




Java8特性快速学习
文章目录
你发任你发,我用Java8
本文整理自稀土掘金 - 柱子爱熊猫大佬的一篇笔记
一:Java8接口的最佳实践
Java8的重头戏就是Lambda表达式和Stream流,放到后面讲,我们先来看看Java8中接口的特性,在日常开发中也挺有用
1:原有接口的弊端
为了更好的理解新的接口特性,就先简单看看之前存在的弊端。
我们日常的开发习惯总是先定义interface接口,再撰写对应的实现类
可是这种方式有种很大的问题,就是代码不好维护,因为接口中定义的方法,实现类需要全都将其实现
比如会员等级权益的业务中,不同等级的会员具备不同权限。要开发这个功能,通常会先定义一个接口
public interface IMemberEquityService {
/*
* 权益一
* */
void equity1();
/*
* 权益二
* */
void equity2();
}
正因为不同等级的会员,能享受到权益有所不同,如果只弄一个实现类,就需要在一个方法里,通过大量if来区分实现不同的权限,这无疑会让代码变得臃肿不堪,更好的做法是借助Java的多态特性,将不同等级的会员权益,创建不同的实现类来编写具体逻辑
/**
* 普通会员权益实现类
*/
public class MemberEquityServiceImpl implements IMemberEquityService {}
/**
* 高级会员权益实现类
*/
public class VIPMemberEquityServiceImpl implements IMemberEquityService {}
/**
* 超级会员权益实现类
*/
public class SVIPMemberEquityServiceImpl implements IMemberEquityService {}
通过这种方式,能让代码更便于维护,看起来也更加优雅。
不过在享受好处的同时,也存在一个致命缺陷,即接口内新增定义了某个权益时,比如新增一个equity3()方法,根据Java的接口特性,所有实现类必须实现新增的方法,但是这个权益不一定所有等级的会员都具备,咋整?
为了接口的可拓展性,在以往的JDK版本中,我们不得不在中间加入一个abstract抽象类:
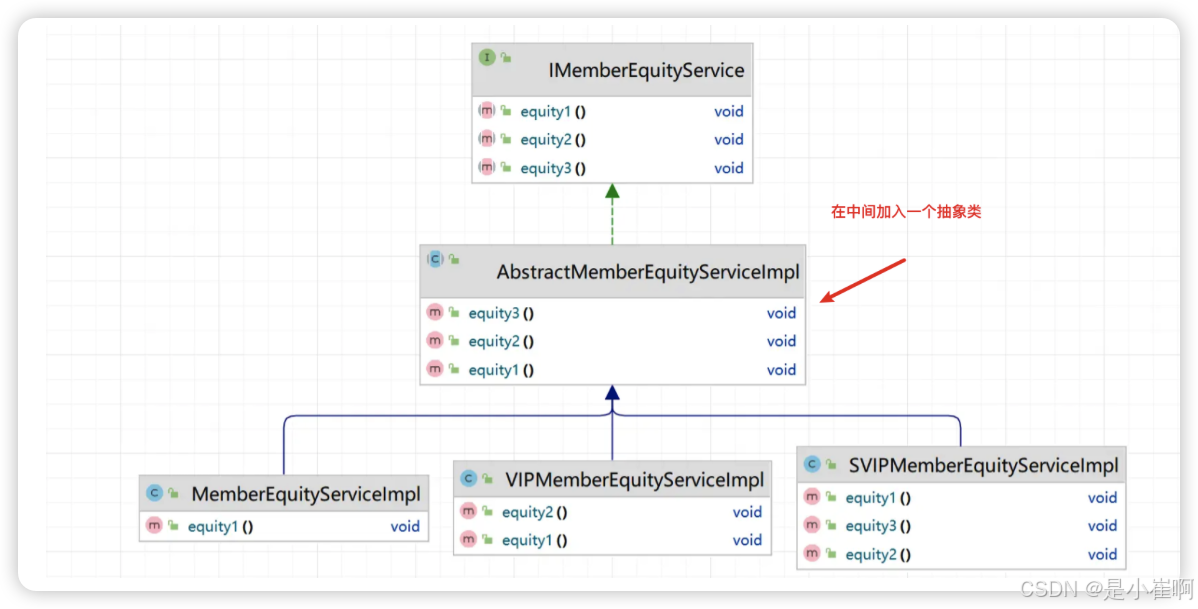
通过这种设计,当顶层接口新增了某个方法时,作为底层的业务实现类,不一定需要强制实现此方法,只需要在抽象类中实现即可。
如果需要实现该方法的业务实现类,重写父类(抽象类)实现的方法即可。
其实这也是Java8之前,所有框架,包括JDK源码在内都在使用的一种方式,如果不这么做,比如JDK官方想对Collection接口新增一个方法,那就需要修改它的所有实现类,这听起来就非常恐怖。
正因如此,中间包一层抽象类,这种方式可以最大程度上保证接口灵活性
这同样是为什么在看各种源码时,会发现为什么有那么多开头以Abstract……命名类的原因。
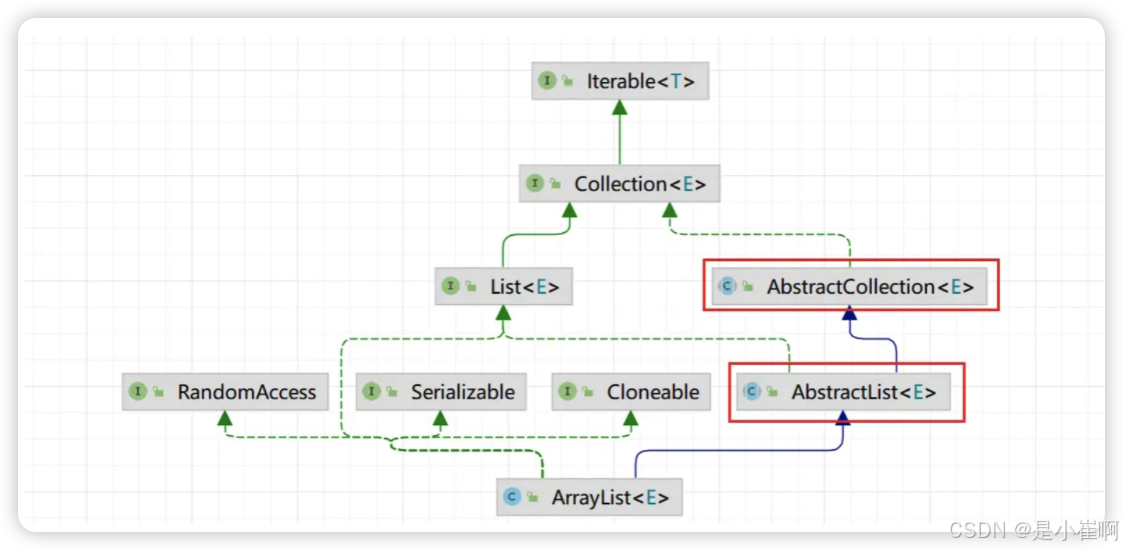
