是:FileWriter(file,true):不会对原有文件覆盖,而是在原有文件基础上追加内容。
- 读取文件时,必须保证文件存在,否则会报异常。
- 对于文本文件(.txt,.java,.c,.cpp),使用字符流处理
- 对于非文本文件(.jpg,.mp3,.mp4,.avi,.doc,.ppt,…),使用字节流处理
- 如果对于文本文件,只是想复制一下,不在内存层面读出来,用字节流也可以。而对于非文本文件,就一定不能用字符流处理。
四、缓冲流的使用
( 处理流的一种 )
1. 缓冲流:
- BufferedInputStream
- BufferedOutputStream
- BufferedReader
- BufferedWriter
2. 作用:
-
作用:提供流的读取、写入的速度
-
提高读写速度的原因:内部提供了一个缓冲区。默认情况下是8KB

处理流与节点流的对比图示


3. 使用说明
- 当读取数据时,数据按块读入缓冲区,其后的读操作则直接访问缓冲区。
- 当使用 BufferedInputStream读取字节文件时,BufferedInputStream会一次性从文件中读取8192个(8Kb),存在缓冲区中,直到缓冲区装满了,才重新从文件中读取下一个8192个字节数组。
- 向流中写入字节时,不会直接写到文件,先写到缓冲区中直到缓冲区写满,BufferedOutputStream才会把缓冲区中的数据一次性写到文件里。使用方法flush()可以强制将缓冲区的内容全部写入输出流。
- 关闭流的顺序和打开流的顺序相反。只要关闭最外层流即可,关闭最外层流也会相应关闭内层节点流。
- flush()方法的使用:手动将buffer中内容写入文件。
- 如果是带缓冲区的流对象的close()方法,不但会关闭流,还会在关闭流之前刷新缓冲区,关闭后不能再写出。
代码示例:
3.1 非文本文件的复制
使用BufferInputStream和BufferOutputStream实现
@Test
public void testBufferedStream(){
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
//1.造文件
File srcFile = new File("狗.jpg");
File destFile = new File("狗1.jpg");
//2.造流
//2.1造节点流
FileInputStream fis = new FileInputStream(srcFile);
FileOutputStream fos = new FileOutputStream(destFile);
//2.2造缓冲流
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
//3.文件复制操作:读取、写入
byte[] buffer = new byte[1024];
int len;
while ((len = bis.read(buffer)) != -1){
bos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.关闭流
//要求:先关外层流,再关内层流(这里指先关缓冲流,再关节点流)
//说明:关闭外层流的同时,内层流也会自动的进行关闭。关于内层流的关闭,可以省略
if (bos != null){
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
3.2 文本文件的复制
使用BufferedReader和BufferedWriter实现
@Test
public void testBufferedReaderBufferedWriter(){
BufferedReader br = null;
BufferedWriter bw = null;
try {
//创建文件和相应的流
br = new BufferedReader(new FileReader(new File("dbcp.txt")));
bw = new BufferedWriter(new FileWriter(new File("dbcp1.txt")));
//读写操作
//方式一:使用char[]数组
//char[] cbuf = new char[1024];
//int len;
//while((len = br.read(cbuf)) != -1){
//bw.write(cbuf,0,len);
// // bw.flush();
// }
//方式二:使用String
String data;
while((data = br.readLine()) != null){//readLine()一行一行的进行读取
//方法一:
// bw.write(data + "\n");//data中不包含换行符,用"\n"换行
//方法二:
bw.write(data);//data中不包含换行符
bw.newLine();//提供换行的操作
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭资源
if(bw != null){
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(br != null){
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
4. 小练习
4.1 缓冲流和节点流复制速度
节点流实现复制方法
//指定路径下文件的复制
public void copyFile(String srcPath,String destPath){
FileInputStream fis = null;
FileOutputStream fos = null;
try {
//1.造文件
File srcFile = new File(srcPath);
File destFile = new File(destPath);
//2.造流
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
//3.复制的过程
byte[] buffer = new byte[1024];
int len;
while((len = fis.read(buffer)) != -1){
fos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if(fos != null){
//4.关闭流
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(fis != null){
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
缓冲流实现复制操作
//实现文件复制的方法
public void copyFileWithBuffered(String srcPath,String destPath){
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
//1.造文件
File srcFile = new File(srcPath);
File destFile = new File(destPath);
//2.造流
//2.1 造节点流
FileInputStream fis = new FileInputStream((srcFile));
FileOutputStream fos = new FileOutputStream(destFile);
//2.2 造缓冲流
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
//3.复制的细节:读取、写入
byte[] buffer = new byte[1024];
int len;
while((len = bis.read(buffer)) != -1){
bos.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.资源关闭
//要求:先关闭外层的流,再关闭内层的流
if(bos != null){
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
测试二者速度
@Test
public void testCopyFileWithBuffered(){
