




 本文介绍了一种名为PTE的高效算法,它通过将异构文本网络嵌入低维空间来学习文本的分布式表示。PTE算法能够从未标记数据和标记信息中提取词共现信息,适用于特定的分类任务。通过此算法学习到的单词表示不仅更健壮,也更适合于特定的任务。
本文介绍了一种名为PTE的高效算法,它通过将异构文本网络嵌入低维空间来学习文本的分布式表示。PTE算法能够从未标记数据和标记信息中提取词共现信息,适用于特定的分类任务。通过此算法学习到的单词表示不仅更健壮,也更适合于特定的任务。

贡献:
提出了一种高效的算法“PTE”,它通过将异构文本网络嵌入低维空间来学习文本的分布式表示。
问题定义
定义1。(word-word Network)
表示为Gw_www_ww=(V,Ew_www_ww),捕获未标记数据的本地上下文中的词共现信息。V是单词的词汇表,ew_www_ww是单词之间的一组边。单词vi_ii和vj_jj之间的边的权重,定义为两个单词在给定窗口大小的上下文窗口中同时出现的次数。
定义2。(Word-Document Network)
表示为Gw_wwd_dd=(V∪D,Ew_wwd_dd),是一个二分网络,其中D是一组文档,V是一组单词。ew_wwd_dd是单词和文档之间的一组边。单词vi_ii和文档dj_jj之间的权重wi_iij_jj简单地定义为文档dj_jj中vi_ii出现的次数
定义3。(Word-Label Network)
示为Gwl=(V∪L,Ew_wwl_ll),是一个捕获类别级单词共现的二分网络。L是一组类标签,V是一组单词。ew_wwl_ll是单词和类之间的一组边。定义词vi_ii与cj_jj类之间的边的权重为:
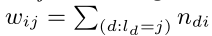
,其中nd_ddi_ii是文档d中单词vi_ii的词频,ld_ddi_ii是d文档的类标签
定义4。(Heterogeneous Text Network)
三个图共同组成
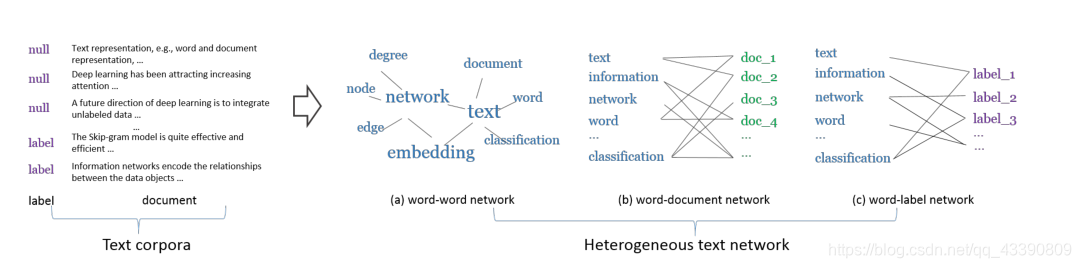
二部图网络嵌入
方法:LINE的二阶方法(参考上一篇博客)
异构文本网络嵌入
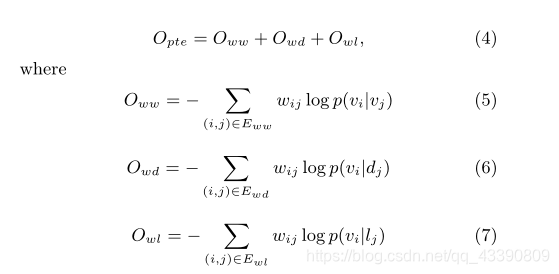
文本嵌入
异构文本网络对词在不同层次上的共现进行编码,从未标记数据和标记信息中提取,用于特定的分类任务。因此,通过嵌入异构文本网络学习的单词表示不仅更健壮,而且更适合该任务。一旦学习了单词向量,就可以通过简单地平均该文本中单词的向量来获得任意文本的表示。
一段文本的向量表示d=w1w2···,wn可以计算为



















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









