







1.循环依赖
1.1 什么是循环依赖问题
我们来看一张图
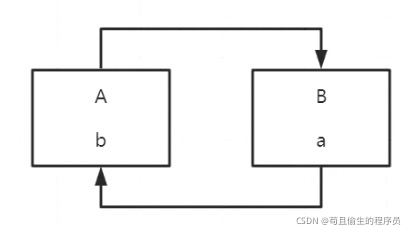
上图中A类有一个属性B对象,B类中有一个属性A。
那么在初始化A对象时发现B对象还未实例化,此时会去进行B对象的实例化和初始化赋值,当对B对象进行初始化赋值时去单例池中查找A对象未找到,发现A对象并未成功被初始化,此时又去进行A的初始化操作,如此往复便陷入了死循环。
可以看出在对属性进行赋值时,产生了问题。我们通常有两种方式对属性进行赋值,一种是构造器一种是setter方法
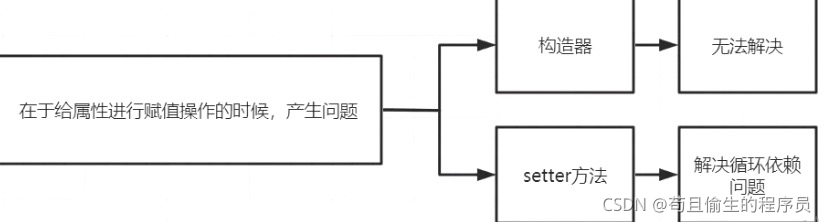
在Spring中采用的是setter方法进行属性赋值,为什么不采用构造器的方式呢?因为构造器的方式无法解决循环依赖问题,它的实例化和初始化是一起进行的,这导致它无法在中间步骤进行解决循环依赖
1.2 如何解决循环依赖问题
如何解决之前我们先了解下bean的生命周期
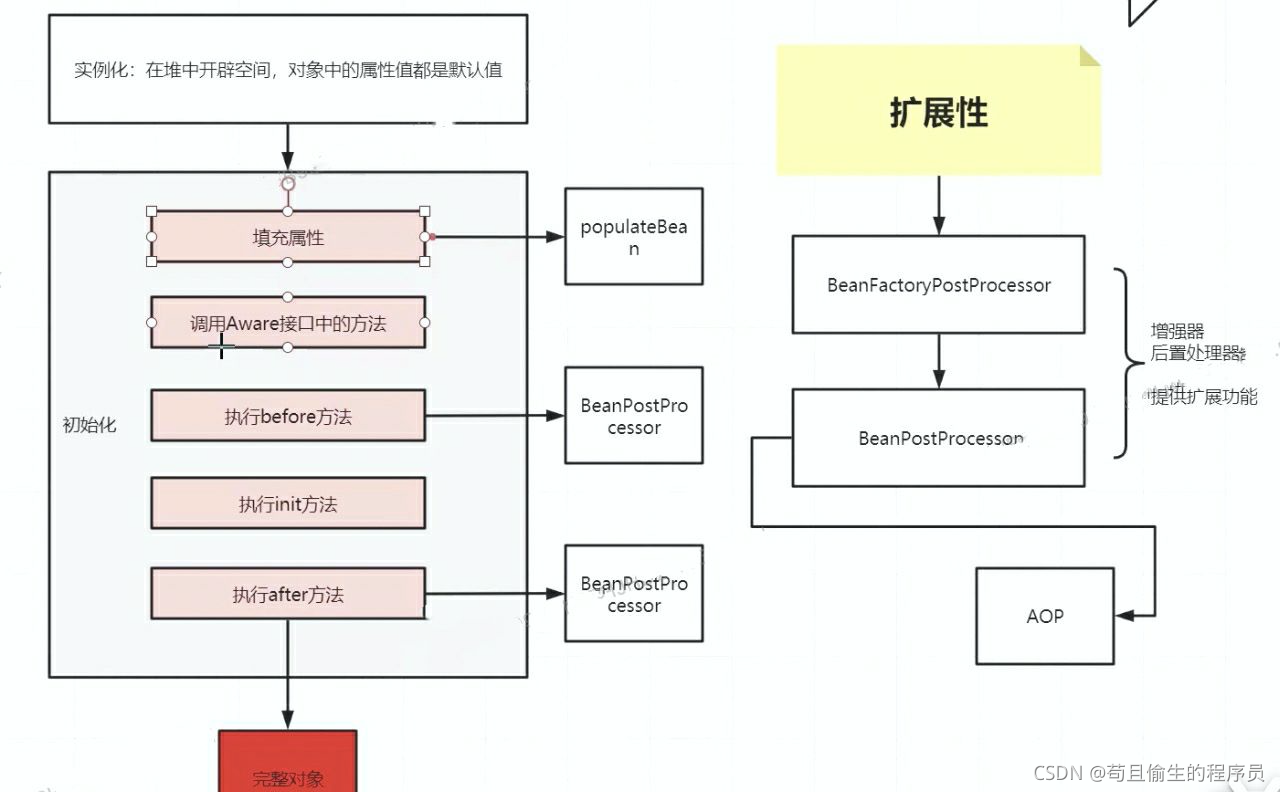
从上图可以看出对象的创建包含实例化和初始化两部分。
接下来我们用图形来展示循环依赖是怎样形成的:

从上图可知,循环依赖的关键在于从单例池(一级缓存)是否查找的出对象。
怎么解决? 是不是只要从单例池中查找出对应的对象,那么这个循环依赖的闭环是不是就解决了呢。
我们再来看一下对象的两种状态:半成品和成品
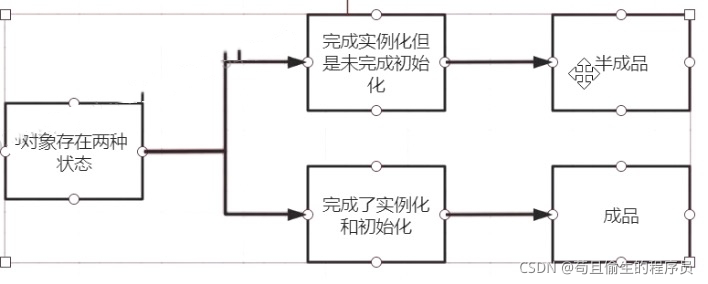
在Spring中,成品对象会被放入一级缓存,半成品对象会被放入二级缓存用来解决循环依赖问题。当A对象完成实例化后,半成品A对象会被放入二级缓存。A的初始化需要填充B属性,在B对象的初始化过程中需要填充属性A,会从二级缓存中拿出半成品对象填入,此时B对象完成创建,只不过现在B对象里的A属性是一个半成品对象。B对象创建完成后又回来继续进行A对象的初始化赋值操作,此时可以查找出B对象,继续进行剩余的赋值操作,初始化完成后得到成品A对象。此时B对象里是一个成品A对象,A对象里是一个成品B对象,这就解决了循环依赖问题。
接下来我们看看源码
在看源码之前,我们要知道创建一个对象都要经历以下源码步骤:

入口:

源码分析
我们找到getBean方法

进入getBean方法

在Spring源码中,凡是以do开头的方法都是实际干活的代码,这里面的逻辑很重要
进入doGetBean方法

这里不出意外shareInstance是null,这里先检查单例池有没有手动注册的单例对。
接下来到达createBean方法
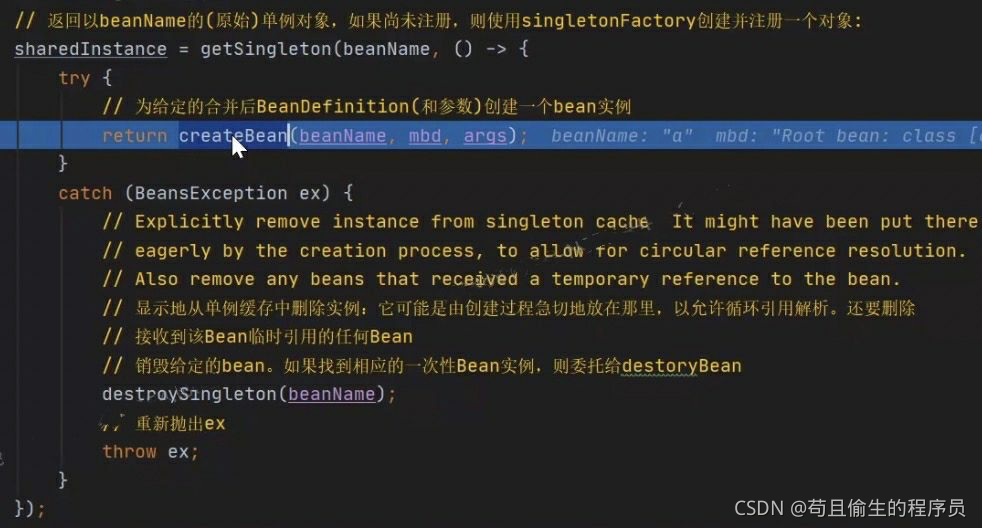
进入createBean方法开始实际的创建bean,到达doCreateBean方法

在doCreateBean方法中创建实例对象,此时A,B对象的属性都是null

接下来应该是填充属性,但在填充属性之前向三级缓存存了个东西,这个东西是一个lambda表达式,这个lanbda表达式指向getEarlyBeanReference(beanName, mbd, bean);

之后对对象填充属性,populateBean方法
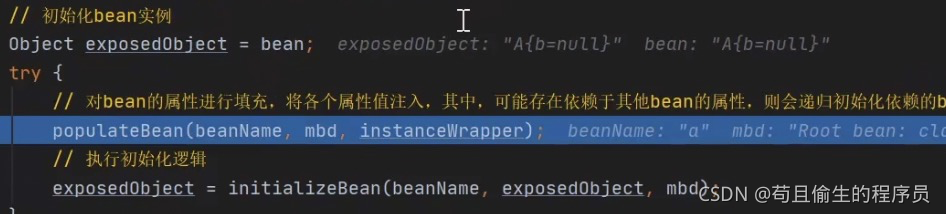
进入populateBean方法,到达填充属性具体的地方applayPropertyValues方法

我们现在要给A对象里面的属性B进行赋值,进入applayPropertyValues方法,获取属性的名字,属性的类型,此时发现B对象的类型是RuntimeBeanReference而不是B类型