long start = System.currentTimeMillis();
String srcPath = "C:\\Users\\Administrator\\Desktop\\视频1.avi";
String destPath = "C:\\Users\\Administrator\\Desktop\\视频2.avi";
//节点流实现复制
copyFile(scrPath,destPath);
//缓冲流实现复制
copyFileWithBuffered(srcPath,destPath);
long end = System.currentTimeMillis();
System.out.println("节点流——复制操作花费的时间为:" + (end - start));//618
System.out.println("缓冲流——复制操作花费的时间为:" + (end - start));//176
}
4.2 实现图片加密操作
加密操作
- 将图片文件通过字节流读取到程序中
- 将图片的字节流逐一进行异或^操作
- 将处理后的图片字节流输出
//图片的加密
@Test
public void test1() {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("狗.jpg");
fos = new FileOutputStream("狗Secret.jpg");
byte[] buffer = new byte[20];
int len;
while ((len = fis.read(buffer)) != -1) {
for (int i = 0; i < len; i++) {
buffer[i] = (byte) (buffer[i] ^ 5);//异或操作
}
fos.write(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
解密操作
- 将加密后图片文件通过字节流读取到程序中
- 将图片的字节流逐一进行操作(原理:AB^B = A)
- 将处理后的图片字节流输出
//图片的解密
@Test
public void test2() {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("狗Secret.jpg");
fos = new FileOutputStream("狗狗4.jpg");
byte[] buffer = new byte[20];
int len;
while ((len = fis.read(buffer)) != -1) {
for (int i = 0; i < len; i++) {
buffer[i] = (byte) (buffer[i] ^ 5);
}
fos.write(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
4.3 统计文本字符出现次数
实现思路:
- 遍历文本每一个字符
- 字符出现的次数存在Map中
- 把map中的数据写入文件
@Test
public void testWordCount() {
FileReader fr = null;
BufferedWriter bw = null;
try {
//1.创建Map集合
Map<Character, Integer> map = new HashMap<Character, Integer>();
//2.遍历每一个字符,每一个字符出现的次数放到map中
fr = new FileReader("dbcp.txt");
int c = 0;
while ((c = fr.read()) != -1) {
//int 还原 char
char ch = (char) c;
// 判断char是否在map中第一次出现
if (map.get(ch) == null) {
map.put(ch, 1);
} else {
map.put(ch, map.get(ch) + 1);
}
}
//3.把map中数据存在文件count.txt
//3.1 创建Writer
bw = new BufferedWriter(new FileWriter("wordcount.txt"));
//3.2 遍历map,再写入数据
Set<Map.Entry<Character, Integer>> entrySet = map.entrySet();
for (Map.Entry<Character, Integer> entry : entrySet) {
switch (entry.getKey()) {
case ' ':
bw.write("空格=" + entry.getValue());
break;
case '\t'://\t表示tab 键字符
bw.write("tab键=" + entry.getValue());
break;
case '\r'://
bw.write("回车=" + entry.getValue());
break;
case '\n'://
bw.write("换行=" + entry.getValue());
break;
default:
bw.write(entry.getKey() + "=" + entry.getValue());
break;
}
bw.newLine();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//4.关流
if (fr != null) {
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bw != null) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
五、转换流
字节流和字符流之间的转换,按操作数据它属于字符流,按流角色分属于处理流。
1. 简介
-
转换流提供了在字节流和字符流之间的转换
-
Java API提供了两个转换流:
InputstreamReader:将Inputstream转换为ReaderOutputStreamWriter:将Writer转换为OutputStream
-
字节流中的数据都是字符时,转成字符流操作更高效。
-
很多时候我们使用转换流来处理文件乱码问题。实现编码和解码的功能。
图示:

1.1 InputStreamReader
将一个字节的输入流转换为字符的输入流- 解码: 字节、字节数组 ===> 字符数组、字符串
- 构造器:
- public InputStreamReader(InputStream in) //
使用系统默认的编码集 - public InputStreamReader(Inputstream in,String charsetName) //charsetName
指定编码集,如utf-8
1.2 OutputStreamWriter
将一个字符的输出流转换为字节的输出流- 编码:字符数组、字符串 ===> 字节、字节数组
- 构造器:
- public OutputStreamWriter(OutputStream out) //
使用系统默认的编码集 - public OutputStreamWriter(Outputstream out,String charsetName)//可以指定编码集,如utf-8、GBK
2. 代码示例:
/**
综合使用InputStreamReader和OutputStreamWriter
*/
@Test
public void test1() {
InputStreamReader isr = null;
OutputStreamWriter osw = null;
try {
//1.造文件、造流
File file1 = new File("dbcp.txt");
File file2 = new File("dbcp_gbk.txt");
FileInputStream fis = new FileInputStream(file1);
FileOutputStream fos = new FileOutputStream(file2);
//new InputStreamReader(fis);使用系统默认的编码集
//参数2指明字符集,具体使用哪个字符集,取决于dbcp.txt文件一开始保存时使用的字符集
