




分布式集群
文章目录
一:集群引入:单点故障问题
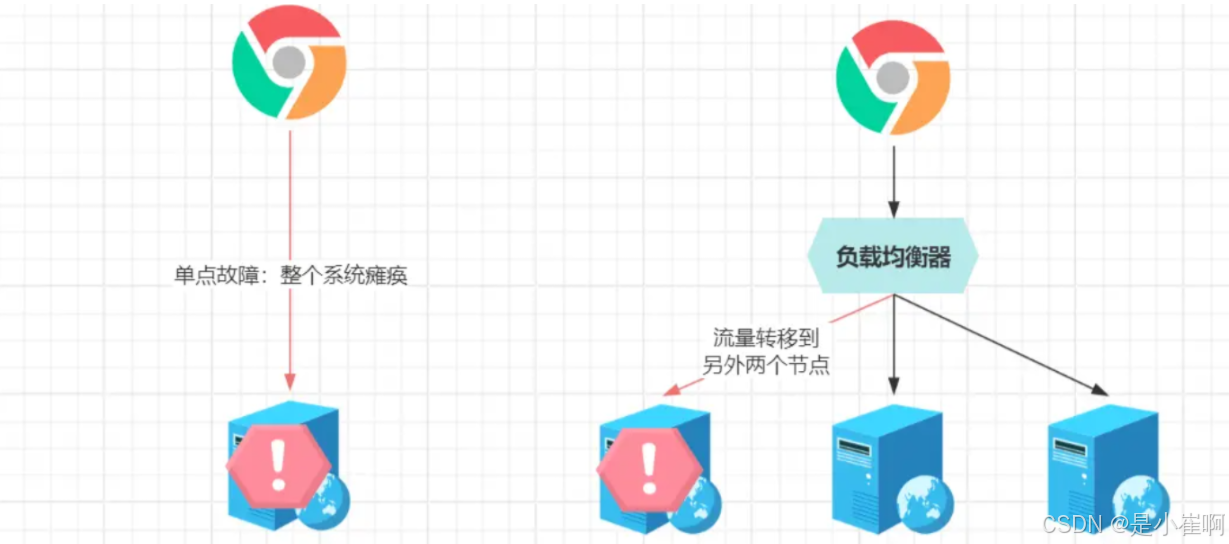
单点故障是建立高可用系统的第一道坎,而集群恰恰是解决单点故障最有效的手段,就算系统内一个节点出现故障,依旧有其他健康的节点能处理请求,保障系统正常运行,实现99.999……%高可用。
很多人对集群的认知,都源自于Nginx,因为当程序性能跟不上业务需求、又不想对服务器升配时,就可以使用Nginx来加机器
使用多台“价格优美”的低配机器,为服务做集群化部署,从而提升系统整体的吞吐量。
二:集群的定义与分类
1:集群的定义
集群,即是指:通过多台物理机器,组成一台逻辑上的庞大机器使用,集群带来的优势有四:
- 高可用:集群内某个节点故障,可迅速将流量迁移至其他节点,解决了单点故障;
- 吞吐量:多台机器并行处理外部请求,可以为系统带来更强大的负载与吞吐能力;
- 拓展性:可根据业务的增长/萎靡,动态伸缩集群内的节点数量,系统更加灵活;
- 性价比:无需花费更高的价格升配机器,可使用多台价格、配置较低的机器构建。
集群带来的好处很多,即解决了单点故障,又兼顾了吞吐与性能、动态伸缩、性价比
同时对客户端是无感知的,客户端在请求时,无法分辨出究竟采用了多少台机器来部署服务。
2:集群的分类
其实集群可粗略分为两大类,逻辑处理集群、数据存储集群,前者对应着业务系统,后者对应着数据存储组件,举些例子说明:
- 逻辑处理型集群:业务服务、
API网关、请求分发器、并行运算(科学计算)服务等; - 数据存储型集群:缓存中间件、消息中间件、数据库、搜索中间件集群、对象存储等。
简单来说,逻辑处理型的集群,只需要处理客户端请求的逻辑运算,拿业务系统来说,目前有个登录功能,系统只需根据业务流程,执行完对应的业务逻辑,接着就可给客户端响应结果。而存储型的集群,客户端一般是“程序”,如DB、Redis、MQ、ES……,生产环境里,处理的绝大多数请求,都来自于业务系统。对于客户端的请求,需要保存信息,处理写入请求需要将客户端带来的数据存好,处理读取请求则需将之前存好的数据拿出来返回。
三:逻辑处理型集群
1:逻辑处理型集群的核心
在之前的模式中,因为只有一台机器,域名可直接映射服务器的公网IP
当出现对应域名的请求,DNS可直接解析到对应的服务器IP,客户端(如浏览器)直接对拿到的IP发起请求就行。
但是当一个业务系统,使用多个节点部署组成集群时,所面临的最大问题,即是请求如何分发到具体服务器?
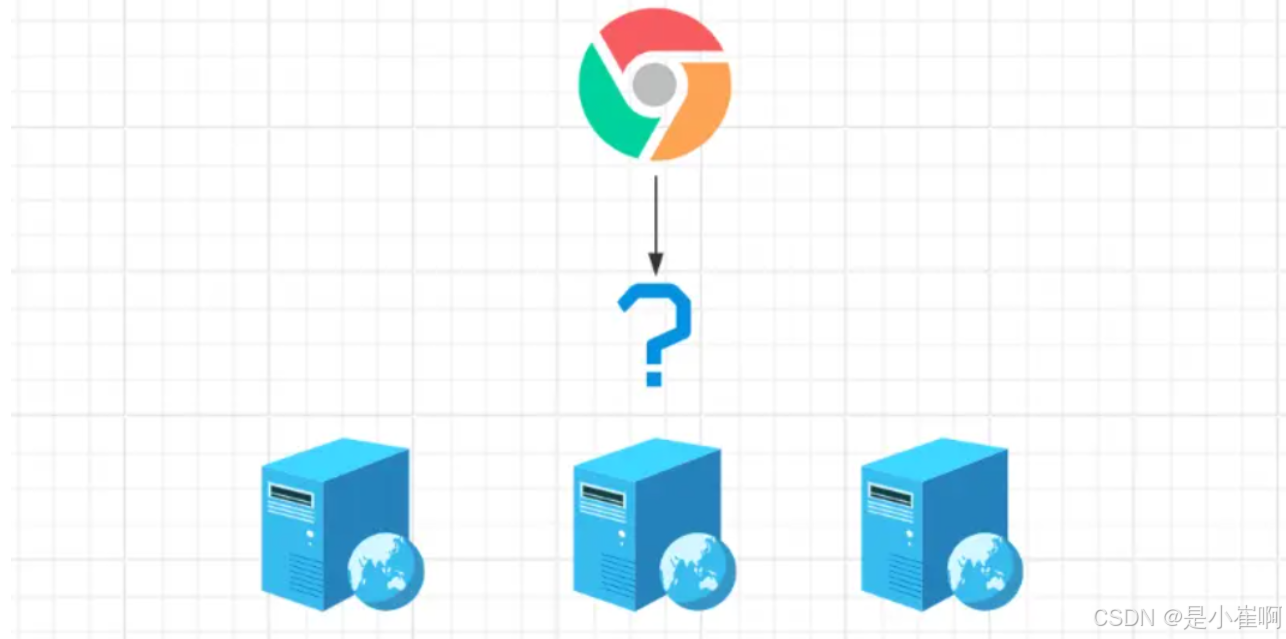
为了解决该问题,不得不引入请求分发器,域名映射请求分发器所在的IP,分发器接到客户端的请求后,再分发给具体的业务节点处理。
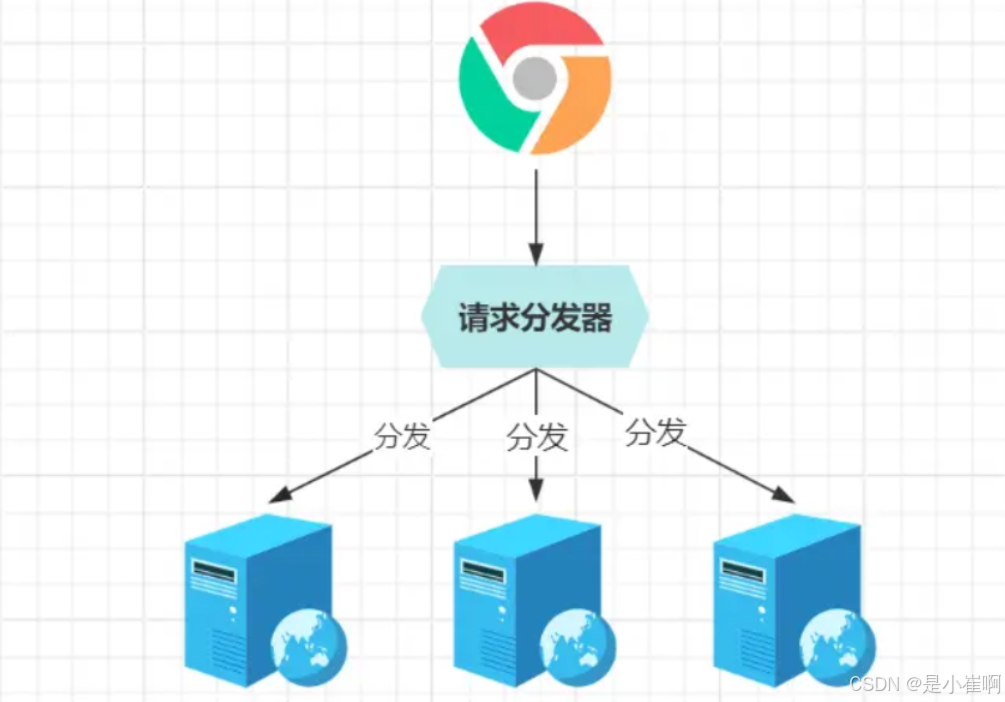
当外部请求来到分发器时,分发器可以在已配置的节点列表中选一台机器,负责处理具体的业务请求逻辑。
但这里有个问题,如何保证各节点的负载均衡呢?