往下走:
进入该方法:
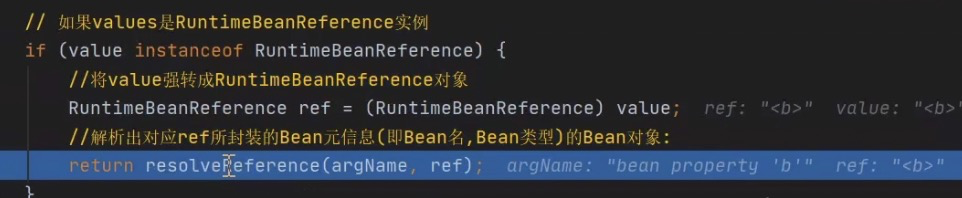
此时value的类型是RuntimeBeanReference
进入resolveReference方法,往下走发现getBean方法,此时我们才走填充属性阶段,接下来应该是从容器中查找B对象,这个时候你会发现此处的getBean是不是就是我们开头的那个getBean方法,只不过参数换成了b。此时又绕到了B对象的创建过程,假设我们没有三级缓存,后面将陷入A->B B->A 的轮回死循环中。
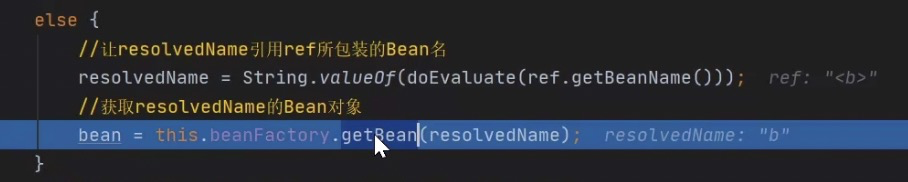
经过A->B B->A我们又到了:

