




zookeeper集群的搭建
文章目录
一:先说点其他的
1:为什么我们需要zookeeper集群
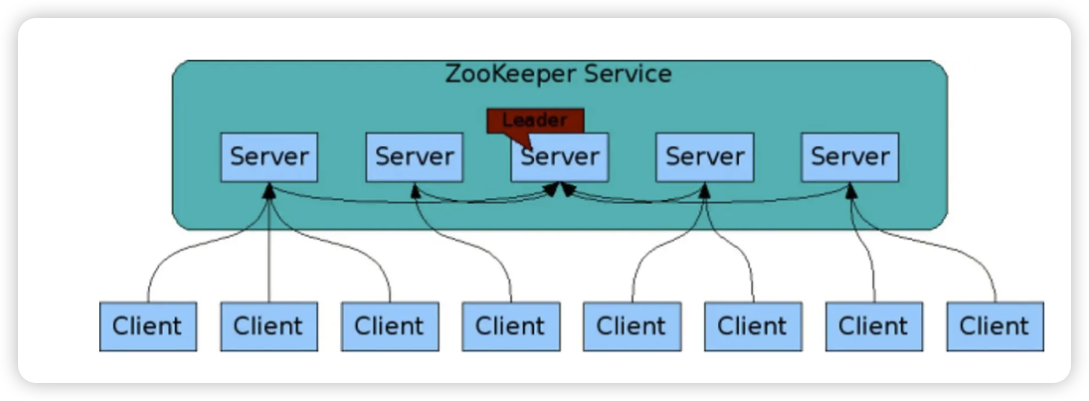
刚刚我们所提到的,zookeeper的可复制性就是zookeeper集群的特点,为了提供可靠的zookeeper服务,我们需要集群的支持,这个集群还有个特点,就是这个集群中只要有大多数的节点准备好了,就可以使用这项服务。
容错集群设置至少需要3台服务器,强烈建议使用奇数个服务器(为啥推荐奇数看到后面就知道啦),然后建议每个服务都运行在单独的机器上。
2:为什么要配置奇数个节点
如果不这样限制,在集群出现脑裂的时候,可能会出现多个子集群同时服务的情况(即子集群各组选举出自己的 leader )这样对整个 zookeeper 集群来说是紊乱的。
换句话说,如果遵守上述规则进行选举,即使出现脑裂,集群最多也只能回出现一个子集群可以提供服务的情况( 能满足节点数量> 总结点数量/2 的子集群最多只会有一个)。所以要限制 可用节点数量 > 集群总结点数量/2
同时在容错的基础上,奇数节点更能够节约资源。
二:zookeeper集群的搭建
1:规划配置和环境准备
| 主机 | 配置文件路径 | 端口 |
|---|---|---|
| 172.26.235.140 | /opt/zookeeper2181 | 2181 |
| 172.26.235.140 | /opt/zookeeper2182 | 2182 |
| 172.26.235.140 | /opt/zookeeper2183 | 2183 |
配置jdk,因为zk需要java环境
1️⃣ 解压JDK的包
tar -zxvf jdk-8u161-linux-x64.tar.gz
2️⃣ 设置环境变量 -> 修改 /etc/profile 文件
# 在文件最后添加如下内容
JAVA_HOME=/opt/jdk1.8
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
安装zk
1️⃣ 解压ZK包
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz -C /opt
# 解压完成查看常用目录结构
bin 用来存放脚本
conf 用来存放配置文件
2️⃣ 修改配置文件,创建zoo.cfg
进入 conf 文件中可以看到并没有 zoo.cfg 文件,但是有一个 zoo_sample.cfg 的模板文件
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
# zookeeper 时间配置中的基本单位(毫秒)
tickTime=2000
# 允许 follower 初始化连接到 leader 最大时长(秒),他表示 tickTime 时间倍数,即:initLimit*tickTime
initLimit=10
# 允许 follower 与 leader 数据同步最大时长(秒),他表示 tickTime 时间倍数
syncLimit=5
# zookeeper 数据存储目录及日志保存目录(如没有指明 dataLogDir,则日志也保存到这个文件中)
dataDir=/tmp/zookeeper
# 对客户端提供的端口
clientPort=2181
# 单个客户端与 zookeeper 最大并发连接数
maxClientCnxns=60
# 保存的数据快照数量,之外的会被清除
autopurge.snapRetainCount=3
# 自动触发清除任务的时间间隔,小时为单位,默认为0,表示不清除
autopurge.purgeInterval=1
2:集群配置
单机环境下,jdk、zookeeper 安装完毕,基于一台虚拟机,进行 zookeeper 伪集群搭建,zookeeper 集群中包含3个节点,节点对外提供服务端口号分别为 2181,2182,2183