isr = new InputStreamReader(fis, "utf-8");
osw = new OutputStreamWriter(fos, "gbk");
//2.读写过程
char[] cbuf = new char[20];
int len;
while ((len = isr.read(cbuf)) != -1){
osw.write(cbuf,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//3.关流
if (isr != null){
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (osw != null){
try {
osw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
说明:文件编码的方式(比如:GBK),决定了解析时使用的字符集(也只能是GBK)。
3. 字符编码
3.1 编码表的由来
计算机只能识别二进制数据,早期由来是电信号。为了方便应用计算机,让它可以识别各个国家的文字。就将各个国家的文字用数字来表示,并一一对应,形成一张表。这张表就是编码表。
3.2 常见的字符集
- ASCII:美国标准信息交换码。用一个字节的7位可以表示。
- ISO8859-1:拉丁码表。欧洲码表用一个字节的8位表示。
- GB2312:中国的中文编码表。最多两个字节编码所有字符
- GBK:中国的中文编码表升级,融合了更多的中文文字符号。最多两个字节编码
- Unicode:国际标准码,融合了目前人类使用的所字符。为每个字符分配唯一的字符码。所有的文字都用两个字节来表示。
- UTF-8:变长的编码方式,可用1-4个字节来表示一个字符。

说明:

UTF-8变长编码表示

实例:以汉字 “尚”为例

3.3 编码应用
- 编码:字符串–>字节数组
- 解码:字节数组–>字符串
- 转换流的编码应用
- 可以将字符按指定编码格式存储
- 可以对文本数据按指定编码格式来解读
- 指定编码表的动作由构造器完成
使用要求:
客户端/浏览器端 <=> 后台(java,GO,Python,Node.js,php) <=> 数据库
要求前前后后使用的字符集都要统一:如UTF-8。
六、标准输入、输出流

1. 简介
System.in:标准的输入流,默认从键盘输入
System.out:标准的输出流,默认从控制台输出
2. 主要方法
System类的setIn(InputStream is) :重新指定输入的流
System类的setOut(PrintStream ps):重新指定输出的流。
3. 使用示例
题目:从键盘输入字符串,要求将读取到的整行字符串转成大写输出。然后继续进行输入操作,
直至当输入“e”或者“exit”时,退出程序。
设计思路
方法一:使用Scanner实现,调用next()返回一个字符串
方法二:使用System.in实现。System.in —> 转换流 —> BufferedReader的readLine()
public static void main(String[] args) {
BufferedReader br = null;
try {
InputStreamReader isr = new InputStreamReader(System.in);
br = new BufferedReader(isr);
while (true) {
System.out.println("请输入字符串:");
String data = br.readLine();
if ("e".equalsIgnoreCase(data) || "exit".equalsIgnoreCase(data)) {
System.out.println("程序结束");
break;
}
String upperCase = data.toUpperCase();
System.out.println(upperCase);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
4. 小练习
设计实现Scanner类
public class MyInput {
//从键盘读取字符串
public static String readString() {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
//声明并初始化字符串
String string = "";
//从键盘上获取字符串
try {
string = br.readLine();
} catch (IOException ex) {
System.out.println(ex);
}
//返回从键盘获取的字符串
return string;
}
//从键盘读取整型值
public static int readInt() {
return Integer.parseInt(readString());
}
// 从键盘读取双精度值
public static double readDouble() {
return Double.parseDouble(readString());
}
//从键盘读取字节值
public static double readByte() {
return Byte.parseByte(readString());
}
//从键盘读取短整形值
public static double readShort() {
return Short.parseShort(readString());
}
//从键盘读取长整形值
public static double readLong() {
return Long.parseLong(readString());
}
//从键盘读取浮点值
public static double readFloat() {
return Float.parseFloat(readString());
}
}
七、打印流

实例:
@Test
public void test2() {
PrintStream ps = null;
try {
FileOutputStream fos = new FileOutputStream(new File("D:\\IO\\text.txt"));
// 创建打印输出流,设置为自动刷新模式(写入换行符或字节 '\n' 时都会刷新输出缓冲区)
ps = new PrintStream(fos, true);
if (ps != null) {// 把标准输出流(控制台输出)改成文件
System.setOut(ps);
}
for (int i = 0; i <= 255; i++) { // 输出ASCII字符
System.out.print((char) i);
if (i % 50 == 0) { // 每50个数据一行
System.out.println(); // 换行
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
if (ps != null) {
ps.close();
}
}
}
八、数据流

注意点:读取不同类型的数据的顺序要与当初写入文件时保存的数据的顺序一致!
示例代码:
将内存中的字符串、基本数据类型的变量写出到文件中。
@Test
public void test3(){
//1.造对象、造流
DataOutputStream dos = null;
try {
dos = new DataOutputStream(new FileOutputStream("data.txt"));
//数据输出
dos.writeUTF("马云");
dos.flush();//刷新操作,将内存的数据写入到文件
dos.writeInt(23);
dos.flush();
dos.writeBoolean(true);
dos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
//3.关闭流
if (dos != null){
try {
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
将文件中存储的基本数据类型变量和字符串读取到内存中,保存在变量中。
/*
注意点:读取不同类型的数据的顺序要与当初写入文件时,保存的数据的顺序一致!