随机分发貌似不太合适,咋办?选择合适的分发算法,如轮询。
所谓的轮询,则是根据配置的节点列表顺序,依次分发请求,如第一个请求给第一个节点、第二个请求给第二个节点……,当分发到最后一个节点时,再回到第一个节点,周而复始。但是轮询有一个非常重要的问题:组成集群的机器有好有差,如果一视同仁,站在那些较差的服务器来说,请求分发的不够合理
负载均衡是两个词,负载即服务器目前承担的压力,均衡代表压力一致,组合起来就是指:集群内各节点承担的压力要一致!
相同的访问量,分发到一台
2C4G服务器上,CPU利用率经常打到95%;但放到8C16G的机器上根本不是事。
综上所述,负载均衡要考虑各机器本身的性能,这时就得用到一些较为智能的分发算法,如:
- 平滑加权轮询算法:在轮询的基础上,根据机器配置,为各节点分配权重值;
- 最小活跃数算法:根据实际负载情况进行调整,自动寻找活跃度最低的节点处理请求;
- 最优响应算法:根据分发后请求的处理时间,新请求到来时,分发给响应最快的节点处理;
- ……
2:为什么分发器性能那么高
业务系统做集群,通常会选择Nginx,毕竟它除开提供负载均衡的能力外,还能做反向代理,避免了将后端服务直接暴露在公网的隐患性
可为什么这类负载均衡器,性能那么高呢?
相同的访问量,Nginx可以轻松抗住,而后端服务或许要起几个才能勉强处理,为啥?
其实道理很简单,因为这类负载均衡器,自身并不负责处理请求,只是负责做请求分发,所以用户的请求,在Nginx里逗留的时间极其短暂。
一台机器处理请求的速度越快,在相同的时间窗口里,其吞吐量更高。
除此之外,因为不需要处理业务逻辑,自然也不存在资源之类的竞争(如锁资源),
并且Nginx底层选用了IO多路复用模型,实际负责分发请求的线程数极少,也不存在多线程应用那种线程上下文频繁切换的开销……
种种因素下,为其高性能表现提供了强有力的支撑。
3:双机热备
所谓的热备机制,可以理解成集群技术的另类体现,它是一种系统冗余设计方案,即同时部署两套系统,一主一备,主系统和备用系统并行运行。
在主系统发生故障时,备用系统能迅速接管主系统的工作,维持系统正常运作,以确保服务的可用性,及业务的连续性。
可是有了Nginx这类负载均衡器,还要啥热备技术呀?
恰巧,就是Nginx这类组件需要热备技术支持,虽然业务系统通过Nginx做了集群化部署,避免单点故障造成系统不可用的风险
但Nginx就成了“咽喉要地”,因为它只有一个节点,如果部署Nginx的机器发生故障,就会导致外部流量无法分发到业务系统,造成整个系统瘫痪。
热备机制如何实现呢?可以借助keepalived、TurbolinuxTurboHA、Heartbeat这类专门保障高可用的技术栈实现,建设热备机制时要考虑几点:
- 当进程出现故障(内存溢出、进程宕机等)时,热备机制能自动重启服务;
- 当部署进程的机器出现故障(断网、停电、硬件损坏)时,备机能及时接替主机工作;
- 新主上线接管后,旧主重新启动能自动成为新主的备机,保障热备机制的可持续性;
- 出现热备机制无法处理的故障时(硬件问题、机房环境问题等),能及时通知人工介入。
做好上述四点,则代表热备机制较为完善
PS:除一主一备外,也可以选择搭建双主热备,这样能最大程度利用资源,避免备机长时间处于空闲状态。
接下来则会通过
keepalived的VIP机制,实现Nginx的高可用。VIP并不是只会员的意思,而是指Virtual IP,即虚拟IP。
keepalived在之前单体架构开发时,是一个用的较为频繁的高可用技术
比如MySQL、Redis、MQ、Proxy、Tomcat等各处都会通过keepalived提供的VIP机制,实现单节点应用的高可用。
3.1:Keepalived+重启脚本+双机热备搭建
首先创建一个对应的目录并下载keepalived到Linux中并解压:
# 创建一个目录用来存储
mkdir /soft/keepalived && cd /soft/keepalived
# 下载keepalived
wget https://www.keepalived.org/software/keepalived-2.2.4.tar.gz
# 解压
tar -zxvf keepalived-2.2.4.tar.gz
进入解压后的keepalived目录并构建安装环境,然后编译并安装:
# 进入解压后的路径
cd keepalived-2.2.4
# 构建安装环境
./configure --prefix=/soft/keepalived/
# 编译并安装
make && make install
进入安装目录的/soft/keepalived/etc/keepalived/并编辑配置文件:
cd /soft/keepalived/etc/keepalived/
# 编辑配置文件
vi keepalived.conf
编辑主机的keepalived.conf核心配置文件,如下:
global_defs {
# 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)
router_id 192.168.12.129
}
# 定时运行的脚本文件配置
vrrp_script check_nginx_pid_restart {
# 之前编写的nginx重启脚本的所在位置
script "/soft/scripts/keepalived/check_nginx_pid_restart.sh"
# 每间隔3秒执行一次
interval 3
# 如果脚本中的条件成立,重启一次则权重-20
weight -20
}
# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)
vrrp_instance VI_1 {
# 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)
state MASTER
# 绑定虚拟IP的网络接口,根据自己的机器的网卡配置
interface ens33
# 虚拟路由的ID号,主从两个节点设置必须一样
virtual_router_id 121
# 填写本机IP
mcast_src_ip 192.168.12.129
# 节点权重优先级,主节点要比从节点优先级高
priority 100
# 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题
nopreempt
# 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
# 将track_script块加入instance配置块
track_script {
# 执行Nginx监控的脚本
check_nginx_pid_restart
}
virtual_ipaddress {
# 虚拟IP(VIP),也可扩展,可配置多个。
192.168.12.111
}
}
克隆一台之前的虚拟机作为从(备)机,编辑从机的keepalived.conf文件,如下:
global_defs {
# 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)
router_id 192.168.12.130
}
# 定时运行的脚本文件配置
vrrp_script check_nginx_pid_restart {