基于 apache-zookeeper-3.8.0-bin 复制三分 zookeeper 安装好的服务器文件,目录名称分别为 zookeeper2181、zookeeper2182、zookeeper2183
mv /opt/apache-zookeeper-3.8.0-bin /opt/zookeeper2181
cp -r /opt/zookeeper2181 /opt/zookeeper2182
cp -r /opt/zookeeper2181 /opt/zookeeper2183
修改三个配置文件(重要,注意下面的注释) -> 修改 /opt/zookeeper218*/conf 配置文件
# zookeeper 数据存储目录及日志保存目录(如没有指明 dataLogDir,则日志也保存到这个文件中)
dataDir=/opt/zookeeper2181
# 对客户端提供的端口
clientPort=2181
# 集群配置信息
# server.A=B:C:D
# A:是一个数字,表示这个是服务器的编号
# B:是这个服务器的ip地址
# C:Zookeeper服务器之间的通信端口号
# D:Leader选举的端口
# 注:因为这里是伪集群(IP 地址是相同的),所以 C 和 D 是不同的,如果是不同的服务器,这里一般是相同的,示例:
# server.1=172.26.235.140:2288:3388
# server.2=172.26.235.141:2288:3388
# server.3=172.26.235.142:2288:3388
server.1=172.26.235.140:2287:3387
server.2=172.26.235.140:2288:3388
server.3=172.26.235.140:2289:3389
创建配置文件 myid -> 在上一步dataDir指定的目录下,创建myid文件,然后在该文件添加上一步server配置对应A数字。
# zookeeper2181对应的数字为1
echo "1" > /opt/zookeeper2181
# zookeeper2182对应的数字为2
echo "2" > /opt/zookeeper2182
# zookeeper2183对应的数字为3
echo "3" > /opt/zookeeper2183
最后启动zk即可
cd /opt/zookeeper2181/bin
./zkServer.sh start
# 或者可以这样
./zkServer.sh start ../conf/zoo.cfg
# 其他两台同样的启动方式
三:集群的工作原理
zookeeper提供了重要的分布式协调服务,它是如何保证集群数据的一致性的
1:ZAB协议的简单描述
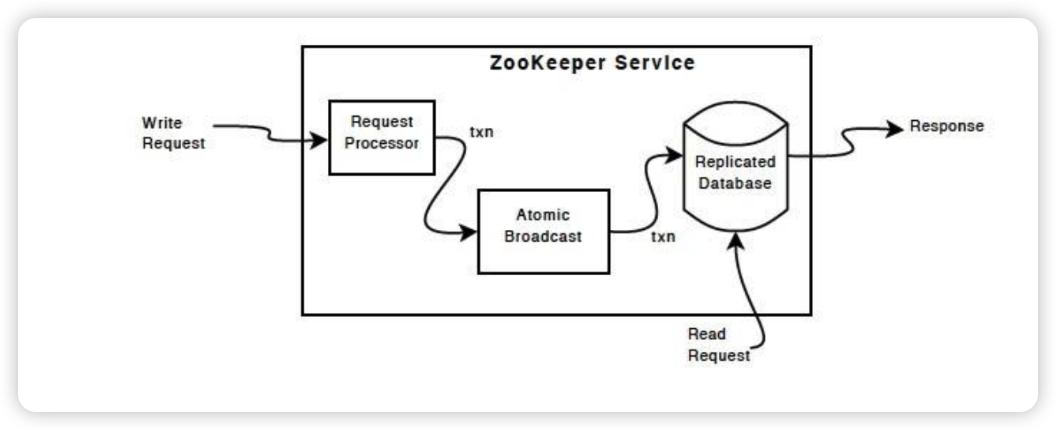
ZAB(zookeeper atomic broadcast)
zookeeper 原子消息广播协议是专门为zookeeper设计的数据一致性协议
注意此协议最主要的关注点在于数据一致性,而无关乎于数据的准确性,权威性,实时性
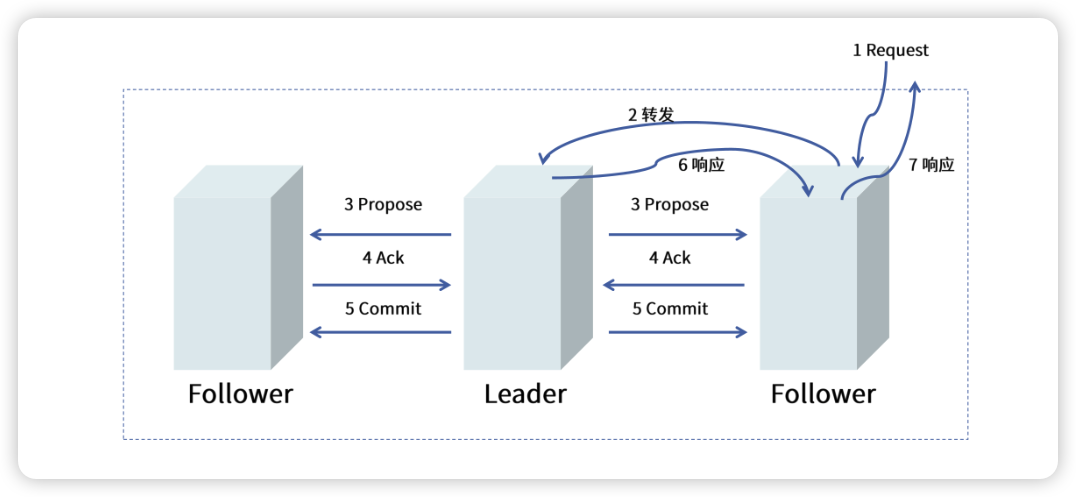
- 所有事务转发给leader(当我们的follower接收到事务请求)
- Leader分配全局单调递增事务id(zxid,也就是类似于paxos算法的编号n),广播协议提议
- Follower处理提议,作出反馈(也就是承诺只接受比现在的n编号大的
- leader收到过半数的反馈,广播commit,把数据彻底持久化(和2pc不同的是,2pc是要等待所有小弟反馈同意)
- leader对原来转发事务的followe进行响应,follower也顺带把响应返回给客户端
还记得我们说过zookeeper比较适合读比较多,写比较少的场景吗,为什么我们说它效率高,我们可以知道,所有的事务请求,必须由一个全局唯一的服务器进行协调,这个服务器也就是现在的leader,leader服务器把客户端的一个写请求事务变成一个提议,这个提议通过我们的原子广播协议广播到我们服务器的其他节点上去,此时这个协议的编号,也就是zxid肯定是最大的