*/
@Test
public void test4(){
DataInputStream dis = null;
try {
//1.造对象、造流
dis = new DataInputStream(new FileInputStream("data.txt"));
//2.从文件读入数据
String name = dis.readUTF();
int age = dis.readInt();
boolean isMale = dis.readBoolean();
System.out.println("name:"+name);
System.out.println("age:"+age);
System.out.println("isMale:"+isMale);
} catch (IOException e) {
e.printStackTrace();
} finally {
//3.关闭流
if (dis != null){
try {
dis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
九、对象流
1. 概述

2. 作用:
- ObjectOutputStream:内存中的对象 ==> 存储中的文件、通过网络传输出去(序列化过程)
- ObjectInputStream:存储中的文件、通过网络接收过来 ==> 内存中的对象(反序列化过程)
3. 对象的序列化


4. 对象序列化的条件:
- 需要实现接口:
Serializable(标识接口) - 当前类提供一个全局常量:serialVersionUID(序列版本号)
- 除了当前Person类需要实现Serializable接口之外,还必须保证其内部所有属性也必须是可序列化的。(默认情况下,基本数据类型可序列化;还有需序列化的属性,不能用static,transient 修饰)
补充:ObjectOutputStream 和 ObjectInputStream不能序列化 static 和 transient 修饰的成员变量。即static,transient 修饰的属性不能被序列化。
示例:
//自定义类Person
public class Person implements Serializable {
public static final long serialVersionUID = 131545142L;//随意,保证唯一就行
private String name;
private int age;
private Account account;
public Person() {
}
public Person(String name, int age, Account account) {
this.name = name;
this.age = age;
this.account = account;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Account getAccount() {
return account;
}
public void setAccount(Account account) {
this.account = account;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", account=" + account +
'}';
}
}
class Account implements Serializable{
public static final long serialVersionUID = 4855615152L;
private Double blance;
public Account() {
}
public Account(Double blance) {
this.blance = blance;
}
public Double getBlance() {
return blance;
}
public void setBlance(Double blance) {
this.blance = blance;
}
@Override
public String toString() {
return "Account{" +
"blance=" + blance +
'}';
}
}
5. 对象流的使用
5.1 序列化代码实现
序列化:将对象写入磁盘或进行网络传输
要求被序列化对象必须实现序列化
@Test
public void testObjectOutputStream(){
ObjectOutputStream oos = null;
try {
//1.创建对象,创建流
oos = new ObjectOutputStream(new FileOutputStream("object.dat"));
//2.操作流
oos.writeObject(new String("我爱北京天安门"));
oos.flush();//刷新操作
//自定义对象实现序列化
oos.writeObject(new Person("王铭",23));
oos.flush();
//自定义对象实现序列化
oos.writeObject(new Person("张学良",23,1001,new Account(5000)));
oos.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if(oos != null){
//3.关闭流
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
5.2 反序列化代码实现
反序列化:将磁盘的对象数据源读出
@Test
public void testObjectInputStream(){
ObjectInputStream ois = null;
try {
ois = new ObjectInputStream(new FileInputStream("object.dat"));
Object obj = ois.readObject();
String str = (String) obj;
//自定义类反序列化
Person p = (Person) ois.readObject();
Person p1 = (Person) ois.readObject();
System.out.println(str);
System.out.println(p);
System.out.println(p1);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if(ois != null){
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
6. 序列化和反序列化 (补充)
- 把对象转换为字节序列的过程称为对象的序列化。
- 把字节序列恢复为对象的过程称为对象的反序列化。
什么情况下会使用到序列化?
(1)把内存中对象的字节序列永久地保存到一个文件中或者数据库中的时候;
(2)用套接字在网络上传输对象时
(3)想通过RMI(远程方法调用)传输对象时
场景举例:
(1)在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些session先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
(2)当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
十、随机存取文件流
RandomAccessFile 类的使用
1. 简介
- RandomAccessFile声明在java.io包下,但直接继承于java.lang.Object类。并且它实现了DataInput和DataOutput接口,也就意味着它既可以输入也可以输出。
- RandomAccessFile既可以作为一个输入流,又可以作为一个输出流
- RandomAccessFile类支持 “随机访问” 的方式,程序可以直接跳到文件的任意地方来读、写文件
- 支持只访问文件的部分内容
- 可以向已存在的文件后追加内容
- RandomAccessFile对象包含一个记录指针,用以标示当前读写处的位置
- RandomaccessFile类对象可以自由移动记录指针:
long getFilePointer():获取文件记录指针的当前位置void seek(long pos):将文件记录指针定位到pos位置
构造器:
public RandomAccessFile(File file,String mode)
public RandomAccessFile(String name,String mode)
2. 使用说明:
- 如果RandomAccessFile作为输出流时,写出到的文件如果不存在,则在执行过程中自动创建。
- 如果写出到的文件存在,则会对原文件内容进行覆盖。(默认情况下,从头覆盖)
- 可以通过相关的操作,实现RandomAccessFile“插入”数据的效果。借助seek(int pos)方法
- 创建RandomAccessFile类实例需要指定一个
mode参数,该参数指定RandomAccessFile的访问模式:r:以只读方式打开rw:打开以便读取和写入rwd:打开以便读取和写入;同步文件内容的更新rws:打开以便读取和写入;同步文件内容和元数据的更新
- 如果模式为只读r,则不会创建文件,而是会去读取一个已经存在的文件,读取的文件不存在则会出现异常。如果模式为rw读写,文件不存在则会去创建文件,存在则不会创建。
3. 使用示例
文件的读取和写出操作
@Test
public void test1() {
RandomAccessFile raf1 = null;
RandomAccessFile raf2 = null;
try {
//1.创建对象,创建流
raf1 = new RandomAccessFile(new File("test.jpg"),"r");
raf2 = new RandomAccessFile(new File("test1.jpg"),"rw");
//2.操作流
byte[] buffer = new byte[1024];
int len;
while((len = raf1.read(buffer)) != -1){
raf2.write(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//3.关闭流
if(raf1 != null){
try {
raf1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(raf2 != null){
try {
raf2.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
使用RandomAccessFile实现数据的插入效果
@Test
public void test2(){
RandomAccessFile raf1 = null;
try {
raf1 = new RandomAccessFile(new File("hello.txt"), "rw");//hello.txt内容:abcdefgh
raf1.seek(3);//将指针调到角标为3的位置
//raf1.write("xyz".getBytes()); //hello.txt内容变为:abcxyzgh
//方式一
//保存指针3后面的所有数据到StringBuilder中
StringBuilder builder = new StringBuilder((int) new File("hello.txt").length());
byte[] buffer = new byte[20];
int len;
while ((len = raf1.read(buffer)) != -1){
builder.append(new String(buffer,0,len));
}//循环执行完指针已经到最后位置
//调回指针到3位置,写入“xyz”
raf1.seek(3);
raf1.write("xyz".getBytes());
//将StringBuilder中的数据写入到文件中
raf1.write(builder.toString().getBytes());
//方式二
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[20];
int len;
while ((len = raf1.read(buffer)) != -1){
baos.write(buffer);
}
//调回指针到3位置,写入“xyz”
raf1.seek(3);
raf1.write("xyz".getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
if (raf1 != null){
try {
raf1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
我们可以用RandomAccessFile这个类,来实现一个多线程断点下载的功能,用过下载工具就知道,下载前都会建立两个临时文件,一个是与被下载文件大小相同的空文件,另一个是记录文件指针的位置文件,每次暂停的时候,都会保存上一次的指针,然后断点下载的时候,会继续从上一次的地方下载,从而实现断点下载或上传功能。
十一、流的基本应用总结
-
流是用来处理数据的。
-
处理数据时,一定要先明确数据源,与数据目的地数据源可以是文件,可以是键盘数据目的地可以是文件、显示器或者其他设备
-
而流只是在帮助数据进行传输,并对传输的数据进行处理,比如过滤处理、转换处理等
-
除去RandomAccessFile类外所有的流都继承于四个基本数据流抽象类InputSteam、OutputSteam、Reader、Writer
-
不同的操作流对应的后缀均为四个抽象基类中的某一个
-
不同处理流的使用方式都是标准操作:
- 创建文件对象,创建相应的流
- 处理流数据
- 关闭流
- 用try-catch-finally处理异常
十二、NIO
这里对Path、Paths、Files的使用做一个简单介绍。
1. NIO的说明:
- Java NIO (New IO,Non-Blocking IO)是从Java 1.4版本开始引入的一套新的IO API,可以替代标准的Java IO API。
- NIO与原来的IO同样的作用和目的,但是使用的方式完全不同,
NIO支持面向缓冲区的(IO是面向流的)、基于通道的IO操作。 NIO将以更加高效的方式进行文件的读写操作。- JDK 7.0对NIO进行了极大的扩展,增强了对文件处理和文件系统特性的支持,称他为 NIO.2。
**`Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO`**
|-----java.nio.channels.Channel
|---- FileChannel:处理本地文件
|---- SocketChannel:TCP网络编程的客户端的Channel
|---- ServerSocketChannel:TCP网络编程的服务器端的Channel
|---- DatagramChannel:UDP网络编程中发送端和接收端的Channel
2. NIO.2中Path、Paths、Files类的使用
-
Path可以看成是File类的升级版本,实际引用的资源也可以不存在。
-
Files包含了大量静态的工具方法来操作文件。
-
Paths则包含了两个返回Path的静态工厂方法。
2.1 Path接口
- 早期的Java只提供了一个File类来访问文件系统,但File类的功能比较有限,所提供的方法性能也不高。而且,
大多数方法在出错时仅返回失败,并不会提供异常信息。 - NIO.2为了弥补这种不足,引入了Path接口,代表一个平台无关的平台路径,描述了目录结构中文件的位置。
Path可以看成是File类的升级版本,实际引用的资源也可以不存在。 - 同时,NIO.2在java.nio.file包下还提供了Files、Paths工具类,Files包含了大量静态的工具方法来操作文件;Paths则包含了两个返回Path的静态工厂方法。
2.1.1 Path的说明:
Path替换原有的File类。
- 在以前IO操作都是这样写的:
- import java.io.File
File file = new File("index.html");
- 但在Java7中,我们可以这样写:
- import java.nio.file.Path;
- import java.nio.file.Paths;