# 之前编写的nginx重启脚本的所在位置
script "/soft/scripts/keepalived/check_nginx_pid_restart.sh"
# 每间隔3秒执行一次
interval 3
# 如果脚本中的条件成立,重启一次则权重-20
weight -20
}
# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)
vrrp_instance VI_1 {
# 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)
state BACKUP
# 绑定虚拟IP的网络接口,根据自己的机器的网卡配置
interface ens33
# 虚拟路由的ID号,主从两个节点设置必须一样
virtual_router_id 121
# 填写本机IP
mcast_src_ip 192.168.12.130
# 节点权重优先级,主节点要比从节点优先级高
priority 90
# 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题
nopreempt
# 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
# 将track_script块加入instance配置块
track_script {
# 执行Nginx监控的脚本
check_nginx_pid_restart
}
virtual_ipaddress {
# 虚拟IP(VIP),也可扩展,可配置多个。
192.168.12.111
}
}
新建scripts目录并编写Nginx的重启脚本,check_nginx_pid_restart.sh:
# 新建scripts目录
mkdir /soft/scripts /soft/scripts/keepalived
# 新建重启脚本文件
touch /soft/scripts/keepalived/check_nginx_pid_restart.sh
# 进入重启脚本文件
vi /soft/scripts/keepalived/check_nginx_pid_restart.sh
#!/bin/sh
# 通过ps指令查询后台的nginx进程数,并将其保存在变量nginx_number中
nginx_number=`ps -C nginx --no-header | wc -l`
# 判断后台是否还有Nginx进程在运行
if [ $nginx_number -eq 0 ];then
# 如果后台查询不到`Nginx`进程存在,则执行重启指令
/soft/nginx/sbin/nginx -c /soft/nginx/conf/nginx.conf
# 重启后等待1s后,再次查询后台进程数
sleep 1
# 如果重启后依旧无法查询到nginx进程
if [ `ps -C nginx --no-header | wc -l` -eq 0 ];then
# 将keepalived主机下线,将虚拟IP漂移给从机,从机上线接管Nginx服务
systemctl stop keepalived.service
fi
fi
编写的脚本文件需要更改编码格式,并赋予执行权限,否则可能执行失败:
vi /soft/scripts/keepalived/check_nginx_pid_r
:set fileformat=unix # 在vi命令里面执行,修改编码格式
:set ff # 查看修改后的编码格式restart.sh
chmod +x /soft/scripts/keepalived/check_nginx_pid_restart.sh # 赋予执行权限
由于安装keepalived时,是自定义的安装位置,因此需要拷贝一些文件到系统目录中:
mkdir /etc/keepalived/
cp /soft/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
cp /soft/keepalived/keepalived-2.2.4/keepalived/etc/init.d/keepalived /etc/init.d/
cp /soft/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
将keepalived加入系统服务并设置开启自启动,然后测试启动是否正常:
# 检查keepalived是否打开
chkconfig keepalived on
# 守护线程重新加载
systemctl daemon-reload
# 设置自启动
systemctl enable keepalived.service
# 启动
systemctl start keepalived.service
# 其他命令:
systemctl disable keepalived.service # 禁止开机自动启动
systemctl restart keepalived.service # 重启keepalived
systemctl stop keepalived.service # 停止keepalived
tail -f /var/log/messages # 查看keepalived运行时日志
最后测试一下VIP是否生效,通过查看本机是否成功挂载虚拟IP:
ip addr
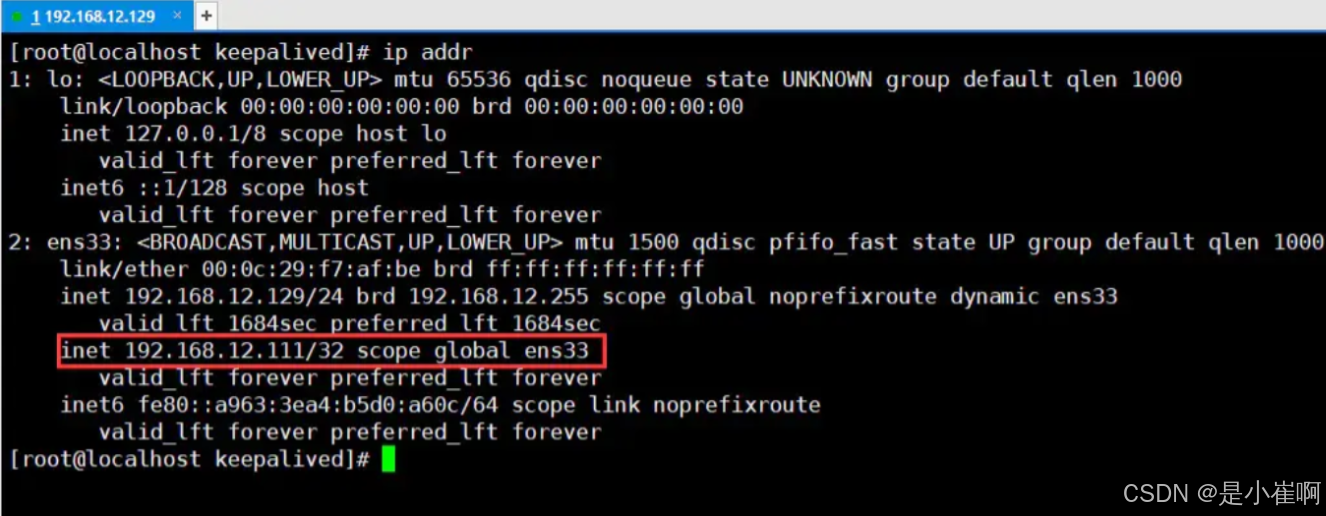
从上图中可以明显看见虚拟IP已经成功挂载,但另外一台机器192.168.12.130并不会挂载这个虚拟IP
只有当主机下线后,作为从机的192.168.12.130才会上线,接替VIP。
最后测试一下外网是否可以正常与VIP通信,即在Windows中直接ping VIP:
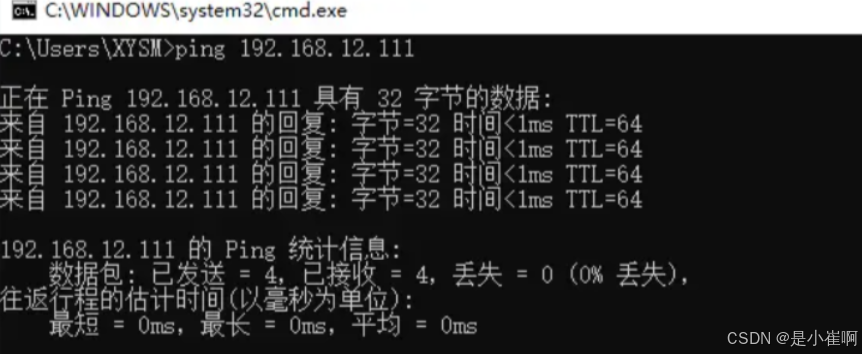
外部通过VIP通信时,也可以正常Ping通,代表虚拟IP配置成功
3.2:Nginx高可用测试
经过上述步骤后,keepalived的VIP机制已经搭建成功,在上个阶段中主要做了几件事:
- 为部署
Nginx的机器挂载了VIP。 - 通过
keepalived搭建了主从双机热备。 - 通过
keepalived实现了Nginx宕机重启。
由于前面没有域名的原因,因此最初server_name配置的是当前机器的IP,所以需稍微更改一下nginx.conf的配置:
sever{
listen 80;
# 这里从机器的本地IP改为虚拟IP
server_name 192.168.12.111;
# 如果这里配置的是域名,那么则将域名的映射配置改为虚拟IP
}

在上述过程中,首先分别启动了keepalived、nginx服务
然后通过手动停止nginx的方式模拟了Nginx宕机情况,过了片刻后再次查询后台进程,我们会发现nginx依旧存活。
从这个过程中不难发现,keepalived已经为我们实现了Nginx宕机后自动重启的功能,那么接着再模拟一下服务器出现故障时的情况:
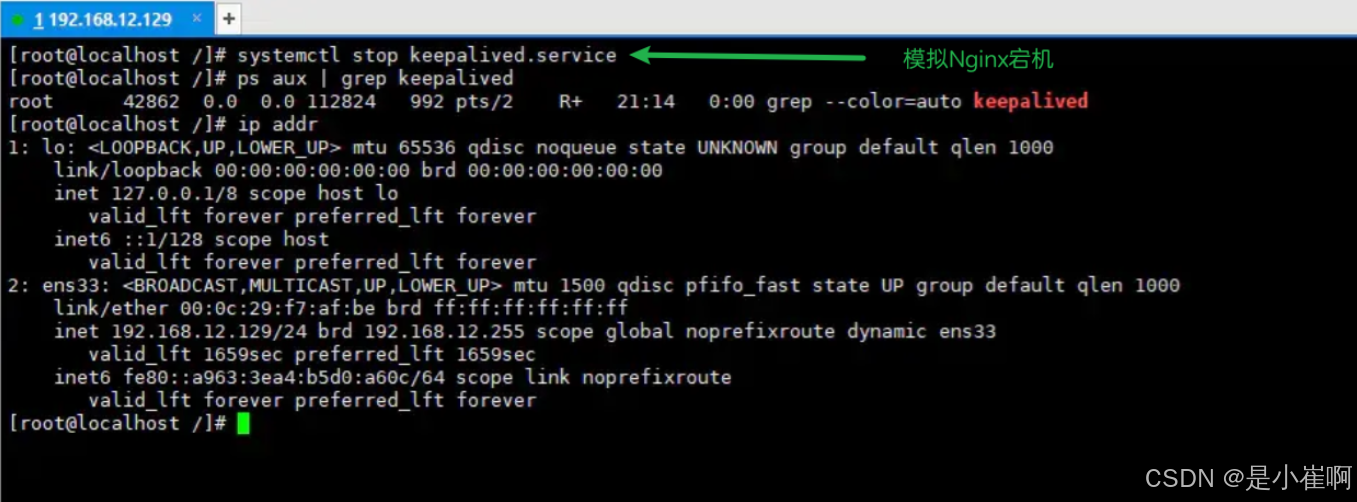
在上述过程中,我们通过手动关闭keepalived服务模拟了机器断电、硬件损坏等情况(因为机器断电等情况=主机中的keepalived进程消失)
然后再次查询了一下本机的IP信息,很明显会看到VIP消失了!
