







前几章链接
目录
正则化
过拟合问题
下面是一个关于房价的回归问题例子:
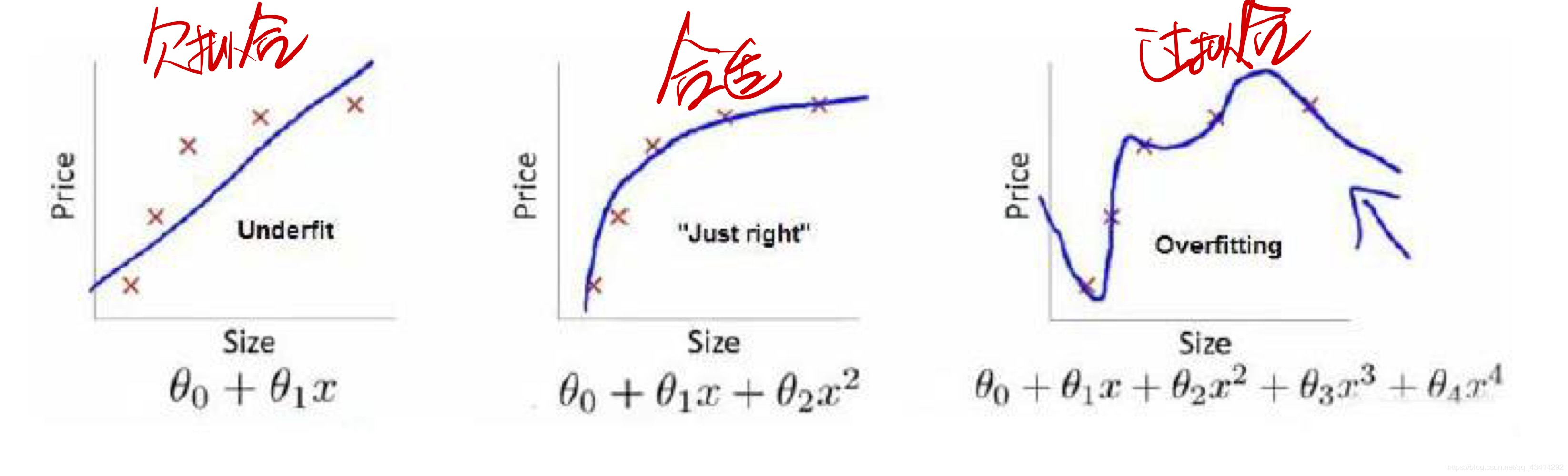
在第一幅图中,可以看到拟合的并不是很好,这叫做欠拟合。根据训练集我们可以看出,当房屋面积越来越大时,房价也开始趋于平缓。相反,第二幅图就拟合得很好。与欠拟合对应的的是过拟合,就如第三幅图,过分的强调训练集中的数据。它相较于该训练集拟合的可以说是完美,但是如果用来预测其他新的数据,它的表现会很差,即泛化性差。
从多项式的角度来看,x的幂次越高,拟合的越好,但是如果超过了一定的界限,就会造成过拟合,使预测能力下降。
分类问题也一样,这里不再过多解释。
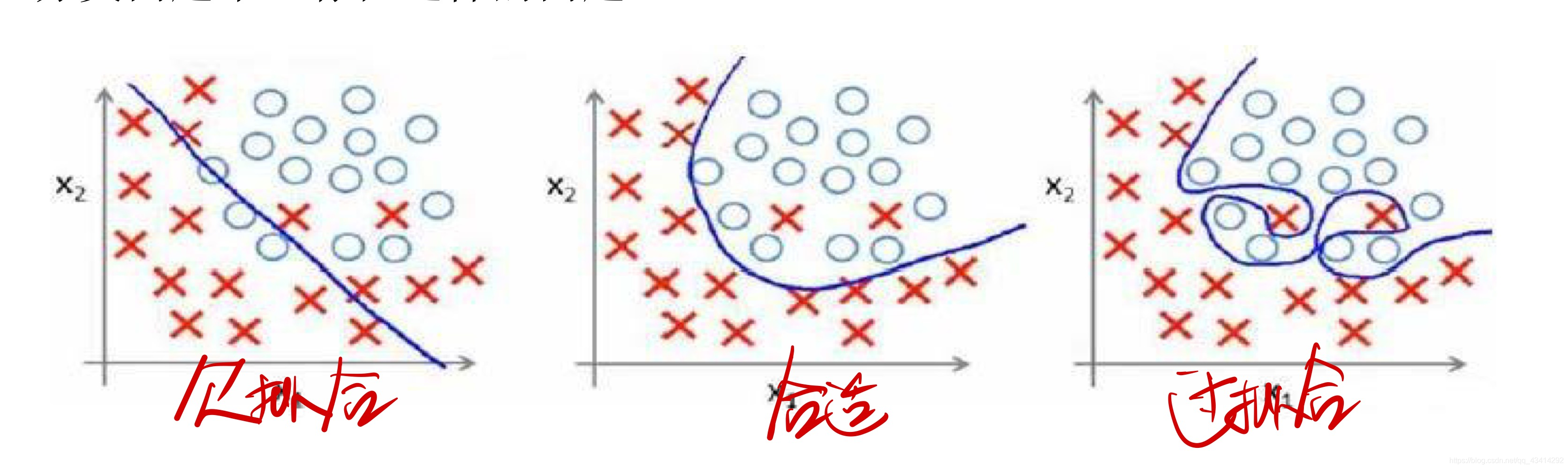
问题已经提出来了,那么该如何解决过拟合的问题呢?主要有以下两个办法。
