







 本文详细介绍了服务器编程中的C/S模型和P2P模型,对比了它们的优缺点,深入解析了I/O模型,包括同步I/O、异步I/O、I/O复用等概念,以及Reactor和Proactor两种事件处理模式。
本文详细介绍了服务器编程中的C/S模型和P2P模型,对比了它们的优缺点,深入解析了I/O模型,包括同步I/O、异步I/O、I/O复用等概念,以及Reactor和Proactor两种事件处理模式。
服务器解构的分类
服务器解构主要分为如下三个主要模块:
1、I/O处理单元。接收客户端发送的数据都属于I/O处理单元。
2、逻辑单元。接收到数据之后进行的一些处理都属于逻辑单元。
3、存储单元。
如下图所示(服务器编程框架):
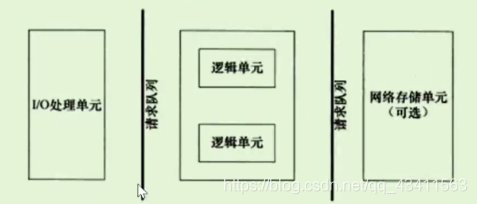
服务器模型的分类
1、C/S模型
C就是客户端,S就是服务器。所以这个模型也称客户端/服务器模型。
C/S模型如下图所示:
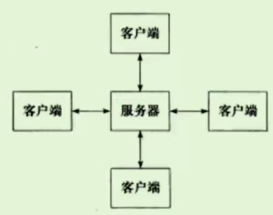
现在大多数的公司用的都是C/S模型。也就是一组服务器,所有的客户端要上网的时候都要访问这个服务器。
C/S模型的逻辑
C/S模型的逻辑很简单,服务器启动后,首先创建一个(或多个)监听socket,并调用bind函数将其绑定到服务器感兴趣的端口上,然后调用listen函数等待客户连接。服务器稳定运行之后,客户端就可以调用connect函数向服务器发起连接了。由于客户连接请求是随机到达的异步事件,服务器需要使用某种I/O模型来监听这一事件。
C/S模型的缺点
C/S模型非常适合资源相对集中的场合,并且它的实现也很简单,但其缺点也很明显:服务器是通信的中心,当访问量过大时,可能所有客户都将得到很慢的响应。下面讨论的P2P模型解决了这个问题。
2、P2P模型
P2P模型也就是点对点模型。
以下是两种P2P模型。
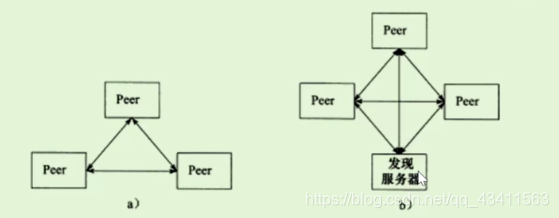
P2P 模型比C/S模型更符合网络通信的实际情况。它摒弃了以服务器为中心的格局,让网络上所有主机重新回归对等的地位。P2P模型使得每台机器在消耗服务的同时也给别人提供服务,这样资源能够充分、自由地共享。云计算机群可以看作P2P模型的一个典范。但P2P模型的缺点也很明显:当用户之间传输的请求过多时,网络的负载将加重。
I/O模型
1、同步I/O和异步I/O模型的区别
- 对异步1/O而言,用户可以直接对I/O执行读写操作,这些操作告诉内核用户读写缓冲区的位置,以及I/O操作完成之后内核通知应用程序的方式。
- 异步I/O的读写操作总是立即返回,而不论I/O是否是阻塞的,因为真正的读写操作已经由内核接管。
- 也就是说,同步I/O模型要求用户代码自行执行1/O操作(将数据从内核缓冲区读人用户缓冲区,或将数据从用户缓冲区写人内核缓冲区),而异步IO机制则由内核来执行I/O操作(数据在内核缓冲区和用户缓冲区之间的移动是由内核在“后台”完成的)。
- 可以这样认为,同步I/O向应用程序通知的是I/O就绪事件,而异步I/O向应用程序通知的是1/O完成事件。
- Linux环境下,aio.h 头文件中定义的函数提供了对异步IO的支持。
2、几种I/O模型的对比
| I/O模型 | 读写操作和阻塞阶段 |
|---|---|
| 阻塞I/O | 程序阻塞于读写函数 |
| I/O复用 | 程序阻寓于I/O复用系统调用,但可同时监听多个10事件。对I/O本身的读写操作是非阻塞的。 |
| SIGIO信号 | 信号触发读写就绪事件,用户程序执行读写操作。程序没有阻塞阶段 |
| 异步I/O | 内核执行读写操作并触发读写完成事件。程序没有限塞阶段 |
两种高效的事件处理模式
服务器程序通常需要处理三类事件:I/O事件、信号及定时事件。这两种高效的事件处理模式是:Reactor模式和Proactor模式
1、Reactor模式
1.1.1 Reactor模式要求主线程只负责监听文件描述符上是否有事件发生,有的话立即将该事件通知工作线程。除此之外,主线程不做任何其他实质性的工作,读写数据,接收新的连接以及处理客户请求均在工作线程中完成。
1.1.2 工作流程
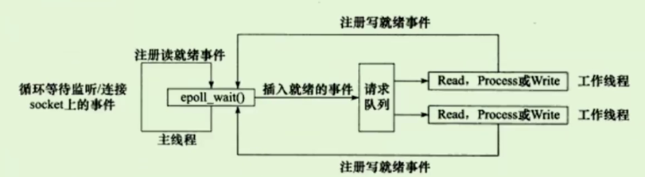
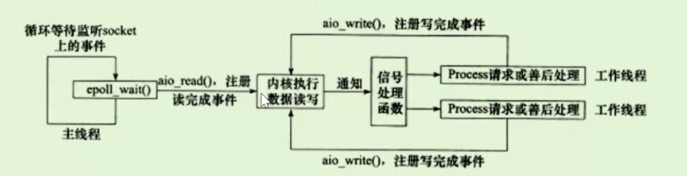
2、Proactor模式
与Reactor完全不同。Proactor模式将所有I/O操作都交给主线程和内核来处理,工作线程仅仅负责业务逻辑。所以Proactor更符合服务器编程框架。
2.1 工作流程

















 5681
5681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