现在再切换到另外一台机器:192.168.12.130来看看情况:
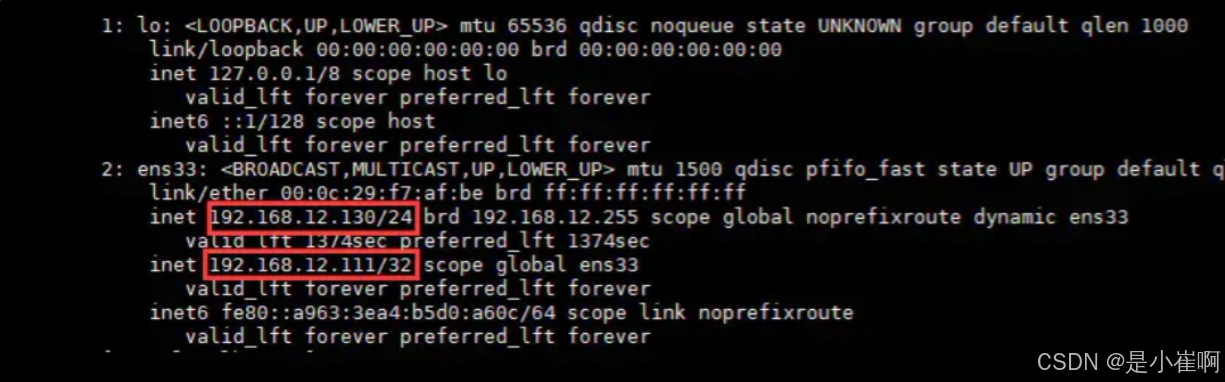
此刻我们会发现,在主机192.168.12.129宕机后,VIP自动从主机飘移到了从机192.168.12.130上
而此时客户端的请求就最终会来到130这台机器的Nginx上。
最终,利用Keepalived对Nginx做了主从热备之后,无论是遇到线上宕机还是机房断电等各类故障时,都能够确保应用系统能够为用户提供7x24小时服务。
四:多形态的存储型集群
逻辑处理型的应用,部署集群架构是为了解决单点故障、获得更高的吞吐量,集群内各节点之间没有依赖关系
同时遵循着“去中心化思想”,即多个节点里没有所谓的“老大”。
反观存储型的应用,需要保存数据、记录会话数据、用户认证信息、事务状态等信息
如果要搭建集群架构,则需要考虑各节点之间的数据一致性和完整性
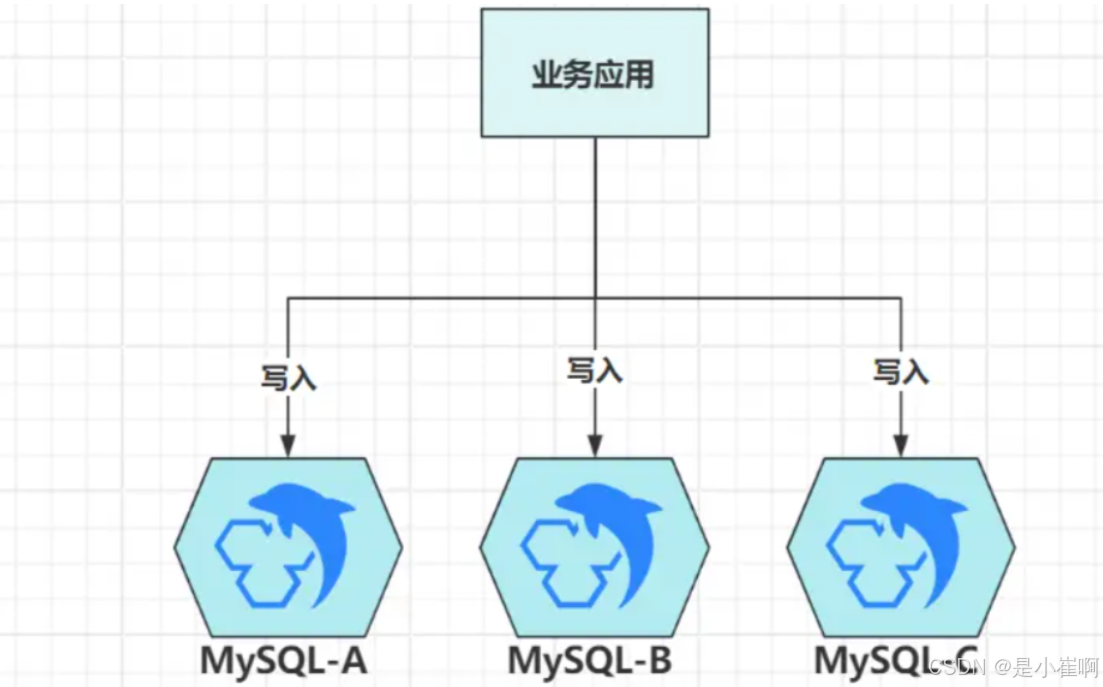
假设现在数据库使用三个节点组成集群,如果和业务系统集群一样,多个节点之间地位平等
此时客户端读写数据时,究竟该去到哪个节点呢?包含多个操作的事务如何保证落到同一节点?
用户在A节点登录后,如何把登录态(连接信息)同步给B、C节点?
正是因为上述一堆的问题,存储型集群里的节点必须要划分等级,一定要有一个等级更高的节点,来承担客户端的写操作。因
此,在很长一段时间内,涉及到数据存储的应用,集群方案都是以主从模式为主。
主从模式对应的英文是
Master/Slave,不过大家会发现,后来许多技术的主从模式,都叫Leader/Follower,这是为啥?因为
Master/Slave代表的是“主人/奴隶”,再加上集群存在选举机制,所以在西方被痛斥为“此命名的政治思想不正确”于是许多技术栈都经历过“语言净化”(如Redis)……
存储型应用的集群方案,粗分下来也是两大类:
- 主从模式:集群内的节点区分等级,可以有一或多个主节点,具备完整的读写能力;也允许拥有多个从节点,但能力方面有所阉割,只具备处理读取请求的能力。
- 分片模式:集群内节点地位平等,各节点都具备数据读写能力,但每个节点只负责一部分数据,完整数据分散在各节点上。
1:主从架构
主从集群,这个概念所有人都熟悉,它的身影在各种技术栈随处可见,如主从集群、镜像集群、复制集群、副本集群……
尽管在不同技术栈的叫法不同,可本质上都是同一个东西。
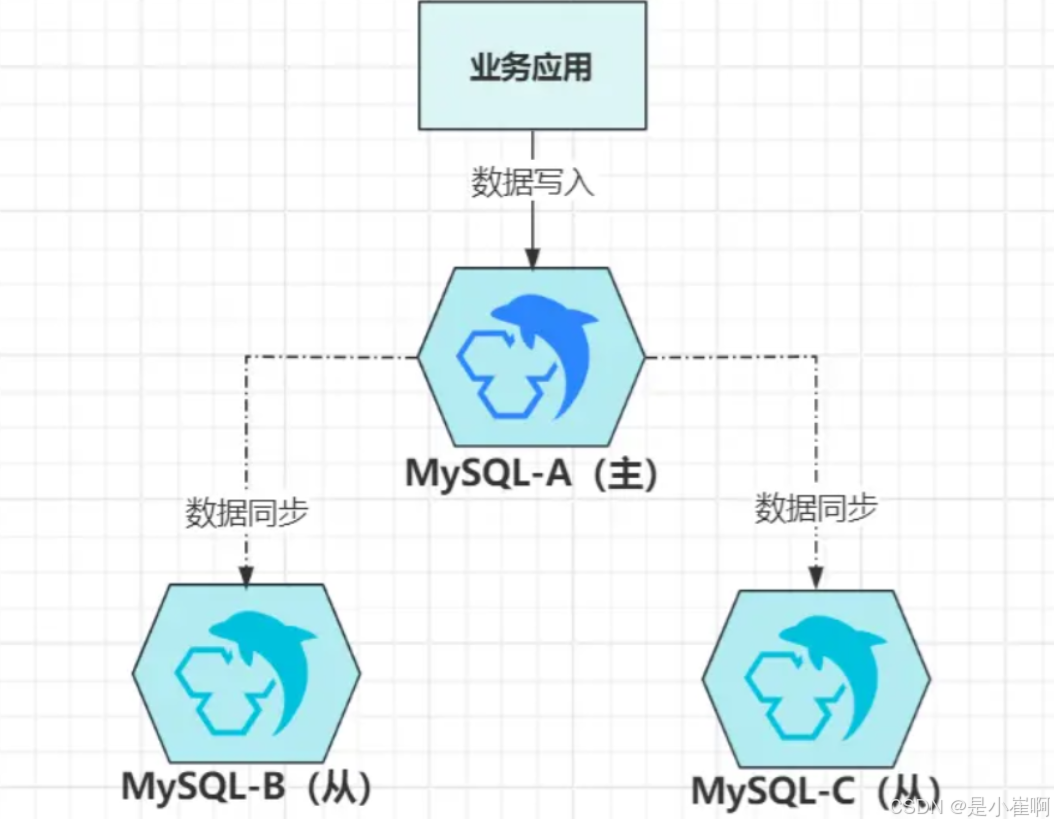
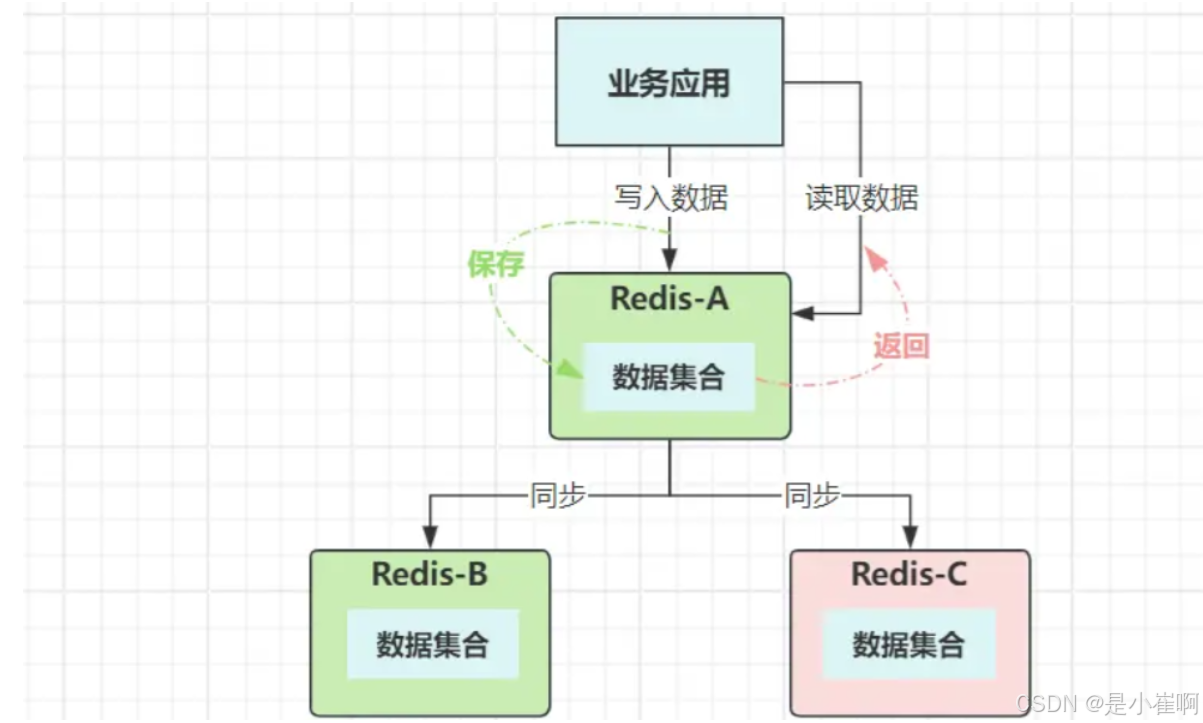
上图是经典的一主多从架构,客户端的写请求,都会落到主节点A上,而后再给同步给B、C这两个从节点,这就是“主从复制技术”,数据同步有三种方案:
- 同步复制:等数据写入集群所有节点后,再给客户端返回写入成功;
- 半同步复制:等集群内一半数量以上的节点写入数据成功后,给客户端返回写入成功;
- 异步复制:数据在主节点上写入成功后,立即给客户端返回写入成功。