Path path = Paths.get("index. html");
2.1.2 Paths类的使用
-
Paths类提供的静态get()方法用来获取Path对象:
static Path get(String first, String….more):用于将多个字符串串连成路径static Path get(URI uri):返回指定uri对应的Path路径
代码示例
@Test
public void test1(){
Path path1 = Paths.get("hello.txt");//new File(String filepath)
Path path2 = Paths.get("E:\\", "test\\test1\\haha.txt");//new File(String parent,String filename);
Path path3 = Paths.get("E:\\", "test");
System.out.println(path1);
System.out.println(path2);
System.out.println(path3);
}
2.1.3 常用方法
- String toString() : 返回调用 Path 对象的字符串表示形式
- boolean startsWith(String path) : 判断是否以 path 路径开始
- boolean endsWith(String path) : 判断是否以 path 路径结束
- boolean isAbsolute() : 判断是否是绝对路径
- Path getParent() :返回Path对象包含整个路径,不包含 Path 对象指定的文件路径
- Path getRoot() :返回调用 Path 对象的根路径
- Path getFileName() : 返回与调用 Path 对象关联的文件名
- int getNameCount() : 返回Path 根目录后面元素的数量
- Path getName(int idx) : 返回指定索引位置 idx 的路径名称
- Path toAbsolutePath() : 作为绝对路径返回调用 Path 对象
- Path resolve(Path p) :合并两个路径,返回合并后的路径对应的Path对象
- File toFile(): 将Path转化为File类的对象
代码示例
@Test
public void test2() {
Path path1 = Paths.get("d:\\", "nio\\nio1\\nio2\\hello.txt");
Path path2 = Paths.get("hello.txt");
//String toString() : 返回调用 Path 对象的字符串表示形式
System.out.println(path1);
//boolean startsWith(String path) : 判断是否以 path 路径开始
System.out.println(path1.startsWith("d:\\nio"));
//boolean endsWith(String path) : 判断是否以 path 路径结束
System.out.println(path1.endsWith("hello.txt"));
//boolean isAbsolute() : 判断是否是绝对路径
System.out.println(path1.isAbsolute() + "~");
System.out.println(path2.isAbsolute() + "~");
//Path getParent() :返回Path对象包含整个路径,不包含 Path 对象指定的文件路径
System.out.println(path1.getParent());
System.out.println(path2.getParent());
// Path getRoot() :返回调用 Path 对象的根路径
System.out.println(path1.getRoot());
System.out.println(path2.getRoot());
//Path getFileName() : 返回与调用 Path 对象关联的文件名
System.out.println(path1.getFileName() + "~");
System.out.println(path2.getFileName() + "~");
//int getNameCount() : 返回Path 根目录后面元素的数量
//Path getName(int idx) : 返回指定索引位置 idx 的路径名称
for (int i = 0; i < path1.getNameCount(); i++) {
System.out.println(path1.getName(i) + "*****");
}
//Path toAbsolutePath() : 作为绝对路径返回调用 Path 对象
System.out.println(path1.toAbsolutePath());
System.out.println(path2.toAbsolutePath());
//Path resolve(Path p) :合并两个路径,返回合并后的路径对应的Path对象
Path path3 = Paths.get("d:\\", "nio");
Path path4 = Paths.get("nioo\\hi.txt");
path3 = path3.resolve(path4);
System.out.println(path3);
//File toFile(): 将Path转化为File类的对象
File file = path1.toFile();//Path--->File的转换
Path newPath = file.toPath();//File--->Path的转换
}
2.2 Files类
java.nio.file.Files用于操作文件或目录的工具类
2.2.1 Files类常用方法
-
Path copy(Path src, Path dest, CopyOption … how) : 文件的复制
要想复制成功,要求path1对应的物理上的文件存在。path1对应的文件没有要求。
-
Files.copy(path1, path2, StandardCopyOption.REPLACE_EXISTING);
-
Path createDirectory(Path path, FileAttribute<?> … attr) : 创建一个目录
要想执行成功,要求path对应的物理上的文件目录不存在。一旦存在,抛出异常。
-
Path createFile(Path path, FileAttribute<?> … arr) : 创建一个文件
要想执行成功,要求path对应的物理上的文件不存在。一旦存在,抛出异常。
-
void delete(Path path) : 删除一个文件/目录,如果不存在,执行报错
-
void deleteIfExists(Path path) : Path对应的文件/目录如果存在,执行删除.如果不存在,正常执行结束
-
Path move(Path src, Path dest, CopyOption…how) : 将 src 移动到 dest 位置
要想执行成功,src对应的物理上的文件需要存在,dest对应的文件没有要求。
-
long size(Path path) : 返回 path 指定文件的大小
代码示例
@Test
public void test1() throws IOException{
Path path1 = Paths.get("d:\\nio", "hello.txt");
Path path2 = Paths.get("atguigu.txt");
//Path copy(Path src, Path dest, CopyOption … how) : 文件的复制
//要想复制成功,要求path1对应的物理上的文件存在。path1对应的文件没有要求。
//Files.copy(path1, path2, StandardCopyOption.REPLACE_EXISTING);
//Path createDirectory(Path path, FileAttribute<?> … attr) : 创建一个目录
