







linux 内核主要分成5部分:进程管理、内存管理、文件系统、网络系统、设备管理
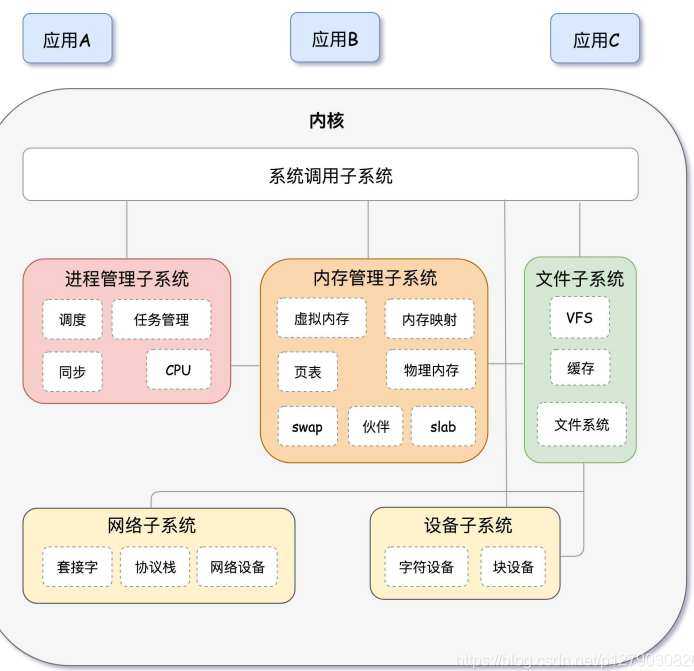
进程管理
linux 与rtos区别是linux可以并行计算,rtos是模拟并行
注意:队列只是一格以前的称呼,底层是链表
进程又叫做任务,通过双向循环链表管理进程描述符,类型为task_struct
进程分类
每个核都有自己的进程队列
每个核都有自己的调度算法
实时进程 与用户交互的进程,需要及时的响应(优先级 0~100)
0~99 优先级 实时进程
SCHED_RR 时间片
轮询调度策略
同等优先级抢占,不同优先级时间片轮询
将cpu分配给就绪队列(循环队列)首进程规定时间片时间,每个进程轮流的运行一个时间片, 时间片用完了就排到就绪队列的尾部
普通进程 响应不需要那么及时的进程。压缩文件,视频的编码解码(由先级100~140)
100~130 普通进程
完全公平的策略 cfs
按照优先级一个个运行,可以被实时进程抢占
每个进程的运行时间=sched_latency_ns * 进程权重值 / 运行队列上所有进程权重之和。
采用友好值(nice value)来为每个任务分配一定比例的CPU处理时间。
友好值的范围是-20--+19,数值低的表示高优先级,数值高的表示低优先级
CFS让运行时间短地方进程获得更加高的优先级,基于红黑树
1、CFS 使用一个叫做 运行队列(runqueue) 的数据结构来存储和管理所有处于可运行状态的进程。
2、在运行队列中,每个进程都有一个 虚拟运行时间(virtual runtime)。这是一个表示进程已经运行了多长时间的值,但是它是通过进程的权重来调整的。
vruntime += delta_exec * nice_0_weight / weight delta_exec:实际执行时间 NICE_0_LOAD:nice为0的权重 weight:当前权重3、当进程需要被调度时,CFS 会选择虚拟运行时间最小的进程。
4、当一个进程的时间片用完时,或者当有更优先的进程需要运行时,CFS 会将当前进程移出 CPU,并更新其虚拟运行时间。
5、这个过程会不断地循环,以确保所有进程都能获得公平的 CPU 时间。
调度算法
1、CFS完全公平调度器
普通进程
2、SCHED_FIFO(First-In-First-Out)(实时进程)
SCHED_FIFO 调度算法会按照进程的提交顺序来分配 CPU 时间,当一个进程获得 CPU 时间后,它会一直运行直到完成或者被更高优先级的进程抢占。因此,该算法可能导致低优先级进程的饥饿情况,因为高优先级进程可能会一直占用 CPU 时间