此时在第三级缓存中有a和b,我们进入getSingleton方法
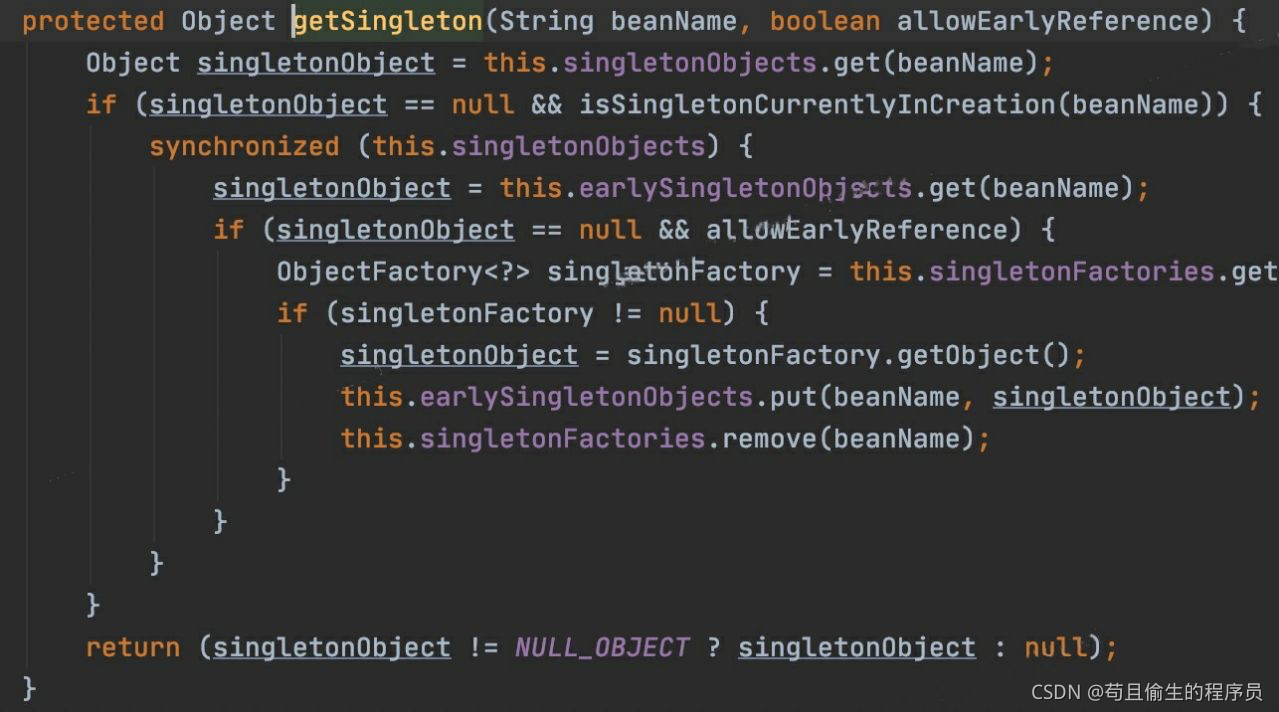
//从单例对象缓存中获取beanName对应的单例对象,singletonObjects是一级缓存
Object singletonObject = this.singletonObjects.get(beanName);
//如果一级缓存中没有且该beanName对应的单例bean正在创建中,此时我们的A,B对象都完成了实例化但没完成初始化表示正在创建中,后半判断为true
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
//如果为空,则锁定全局对象并进行处理
synchronized (this.singletonObjects) {
//从二级缓存中获取单例对象,此时二级缓存没有A,B对象
singletonObject = this.earlySingletonObjects.get(beanName);
//如果二级缓存也没有,allowEarlyReference传进来为true,则进入
if (singletonObject == null && allowEarlyReference) {
//从三级缓存取出对应的lambda表达式,此时取出的是A对应的lambda表达式,这个`lambda表达式指向getEarlyBeanReference(beanName, mbd, bean)
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
//如果对象对应的lambda不为空
if (singletonFactory != null) {
//执行lambda表达式,也就是getEarlyBeanReference方法,此时会返回原来的那个半成品对象A
singletonObject = singletonFactory.getObject();
//记录在二级缓存中,二级缓存和三级缓存的对象不能同时存在
this.earlySingletonObjects.put(beanName, singletonObject);
