




Oracle03 - Oracle高级部分
一:序列sequence
序列是Oracle数据库中特有的,使用序列可以生成类似于 auto_increment 这种ID自动增长 1,2,3,4,5… 的效果
1:创建序列
create sequence [序列名称]
[INCREMENT BY n] -- 序列每次增加的步长(默认为1)
[START WITH n] -- 序列起始值(默认为1)
[{MAXVALUE n | NOMAXVALUE}] -- 序列最大值
[{MINVALUE n | NOMINVALUE}] -- 序列最小值
[{CYCLE | NOCYCLE}] -- 达到最大值后是否循环(默认为NOCYCLE)
[{CACHE n | NOCACHE}] -- 是否缓存序列值以提高性能(默认为CACHE 20)
[{ORDER | NOORDER}]; -- 是否保证序列值按请求顺序生成
CREATE SEQUENCE employee_seq
INCREMENT BY 1
START WITH 1000
MAXVALUE 999999
NOCYCLE -- 达到最大值也不循环
CACHE 20;
2:使用序列
-- 获取下一个序列值
SELECT sequence_name.NEXTVAL FROM dual;
-- 获取当前的序列值
SELECT sequence_name.CURRVAL FROM dual;
-- 例如在插入语句中
INSERT INTO employees (id, name) VALUES (employee_seq.NEXTVAL, '张三');
3:修改序列
-- 不能修改START WITH值,如需修改需删除后重建序列
ALTER SEQUENCE sequence_name
[INCREMENT BY n]
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}]
[{CACHE n | NOCACHE}]
[{ORDER | NOORDER}];
4:删除序列
DROP SEQUENCE sequence_name;
二:PL/SQL编程
PL/SQL (Procedural Language extensions to SQL) 是 Oracle 数据库的过程化编程语言
它结合了 SQL 的数据操作能力和过程化语言的流程控制能力。
1:PL/SQL基础结构
DECLARE
-- 声明部分 (可选)
-- 变量、常量、游标、异常等声明
BEGIN
-- 执行部分 (必需)
-- PL/SQL 语句和 SQL 语句
[EXCEPTION]
-- 异常处理部分 (可选)
-- 异常处理程序]
-- when 异常类别 then ..., 异常类别如下:
-- zero_divide :除数为零异常
-- value_error :类型转换异常
-- no_data_found : 没有找到数据
-- too_many_rows : 查询出多行记录,但是赋值给了%rowtype一行数据变量
END;
举一个简单的例子:
-- 1. 声明两个变量用于存储员工姓名和薪资
-- 2. 从employees表中查询employee_id=100的员工的全名和薪资
-- 3. 将查询结果赋值给变量
-- 4. 输出员工姓名和薪资信息
-- 5. 如果找不到该员工,捕获异常并输出提示信息
DECLARE
v_employee_name VARCHAR2(100); -- 定义一个v_employee_name变量,类型是varchar2(100)
v_salary NUMBER; -- 定义一个v_salary变量,类型是number
BEGIN
SELECT first_name || ' ' || last_name, salary
-- 将first_name || ' ' || last_name赋值给v_employee_name
-- 将salary赋值给v_salary
INTO v_employee_name, v_salary
FROM employees
WHERE employee_id = 100;
-- 调用Oracle内置包DBMS_OUTPUT的PUT_LINE过程,输出文本到控制台
DBMS_OUTPUT.PUT_LINE('Employee: ' || v_employee_name);
DBMS_OUTPUT.PUT_LINE('Salary: ' || v_salary);
EXCEPTION
-- 如果SELECT语句没有找到任何记录(employee_id=100不存在),会触发NO_DATA_FOUND异常
WHEN NO_DATA_FOUND THEN
DBMS_OUTPUT.PUT_LINE('Employee not found');
END;
2:变量声明
declare
--声明变量
-- 格式一:变量名 变量类型;
-- 格式二:变量名 变量类型 := 初始值;
-- 格式三:变量名 变量类型 := &文本框名;
-- 格式四:变量名 表名.字段名%type;
-- 格式五:变量名 表名%rowtype;
vnum number;
vage number := 28;
vabc number := &abc;-- 输入一个数值,从一个文本框输入
vsal emp.sal%type; -- 引用型的变量,代表emp.sal的类型
vrow emp%rowtype; -- 记录型的变量,代表emp一行的类型
begin
-- 业务逻辑
dbms_output.put_line(vnum); -- 输出一个未赋值的变量
dbms_output.put_line(vage); -- 输出一个已赋值的变量
dbms_output.put_line(vabc); -- 输出一个文本框输入的变量
select sal into vsal from emp where empno = 7654; -- 将查询到的sal内容存入vsal并输出
dbms_output.put_line(vsal);