- 丢弃一些对于预测没有用的特征。我们可以人工筛选出一些比较重要的特征,或者利用一些模型选择的方法来帮助我们。
- 正则化。也许你会发现有很多特征,但是每一个都很重要,你无法取抛弃它们,这时候就需要减少参数的大小。
正则化原理
惩罚高阶参数,使其系数趋近于0。
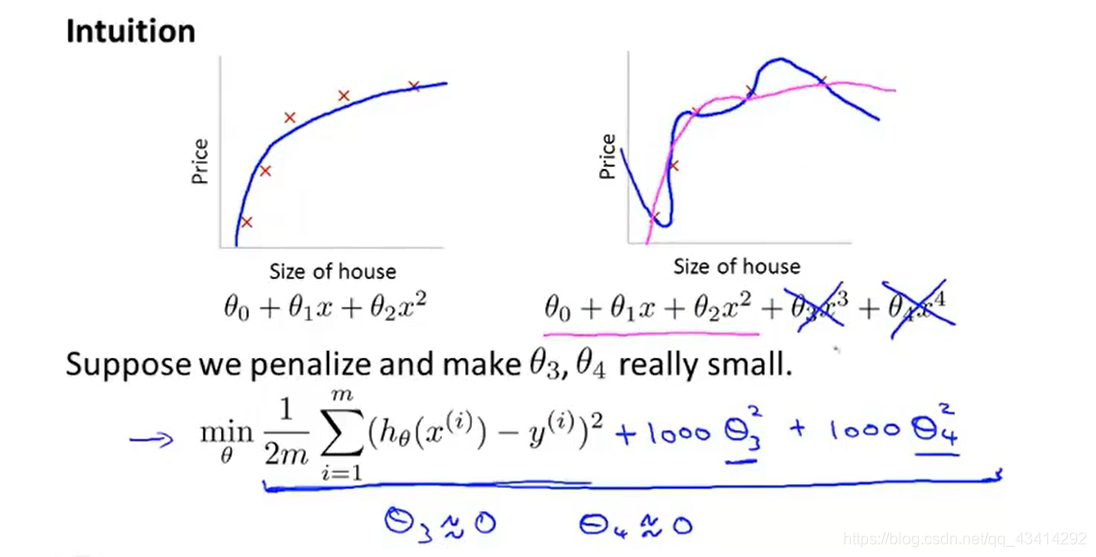
在上例中我们对和
设置惩罚项,要想使代价函数尽可能的小,它们就会都趋近于0,此时最高幂次为二次,过拟合也就会被消除。假设有很多个特征,但是我们不知道应该惩罚哪些,此时就应该一个都不放过,对所有特征进行惩罚,但是也需要掌握好惩罚程度,否则过大的话会导致模型最后变成
(根据惯例
不惩罚),直接变成一条直线,显然这是不对的。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











