




存储过程和触发器(难,了解)
文章目录
MySQL起初并不支持存储过程,而是到了
MySQL5.0版本才支持存储过程的编写与执行
在MySQL中存储过程主要分为两类,一类是普通的存储过程,另一类则是触发器类型的存储过程
一:存储过程
1:初识存储过程
Stored Procedure存储过程是数据库系统中一个十分重要的功能,使用存储过程可以大幅度缩短大SQL的响应时间,同时也可以提高数据库编程的灵活性
存储过程是一组为了完成特定功能的SQL语句集合
使用存储过程的目的在于:将常用且复杂的SQL语句预先写好,然后用一个指定名称存储起来
这个过程经过MySQL编译解析、执行优化后存储在数据库中,因此称为存储过程。
当以后需要使用这个过程时,只需调用根据名称调用即可。
其实存储过程和Java中的方法、其他语言中的函数十分类似
也就是先将一堆代码抽象成一个函数,当之后需要使用时,不需要再重写一遍代码,而是直接根据名称调用相应的函数/方法即可。
对比常规的SQL语句来说,普通SQL在执行时需要先经过编译、分析、优化等过程,最后再执行,而存储过程则不需要,一般存储过程都是预先已经编译过的
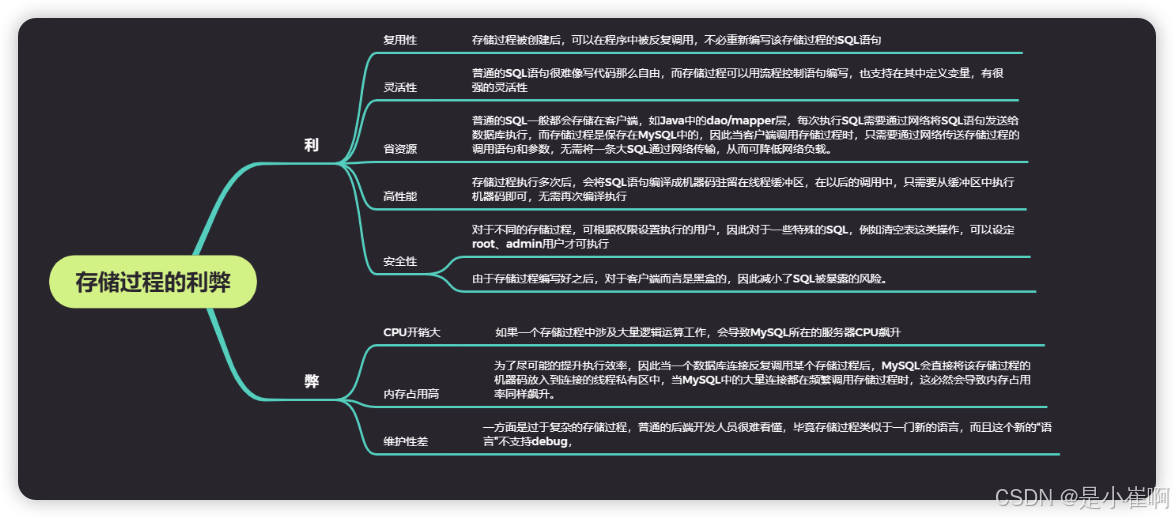
存储过程的利弊性
2:存储过程的定义、调用与管理
存储过程类似于一门新的语言,在其中存在专门的语法规则,因此想要撰写一个高效的存储过程之前,我们得先掌握存储过程中的一些基本语法
2.1:存储过程的语法
DELIMITER $ -- 定界符,这里指定定界符为 $,判定存储过程开始和结束
-- 创建的语法:指定名称、入参、出参
CREATE
PROCEDURE 存储过程名称 (返回类型 参数名1 参数类型1, ....) # 看这里是不是和java的方法十分的像
[存储过程的约束条件]
-- 表示开始编写存储过程体,类似于java的 {
BEGIN
-- 具体组成存储过程的SQL语句....