select * into vrow from emp where empno = 7654; -- 将查询到的一行内容存入vrow并输出
dbms_output.put_line(vrow.sal);
dbms_output.put_line(123); -- 输出一个整数
dbms_output.put_line(123.456); -- 输出一个小数
dbms_output.put_line('Hello,World'); -- 输出一个字符串
dbms_output.put_line('Hello'||',World'); -- 输出一个拼接的字符串,||拼接符Oracle特有
dbms_output.put_line(concat('Hello',',World')); -- 输出一个拼接的字符串,concat函数比较通用
end;
3:流程控制
if - then - elseif - else
IF condition THEN
statements;
ELSEIF condition THEN
statements;
ELSE
statements;
END IF; -- 声明当前的if结束
-- 例如
declare
age number := &age; -- 输入一个数值,从一个文本框输入
begin
if age < 18 then
dbms_output.put_line('小屁孩');
elsif age >= 18 and age <= 24 then
dbms_output.put_line('年轻人');
elsif age > 24 and age < 40 then
dbms_output.put_line('老司机');
else
dbms_output.put_line('老年人');
end if;
end;
case - when - then - else
CASE selector
WHEN value1 THEN statements1;
WHEN value2 THEN statements2;
...
ELSE else_statements;
END CASE;
loop & while - loop & for - loop
-- loop
LOOP
statements;
EXIT WHEN condition;
END LOOP;
-- while - loop
WHILE condition LOOP
statements;
END LOOP;
-- for - loop
FOR counter IN [REVERSE] lower_bound..upper_bound LOOP
statements;
END LOOP;
-- 输出1~10
declare
begin
for i in reverse 1 .. 10 loop
dbms_output.put_line(i);
end loop;
end;
-- 输出1~10
declare
i number := 1;
begin
loop
exit when i > 10;
dbms_output.put_line(i);
i := i + 1;
end loop;
end;
4:游标
游标是用来操作查询结果集,相当于是JDBC中ResultSet,它可以对查询的结果一行一行的获取
-- 第一步:定义游标
-- 第一种:普通游标
cursor 游标名[(参数 参数类型)] is 查询语句;
-- 第二种:系统引用游标
游标名 sys_refcursor;
-- 第二步:打开游标
-- 第一种:普通游标
open 游标名[(参数 参数类型)];
-- 第二种:系统引用游标
open 游标名 for 查询语句;
-- 第三步:获取一行
fetch 游标名 into 变量;
-- 第四步:关闭游标
close 游标名;
-- 最简单的例子
-- 输出员工表中所有的员工姓名和工资
declare
cursor vrows is select * from emp;
begin
-- 自动定义变量vrow,自动打开游标,自动关闭游标
for vrow in vrows loop
dbms_output.put_line('姓名:' || vrow.ename || ' 工资: ' || vrow.sal || '工作:' || vrow.job);
end loop;
end;
举一个例子:
DECLARE
-- 定义一个名为emp_cursor的游标,目标是is后面跟的语句
CURSOR emp_cursor IS
SELECT employee_id, last_name FROM employees
WHERE department_id = 10;
-- 声明变量 v_emp_id, 其数据类型与 employees 表中的 employee_id 列完全相同
-- v_emp_name同理
v_emp_id employees.employee_id%TYPE;
v_emp_name employees.last_name%TYPE;
BEGIN
-- 打开指定名称的游标
OPEN emp_cursor;
-- 逐行打印
LOOP
FETCH emp_cursor INTO v_emp_id, v_emp_name;
-- 到最后一行退出
EXIT WHEN emp_cursor%NOTFOUND;
DBMS_OUTPUT.PUT_LINE(v_emp_id || ': ' || v_emp_name);
END LOOP;
-- 关闭游标
CLOSE emp_cursor;
END;
5:存储过程
存储过程实际上是封装在服务器上一段PLSQL代码片断,它已经编译好了,如果客户端调用存储过程,执行效率就会非常高效
-- 下面是调用方式
-- 方式一:
call 存储过程名称(...);
-- 方式二:
declare
begin
存储过程名称(...);
end;
创建存储过程
create procedure 存储过程名称(参数名 in|out 参数类型,参数名 in|out 参数类型,...)