//将三级缓存中对应的A对象的lambda删除
this.singletonFactories.remove(beanName);
}
经过A->B,B->A此时在B对象初始化填充A属性时this.beanFactory.getBean返回的是半成品A对象,此时B对象便可以继续填充其他属性而不会陷入死循环当中。之后B完成初始化成为了成品对象,只不过B对象里面的A属性是一个半成品对象,此时继续进行A对象的初始化操作,A初始化操作里的this.beanFactory.getBean返回值是B成品对象,此时A填充完其他属性后也成为了成品对象。这时A,B对象都是一个完整的对象。
在成品B对象在返回的途中,调用第三级缓存的lambda表达式的createBean方法后,执行addSingleton方法
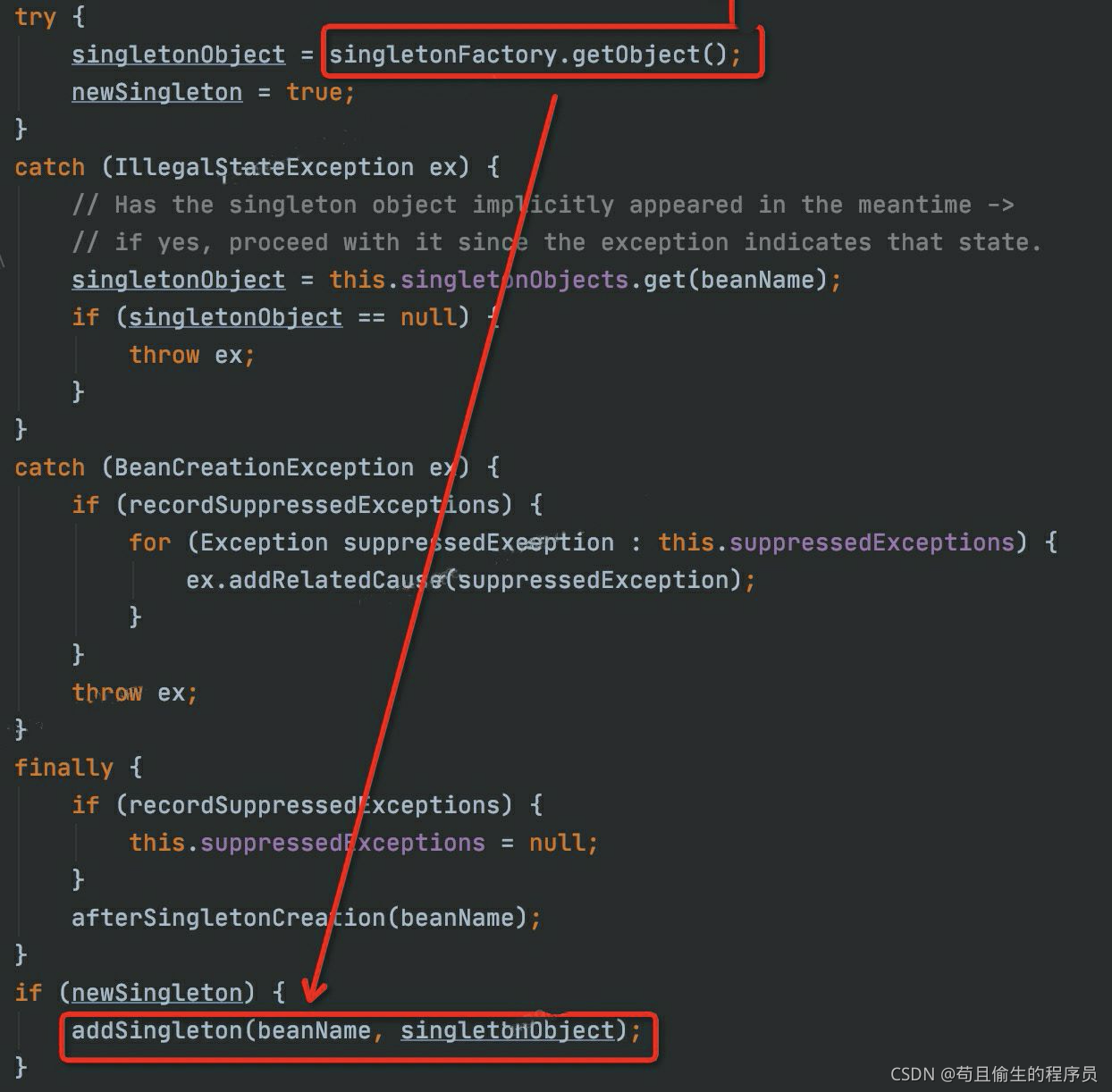
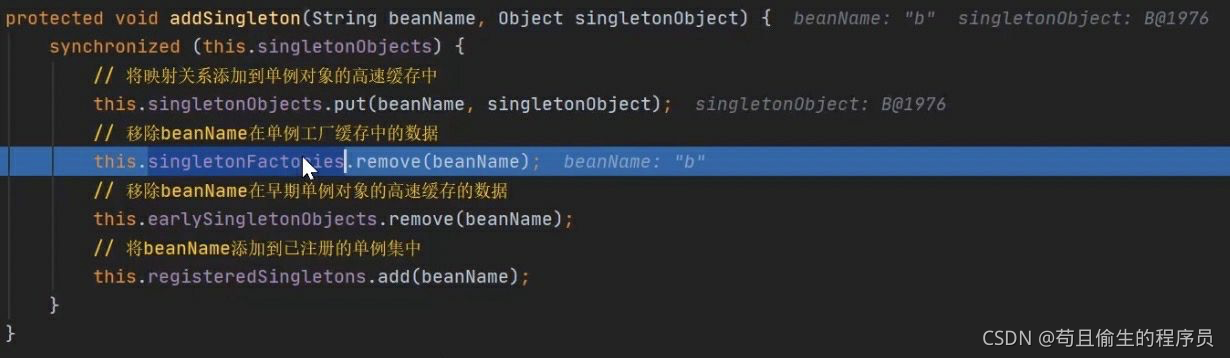
将成品对象放入一级缓存,二级三级缓存删除b
1.2.1总结
1.2.1.1 为什么要移除二三级缓存?
在三级缓存中,我们先找一级,再找二级,再找三级,那么如果一级缓存中已经有了对象,就不会去二级中查找,将二三级缓存移除可以减少内存的使用。
1.2.1.2 如果只有一级缓存能否解决循环依赖问题?
不能。在一级缓存中存放的是成品对象,在二级缓存中存放的是半成品对象。如果只有一级缓存的话,那么成品对象和半成品对象就会存放在一起,这时有可能拿错。也不要说加标示判断,加标示判断会使逻辑及其复杂,为什么不直接使用二级缓存呢。
1.2.1.3 如果只有二级缓存能否解决循环依赖问题?
当对象没有使用到AOP时,使用二级缓存是可以解决循环依赖问题的,接下来我们来说为什么要用三级缓存。
1.3 为什么非要使用三级缓存
三级缓存存在的本质目的是为了解决AOP过程中动态代理的时候如何处理!
我们来看向三级缓存put时都做了什么操作
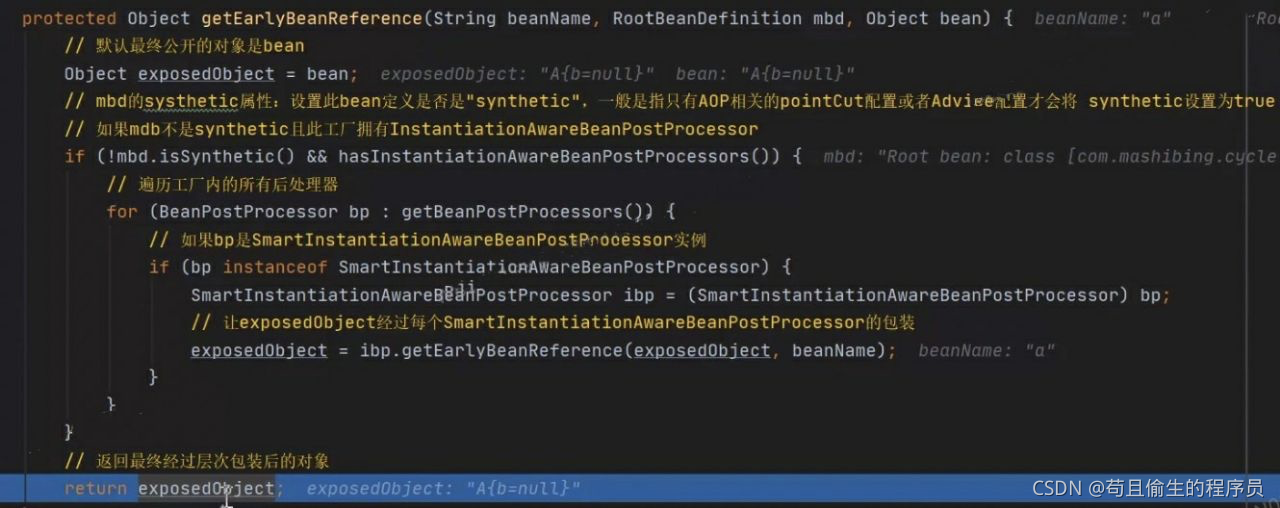
进入getEarlyBeanReference(expseObject, beanName)重载方法