大多数支持主从复制的技术栈,几乎都上面三种同步方案
从数据一致性角度看:同步复制 > 半同步复制 > 异步复制,而从性能角度出发则完全相反:异步复制 > 半同步复制 > 同步复制。
如今大多数技术栈默认的复制方案都是第三种,虽然有数据丢失的风险,可是它的性能最好
何况“主节点写入完数据,正好就发生故障”的这种几率很小。
当然,如果你的系统更在乎数据一致性和安全性,那就可以选择半同步模式,如果完全不在乎性能,则可以切换成同步复制模式。
1.1:读写分离
在主从架构中,因为从节点被阉割掉了处理写请求的能力,所以在大部分时间里,如果从节点只作为数据副本而存在,显然会造成很大的资源浪费。
为了充分利用从节点的资源,一种名为“读写分离”的技术曾风靡一时。
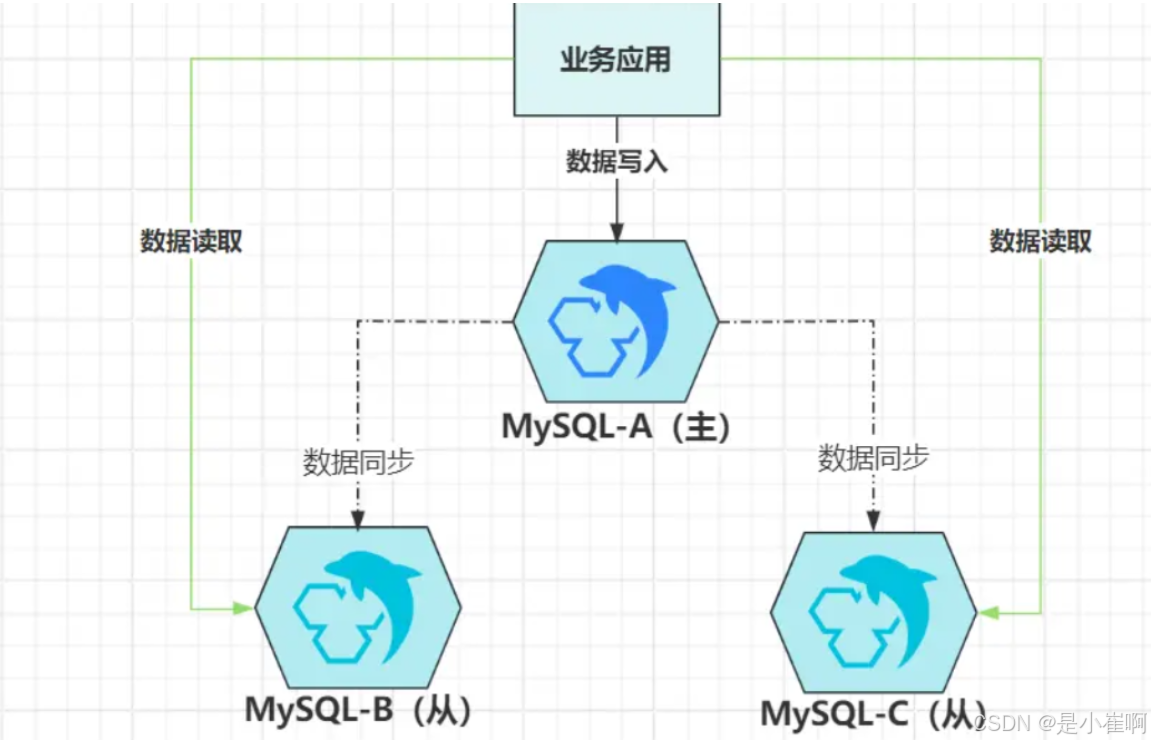
虽然从节点没有处理写请求的能力,可是它会把主节点写入的所有数据都同步过来
为此,它具备“一定程度”的读请求处理能力,此时就可以将读取数据的请求分发给从机,既能充分利用空闲资源,又能减轻主节点的访问压力。
因为主从复制技术,都依靠网络来同步数据,而网络并不可靠,也必然存在延迟性。
在异步复制的模式下,当一个数据写入到主节点,立马出现读请求到从节点读取,此时有可能读不到最新的数据。
1.2:故障转移
集群四大优势,其中一条则是保证了高可用,解决了单点故障问题,可实际上部分技术栈
虽然支持主从集群,但却只提供了基本的主从复制功能(如MySQL),并不具备故障转移能力。
所谓的故障转移,通常是针对主节点而言的,即:当主节点发生故障时,集群能自动推选出新主节点,并将流量自动转移到新主处理。
大家熟知的MySQL,它并不具备自动故障转移功能
当原本设定的主节点故障后,必须通过人工介入、或第三方工具(如MHA),又或者自己研发的组件实现故障转移。
当然,也有很多技术栈,官方就实现了故障转移机制,比如Redis的Sentinel哨兵、MongoDB的Arbiter仲裁者、Kafka的Controller控制器……
这些中间件的主从集群,在主节点发生故障时,都能实现无人力介入、自动转移效果。
这种自动故障转移机制,它们内部是如何实现的?其实原理大同小异,故障转移的第一步,是需要能检测出故障的节点,有两种方案可选:
- ①探测模式:负责故障处理的节点,每隔一段时间向集群所有节点发送探测包(
ping),没有回复的节点说明已经故障; - ②上报模式:集群内所有节点,主动向负责故障处理的节点发送存活信息(心跳),当一个节点没有心跳时说明陷入故障。
不过为了兼容网络分区问题,通常会组合起来使用,正常情况下,集群节点主动发送心跳包,当某个节点没有心跳后,故障处理节点会主动发起探测请求,如果还是没有回复,则会认为该节点陷入故障。
考虑到网络分区的影响,故障处理节点也可能陷入了分区,因此也会向其他故障处理节点,发出二次确认的请求,以此进一步确认对应节点是否故障。
上述概念类似于