Java接口这种特性在之前的版本中,令人饱受折磨
而到了Java8以后,就算你设计时没包一层抽象类,也大可不必担心,因为有了两个新的接口特性:接口默认方法与静态方法。
2:新特性-接口默认方法
在接口中,使用default关键字修饰的方法称之为接口默认方法。
默认方法一定要有默认实现,也就是直接在接口里实现方法体,当一个类实现该接口时,既可以选择直接继承它,也选择重新实现将其覆盖
public interface IMemberEquityService {
/*
* 权益四
**/
default void equity4() {
System.out.println("会员权益4的默认实现");
}
}
默认方法允许在接口中添加新的方法,而无需修改实现该接口的类,这对扩展现有接口或添加新功能特别有用
因为接口中提供了默认的实现,所以不必改动所有子类实现,能最大程度上保持与已有代码的兼容性
当然,默认方法除开可以提升接口拓展的灵活性外,在日常开发中还有另外的玩法:
@Repository
public interface XxxMapper {
/*
* 查询分页数据
* */
PageVO<?> selectPage(……);
/*
* 查询分页数据
* */
default xxx selectXxx() {
// 基于selectPage()方法继续补全逻辑(不用写XML)
PageVO<?> page = this.selectPage(……);
// 省略其他代码……
}
}
比如使用MyBatis开发时,Dao层通常是接口结合XML的形式
如果你有个需求,可以基于前面已经写好的方法继续实现,这时就能直接通过默认方法来继续补齐逻辑~
3:接口静态方法
在接口里用static修饰的方法称为接口静态方法,它的作用和默认方法的逻辑类似,如下:
public interface IMemberEquityService {
/**
* 权益5
*/
static void equity5() {
System.out.println("会员权益5的默认实现");
}
}
不过和默认方法的区别在于:静态方法属于接口本身,而默认方法属于具体的实例,静态方法的调用方式如下
IMemberEquityService.equity5(); // 直接类名.静态方法名
由于静态方法与接口实现类无关,因此可以在不创建接口实例的前提下被调用。
使用场景:接口静态方法一般用来实现一些常用的、与实例无关的功能,比如与接口相关的工具方法或辅助方法等。
接口有了默认方法和静态方法,可以让你的代码变得更优雅
比如某个接口方法在所有子类中的实现都一样,这就可以直接将这种可共用的逻辑,抽象到接口中来定义成默认方法,从而减少子类中的冗余实现。
二:优雅使用Java8的前置知识
Java8使用的三个前置知识就是:Lambda表达式、函数式接口、函数引用
1:Lambda表达式
在JDK1.8之前,一个方法能接收的入参类型,都只能是“值类型”,要么是基本数据类型,要么就是一个引用对象
如果想要将另一个方法作为入参怎么办?