is|as
--声明部分
begin
--业务逻辑
end;
-- 示例
-- 给指定员工涨薪并打印涨薪前和涨薪后的工资
create procedure proc_update_sal(vempno in number,vnum in number)
is
-- 声明变量
vsal number;
begin
-- 查询当前的工资
select sal into vsal from emp where empno = vempno;
-- 输出涨薪前的工资
dbms_output.put_line('涨薪前:' || vsal);
-- 更新工资
update emp set sal = vsal + vnum where empno = vempno;
-- 输出涨薪后的工资
dbms_output.put_line('涨薪后:' || (vsal + vnum));
-- 提交事物
commit;
end;
-- 给员工编号为7521的员工涨工资10元
call proc_update_sal(7521, 10);
修改存储过程
create [or replace] procedure 存储过程名称(参数名 in|out 参数类型,参数名 in|out 参数类型,...)
is|as
-- 声明部分
begin
-- 业务逻辑
end;
-- 给指定员工涨薪并打印涨薪前和涨薪后的工资
create or replace procedure proc_update_sal(vempno in number,vnum in number)
is
-- 声明变量
vsal number;
begin
-- 查询当前的工资
select sal into vsal from emp where empno = vempno;
-- 输出涨薪前的工资
dbms_output.put_line('涨薪前:' || vsal);
-- 更新工资
update emp set sal = vsal + vnum where empno = vempno;
-- 输出涨薪后的工资
dbms_output.put_line('涨薪后:' || (vsal + vnum));
-- 提交事物
commit;
end;
-- 给员工编号为7521的员工涨工资10元
call proc_update_sal(7521, 10);
删除存储过程
drop procedure 存储过程名称;
6:函数
函数实际上是封装在服务器上一段PLSQL代码片断,它已经编译好了,如果客户端调用存储过程,执行效率就会非常高效,它跟存储过程没有什么本质区别,存储过程能做的函数也能做,只不过函数有返回值
-- 下面是调用方式
-- 方式一:
select 函数名称(...) from dual;
-- 方式二:
declare
变量名 变量类型;
begin
变量名 = 函数名称(...);
end;
创建函数
create function 函数名称(参数名 in|out 参数类型,参数名 in|out 参数类型,...) return 返回的参数类型
is|as
--声明部分
begin
--业务逻辑
end;
-- 举一个例子
-- 查询指定员工的年薪
/*
参数 : 员工的编号
返回 : 员工的年薪
*/
create function func_getsal(vempno number) return number
is
vtotalsal number;
begin
select sal * 12 + nvl(comm, 0) into vtotalsal from emp where empno = vempno;
return vtotalsal;
end;
-- 查询员工编号为7788的年薪
declare
vsal number;
begin
vsal := func_getsal(7788);
dbms_output.put_line(vsal);
end;
删除函数
drop function [func_name]
7:触发器
当用户执行了 insert | update | delete 这些操作之后,可以触发一系列其它的动作、业务逻辑,使用触发器可以协助应用在数据库端确保数据的完整性、日志记录 、数据校验等操作。