-- 表示到这里为止,存储过程结束,类似于java的 }
END $ -- 声明本次存储过程结束
DELIMITER ; -- 在结束之后,要再次把结束符改回;
所有语言的函数/方法定义时,一般都会分为四类:无参无返回,有参无返回,无参有返回,有参有返回。
而SQL的存储过程也不例外,同样也支持这四种定义,主要依赖于IN、OUT、INOUT三个关键字来区分:
- 定义存储过程时,没有入参也没有出参,代表无参无返回类型。
- 定义存储过程时,仅定义了带有
IN类型的参数,表示有参无返回类型。 - 定义存储过程时,仅定义了带有
OUT类型的参数,表示无参有返回类型。 - 定义存储过程时,同时定义了带有
IN、OUT类型的参数,或定义了带有INOUT类型的参数,表示有参有返回类型。
DELIMITER $ 是什么意思?
其实这表示指定结束标识,在MySQL中默认是以;分号作为一条语句的结束标识
因此当存储过程的过程体中,如果包含了SQL语句,SQL语句以;结束时,MySQL会认为存储过程的定义也结束了,过程体就会和;结束符冲突
所以一般咱们要重新定义结束符,例如DELIMITER $,表示以$作为结束标识,只有当MySQL识别到$符时,才会认为结束了。
⚠️ 在结束之后,要再次把结束符改回;,即DELIMITER ;。
存储过程的约束条件
LANGUAGE SQL:说明存储过程中的过程体是否由SQL语句组成[NOT] DETERMINISTIC:存储过程的返回值是否为固定的,没有[NOT]表示为固定的,默认为非固定的{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }:使用SQL语句的限制CONTAINS SQL:表示当前存储过程包含SQL,但不包含读写数据的SQL语句。NO SQL:表示当前存储过程中不包含任何SQL语句。READS SQL DATA:表示当前存储过程中包含读数据的SQL语句。MODIFIES SQL DATA:表示当前存储过程中包含写数据的SQL语句。
SQL SECURITY { DEFINER | INVOKER }:哪些用户可以调用当前创建的存储过程DEFINER:表示只有定义当前存储过程的用户才能调用。INVOKER:表示任何具备访问权限的用户都能调用。
COMMENT '....':注释信息,可以用来描述当前创建的存储过程。
2.2:存储过程的定义
直接举例子演示下,因为上面的定义有点绕
假设有一张user表有如下内容和表字段结构
| user_id | user_name | user_sex | password | register_time |
|---|---|---|---|---|
| 1 | 张三 | 女 | 1111 | 2023-10-21 15:22:01 |
| 2 | 李四 | 男 | 2222 | 2023-10-21 15:22:01 |
| 3 | 王五 | 男 | 3333 | 2023-10-21 15:22:01 |
| 4 | 赵六 | 男 | 4444 | 2023-10-21 15:22:01 |
| 8 | 钱七 | 女 | 8888 | 2023-10-21 15:22:01 |
| Field | Type | Null | Key | Default | Extra |
|---|---|---|---|---|---|
| user_id | int(8) | NO | PRI | NULL | |
| user_name | varchar(255) | YES | MUL | NULL | |
| user_sex | varchar(255) | YES | NULL | ||
| password | varchar(255) | YES | NULL | ||
| register_time | varchar(255) | YES | NULL |
无参数无返回值示例
查询用户表的所有用户信息
# 改变定界符为 $
delimiter $
create
# 定义存储过程的名称为:get_all_userInfo()
procedure get_all_userInfo()
begin
# 存储过程体:由一条查询全表的SQL组成
select * from `user`;
# 标识存储过程体结束
end $
delimiter ; # 改回去
call get_all_userInfo();
🎉 所有存储过程都是通过CALL命令来调用
有参数无返回值示例
接收一个用户名,查询用户的注册时间
# 这里又将结束标识换成了 // 符号
DELIMITER //
CREATE