在之前的版本中只能通过匿名内部类来拐着弯实现,不过匿名内部类依赖于接口,所以先定义一个接口
public interface TestCallback {
/*
* 回调方法
* */
void callback(ZhuZi zhuZi);
}
// 如何将这个回调方法作为入参传递给一个方法
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private Long id;
private String name;
}
public class Test {
/*
* 创建完对象后,触发指定的回调逻辑
* */
public static void create(long id, String name, TestCallback testCallback) {
// id & name 构建对象
User user = new User(id, name);
// 触发回调
testCallback.callback(user);
}
/**
* 将接口作为方法的参数,然后实现就可以了
*/
public static void main(String[] args) {
Test.create(88888888, "崔海达", new TestCallback() {
@Override
public void callback(User user) {
System.out.println("我是创建完对象后的回调,创建的对象为:" + user);
}
});
}
}
/*
* 执行结果:
* 我是创建完对象后的回调,创建的对象为:User(id=88888888, name=崔海达)
**/
来看上面这个回调事件的例子,其中的TestCallback是一种动作,我们真正关心的只有callback()方法里的逻辑而已
可是Java中不支持直接传递函数,所以为了将这个回调方法传递给要执行的create()方法,必须得new一个匿名内部类,写起来费劲不说,还不美观!
到了JDK1.8,就可以直接用Lambda表达式来代替,上述代码可以优化成:
public static void main(String[] args) {
Test.create(88888888, "崔海达", user -> {
System.out.println("我是创建完对象后的回调,创建的对象为:" + user);
});
}
这样写起来更简单,看起来更优雅!
不过值得注意的是,Test.create()方法的第三个入参,仍然是TestCallback这个接口类型(为什么可以这样呢,后面说)
1.1:Lambda表达式的语法
Lambda表达式,是JDK1.8从函数式编程语言中“借鉴”而来的特性,Lambda允许将一个函数作为方法的入参:
而Lambda表达式的基础语法由三部分组成:
()包裹的参数列表、–>符号、{}包裹的函数体。
Test.create(88888888, "崔海达", (User user) -> {
System.out.println("我是创建完对象后的回调,创建的对象为:" + user);
});
User代表是入参的类型,user代表是方法的参数名,这个名字你想叫啥就叫啥。->是Lambda表达式的固定语法,这个是固定的语法糖,不能改变成→、_>、=>或其他箭头。- 最后就是
{}这对花括号包裹的代码块,实际上就是具体要执行的函数体,就跟方法体一样。
掌握上述基本语法后,下面再来看几类变种写法
无参数的
lambda写法:
/**
* 无参数回调
*/
public interface NoArgsCallback {
void callback();
}
public class Test {
public static void noArgs(NoArgsCallback noArgsCallback) {
noArgsCallback.callback();
}
public static void main(String[] args) {
Test.noArgs(() -> {
System.out.println("我是无参数的lambda语法……");
});
}
}
注意看上面无参数的lambda写法,和之前的唯一区别在于:如果对应的函数没有入参,那么参数列表部分就用()小括号代替即可
多参数的Lambda写法:
/**
* 多参数回调
*/
public interface MultipleArgsCallback {
// 多参数
void callback(int arg1, String arg2);
}
public class Test {
public static void multipleArgs(int arg1, String arg2, MultipleArgsCallback multipleArgsCallback) {