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。
现在Oracle触发器不仅支持行级触发,还支持语句级触发
| 触发器类型 | NEW 和 OLD的使用 |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据 |
| UPDATE 型触发器 | OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的数据 |
创建触发器
create trigger [触发器名称]
before|after -- 在指定的操作类型之前触发还是之后触发
insert|update|delete -- 指定的操作类型
on [表名称] -- 作用的表
[for each row] -- 行级触发器, 对于被操作的每一行
declare
-- 声明部分
begin
-- 业务逻辑
end;
-- 新员工入职之后,输出一句话: 欢迎加入我们
create or replace trigger tri_emp_insert
after
insert -- 在insert之后触发
on emp
declare
begin
dbms_output.put_line('欢迎加入我们'); -- 在insert之后将会触发这句话
end;
-- 插入数据就可以自动触发触发器
insert into emp(empno, ename) values(9527, '马哈哈');
更新型触发器
create [or replace] trigger [触发器名称]
before|after
insert|update|delete
on [表名称]
[for each row] -- 行级触发器
declare
-- 声明部分
begin
-- 业务逻辑
end;
-- 判断员工涨工资后的工资一定要大于涨工资前的工资
create or replace trigger tri_emp_update_sal
before
update
on emp
for each row
declare
begin
-- 如果旧的工资 > 新的工资,将会触发error
if :old.sal > :new.sal then
raise_application_error(-20002,'旧的工资不能大于新的工资');
end if;
end;
-- 更新数据就可以自动触发触发器(无异常)
update emp set sal = sal + 10;
select * from emp;
-- 更新数据就可以自动触发触发器(有异常)
update emp set sal = sal - 100;
select * from emp;
删除触发器
drop trigger tri_emp_insert;
drop trigger tri_emp_update_sal;
drop trigger tri_emp_delete;
三:Oracle索引
索引是与表关联的可选结构,用于加快数据的检索速度。你可以想象成是一本书的目录,通过存储排序的键值和ROWID来快速定位数据
- 索引是独立于表的数据库对象
- 索引由Oracle自动维护和使用
- 索引对用户透明,SQL语句无需修改即可利用索引
Oracle索引分类
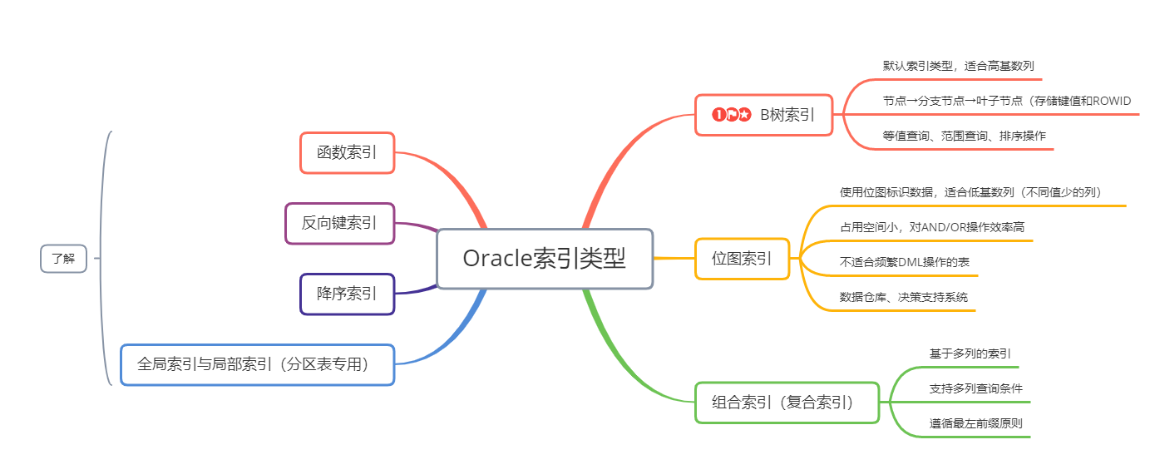
1:索引操作
1.1:创建索引
-- 基本语法
CREATE [UNIQUE] INDEX index_name
ON table_name (column1 [ASC|DESC], column2, ...)
-- 下面这些选项都不咋用
[TABLESPACE tablespace_name]
[STORAGE (storage_parameters)]
[COMPUTE STATISTICS]
[其他选项];
-- 示例 create index index_name on table_name(col1 [asc|desc], col2...)