# 在定义存储过程时,用 IN 声明了一个入参,入参名称是name, 类型是varchar(255)
PROCEDURE get_user_register_time(IN name varchar(255))
BEGIN
select `register_time` from `user` where `user_name` = name;
# 标记存储过程结束
END //
DELIMITER ;
call get_user_register_time("张三")
无参数有返回值示例
查询
ID=1的用户密码并返回
DELIMITER //
CREATE
# 在定义存储过程时,用 OUT 声明了一个返回值
PROCEDURE get_user_password(OUT userPassword varchar(255))
BEGIN
# 注意into的使用
select `password` into userPassword from `user` where `user_id` = 1;
END //
DELIMITER ;
# 调用
CALL get_user_password(@userPassword); # 直接使用`@`符号,在调用的地方定义变量即可
select @userPassword;
🎉 要调用时直接使用@符号,在调用的地方定义变量即可,调用完成后想要查看返回值,还需要手动查询一次调用时定义的变量
⚠️ 返回值的数据类型一定要和表字段保持一致,否则有可能出现类型转换错误,毕竟不是所有的类型之间可以隐式转换
有参数有返回值示例
接收一个用户名,返回该用户名对应的用户
ID
这个需求有两种实现方式:
- 定义两个参数,一个
IN类型的,一个OUT类型的。 - 使用
INOUT关键字来实现。
# 由于方式2还没有用过,这里用inout测试
DELIMITER $
CREATE
-- 在定义存储过程时,用 OUT 声明了一个返回值
PROCEDURE get_user_id(INOUT parameters varchar(255))
BEGIN
select `user_id` into parameters from `user` where `user_name` = parameters;
END $
DELIMITER ;
上述存储过程中,利用INOUT定义了一个参数parameters,在下面的存储过程体当中,即使用它作为查询参数,又使用它作为了保存返回值的变量
-- 先定义一个变量
set @parameters = "张三";
-- 将定义的变量在调用时传入
CALL get_user_id(@parameters);
-- 再次查询定义的变量
select @parameters;
🎉 如果想要调用这类方法,咱们得先定义一个变量,然后在调用时传入,最后再次查询这个变量即可。
// 类比一下java就是这样的,就是实际上没有return出结果,而是通过重新赋值的方式做到值传递
public void getUserId(Object obj) {
obj = 1; // 重新赋值,从而做到值传递
}
Object obj = new Object("张三");
getUserId(obj);
System.out.println(obj);
2.3:系统变量和用户变量、局部变量
系统变量
在MySQL启动后,其内部也会存在许多的系统变量,系统的意思是指由MySQL定义的,而并非用户自己定义的
一般系统变量要么来自于MySQL编译期,要么来自于my.ini配置文件,对于具体拥有那些系统变量,可参考:MySQL官网文档-系统变量
MySQL的系统变量也会分为两类,一类是全局级变量,一类是会话级变量
# 例如transaction_isolation变量就是一个系统变量, 引用一下之前讲过的事务隔离机制的命令:
-- 方式①:查询当前数据库的隔离级别
SELECT @@transaction_isolation;
-- 方式②:查询当前数据库的隔离级别
show variables like '%transaction_isolation';
-- 设置隔离级别为RU级别(当前连接生效)
set transaction isolation level read uncommitted;
-- 设置隔离级别为RC级别(全局生效)
set global transaction isolation level read committed;
-- 设置隔离级别为RR级别(当前连接生效)
-- 这里和上述的那条命令作用相同,是第二种设置的方式
set transaction_isolation = 'repeatable-read';
-- 设置隔离级别为最高的serializable级别(全局生效)