//要想执行成功,要求path对应的物理上的文件目录不存在。一旦存在,抛出异常。
Path path3 = Paths.get("d:\\nio\\nio1");
//Files.createDirectory(path3);
//Path createFile(Path path, FileAttribute<?> … arr) : 创建一个文件
//要想执行成功,要求path对应的物理上的文件不存在。一旦存在,抛出异常。
Path path4 = Paths.get("d:\\nio\\hi.txt");
//Files.createFile(path4);
//void delete(Path path) : 删除一个文件/目录,如果不存在,执行报错
//Files.delete(path4);
//void deleteIfExists(Path path) : Path对应的文件/目录如果存在,执行删除.如果不存在,正常执行结束
Files.deleteIfExists(path3);
//Path move(Path src, Path dest, CopyOption…how) : 将 src 移动到 dest 位置
//要想执行成功,src对应的物理上的文件需要存在,dest对应的文件没有要求。
//Files.move(path1, path2, StandardCopyOption.ATOMIC_MOVE);
//long size(Path path) : 返回 path 指定文件的大小
long size = Files.size(path2);
System.out.println(size);
}
2.2.2 Files类常用方法:用于判断
-
boolean exists(Path path, LinkOption … opts) : 判断文件是否存在
-
boolean isDirectory(Path path, LinkOption … opts) : 判断是否是目录
不要求此path对应的物理文件存在。
-
boolean isRegularFile(Path path, LinkOption … opts) : 判断是否是文件
-
boolean isHidden(Path path) : 判断是否是隐藏文件
要求此path对应的物理上的文件需要存在。才可判断是否隐藏。否则,抛异常。
-
boolean isReadable(Path path) : 判断文件是否可读
-
boolean isWritable(Path path) : 判断文件是否可写
-
boolean notExists(Path path, LinkOption … opts) : 判断文件是否不存在
代码示例
@Test
public void test2() throws IOException{
Path path1 = Paths.get("d:\\nio", "hello.txt");
Path path2 = Paths.get("atguigu.txt");
//boolean exists(Path path, LinkOption … opts) : 判断文件是否存在
System.out.println(Files.exists(path2, LinkOption.NOFOLLOW_LINKS));
//boolean isDirectory(Path path, LinkOption … opts) : 判断是否是目录
//不要求此path对应的物理文件存在。
System.out.println(Files.isDirectory(path1, LinkOption.NOFOLLOW_LINKS));
//boolean isRegularFile(Path path, LinkOption … opts) : 判断是否是文件
//boolean isHidden(Path path) : 判断是否是隐藏文件
//要求此path对应的物理上的文件需要存在。才可判断是否隐藏。否则,抛异常。
//System.out.println(Files.isHidden(path1));
//boolean isReadable(Path path) : 判断文件是否可读
System.out.println(Files.isReadable(path1));
//boolean isWritable(Path path) : 判断文件是否可写
System.out.println(Files.isWritable(path1));
//boolean notExists(Path path, LinkOption … opts) : 判断文件是否不存在
System.out.println(Files.notExists(path1, LinkOption.NOFOLLOW_LINKS));
}
补充:
- StandardOpenOption.READ:表示对应的Channel是可读的。
- StandardOpenOption.WRITE:表示对应的Channel是可写的。
- StandardOpenOption.CREATE:如果要写出的文件不存在,则创建。如果存在,忽略
- StandardOpenOption.CREATE_NEW:如果要写出的文件不存在,则创建。如果存在,抛异常
2.2.3 Files类常用方法:用于操作内容
- InputStream newInputStream(Path path, OpenOption…how):获取 InputStream 对象
- OutputStream newOutputStream(Path path, OpenOption…how) : 获取 OutputStream 对象
- SeekableByteChannel newByteChannel(Path path, OpenOption…how) : 获取与指定文件的连接,how 指定打开方式。
- DirectoryStream
newDirectoryStream(Path path) : 打开 path 指定的目录
代码示例
@Test
public void test3() throws IOException{
Path path1 = Paths.get("d:\\nio", "hello.txt");
//InputStream newInputStream(Path path, OpenOption…how):获取 InputStream 对象
InputStream inputStream = Files.newInputStream(path1, StandardOpenOption.READ);
//OutputStream newOutputStream(Path path, OpenOption…how) : 获取 OutputStream 对象
OutputStream outputStream = Files.newOutputStream(path1, StandardOpenOption.WRITE,StandardOpenOption.CREATE);
//SeekableByteChannel newByteChannel(Path path, OpenOption…how) : 获取与指定文件的连接,how 指定打开方式。
SeekableByteChannel channel = Files.newByteChannel(path1, StandardOpenOption.READ,StandardOpenOption.WRITE,StandardOpenOption.CREATE);
//DirectoryStream<Path> newDirectoryStream(Path path) : 打开 path 指定的目录
Path path2 = Paths.get("e:\\teach");
DirectoryStream<Path> directoryStream = Files.newDirectoryStream(path2);
Iterator<Path> iterator = directoryStream.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
十三、BIO、NIO与AIO的区别(拓展)
这里只是简单说明一下,而有关java中BIO、NIO与AIO的区别的详细说明,请前往【BIO、NIO与AIO的区别】。
1. 首先来说一下什么是I/O?