CREATE INDEX emp_deptno_idx ON emp(deptno);
CREATE BITMAP INDEX emp_gender_idx ON emp(gender);
1.2:修改索引
-- 重建索引
ALTER INDEX index_name REBUILD;
-- 合并索引碎片
ALTER INDEX index_name COALESCE;
-- 重命名索引
ALTER INDEX old_name RENAME TO new_name;
1.3:删除索引
DROP INDEX index_name;
1.4:监控索引使用
-- 开启监控
ALTER INDEX index_name MONITORING USAGE;
-- 查看使用情况
SELECT * FROM v$object_usage WHERE index_name = 'INDEX_NAME';
2:索引相关数据字典视图
| 视图名称 | 描述 |
|---|---|
USER_INDEXES | 用户拥有的索引信息 |
USER_IND_COLUMNS | 索引列信息 |
USER_IND_EXPRESSIONS | 函数索引的表达式 |
USER_PART_INDEXES | 分区索引信息 |
V$OBJECT_USAGE | 索引使用监控信息 |
3:索引优化策略
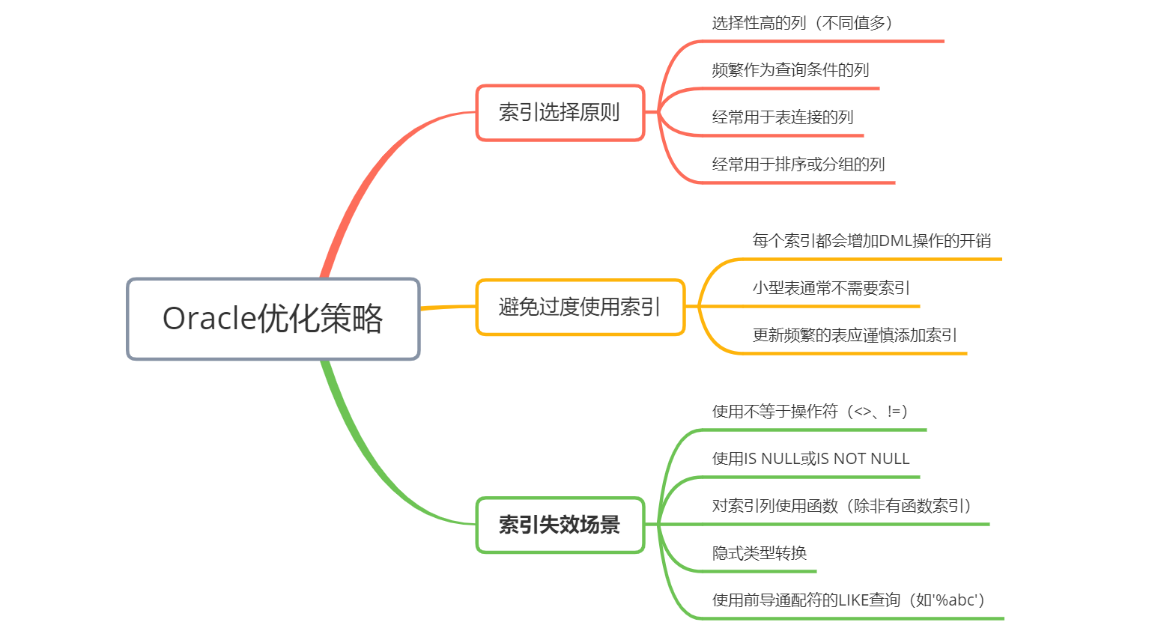
4:索引维护
4.1:定期分析索引统计信息
ANALYZE INDEX index_name COMPUTE STATISTICS;
-- 或
EXEC DBMS_STATS.GATHER_INDEX_STATS('SCHEMA','INDEX_NAME');
4.2:监控索引碎片
-- 检查索引高度(理想情况下应为2-3)
SELECT index_name, blevel+1 AS height FROM user_indexes;
-- 检查聚簇因子(接近表块数表示良好)
SELECT index_name, clustering_factor FROM user_indexes;
4.3:考虑使用不可见索引测试
Oracle11g +
-- 创建不可见索引
CREATE INDEX idx_name ON table_name(column_name) INVISIBLE;
-- 修改索引可见性
ALTER INDEX idx_name VISIBLE|INVISIBLE;
四:Oracle视图
视图是Oracle数据库中非常重要的数据库对象,它提供了一种灵活、安全的数据访问方式
视图是基于一个或多个表的逻辑表;视图不直接存储数据,只是一个存储的查询定义;视图也被称为"虚拟表"
视图具有如下的特点:
- 简化复杂查询
- 提供数据安全性(隐藏敏感数据)
- 保证数据独立性(表结构变化不影响应用)
- 可以像表一样被查询
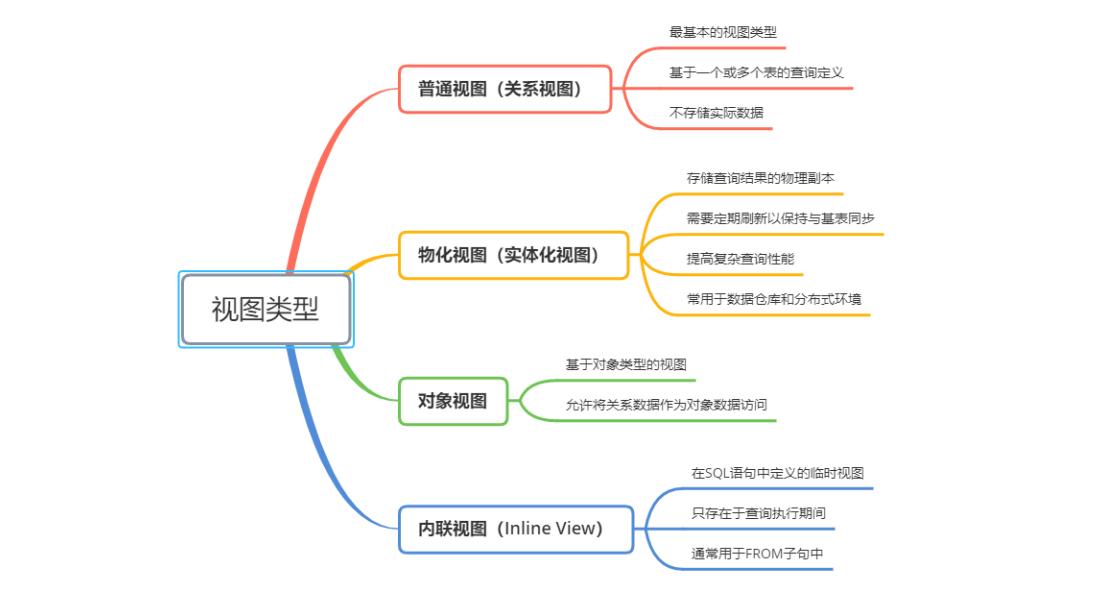
1:视图创建与管理
1.1:创建视图
create [or replace] [force | noforce] view [schema.]view_name
[(col1, col2)]
as subquery
[with check option [constraint constraint_name]]
[with read only [constraint constraint_name]];