Redis哨兵里的主观下线、客观下线,同时也不仅仅只有故障处理节点,具备故障检测能力,集群内的节点也拥有该能力,如从节点去拉数据时,也可以检测出主节点的健康状态。
如果本次检测出的故障节点是主节点,则会进入新主选举流程
选举一般是通过投票机制实现,新主上任的前提是“节点数一半以上的票数”;
而投票机制的内在逻辑则是数据POS点,即谁的数据更新则更有机会成为新主
总体流程如下:
- 故障检测:当感知到某个节点不可用时,会先发起通信向其他可用节点进行二次确认;
- 故障处理:如果检测到主节点不可用,从节点会将自己转换为候选人,并向其他成员宣布;
- 选举开始:轮次号加一,开启一轮新的选举,每个候选人节点开始向其他成员发送拉票请求;
- 投票开始:在一个新的选举轮次中,每个节点只能投一票,可以投给自己或者其他节点;
- 投票结束:所有节点已投票,或抵达本轮选举的时间限制后,将获得大多数投票的节点立为新主;
- 主从切换:新主会向其他节点发送“上位”消息,其他节点更新自己的配置,接受新主上位;
- 数据同步:完成主从切换后,从节点以新主为数据基准,校验自身数据是否完整,有缺失则同步。
上面只是大概流程,但几乎所有技术栈实现的思路都是这样,因为它们都遵循着Paxos、Raft等协议制定的标准
1.3:级联复制
级联复制是主从架构的变种,其本质还是主从模型,主要用于一主多从的结构中
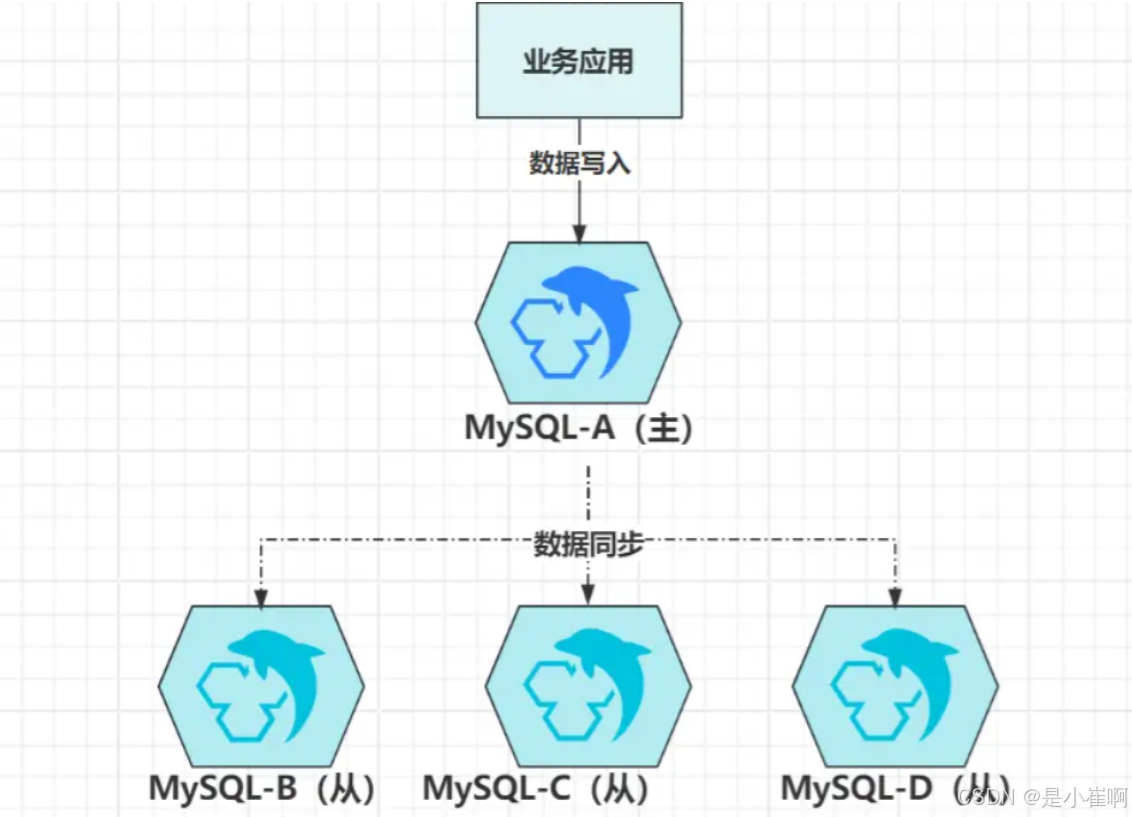
在主从架构中,想要实现数据同步有两种方式:
- 主节点推送:当主节点出现数据变更时,主动向自身注册的所有从节点推送新数据写入。
- 从节点拉取:从节点定期去询问一次主节点是否有数据更新,有则拉取新数据写入。
但不管是哪种方式,都会存在一个问题:主节点同步数据的压力,会随着从节点的数量呈线性增长!
因为不管是推还是拉,数据都需要从主节点出站。
对主节点来说,数据同步会对磁盘、内存、带宽、CPU带来不小压力,此时多一个从节点,自然多出一倍的压力,数据量较大时,特别容易把主节点的资源占满,从而造成主节点无法处理客户端的请求,级联复制的出现,就是为了解决此问题。
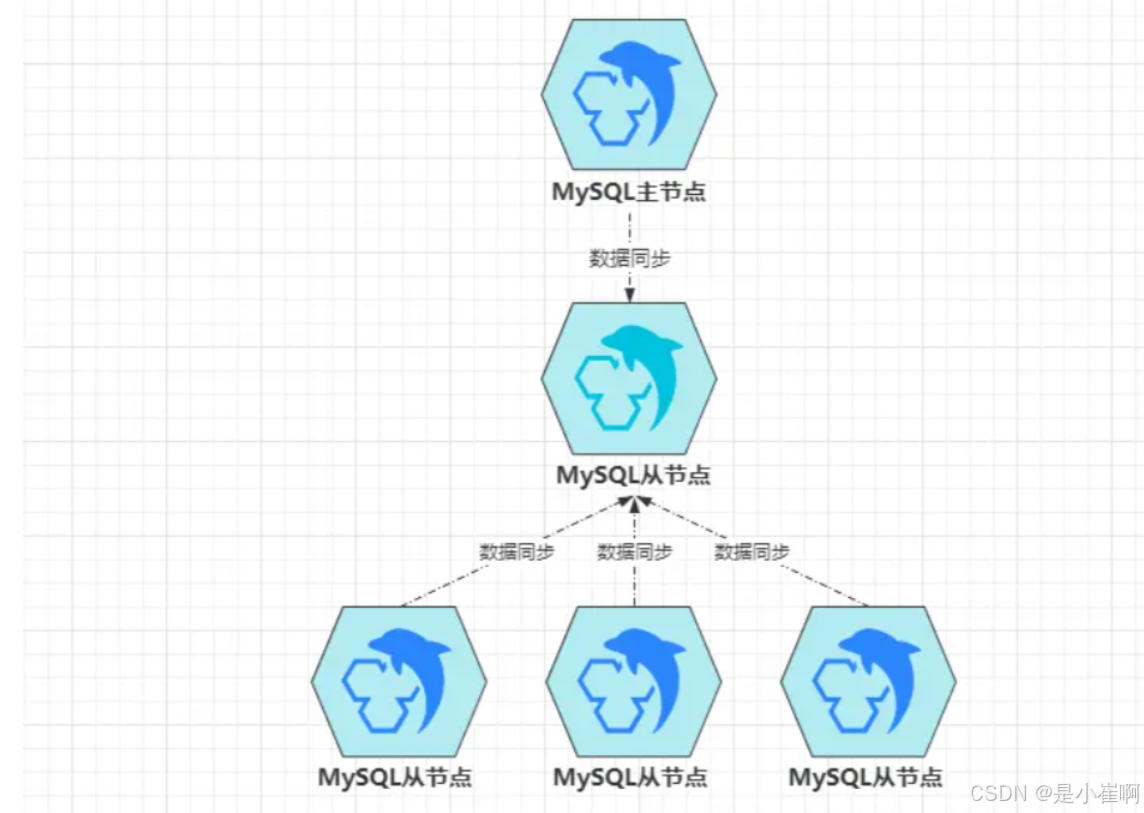
级联复制模式中,只有一个从节点B挂在主节点A下面,其余的从节点都会成为B的从节点
数据由B先同步到自身,其余节点再从B去同步数据,这样就解决前面的问题,可此时又会带来新问题:
- 数据延迟:本身主从复制就存在延迟性,而新加入一层后,数据延迟性会更高;
- 级联节点故障:负责同步主节点数据的
B一旦故障,会导致其余从节点无法同步数据。
凡事有利必有弊,虽然级联复制能解决原本的问题,可是也会带来新问题,这时就需要处理新的问题,或者把新问题的影响降到最低。
用来同步数据的
Canal中间件,就类似于级联复制的思想。当然,除开小部分特殊的项目,一般很少用到级联复制模式。
1.4:多主热备
虽然可以通过读写分离、级联复制,减轻主节点的部分压力,可对于写请求,都必须得落到主节点上处理
而主节点再强悍,总有扛不住的时候,这时又出现了变种集群:双主/多主模式。