set global.transaction_isolation = 'serializable';
全局生效和会话生效
-
当在修改命令中加上
global关键字,则代表修改全局级别的系统变量,修改全局级别表示对所有连接都生效 -
如若不加或加上
session关键字,则表示只修改当前会话的系统变量,修改会话级别的变量,表示只对当前连接生效,在当前连接中修改系统变量的值之后,是不会影响其他数据库连接的。
🎉 对于系统变量,想要查看或修改,使用两个@@符号即可,例如:
-- 查看某个系统变量
select @@xxx;
-- 修改某个系统变量
set @@xxx = "xxx";
用户变量
用户变量,也就是自定义的变量
set @变量名称 = 变量值; # 中间 = 可以使用 :=
select @变量名称;
相较于系统变量而言,用户变量仅仅少了一个@符号而已
除此之外,用户变量的定义还可以和SQL组合,如下:
-- 将用户表的总行数赋值给 row_count 变量
select @row_count := count(*) from `users`;
-- 将 user_id 的平均值赋给 avg_user_id 变量
select avg(user_id) into @avg_user_id from `users`;
但凡出现@符号时,MySQL都会将其识别为在定义变量
局部变量
局部变量只对当前存储过程体有效,其他存储过程或外部是无法读取或操作局部变量的
declare 变量名称 数据类型 default 默认值
# 举个例子
DECLARE message varchar(255) default "not message";
上述定义了一个名为message的局部变量,如果后续使用时未对其赋值,该变量的默认值为"not message"。
后续使用局部变量时,主要有两种赋值方式,如下:
-- 赋值方式一
set message = 变量值;
set message := 变量值;
-- 赋值方式二
select 字段名或函数 into message from 表名;
总结
结合存储过程一起熟悉一下用户变量和局部变量
DELIMITER //
CREATE
-- 定义了一个求两数之和的存储过程
procedure add_value(IN number1 int(8), OUT result int(8))
BEGIN
-- 对于局部变量的定义,必须要写在BEGIN、END之间,否则会提示语法错误
-- 这里定义了一个局部变量:number2,默认值为 666
declare number2 int(8) default 666;
-- 将两个数字相加,计算得到的和放入用户变量 result 中
set result := number1 + number2;
END //
DELIMITER ;
-- 定义一个用户变量,接收调用存储过程后得到的和
set @result = 0;
-- 调用存储过程,传入一个数字 888 以及接收结果的 result 变量
call add_value(888, @result);
-- 查询计算后的和
select @result;
⚠️ 对于局部变量的定义,必须要写在BEGIN、END之间,否则会提示语法错误
2.4:流程控制
条件选择 -> if
if 条件判断 then
-- 分支操作.....
elseif 条件判断 then
-- 分支操作.....
else
-- 分支操作.....
end if
上述这段if判断语句基本上和其他语言中相差无几,当一个条件判断成立时,就会进入相应的分支中执行,否则程序会跳过该分支继续往下执行
delimiter $
# 声明存储过程:名称,入参,返回值
create
procedure if_user_age(int age int, out msg varchar(255))
# sql块
begin
if age < 18 then
set msg := '未成年';
elseif age = 18 then
set msg := '刚成年';
else
set msg := '已成年';
end if;
# 存储过程结束
end $
# 分界符变回到;
delimiter ;
条件选择 -> case
-- 第一种语法
case 变量
when 值1 then
-- 分支操作1....
when 值2 then
-- 分支操作2....
.....
else
-- 分支操作n....
end case;
-- 第二种语法
case
when 条件判断1 then
-- 分支操作1....
when 条件判断2 then
-- 分支操作2....
.....
else
-- 分支操作n....