-- 简单的示例
create view emp_view -- 创建一个名为emp_view的视图
as -- 下面声明视图的数据来源 - subquery
select e.empno, e.ename, d.dname, d.loc
from emp e, dept d
where e.deptno = d.deptno;
-- 带列别名的视图
CREATE VIEW emp_sal_view (employee_id, name, annual_salary) AS
SELECT empno, ename, sal*12 FROM emp;
-- 带检查选项的视图
CREATE VIEW high_sal_emp AS
SELECT * FROM emp WHERE sal > 2000
WITH CHECK OPTION CONSTRAINT high_sal_check;
-- 只读视图
CREATE VIEW dept_summary AS
SELECT d.dname, COUNT(e.empno) emp_count
FROM dept d LEFT JOIN emp e ON d.deptno = e.deptno
GROUP BY d.dname
WITH READ ONLY;
1.2:修改视图
-- 使用OR REPLACE重建视图
CREATE OR REPLACE VIEW emp_dept_view AS
SELECT e.empno, e.ename, e.sal, d.dname, d.loc
FROM emp e, dept d
WHERE e.deptno = d.deptno;
-- 添加约束
ALTER VIEW view_name ADD CONSTRAINT constraint_name PRIMARY KEY (col1) DISABLE;
1.3:删除视图
DROP VIEW [schema.]view_name [CASCADE CONSTRAINTS];
1.4:查看视图的定义
SELECT text FROM user_views WHERE view_name = 'VIEW_NAME';
2:视图相关的数据字典
| 视图名称 | 描述 |
|---|---|
USER_VIEWS | 用户拥有的视图定义 |
USER_MVIEWS | 用户拥有的物化视图信息 |
USER_MVIEW_REFRESH_TIMES | 物化视图刷新时间 |
USER_MVIEW_LOGS | 物化视图日志信息 |
USER_UPDATEABLE_COLUMNS | 可更新视图列信息 |
3:视图注意事项
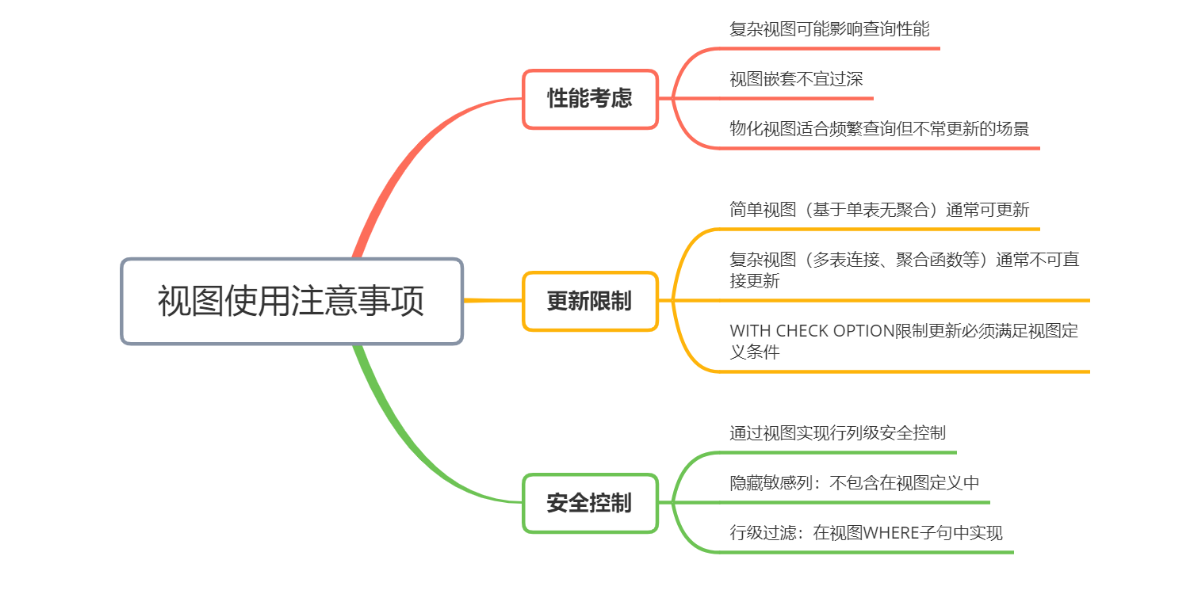
4:物化视图
4.1:创建物化视图
CREATE MATERIALIZED VIEW mv_name
[REFRESH [FAST|COMPLETE|FORCE]
[ON DEMAND|COMMIT]
[START WITH date] [NEXT date]
[WITH PRIMARY KEY|ROWID]]
[ENABLE|DISABLE QUERY REWRITE]
AS subquery;
-- 示例
CREATE MATERIALIZED VIEW emp_sum_mv
REFRESH COMPLETE ON DEMAND
ENABLE QUERY REWRITE