进入他的实现类:
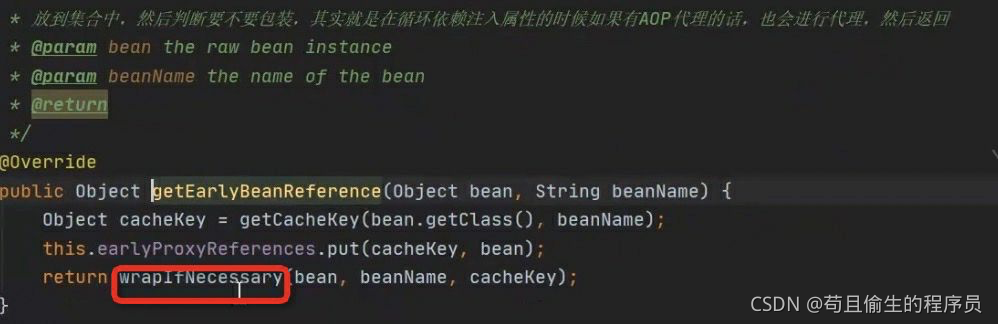
进入wrapIfNecessary方法
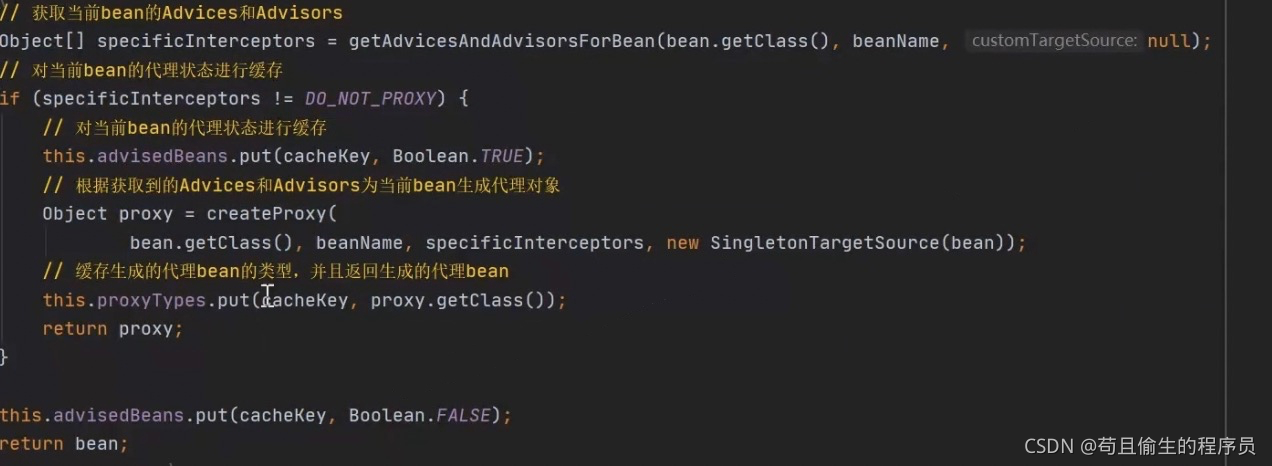
此时我们看到创建代理对象的动作createProxy,创建完代理对象后返回。
进入createProxy方法,我们可以看到真正创建代理对象的地方
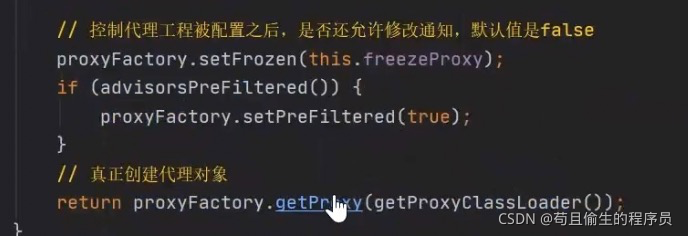
进入getProxy方法,我们看到了非常熟悉的两种动态代理模式