end case;
第二种语法和if其实是一样的, 这里对第一种方式举一个例子:
delimiter $
create
procedure test_case(in n int)
begin
case n
when 1 then
select "张三"
when 2 then
select "李四"
else
select "王五"
end case;
end $
# 存储过程结束
end $
# 分界符变回到;
delimiter ;
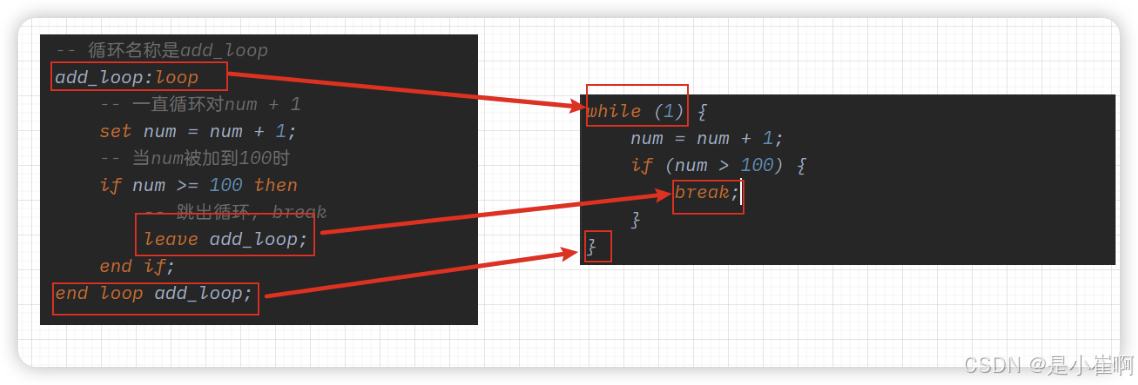
循环控制 -> loop
循环名称:loop
-- 循环体....
end loop 循环名称;
在存储过程的循环,与其他编程语言的循环并不同,在存储过程中可以给每个循环取一个名字,后续可以基于这个名字来跳出循环
如果想要跳出一个循环,还需要结合LEAVE这个关键字,否则会令循环成为一个死循环
delimiter $
create
procedure test_loop(in num int)
begin
-- 定义一个局部变量:num
declare num int(8) default 1;
-- 循环名称是add_loop
add_loop:loop
-- 一直循环对num + 1
set num = num + 1;
-- 当num被加到100时
if num >= 100 then
-- 跳出循环, break
leave add_loop;
end if;
end loop add_loop;
select num;
end $
delimiter ;
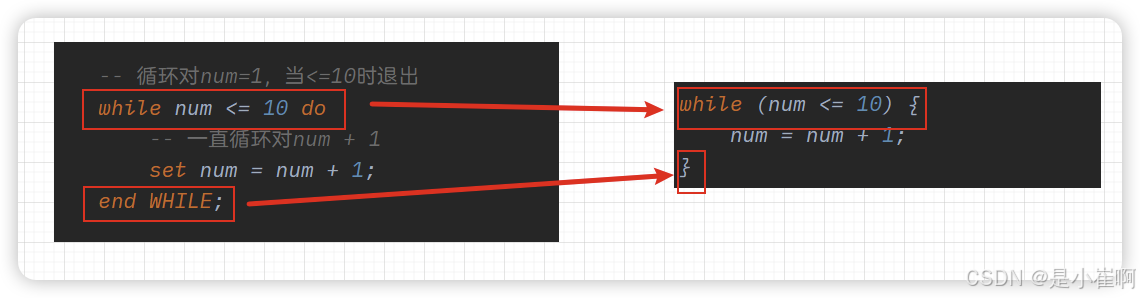
循环控制 -> while
【循环名称】: while 循环条件 do
-- 循环体....