AS
SELECT deptno, COUNT(*) emp_count, AVG(sal) avg_sal
FROM emp
GROUP BY deptno;
4.2:物化视图刷新方式
COMPLETE:完全刷新,重新执行定义查询FAST:增量刷新,只更新变化部分(需要物化视图日志)FORCE:默认尝试FAST刷新,失败则COMPLETE刷新ON COMMIT:基表提交时自动刷新ON DEMAND:手动刷新
4.3:手动刷新物化视图
-- 完全刷新
EXEC DBMS_MVIEW.REFRESH('mv_name', 'C');
-- 快速刷新
EXEC DBMS_MVIEW.REFRESH('mv_name', 'F');
-- 刷新多个物化视图
EXEC DBMS_MVIEW.REFRESH_LIST('mv1,mv2,mv3');
五:Oracle同义词
同义词(Synonym)是Oracle数据库中的一个重要对象,它为数据库对象提供了别名功能,可以简化SQL语句并提高安全性。
同义词是数据库对象的别名,它指向表、视图、序列、存储过程、函数、包或其他同义词
同义词不存储实际数据,只是一个指向其他对象的引用
同义词可以简化复杂对象名的引用,隐藏底层对象的真实名称和位置,提供位置透明性(分布式环境中特别有用)
同义词不占用实际存储空间,依赖其所指向的对象存在,并且同义词可以公开或私有
同义词分成:
- 私有同义词(属于特定用户, 只能在创建者的schema中使用, 命名不需要唯一)
- 公有同义词(不属于任何特定用户, 所有用户都可以访问, 名称在数据库范围内必须唯一)
1:同义词创建与管理
1.1:创建同义词
-- 基本语法
CREATE [OR REPLACE] [PUBLIC] SYNONYM [schema.]synonym_name
FOR [schema.]object_name[@dblink];
-- 创建私有同义词示例
CREATE SYNONYM emp_syn FOR hr.employees;
-- 创建公有同义词示例
CREATE PUBLIC SYNONYM dept_syn FOR hr.departments;
-- 为远程对象创建同义词
CREATE SYNONYM remote_emp FOR emp@remote_db;
-- 替换现有同义词
CREATE OR REPLACE SYNONYM emp_syn FOR hr.emp_new;
1.2:使用同义词
-- 查询同义词指向的表
SELECT * FROM emp_syn;
-- 在存储过程中使用同义词
CREATE OR REPLACE PROCEDURE update_emp AS
BEGIN
UPDATE emp_syn SET sal = sal * 1.1 WHERE deptno = 10;
END;
1.3:删除同义词
-- 删除私有同义词
DROP SYNONYM emp_syn;
-- 删除公有同义词
DROP PUBLIC SYNONYM dept_syn;
1.4:查看同义词信息
-- 查看用户拥有的同义词
SELECT * FROM USER_SYNONYMS;
-- 查看所有公有同义词
SELECT * FROM ALL_SYNONYMS WHERE OWNER = 'PUBLIC';
-- 查看同义词定义
SELECT TABLE_NAME, TABLE_OWNER, DB_LINK