此时我们发现经过了getEarlyBeanReference这个方法后,原本的对象就有可能被替换为代理对象。那为什么加了三级缓存之后就解决了这个问题呢?
我们再来看一段代码
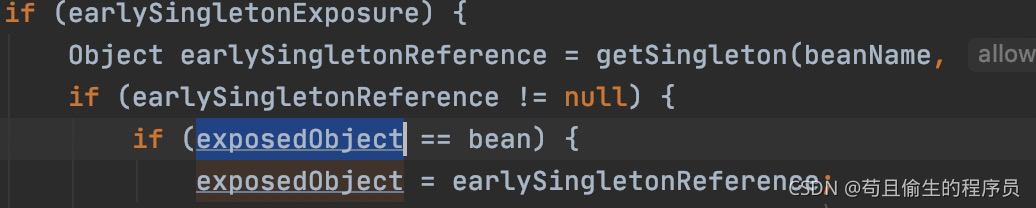
我们思考一个问题,当创建完B成品对象的过程中,创建出来一个A的代理对象,然后完成B对象的初始化,创建B成品对象。此时B对象里面的属性A是一个代理对象A,那么在B成品对象创建完之后接下来应该是继续A对象的初始化填充其他的属性,但此时的A对象是通过createBeanInstance(beanName, mbd, args)方法创建出来的原生对象,这样A初始化完成后第一级缓存里面A对象是原生对象,A对象里面的B属性对象里的A属性对象是一个代理对象,此时就会暴露出来两个A对象。上面这段代码就是为了解决这个问题,这段代码的逻辑是填充完属性之后再调用一次getSingleton(beanName,false),第二个参数传的是false,此时只会判断对象在第二级缓存是否存在,如果存在且还是原生对象则把将要返回出去exposedObject对象替换成第二级缓存里的对象,后面我们返回A对象时便返回的是第二级缓存里的A代理对象。
我们再一次来看这张图:
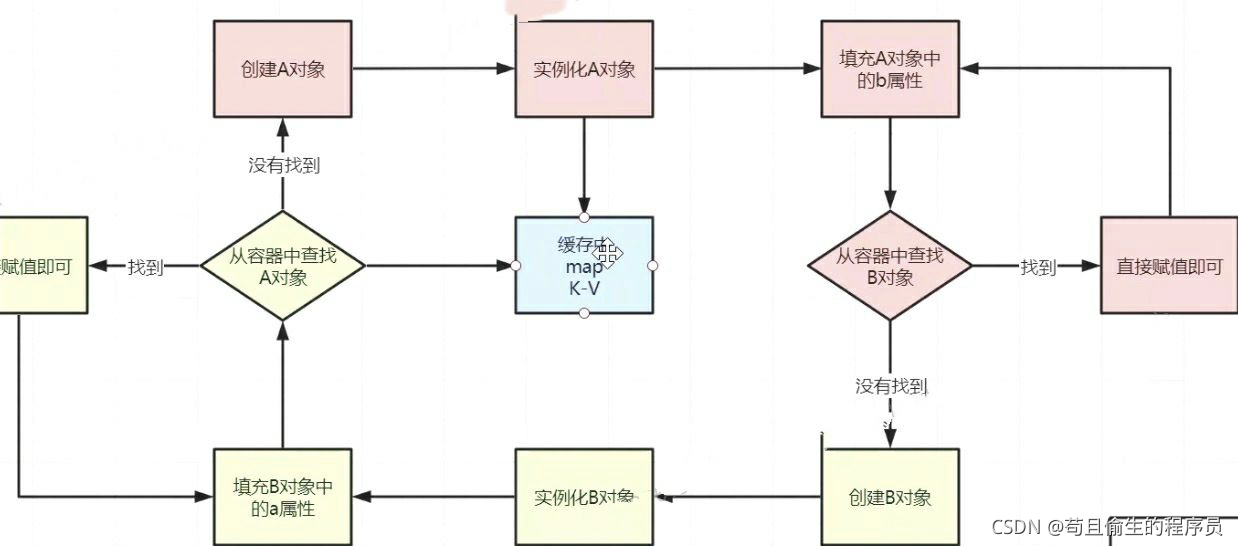
假设只有二级缓存,当我们实例化A和实例化B后,到了从缓存中查找A对象环节,此时会发现我们不知道该A对象是否需要被代理。
有人可能会想为什么不能在查找A对象后加入一个判断A对象是否需要代理的逻辑,如果需要则把第二级缓存里的半成品对象覆盖成代理对象,这样不就不要第三级缓存了吗?是的的确,但是我们仔细捋一捋上面的流程,会发现当B对象初始化过程查找A对象时,加入了判断是否代理的逻辑,那么查找出的就是A对象的代理对象并会放入第二级缓存,此时B是一个完整对象,那么就会继续A的初始化操作,这时问题来了,因为判断是否需要代理是在查找对象之后那么代理对象放入二级缓存的时机肯定也是在查找对象之后,此时的A对象是原生对象,最后会导致A原生对象里有一个B代理对象,B代理对象里有一个A的代理对象,这就同时暴露了两个A对象出来。
2.IOC
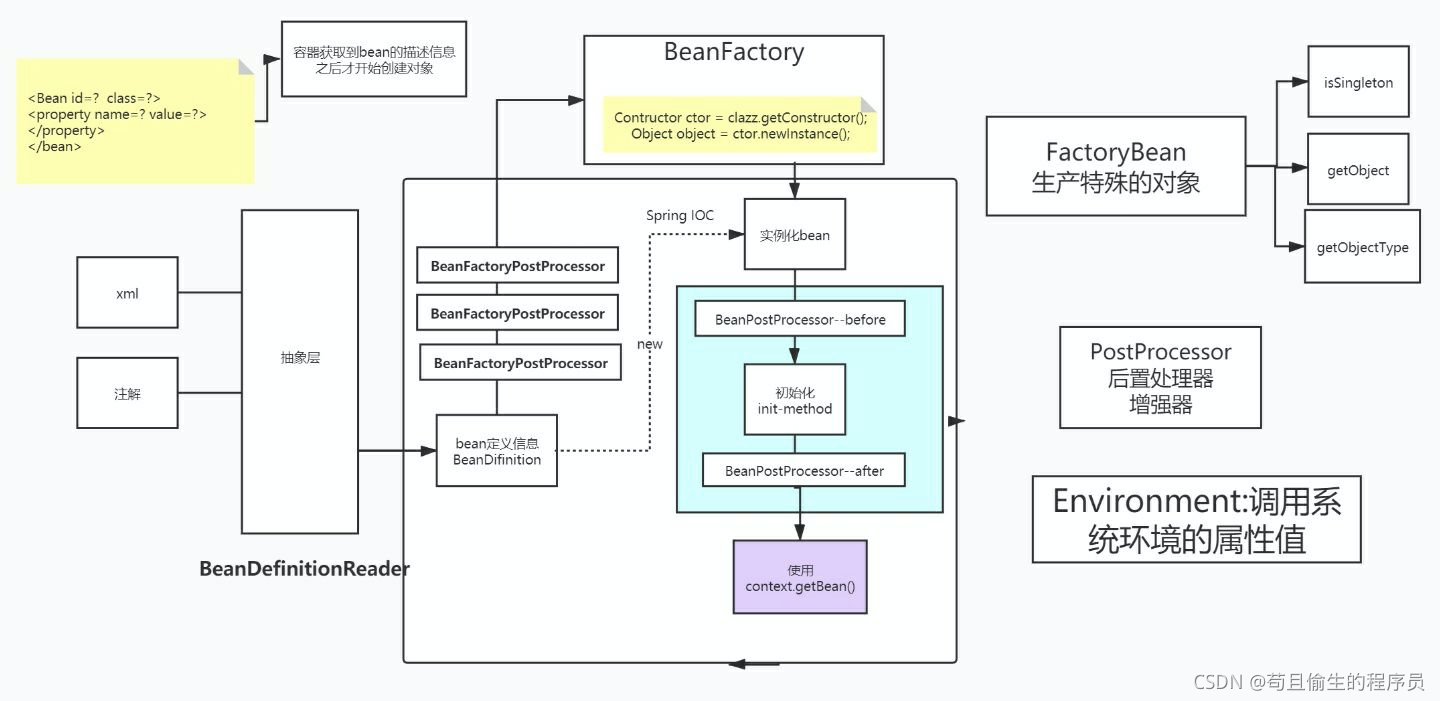
2.1Spring源码整体流程图
2.2 BeanFactoryPostProcessor
我们先来了解下什么是BeanFactoryPostProcessor,他的作用是什么?
通常我们把PostProcessor称为后置处理器或增强器,那么BeanFactoryPostProcessor自然就是BeanFactory的后置处理器,接下来我们举一个例子;
在使用配置文件的时候,我们经常需要配置数据源;
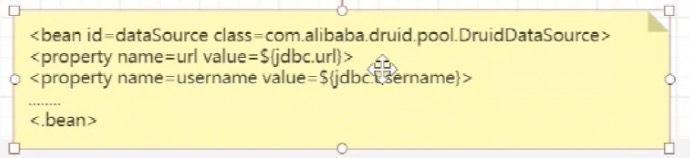
那么我们思考一个问题,文件经过加载解析到BeanDefinition,在这个过程中会将{jdbc.url}等进行替换成真正的值吗??答案是不会。真正的值替换在我们的后置处理器中-BeanFactoryPostProcessor,我们来看下BeanFactoryPostProcessor这个接口;
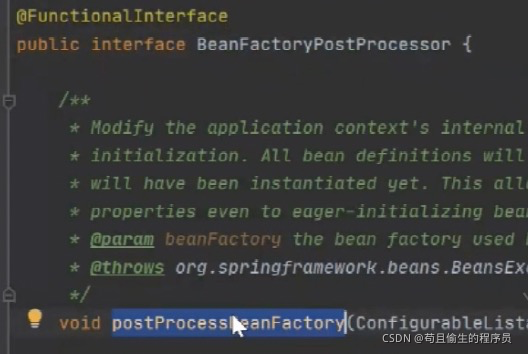
找到其中的一个子类PlaceholderConfigurerSupport,翻译过来就是占位符配置支持处理;
我们来看beanDefinitionMap里面值的情况,当刚经过bean的加载解析后我们看下值有没有被替换?