end while 【循环名称】;
循环控制 -> repeat
REPEAT循环和之前两个循环不同,在这种循环中,有专门控制循环结束的语法
【循环名称】: repeat
-- 循环体
until 【结束循环的判断条件】
end repeat 【循环名称】
当UNTIL关键字之后的条件为真时,循环就会终止
delimiter $
create
procedure test_repeat()
begin
-- 定义一个局部变量:num
declare num int(8) default 1;
repeat
set num = num + 1;
until num >= 10 -- 结束循环条件
end repeat;
-- 最后查询一下num值
select num;
end $
delimiter ;
跳转条件 -> leave & iterate
leave, iterate两个跳转的关键字,其实本质上就和Java中的break、continue类似
-- 测试ITERATE关键字跳出循环
delimiter $
create
procedure test_iterate()
begin
-- 定义一个局部变量:num
declare num int(8) default 0;
-- 定义一个局部变量用来统计偶数和
declare even_sum int(8) default 0;
sum_while: while num <= 100 do
-- 对num持续做+1
set num = num + 1;
-- 如果num=10,用LEAVE终止循环
if num % 2 = 0 then
set even_sum = even_sum + num;
else
-- continue
iterate sum_while;
end if;
end while sum_while;
-- 最后查询一下偶数之和
select even_sum;
end $
delimiter ;
2.5:存储过程的游标
游标是所有数据库的存储过程中,很重要的一种特性
游标可以对一个结果集中的数据按条处理,也就意味着原本查询出的数据是一个整体性质的集合,而使用游标可以对该集合中的数据逐条处理
在使用游标时一般都会遵循下述四步:
-- ①声明(创建)游标
declare 游标名称 cursor for select ...;
-- ②打开游标
open 游标名称;
-- ③使用游标
fetch 游标名称 into 变量名称;
-- ④关闭游标
close 游标名称;
计算用户表中
user_id最大的前N个奇数ID之和。
delimiter $
create
procedure id_odd_number_sum(in N int(8), out sum int(8))
begin
-- 声明局部变量:
-- uid:用于记录每一个user_id
-- odd_id_count:记录奇数ID的个数
-- odd_id_sum:记录奇数ID的和
declare uid int(8) default 0;
declare odd_id_count int(8) default 0;
declare odd_id_sum int(8) default 0;
-- 声明一个游标:存储倒序的user_id结果集,可以想象成为一个缓存,后面会用这个游标
declare uid_cursor cursor for select user_id from users order by user_id desc;
-- 打开游标
open uid_cursor;
-- 使用游标
repeat
-- 将游标中的每一条user_id值,赋给user_id变量
fetch uid_cursor into uid;
-- 如果当前user_id是奇数,则将ID值累加到sum中
if uid % 2 != 0 then
set odd_id_count = odd_id_count + 1;
set odd_id_sum = odd_id_sum + uid;
end if;
-- 根据传入的N来决定循环的次数
until odd_id_count >= N
end repeat;
-- 将前N个奇数ID之和赋给外部变量:sum
set sum = odd_id_sum;
-- 关闭游标
close uid_cursor;
end $
delimiter ;
3:客户端如何调用存储过程
一般在Java项目中,都会选择MyBatis作为操作数据库的ORM框架,那在其中调用存储过程的方式如下:
<parameterMap type="根据存储过程决定" id="自己命名">
<parameter property="存储过程参数1" jdbcType="数据类型" mode="IN"/>
<parameter property="存储过程参数2" jdbcType="数据类型" mode="IN"/>
<parameter property="存储过程参数3" jdbcType="数据类型" mode="OUT"/>
</parameterMap>
<!-- 注意这个类型CALLABLE -->
<insert id="和Dao接口的方法同名" parameterMap="上面的ID值" statementType="CALLABLE">
{call 存储过程名(?, ?, ?)}
</insert >
当需要调用存储过程中,只需要调用该xml对应的Dao/Mapper层接口即可。
4:存储过程的管理
所谓的存储过程管理,也就是指存储过程的查看、修改和删除。在MySQL中也提供了一系列命令,以便于咱们完成这些工作,如下:
SHOW PROCEDURE STATUS;:查看当前数据库中的所有存储过程。SHOW PROCEDURE STATUS WHERE db = '库名' AND NAME = '过程名';:查看指定库中的某个存储过程。SHOW CREATE PROCEDURE 存储过程名;:查看某个存储过程的源码。ALTER PROCEDURE 存储过程名称 ....:修改某个存储过程的特性。DROP PROCEDURE 存储过程名;:删除某个存储过程。
当然,也可以通过下述命令来查看某张表的存储过程:
-- 查看某张表的所有存储过程
select * from xxx.Routines where routine_type = "PROCEDURE";
-- 查看某张表的某个存储过程
select * from xxx.Routines where routine_name = "过程名" AND routine_type = "PROCEDURE";
5:存储过程的应用场景
因为存储过程难以维护,同时拓展性和移植性都很差,因此大多数的开发规范中都会明令禁止使用,例如阿里规约中就明确强制禁用存储过程

但存储过程能够带来的优势也极为明显,是一把双刃剑,至于用不用,就是见仁见智了。
一般来说,下面三种情况适合使用存储过程:
- 插入测试数据时,一般为了测试项目,都会填充测试数据,往常是写
Java-for跑数据,但现在可以用存储过程来批量插入,它的效率会比用for循环快上无数倍 - 对数据做批处理时,也可以用存储过程来跑,比如将一个表中的数据洗到另外一张表时
- 一条
SQL无法完成的、需要应用程序介入处理的业务,尤其是组成起来SQL比较长时,也可以编写一个存储过程
二:触发器
1:触发器定义
触发器本质上是一种特殊的存储过程,但存储过程需要人为手动调用,而触发器则不需要,它可以在执行某项数据操作后自动触发
触发器类似于
Spring-AOP中的切面一样,当执行了某个操作时就会触发相应的切面逻辑。
⚠️ 但触发器是在MySQL5.0.2版本以后才开始被支持的,在此之前的MySQL并不能创建触发器
create trigger 触发器的名称
{before | after} {insert | update | delete} on xxx_table_name
for each row
【触发器的逻辑】【代码块】
对于每一个触发器而言,总共有插入、修改以及删除三种触发事件可选,同时也可以选择将触发器放在事件开始前,亦或事件结束后执行
这点几乎和AOP切面的切入点一模一样
⚠️ 每个触发器创建后,必然是附着在一张表上的,因为在创建触发器的时候必须要指定表名,它会监控这张表上发生的事件
举个例子:
假设有一张注册日志表 register_log
| register_time | register_address | register_facility |
|---|---|---|
| 2023-10-21 12:22:05 | 大连市高新园区 | 安卓 |
| 2023-10-21 12:22:06 | 赤峰市宁城县 | 苹果 |
-- 在用户表上创建一个触发器
delimiter $
create
trigger users_insert_before
before insert on users -- 声明触发器的触发条件是每次users表插入之前
for each row
begin
-- 在每次users表插入之前,都插入一条信息到register_log
insert into `register_log` values(NOW(),"大连市高新园区","安卓");
end $
DELIMITER ;
2:new, old关键字
在触发器中,NEW表示新数据,OLD表示老数据,各类型的事件如下:
insert插入事件:NEW表示当前插入的这条行数据。update修改事件:NEW表示修改后的新数据,OLD表示修改前的老数据。delete删除事件:OLD表示删除前的老数据。
-- 执行的修改语句
update `users` set user_name = "张三" and user_sex = "女" where user_id = 9;
-- 用户表修改事件的触发器
delimiter $
create
trigger users_update_before
before update on zz_users
for each row
begin
declare new_name varchar(255);
declare old_name varchar(255);
-- 可以通过 NEW 关键字拿到修改后的新数据
set new_name := NEW.user_name;
-- 可以通过 OLD 关键字拿到修改前的老数据
set old_name := OLD.user_name;
end $
delimiter ;
为啥说触发器是一种特殊的存储过程呢
因为本质上触发器中所用的语法,和存储过程完全是一模一样的,只是存储过程需要手动调用,而触发器则是根据事件自动触发。
触发器可以用于一些特殊的业务场景比如需要在写数据前做数据安全性检测、又或者是洗数据时需要效验数据完整性、正确性、又或者是数据的备份和同步等
3:触发器的管理
show triggers:查看当前数据库中定义的所有触发器。show create trigger 触发器名称;:查看当前库中指定名称的触发器。select * from information_schema.TRIGGERS;:查看MySQL所有已定义的触发器。drop trigger if exists 触发器名称;:删除某个指定的触发器。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