3、SCHED_RR(Round-Robin)(实时进程)
与 SCHED_FIFO 类似,SCHED_RR 调度算法也会按照进程的提交顺序来分配 CPU 时间。不同之处在于,每个进程都被赋予一个固定的时间片,当时间片用完后,该进程就会被放回就绪队列的尾部,等待下一次调度。该算法可以避免低优先级进程饥饿的问题,因为每个进程都能够获得一定数量的 CPU 时间,而且高优先级进程也不能一直占用 CPU 时间
上下文切换
将p1进程的一些环境存放到内核的栈里面,然后将p2加载进内存中去运行
上下文:进程的一些信息,程序计数器,变量,程序运动到哪了,一些寄存器里面的值。保存在内核的栈里面
linux进程状态
Linux系统中的进程主要有以下六种状态
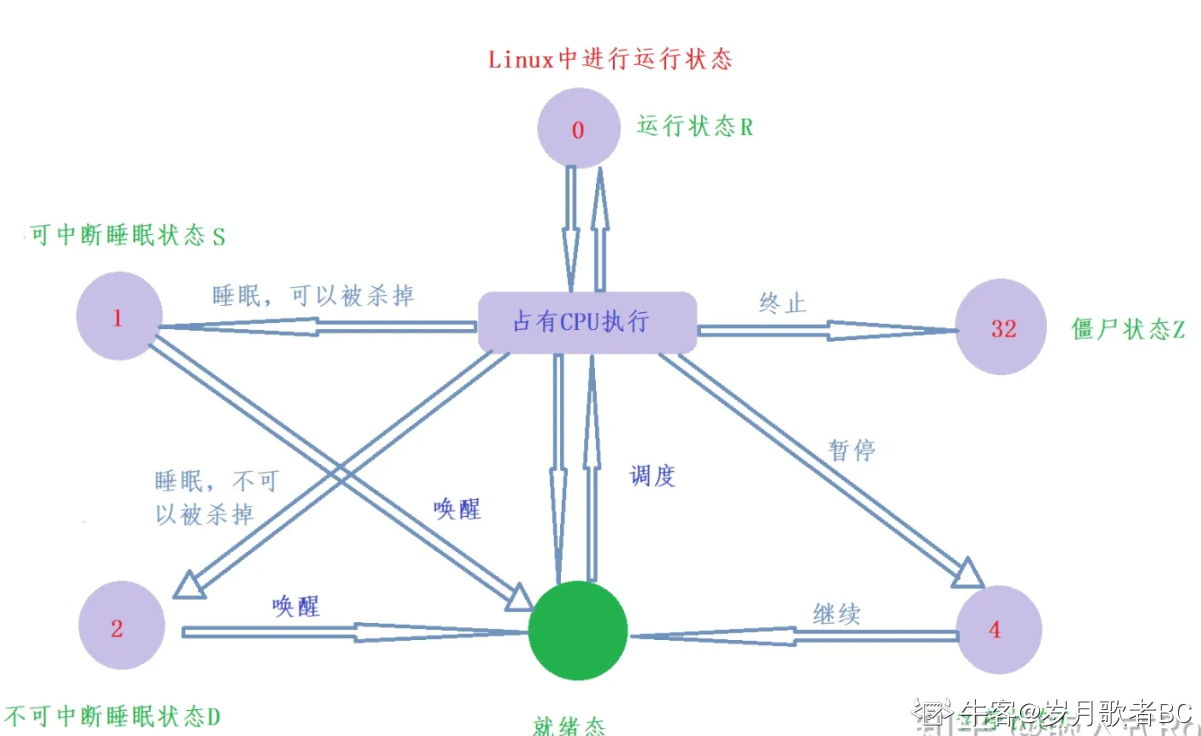
不同的状态都有一个队列,存放着进程
挂起与阻塞之间的区别,挂起是将资源从内存中移除,是被动的,阻塞是资源不足仍在内存中
**R运行状态(running)**并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列。
**S睡眠状态(sleeping)**意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠(interruptible sleep))。
**D磁盘休眠状态(Disk sleep)**有时候也叫不可中断睡眠状态(uninterruptible sleep),这个状态的进程通常会等待IO的结束。
**T停止状态(stopped)**可以发送 SIGSTOP 信号给进程来停止进程。被暂停的进程可以发送 SIGCONT 信号让进程继续运行。
**Z僵尸状态(Zombies)**父进程不读取子进程结束信息。
**X死亡状态(dead)**当父进程读取子进程的返回结果时,子进程立刻释放资源。
进程切换的内容
上下文切换:
将p1进程的一些环境存放到内核的栈里面,然后将p2加载进内存中去运行
上下文:进程的一些信息,程序计数器,变量,程序运动到哪了,一些寄存器里面的值。保存在内核的栈里面,
进程的创建
fork,vfork,clone都是linux的系统调用,这三个函数分别调用了sys_fork、sys_vfork、sys_clone,最终都调用了do_fork函数,差别在于参数的传递和一些基本的准备工作不同,主要用来linux创建新的子进程或线程(vfork创造出来的是线程)。
所有进程都是pid为1的init进程的后代
进程创建先是调用fork()函数,然后调用exec()加载启动一个新的进程