FROM ALL_SYNONYMS
WHERE SYNONYM_NAME = 'SYNONYM_NAME';
2:同义词使用场景
简化复杂对象名:
-- 原查询
SELECT * FROM hr.employee_details_view@prod_db;
-- 使用同义词后
SELECT * FROM emp_details;
多环境适配:
- 开发、测试、生产环境使用相同SQL
- 通过同义词指向不同环境的实际对象
对象重命名过渡:
- 旧表名和新表名共存期间
- 创建同义词指向新表,逐步迁移应用
权限管理:
- 通过同义词控制对底层对象的访问
- 不直接授予基表权限,只授予同义词权限
3:同义词注意事项
权限要求:
- 创建私有同义词需要CREATE SYNONYM权限
- 创建公有同义词需要CREATE PUBLIC SYNONYM权限
- 使用同义词需要对其指向的对象有相应权限
依赖关系:
- 同义词依赖于其指向的对象
- 当基对象被删除或重命名时,同义词会变为无效
- 可以使用
SELECT * FROM ALL_DEPENDENCIES查看依赖关系
命名冲突:
- 私有同义词优先于公有同义词
- 当存在同名私有和公有同义词时,使用私有同义词
性能影响:
- 同义词解析会增加少量开销
- 在极高性能要求的场景中考虑直接使用对象名
4:同义词最佳实践
命名规范:使用一致的命名约定(如_syn后缀)& 避免与现有对象名冲突
文档化:记录同义词与其指向对象的关系
COMMENT ON SYNONYM emp_syn IS '指向hr.employees表的同义词,创建于2023-01-01';
维护策略:定期检查无效同义词 & 重建无效同义词
SELECT * FROM ALL_OBJECTS WHERE STATUS = 'INVALID' AND OBJECT_TYPE = 'SYNONYM';
CREATE OR REPLACE SYNONYM ...;
迁移方案:对象迁移时先创建同义词 & 逐步更新应用使用新对象名 & 最后删除旧对象和过渡同义词
5:同义词相关数据字典
| 视图名称 | 描述 |
|---|---|
| USER_SYNONYMS | 用户拥有的同义词 |
| ALL_SYNONYMS | 用户可访问的所有同义词 |
| DBA_SYNONYMS | 数据库中所有同义词(DBA视图) |
| USER_OBJECTS | 包含同义词的对象信息 |
| ALL_DEPENDENCIES | 同义词的依赖关系 |
同义词是Oracle数据库管理中的实用功能,合理使用可以显着提高SQL的可读性和可维护性,同时增强数据库的安全性和灵活性。在设计数据库架构时,应考虑将同义词作为整体命名策略的一部分。
六:数据的备份和恢复
1:全部导出、导入
# 注意:以下操作为cmd命令行操作
exp 管理员帐号/密码 file='d:\beifen.dmp' full=y
imp 管理员帐号/密码 file='d:\beifen.dmp' full=y
2:按照用户导出、导入
exp 管理员帐号/密码 file='d:\beifen.dmp' owner=帐号
imp 管理员帐号/密码 file='d:\beifen.dmp' fromuser=帐号

















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









