




 本文详细介绍了PyTorch中如何进行反向传播,通过实例展示了如何设置变量和函数,以及如何使用`requires_grad=True`标记可求导变量,并通过`z.backward()`执行反向传播计算梯度。此外,还提及了`retain_graph=True`选项,用于在不释放计算图的情况下进行多次求导。
本文详细介绍了PyTorch中如何进行反向传播,通过实例展示了如何设置变量和函数,以及如何使用`requires_grad=True`标记可求导变量,并通过`z.backward()`执行反向传播计算梯度。此外,还提及了`retain_graph=True`选项,用于在不释放计算图的情况下进行多次求导。
设置变量x1, x2, x3
设置函数
z = x1 * x2 + x3
并且对x1进行求导,所以求出的结果因该为x2
requires_grad=True //设置变量是可以求导的
z.backward()//是z进行反向传播
retain_graph = True//可以进行多次的求导
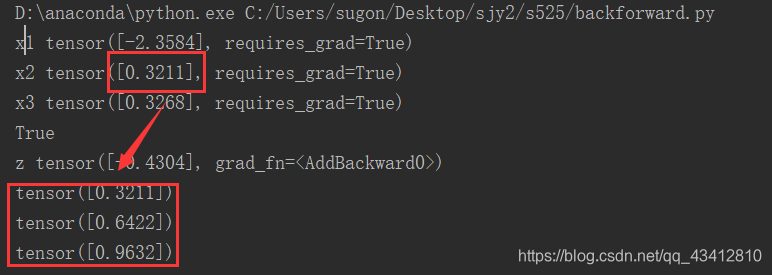
x1 = torch.randn(1, requires_grad=True)
print("x1", x1)
x2 = torch.randn(1, requires_grad=True)
print("x2", x2)
x3 = torch.randn(1, requires_grad=True)
print("x3", x3)
y = x1*x2
z = y+x3
print(z.requires_grad)
print('z', z)
# 梯度如果不清空,每次循环就会累加
z.backward()
# print(y.grad)
print(x1.grad)

x1 = torch.randn(1, requires_grad=True)
print("x1", x1)
x2 = torch.randn(1, requires_grad=True)
print("x2", x2)
x3 = torch.randn(1, requires_grad=True)
print("x3", x3)
y = x1*x2
z = y+x3
print(z.requires_grad)
print('z', z)
# 梯度如果不清空,每次循环就会累加
for i in range(0, 3):
z.backward(retain_graph = True)
# print(y.grad)
print(x1.grad)


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