第一个进程:init进程在内核启动的时候创建,负责进行一些初始化工作 pid 为1
守护进程:守护进程在操作系统和服务器环境中扮演重要角色,提供各种服务,如网络服务、日志记录、定时任务等
clow 写时拷贝技术*(这个一种策略,后面的fork也在用)
写时复制:允许父子进程读取相同的物理页,单只有子进程准备写的时候才会去复制新的物理页
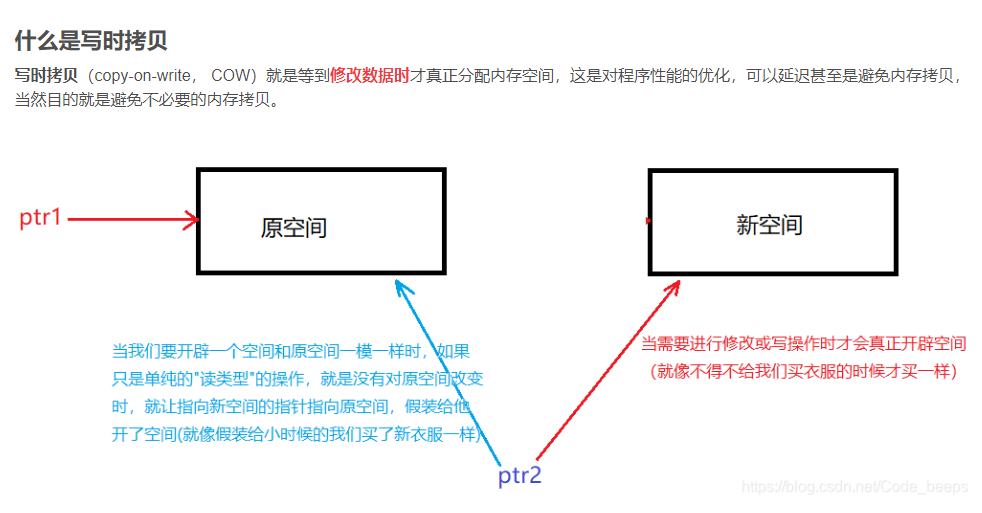
fork
父子进程相同:
data段、text段、堆、栈、
父子进程不同:
进程id、各自父进程、进程创建时间,返回值
- 对于父进程:在父进程中,fork()函数返回子进程的PID(子进程的标识符)。
- 对于子进程:在子进程中,fork()函数返回0。
vfork
随着写时拷贝的出现,很少使用
fork()和fork()的功能一样,不同的是vfork()不拷贝父进程的页表项。通过这种方法创建进程时,子进程作为父进程的一个单独的线程在它的地址空间里运行,父进程被阻塞,也就是说只有当子进程退出后,父进程才可以继续执行,子进程不能向地址空间写入。使用vfork的好处是不用拷贝父进程的页表项。(注:随着写时拷贝技术的出现,vfork一般不再使用)
clone
创建轻量级进程也就是线程
孤儿进程与僵尸进程
孤儿进程,父进程结束了,子进程无人回收,最后是init进程回收
僵尸进程:子进程退出后而父进程并未接收结束子进程(如调用waitpid获取子进程的状态信息),进程的进程描述符(Process Descriptor)仍然保留在系统进程表中,并占用一定的系统资源。
这个一般是父进程可以通过调用
wait()或waitpid()等系统调用来等待子进程的终止
进程通信
管道
连接一个读进程一个写进程,以实现他们之间通信的共享文件。向管道提供输出的发送进程(即写进程),以字符流形式将大量的数据送入管道,而接收管道输出接收进程(即读进程)可以从管道中接收数据
管道的内部机制:
进程1 将自己的进程地址空间中的数据先复制到inode 指定的物理页面上,然后进程2 则复制 inode 指定的页面(同一个页面,即共享的数据页)上的数据到自己的进程地址空间上。这就完成了进程1的写,进程2的读,反之一样。换句话说共享了一个物理页
无名管道------需要血缘关系
有名管道----任意之间数据传输
无名管道是通过文件描述符通信,只能在父子进程之间通信
有名管道是通过一个特殊的文件,来实现进程通信
消息队列(链表)
多个进程都可以操作的队列,可以往里面写入数据和读取数据
要找到我们需要的消息队列,需要获得对应的键值