多主模式也是建立在主从复制的基础之上,比如双主模式时,两个节点互为主从,各自都具备完整的读写能力,客户端的写请求,可以落入任意节点上处理。
不管数据落到哪个节点,另一个节点都会将数据同步过去,此时客户端的读取请求,在任意节点上都能读到数据。
通过这种方案,可以将写入性能翻个倍,并且可以继续拓展出更多的主节点,组成多主集群。
不过一般是双主,因为大部分技术栈支持的主从集群,仅允许为一个从节点配置一个主节点,在这个限制下,想要实现多主,则只能组成环形多主集群:
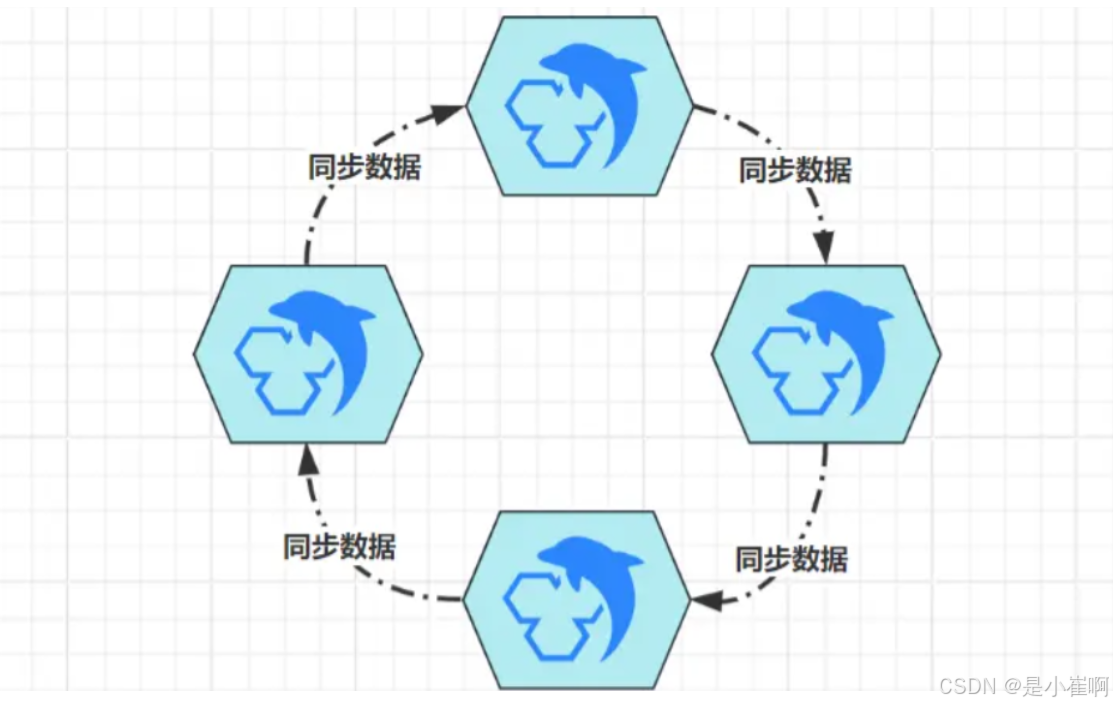
这种环形多主架构,由于每个节点都支持写入数据,所以能极大提升写入吞吐量,但成也萧何败也萧何
一个节点写入新数据后,需要经过N次(节点数量-1)复制,才能将数据同步给所有节点,集群内的延迟性很高,这也是为什么一般只搭建双主的根本原因。
多主集群除开能提升写入吞吐量外,只要客户端略加适配,就可以实现“客户端版故障转移”
即客户端检测到一个节点不可用后,自动切换到其他节点上读写数据
2:分片架构
2.1:分片集群
之前的单体模式也好,主从集群也罢,数据其实都是集中式存储,即所有数据都存储在一起。
分区存储,就相当于把原本的一缸水,分到不同的桶子里
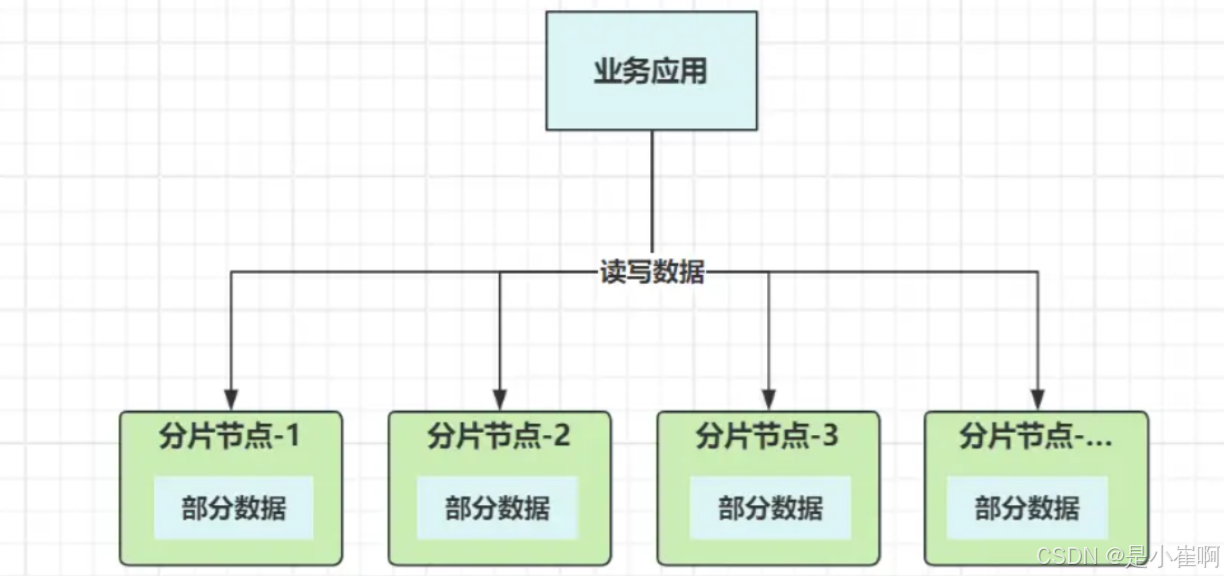
每个分片节点,都具备读写数据的能力,这样就从根本上解决了写入瓶颈
并且数据分散到多个节点独立存储,这并不受木桶效应的影响,解决了PB级数据存储造成的容量危机。
分片集群的好处很多,但想要实现分片式存储,首先要解决的就是数据路由问题,写入时能自动根据规则落到某个分片节点存储,读取时能精准找到存储的分片节点获取数据。这和前面的请求分发算法类似,只不过数据分发时,需要保证同一数据的写入/读取落入相同的节点。
数据路由到具体的分片节点,有两个核心点,一是分片(路由)算法,二是分片(路由)键。
数据分发和请求分发不同,因为要保证同一数据读写都在相同节点操作,光靠分发算法无法实现
所以每条数据需要有个标识,这个标识就是路由键,以ID字段作为路由键来举例:
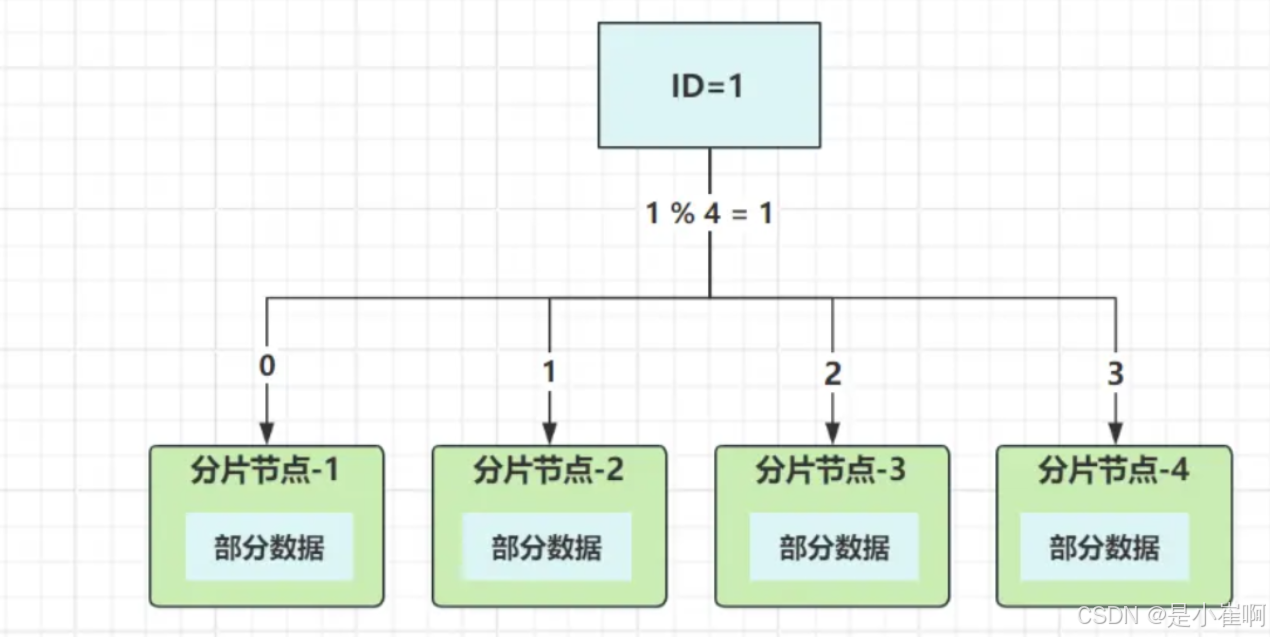
集群有四个节点,选用取模分发算法,根据ID值取模节点数量,计算出数据最终要落入的节点。来看实际过程,假设要操作ID=1这条数据:
- 写入:路由键
ID取模四:1%4,结果为1,数据落入分片节点2; - 读取:路由键
ID取模四:1%4=1,从分片节点2中读取数据。
通过这种方式,就保证了读写数据的节点一致,避免“写入成功,无法读取”的尴尬现象发生。
不过除了取模分发外,还有其他一些分发算法,如范围分发、哈希取模、一致性哈希、哈希槽……
像Redis-cluster集群中,就采用CRC16算法计算Key(Key即路由键),并结合哈希槽模式实现数据分发。
解决了数据分发问题后,分片架构其实还存在一系列问题,好比多节点的数据如何聚合等等。如果当前分片的存储组件属于关系型数据库,如何兼容事务机制?多表联查如何关联?