- 在计算机系统中I/O就是输入(Input)和输出(Output)的意思,针对不同的操作对象,可以划分为磁盘I/O模型,网络I/O模型,内存映射I/O, Direct I/O、数据库I/O等,只要具有输入输出类型的交互系统都可以认为是I/O系统,也可以说I/O是整个操作系统数据交换与人机交互的通道,这个概念与选用的开发语言没有关系,是一个通用的概念。
- 在如今的系统中I/O却拥有很重要的位置,现在系统都有可能处理大量文件,大量数据库操作,而这些操作都依赖于系统的I/O性能,也就造成了现在系统的瓶颈往往都是由于I/O性能造成的。因此,为了解决磁盘I/O性能慢的问题,系统架构中添加了缓存来提高响应速度;或者有些高端服务器从硬件级入手,使用了固态硬盘(SSD)来替换传统机械硬盘;在大数据方面,计算引擎(Spark)越来越多的承担了实时性计算任务,而传统的分布式系统基础架构则大多应用在了离线计算与大量数据存储的场景,这也是由于磁盘I/O性能远不如内存I/O性能而造成的格局。因此,一个系统的优化空间,往往都在低效率的I/O环节上,很少看到一个系统CPU、内存的性能是其整个系统的瓶颈。也正因为如此,Java在I/O上也一直在做持续的优化,从JDK 1.4开始便引入了NIO模型,大大的提高了以往BIO模型下的操作效率。
2. BIO、NIO、AIO的基本定义
-
BIO (Blocking I/O):同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。这里使用那个经典的烧开水例子,这里假设一个烧开水的场景,有一排水壶在烧开水,BIO的工作模式就是, 叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做。
-
NIO (New I/O):同时支持阻塞与非阻塞模式,但这里我们以其同步非阻塞I/O模式来说明,那么什么叫做同步非阻塞?如果还拿烧开水来说,NIO的做法是叫一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作。
-
AIO ( Asynchronous I/O):异步非阻塞I/O模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了。
3. 进程中的IO调用步骤
大致可以分为以下四步:
- 进程向操作系统请求数据 ;
- 操作系统把外部数据加载到内核的缓冲区中;
- 操作系统把内核的缓冲区拷贝到进程的缓冲区 ;
- 进程获得数据完成自己的功能 ;
当操作系统在把外部数据放到进程缓冲区的这段时间(即上述的第二,三步),如果应用进程是挂起等待的,那么就是同步IO,反之,就是异步IO,也就是AIO 。
指定的目录
代码示例
@Test
public void test3() throws IOException{
Path path1 = Paths.get("d:\\nio", "hello.txt");
//InputStream newInputStream(Path path, OpenOption…how):获取 InputStream 对象
InputStream inputStream = Files.newInputStream(path1, StandardOpenOption.READ);
//OutputStream newOutputStream(Path path, OpenOption…how) : 获取 OutputStream 对象
OutputStream outputStream = Files.newOutputStream(path1, StandardOpenOption.WRITE,StandardOpenOption.CREATE);
//SeekableByteChannel newByteChannel(Path path, OpenOption…how) : 获取与指定文件的连接,how 指定打开方式。
SeekableByteChannel channel = Files.newByteChannel(path1, StandardOpenOption.READ,StandardOpenOption.WRITE,StandardOpenOption.CREATE);
//DirectoryStream<Path> newDirectoryStream(Path path) : 打开 path 指定的目录
Path path2 = Paths.get("e:\\teach");
DirectoryStream<Path> directoryStream = Files.newDirectoryStream(path2);
Iterator<Path> iterator = directoryStream.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
十三、BIO、NIO与AIO的区别(拓展)
这里只是简单说明一下,而有关java中BIO、NIO与AIO的区别的详细说明,请前往【BIO、NIO与AIO的区别】。
1. 首先来说一下什么是I/O?
- 在计算机系统中I/O就是输入(Input)和输出(Output)的意思,针对不同的操作对象,可以划分为磁盘I/O模型,网络I/O模型,内存映射I/O, Direct I/O、数据库I/O等,只要具有输入输出类型的交互系统都可以认为是I/O系统,也可以说I/O是整个操作系统数据交换与人机交互的通道,这个概念与选用的开发语言没有关系,是一个通用的概念。
- 在如今的系统中I/O却拥有很重要的位置,现在系统都有可能处理大量文件,大量数据库操作,而这些操作都依赖于系统的I/O性能,也就造成了现在系统的瓶颈往往都是由于I/O性能造成的。因此,为了解决磁盘I/O性能慢的问题,系统架构中添加了缓存来提高响应速度;或者有些高端服务器从硬件级入手,使用了固态硬盘(SSD)来替换传统机械硬盘;在大数据方面,计算引擎(Spark)越来越多的承担了实时性计算任务,而传统的分布式系统基础架构则大多应用在了离线计算与大量数据存储的场景,这也是由于磁盘I/O性能远不如内存I/O性能而造成的格局。因此,一个系统的优化空间,往往都在低效率的I/O环节上,很少看到一个系统CPU、内存的性能是其整个系统的瓶颈。也正因为如此,Java在I/O上也一直在做持续的优化,从JDK 1.4开始便引入了NIO模型,大大的提高了以往BIO模型下的操作效率。
2. BIO、NIO、AIO的基本定义
-
BIO (Blocking I/O):同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。这里使用那个经典的烧开水例子,这里假设一个烧开水的场景,有一排水壶在烧开水,BIO的工作模式就是, 叫一个线程停留在一个水壶那,直到这个水壶烧开,才去处理下一个水壶。但是实际上线程在等待水壶烧开的时间段什么都没有做。
-
NIO (New I/O):同时支持阻塞与非阻塞模式,但这里我们以其同步非阻塞I/O模式来说明,那么什么叫做同步非阻塞?如果还拿烧开水来说,NIO的做法是叫一个线程不断的轮询每个水壶的状态,看看是否有水壶的状态发生了改变,从而进行下一步的操作。
-
AIO ( Asynchronous I/O):异步非阻塞I/O模型。异步非阻塞与同步非阻塞的区别在哪里?异步非阻塞无需一个线程去轮询所有IO操作的状态改变,在相应的状态改变后,系统会通知对应的线程来处理。对应到烧开水中就是,为每个水壶上面装了一个开关,水烧开之后,水壶会自动通知我水烧开了。
3. 进程中的IO调用步骤
大致可以分为以下四步:
- 进程向操作系统请求数据 ;
- 操作系统把外部数据加载到内核的缓冲区中;
- 操作系统把内核的缓冲区拷贝到进程的缓冲区 ;
- 进程获得数据完成自己的功能 ;
当操作系统在把外部数据放到进程缓冲区的这段时间(即上述的第二,三步),如果应用进程是挂起等待的,那么就是同步IO,反之,就是异步IO,也就是AIO 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