消息队列的本质其实是一个内核提供的链表,内核基于这个链表,实现了一个数据结构,并且通过维护这个数据结构来维护这个消息队列。向消息队列中写数据,实际上是向这个数据结构中插入一个新结点;从消息队列汇总读数据,实际上是从这个数据结构中删除一个结点。
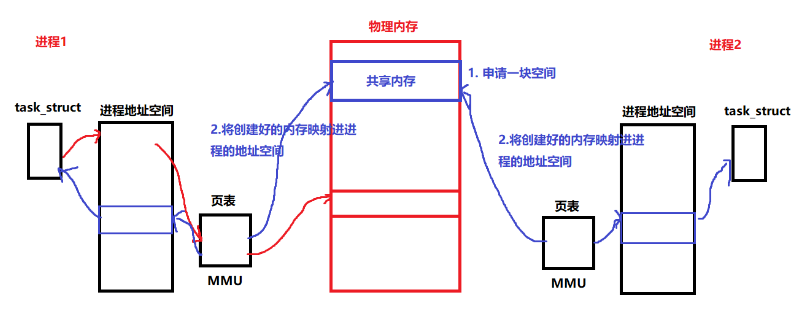
共享内存
共享内存通信
先创建一个空间
将共享内存映射到两个进程的地址空间
信号量
信号量会陷入休眠,中断中不能使用
信号量的底层是利用锁与条件变量实现的,而锁与条件变量的实现又是利用到了底层硬件的支持,包括同步原语,等待队列,休眠机制等
信号
信息理解为软件中断,每一个进程都维护者一个信号表,一个进程收到信号与处理器处理一个中断差不多
信号产生 -> 信号注册 -> 信号在进程中注销 -> 信号处理函数执行完毕
来自 <Linux应用 之 信号_才大难为用的博客-优快云博客>
内核对B进程信号设置完成后,就会发送中断请求给B进程,这样B进程就进入到内核态,这个时候进程B根据那个信号表,查找对应的此信号的处理函数,然后设置frame,设置好之后,跳回到用户态执行信号处理函数,处
理完成后,再次返回到内核态,再次设置frame,然后再次返回用户态,从中断位置开始继续执行
socket
内存映射
虚拟内存解决了
1、进程地址空间隔离,每个进程的代码不会互相打扰
2、将需要运行的程序段放到内存中,暂时不需要的程序段存放到磁盘空间中
3、解决了内存空间地址分配混
解决方案
分页
1、将物理内存分块(页框)、虚拟内存也分块(页),这样的一个物理内存块叫做页框
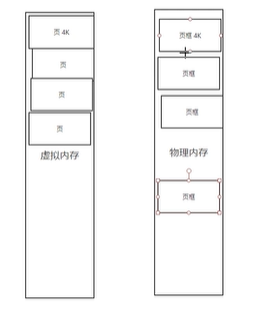
一个页大小4k ,32位操作系统 4G /4k = 1M个页,页表中的条目 一个大小是 4b,4b × 1M = 4M,一个进程页表就需要4M大小
页表(虚拟页与物理页之间的映射关系), 页表中有很个物理页框和虚拟内存页之间的映射关系,方便我们cpu进行地址转换
页框码+偏移量 就相当于页码+行数 (偏移量自带的)
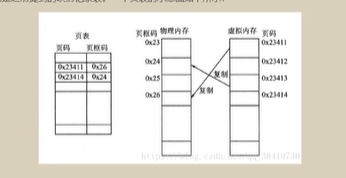
当要访问的物理内存不存在,就会发送缺页中断,然后发生页面置换将磁盘内存换到内存中刷新物理页
多级页表
将多个进程的页表做成一个目录,方便查找具体的虚拟页和物理页的联系
页表共享
多个虚拟地址可以映射到一个物理地址,引用

多线程
线程创建与注销函数
pthread_create
pthread_join
进程与线程的区别
进程是一个执行流,正在运行的程序的实例,是资源分配的基本单位,独占地址空间
线程是进程中的一个执行单元,共享进程的地址空间和资源、数据
进程有自己的独立地址空间,多个线程共有一个地址空间
每个线程都有自己的栈区,寄存器