此时可以发现经过加载解析后,beanDefinitionMap里面的值还没有被替换。
往下走,到达invokeBeanFactoryPostProcessors,从名字就可以看出是调用各种的beanFactory处理器
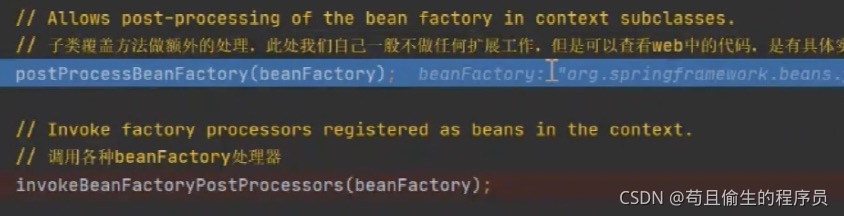
执行完invokeBeanFactoryPostProcessors,我们再来看下beanDefinitionMap里面的值有没有被替换
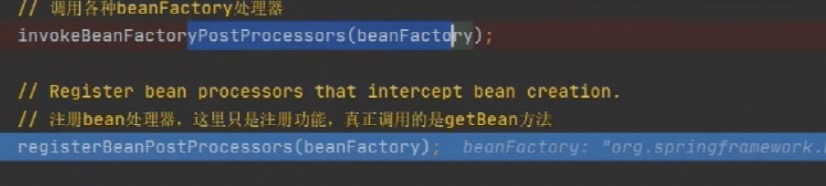
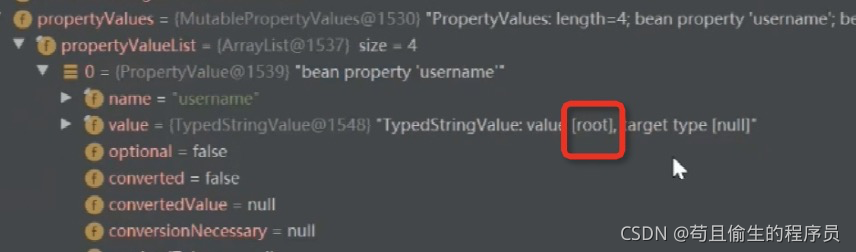
此时我们看到{jdbc.username}被替换成真实的值root;
那么假如我们要改beanDefinitionMap里面的bean的信息怎么修改??
我们可以自定义一个beanFactoryPostProcessors实现BeanFactoryPostProcessor接口

拿到对应的BeanDefinition后,我可以对里面的信息做任意的修改


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