由于我们的zxid都是由leader管理的,在上一节也是讲过,leader之所以能成为leader,本来就是因为它的zxid最大,此时的事务请求过来,leader的zxid本身最大的基础上再递增,这样新过来的事务的zxid肯定就是最大的。那么一连串的事务又是如何在leader中进行处理,leader中会内置一个队列,队列的作用就是用来保证有序性(zxid有序且队列先进先出原则),所以后面来的事务不可能跳过前面来的事务。所以这也是ZAB协议的一个重要特性—有序性
2:Leader崩溃时的举措
leader服务器崩溃,或者说由于网络原因导致leader失去了与过半follower的联系,那么就会进入崩溃恢复模式
回到上一节配置集群节点配置时,提到了在配置各节点时
server.id = host:port:port
这里面第二个port就是崩溃恢复模式要使用到的:
- ZAB协议规定如果一个proposal在一台机器上被处理成功,那么他应该在所有的机器上处理成功,哪怕这台机器已经崩溃或者出现故障
- ZAB协议确保哪些已经在Leader服务器上提交的事务最终被所有的服务器提交
- ZAB协议确保丢失的哪些只在leader上被提出的事务
所以此时我们ZAB协议的选举算法应该满足:确保提交已经被leader提交的事务proposal,同时丢弃已经被跳过的事务proposal
如果让leader选举算法能够保证新选举出来的leader拥有集群中所有机器的最高zxid的事务proposal,那么就可以保证这个新选举出来的leader一定具有所有已经提交的提案
同时如果让拥有最高编号的事务proposal的机器来成为leader,就可以省去leader检查事务proposal的提交和丢弃事务proposal的操作
3:ZAB协议的数据同步
leader选举完成后,需要进行follower和leader的数据同步,当半数的follower完成同步,则可以开始提供服务。同步过程如下:
Leader服务器会为每一个follower准备一个队列,并将那些没有被各个follower服务器同步的事务以proposal的方式逐个发送给follower服务器,并在每一个proposal后面接着发送一个commit消息。表示这个事务已经进行提交,知道follower服务器将所有的尚未同步的proposal都从leader上同步,并成功的提交到本地的数据库中,leader就会将这个follower加入到可用的follower中
4:ZAB协议中丢弃事务proposal
zxid = 高32位 + 低32位 = leader周期编号 + 事务proposal编号
事务编号zxid是一个64位的数字,低32位是一个简单的单调递增的计数器,针对客户端的每一个事务请求,leader产生新的事务proposal的时候都会对该计数器进行+1的操作,高32位代表了leader周期纪元的编号。
每当选举产生一个新的leader,都会从这个leader服务器上取出其本地日志中最大事务proposal的zxid,并从zxid解析出对应的纪元值,然后对其进行+1操作,之后以此编号作为新的纪元,并将低32位重置为0开始生产新的zxid。
基于此策略,当一个包含了上一个leader周期中尚未提交过的事务proposal的服务器启动加入到集群中,发现此时集群中已经存在leader,将自身以follower角色连接上leader服务器后,leader服务器会根据自身最后被提交的proposal和这个follower的proposal进行比对,发现这个follower中有上一个leader周期的事务proposal后,leader会要求follower进行一个回退操作,回到一个确实被集群过半机器提交的最新的事务proposal
下面是ZAB的动画演示

















 1490
1490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









