




 本文详细介绍了Linux内核中的SLAB和SLUB内存管理技术。解释了这两种技术如何解决操作系统内存分配的问题,特别是在面对频繁申请和释放的小对象时。SLAB通过对象池的方式减少了对象初始化的时间,而SLUB则进一步优化了SLAB,降低了内存占用并提高了性能。
本文详细介绍了Linux内核中的SLAB和SLUB内存管理技术。解释了这两种技术如何解决操作系统内存分配的问题,特别是在面对频繁申请和释放的小对象时。SLAB通过对象池的方式减少了对象初始化的时间,而SLUB则进一步优化了SLAB,降低了内存占用并提高了性能。
为了准备冲刺秋招、提前批
准备从今天开始每天更新一些技术,一部分可能来自粘贴,但是都保证看过一遍
内存管理函数是 kmalloc 和 kfree 函数。这两个函数的原型如下:
void *kmalloc( size_t size, int flags );
void kfree( const void *objp );
kmalloc 和kfree 使用了类似于前面定义的函数的 slab 缓存。kmalloc没有为要从中分配对象的某个 slab 缓存命名,而是循环遍历可用缓存来查找可以满足大小限制的缓存。找到之后,就(使用 __kmem_cache_alloc)分配一个对象。要使用 kfree 释放对象,从中分配对象的缓存可以通过调用 virt_to_cache 确定。这个函数会返回一个缓存引用,然后在 __cache_free 调用中使用该引用释放对象。
linux2.4内核中出现了slab
SLAB的诞生是因为:
操作系统内存分配以页为单位进行的,也内核对象远小于页的大小,而这些对象在操作系统的生命周期中会被频繁的申请和释放。
实验发现,这些对象初始化的时间超过了分配内存和释放内存的总时间,所以需要一种更细粒度的针对内核对象的分配算法
众所周知,为了减少浪费的时间,目前多数系统采用了虚拟化技术,SLAB灵感就来源于此,SLAB就是一个对象池
SLAB缓存已经释放的内核对象,以便下次申请时不需要再次初始化和分配空间。
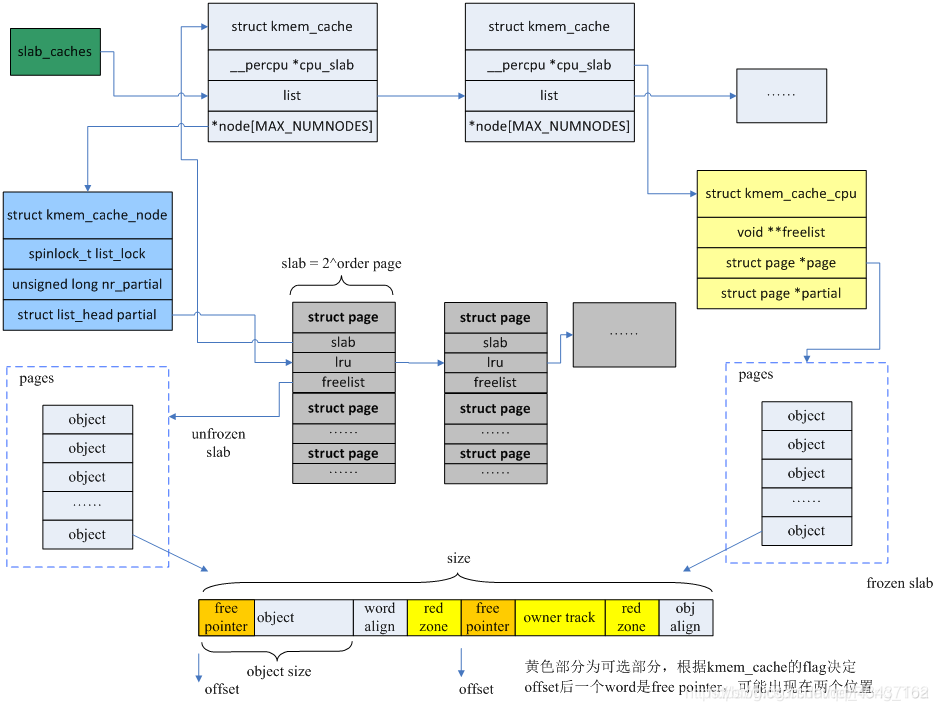
不同大小的对象难以一起管理
所以SLAB按照对象的大小进行分组 ,在分配的时候不会产生堆分配方式的碎片,也不会产生Buddy分配算法中的空间浪费,并且支持硬件缓存对齐来提高 TLB的性能,堪称完美。每 CPU节点单独维护SLAB队列,而且每个SLAB开头保存了该SLAB对象的metadata。
-
slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能
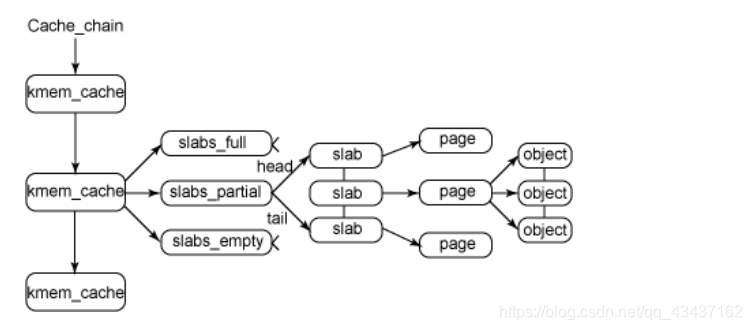 在最高层是cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit 算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。每一个kmem_cache都有三种队列,slabs_full/slabs_partial/slabs_empty
在最高层是cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit 算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。每一个kmem_cache都有三种队列,slabs_full/slabs_partial/slabs_empty -
slab 列表中的每个 slab 都是一个连续的内存块(一个或多个连续页)
-
slab 是 slab 分配器进行操作的最小分配单位,每个 slab 被分配为多个对象
-