2.2:中心化分片集群
中心化分片集群,意味着集群中又存在不同的角色节点,最少有两种:
- 中心节点:负责路由规则、数据节点的管理工作,以及处理数据分发请求,自身不存储分片数据;
- 数据节点:具体存储数据的分片节点,负责处理中心节点分发过来的写入/读取数据请求。
上面的中心节点,就类似于之前的”负载均衡器“,负责管理集群所有节点,以及具体的分发工作
这种模式也是早期最主流的分片集群方案,即:代理式分片集群。
代理式分片,可以在官方不支持分片集群的情况下,自己来搭建分片集群
以传统关系型数据为例,MySQL官方并不支持分片存储,怎么办?之前有个大名鼎鼎的中间件叫:MyCat
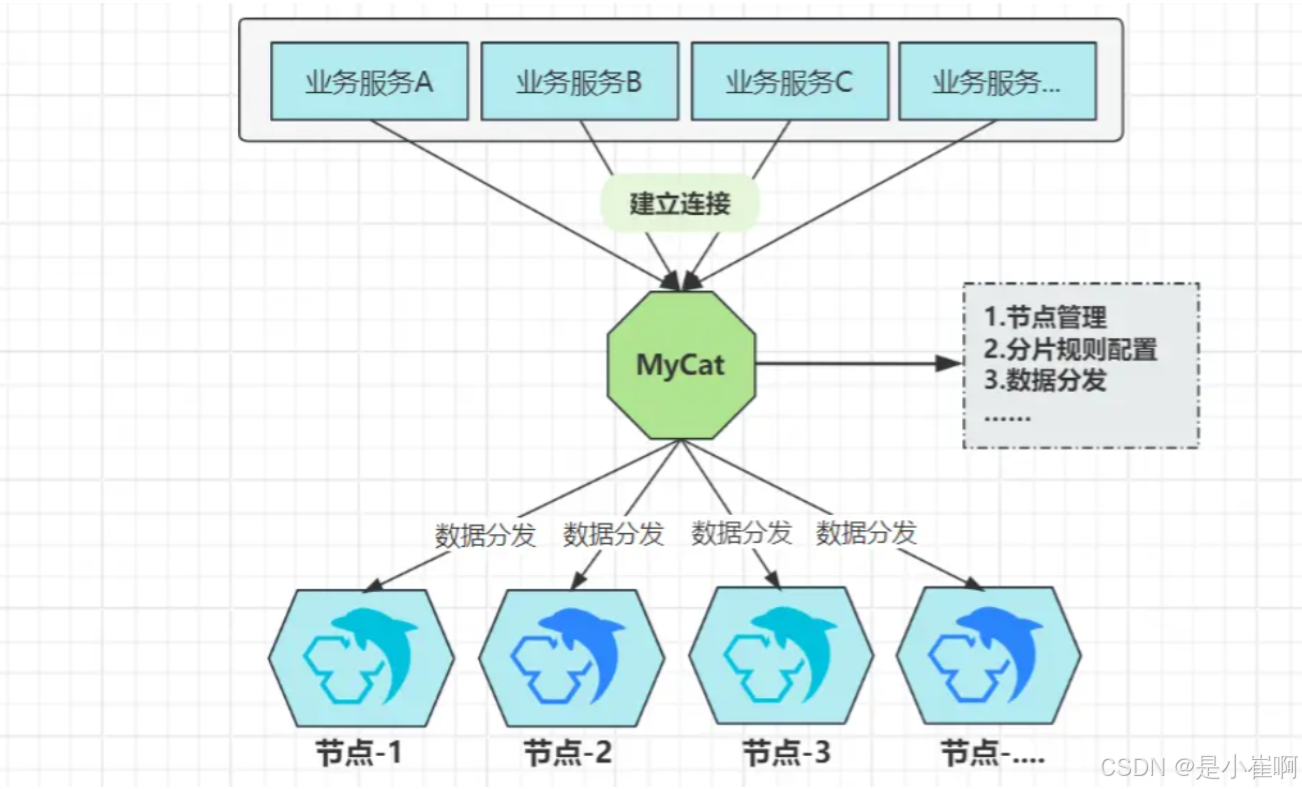
尽管MySQL不支持分片架构,但通过上述方案,可以将一个个独立的MySQL节点,组合成一个逻辑上的大整体
每个独立的MySQL节点,则代表着具体要存储数据的分片节点
MyCat则是负责节点管理与数据分发的中心节点,所有要操作MySQL的客户端,都会连接到MyCat,读写请求交给MyCat做具体分发。
际MyCat就是伪装成了一台MySQL,业务系统依旧和往常一样连接即可,屏蔽了客户端对分片集群的感知。
除开MyCat外,如同类型的Sharding-Proxy,又或者早期Redis的TwemProxy、Codis等等,这都是代理式分片理念的产物。究其根本,还是由于早期官方并不支持分片式架构,因此部分业务庞大的企业迫于无奈,只能在更高的维度上,架设中心节点来分发数据到不同的节点中存储。
这种中心化分片集群的思想,直到现在依旧在使用,只不过如今很少有代理中间件,基本都由官方自己实现,如MongoDB分片集群,依靠路由节点mongos进行数据分发。
为啥我称呼这类分片集群为“中心化分片集群”呢?其实站在数据/分片节点的角度出发,节点之间相互平等,不存在之前主从架构里的Master概念。可是,虽然没有了Master,但在数据节点之上有了一种更高维度的节点,所有数据节点都得“听”它安排,这就是一种另类的中心化体现。
中心化分片集群有何劣势?特别明显,不管是第三方实现的代理中间件,还是官方自身研发的“高等级节点”,毕竟所有请求都需经过“中心节点”,为此,一旦这类节点故障,必然会造成整个分片集群不可用。
中心化分片集群,为了解决中心节点的单点故障问题,一般都需要对中心节点做高可用建设,如mongos集群式部署、MyCat做热备等等。
2.3:去中心化分片集群
与上阶段提到的中心化分片集群相反的,则是去中心化分片集群
典型的例子就是Redis3.x推出的Redis-Cluster集群,这是一种完全意义上的去中心化集群
所有负责读写数据的节点地位平等,并且没有“中心化”的路由节点。
相反,Redis-Cluster中采用了哈希槽的概念,总计16384个槽位,集群初始化时会平均分给每个节点负责管理(支持手动设置)
比如现在有四个节点,哈希槽的默认分配如下:
A节点:0~4095槽位;B节点:4096~8191槽位;C节点:8192~12287槽位;D节点:12288~16384槽位;
类似于之前0~15这16个默认的库一样,每个槽中都可以存放多个Key,同时配备CRC16哈希算法,最终实现数据的分发,例如下述命令:
set name cui
则会使用CRC16算法对name这个键名进行哈希,接着取模总槽数16384,从而得出具体要落入的槽位。
假设name对应的哈希值是185272,最终落入槽位则是5047(185272%16384-1),即落入到B节点中存储。
既然没有中心化的路由节点,那CRC16+取模运算的工作谁来完成?集群内的所有节点!
在Redis-Cluster中,任意节点都具备CRC16取模的能力,来看个场景:
如果一个本该落入
A节点的Key,在set时去到了C节点,那么C节点在经过CRC16计算后,会不会把该Key转发到A节点去呢?
答案是不会,而是会向客户端会返回一个重定向错误的消息,其中指示了正确的节点位置,告诉客户端去连接对应节点写入数据即可。
实际项目中,并不会把
CRC16+取模的工作交给Redis来做,因为这样有可能会出现一次重定向通常都是客户端计算,而后直连正确的节点写入数据(如
Java中主流的Redis客户端框架,都有实现CRC16的逻辑)。
好了,上述便是去中心化的大体逻辑,相信大家一定明白为啥叫去中心化分片集群,因为不存在中心节点,各个节点自身就具备数据分发计算的能力
即使集群内部分节点宕机,也只会影响部分数据,保证了BASE理论中的基本可用思想
并不会像中心化分片集群那样,一旦中心节点故障,就会造成分片集群不可用。
分库分表领域的
Sharding-JDBC,也是一种去中心化分片存储的体现,即各个客户端具备数据分发的能力,不需要依赖MyCat这类中间件实现数据路由。
相较于传统的主从集群,分片式集群的维度显然更高,当应对数据量级、并发规模非常大的系统时,分片式集群能够利用多台机器的共同满足数据需求,它能充分利用集群中每一台机器的资源,实现数据读写的并行处理,以及海量数据的分区存储。

















 3201
3201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