多个线程共享代码区、堆区、全局数据区、打开的文件(文件描述符)都是线程共享的
线程实最小的执行单位,进程是最小的的资源分配单位
多个线程可以抢占更多的时间片
线程切换上下文比进程切换快
线程和进程一样,子线程退出的时候其内核资源主要由主线程回收,线程库中提供的线程回收函叫做 pthread_join(),这个函数是一个阻塞函数,如果还有子线程在运行,调用该函数就会阻塞,子线程退出函数解除阻塞进行资源的回收,函数被调用一次,只能回收一个子线程,如果有多个子线程则需要循环进行回收。
线程同步
互斥锁
只能锁或者开锁
条件变量
条件变量通常搭配互斥锁来
一个线程等待某个条件满足而被阻塞; 另一个线程中,条件满足时发出“信号
自旋锁
中断
可以使用 pthread_spin_lock()函数或 pthread_spin_trylock()函数对自旋锁进行加锁,前者在未获取到锁时
一直“自旋”;对于后者,如果未能获取到锁,就立刻返回错误,错误码为 EBUSY。不管以何种方式加锁,
自旋锁都可以使用 pthread_spin_unlock()函数对自旋锁进行解锁。其函数原型如下所示注意:互斥锁在没获取到锁前访问会陷入睡眠
读写锁
当读写锁处于写加锁状态时,在这个锁被解锁之前,所有试图对这个锁进行加锁操作(不管是以读
模式加锁还是以写模式加锁)的线程都会被阻塞。
当读写锁处于读加锁状态时,所有试图以读模式对它进行加锁的线程都可以加锁成功;但是任何以
写模式对它进行加锁的线程都会被阻塞,直到所有持有读模式锁的线程释放它们的锁为止
线程池
线程池是预先创建了很多线程,要使用的时候直接从里面调用,不使用的时候放回来
-
创建线程池并初始化一定数量的工作者线程。
-
当有任务需要执行时,将任务放入任务队列中。
-
工作者线程从任务队列中取出任务并执行。
-
执行完成后,工作者线程返回到线程池,等待下一个任务
八股文
挂起与堵塞的区别
1、挂起是主动的,堵塞是被动的
2. 进程都释放CPU,即两个过程都会涉及上下文切换
对系统资源占用不同:虽然都释放了CPU,但阻塞的进程仍处于内存中,而挂起的进程通过“对换”技术被换出到外存(磁盘)中。
2. 发生时机不同:阻塞一般在进程等待资源(IO资源、信号量等)时发生;而挂起是由于用户和系统的需要,例如,终端用户需要暂停程序研究其执行情况或对其进行修改、OS为了提高内存利用率需要将暂时不能运行的进程(处于就绪或阻塞队列的进程)调出到磁盘
内存管理
物理内存管理
虚拟内存管理
MMU、页表、TLB
内存申请与释放接口
映射机制底层实现


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