slab 中的所有对象都被使用完时,就从 slabs_partial 列表中移动到slabs_full
-
slab 完全被分配并且有对象被释放后,就从 slabs_full 列表中移动到 slabs_partial 列表中
-
所有对象都被释放之后,就从 slabs_partial 列表移动到 slabs_empty 列表中
SLAB API
struct kmem_cache *slab_cache;
slab_cache* kmem_cache_create(const char *name, size_t size, size_t align, unsigned long flags, void (*ctor)(void*, struct kmem_cache *, unsigned long), void (*dtor)(void*, struct kmem_cache *, unsigned long));
kmem_cache_destroy
kmem_cache_alloc
kmem_cache_zalloc
kmem_cache_free
unsigned int kmem_cache_size( struct kmem_cache *cachep );
const char *kmem_cache_name( struct kmem_cache *cachep );
int kmem_cache_shrink( struct kmem_cache *cachep );
SLUB的诞生 (去看第二个链接的文章,写的很好)
由于SLAB算法节约了时间,但是耗费了大量的空间用来保存metadata和队列。
为了tradeoff时间和空间的消耗,诞生了SLUB,SLUB相对于SLAB有5%-10%的性能提升和减少50%的内存占用
每个缓冲区由多个小的slab 组成,每个 slab 包含固定数目的对象。SLUB分配器简化kmem_cache,slab等相关的管理数据结构,摒弃了SLAB 分配器中众多的队列概念,并针对多处理器、NUMA系统进行优化,从而提高了性能和可扩展性并降低了内存的浪费。
slub把内存分组管理,每个组分别包含23、4、…11个字节,在4K页大小的默认情况下,另外还有两个特殊的组,分别是96B和192B,共11组。之所以这样分配是因为如果申请2^12B大小的内存,就可以使用伙伴系统提供的接口直接申请一个完整的页面即可。
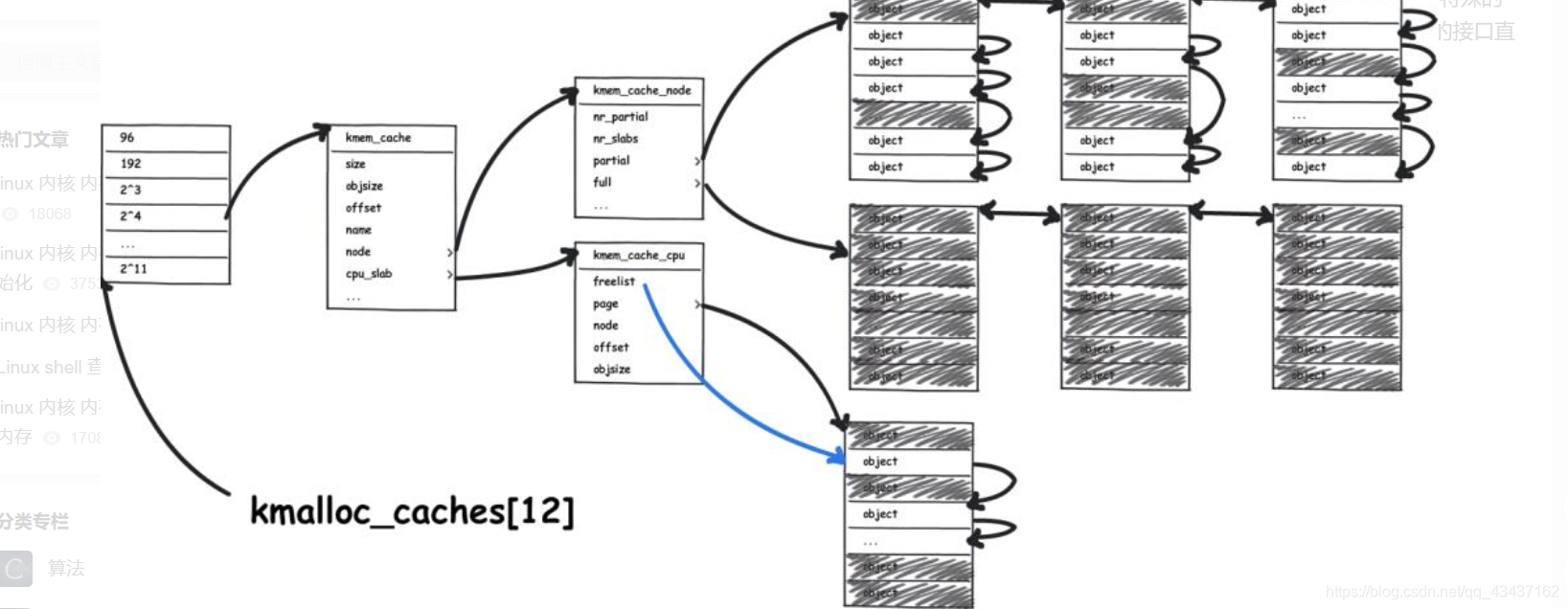
struct kmem_cache kmalloc_caches[PAGE_SHIFT] __cacheline_aligned;
物理页按照对象(object)大小组织成单向链表,对象大小时候objsize指定的。例如16字节的对象大小,每个object就是16字节,每个object包含指向下一个object的指针,该指针的位置是每个object的起始地址+offset

参考博客
ref :
- https://blog.youkuaiyun.com/rong_toa/article/details/106440497
- https://blog.youkuaiyun.com/lukuen/article/details/6935068?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.baidujs&dist_request_id=&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.baidujs

















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