multipleArgsCallback.callback(arg1, arg2);
}
public static void main(String[] args) {
Test.multipleArgs(1, "崔海达", (int a, String b) -> {
System.out.println("我是" + b + ",我是序号" + a);
});
}
}
与无参数的写法对比,如果函数存在多个入参,只需要用()将参数列表包起来、多个参数用,逗号隔开就行
函数存在多少个入参,这里就需要定义多少个参数,顺序与函数定义的入参列表一一对应。
只有一个参数:
Test.create(88888888, "崔海达", (User user) -> {
System.out.println("我是创建完对象后的回调,创建的对象为:" + user);
});
// 可以优化为:
Test.create(88888888, "崔海达", user ->
System.out.println("我是创建完对象后的回调,创建的对象为:" + user)
);
可以发现:如果参数只有一个,所以可以省略();如果函数体也只有一行代码,{}也可以省略不写
最关键的是参数竟然可以不用声明类型了!这是什么原因呢?这跟lambda的原理有关系。
1.2:Lambda表达式原理浅谈
尽管Java身为强类型限制的语言,可在上面的lambda表达式例子中,参数列表可以不强制声明参数类型
首先要明白,lambda表达式在Java中的实现,本质上跟匿名内部类很接近,只不过是将匿名内部类的写法简化了而已。
同时,注意观察上面无参、单参、多参这三个例子,大家就会发现,每个例子中都需要单独定义一个接口,并且每个接口内只有一个方法,这种接口也被称之为函数式接口。
正因如此,我们写的每一个lambda表达式,实际上就是在实现这个函数式接口的抽象方法。
lambda表达式能在Java环境中正常运行,这得益于Java8的类型推导机制,以之前的例子作为说明
// 接口定义
public interface TestCallback {
void callback(User user);
}
// 业务方法
public static void create(long id, String name, TestCallback testCallback) {
User user = new User(id, name);
testCallback.callback(user);
}
// lambda表达式
Test.create(88888888, "崔海达", user ->
System.out.println("我是创建完对象后的回调,创建的对象为:" + user)
);
在执行lambda表达式时,Java编译器会基于上下文(即表达式所在的位置)推断其类型,怎么推断出来的?
其实很简单,上述create()方法的第三个入参为TestCallback类型,那么执行对应方法时,就自然能推断出对应位置的lambda是TestCallback接口的实现!
其次,Lambda表达式实现了接口里的有且仅有的一个抽象方法,那么编译器自然也能知道表达式就是callback()方法的实现。
最后再来看参数,其实逻辑也差不多,毕竟已经确定了Lambda表达式对应的接口方法,那么参数列表肯定就对应着接口方法的入参,这时再显式声明类型的意义也不大了,因为编译器可以直接推导出来。
在此之前Java一直是强类型语言,即编码时必须要为每个变量声明类型,所以Java8中的类型推导机制并不算强大
从上面也能感受出来,想用Lambda的前提是定义一个接口、接口里还只能有一个方法,只有这样编译器才能完成类型推导工作。
不过到了后续高版本的JDK中,类型推导机制得到了很大完善,如果有用过
JDK17、21等版本,就会发现写出来的代码充满了智能推导
2:函数式接口
归功于类型推导机制,我们可以在Java8中使用lambda来使得代码简洁化
不过经过上面分析会发现一个致命问题,每写一个Lambda表达式,就需要单独定义一个接口,如果真是这样,Lambda省下来的代码,又全都在接口定义上补回去了,这有点拆东墙补西墙的味道
JDK官方显然也想到了这一点,所以提供了一个java.util.function包
这里面定义了一系列可复用的、使用频率较高的函数式接口,以此避免日常开发过程中重复定义类似的接口,可到底啥叫做函数式接口?
函数式接口是Java8新增的一种接口定义
但说到底,函数式接口跟普通的接口写法都一样,唯一的区别在于:
函数式接口就是一个只具有一个抽象方法的特殊接口(可以定义多个方法,但其他的方法只能是default或static)。
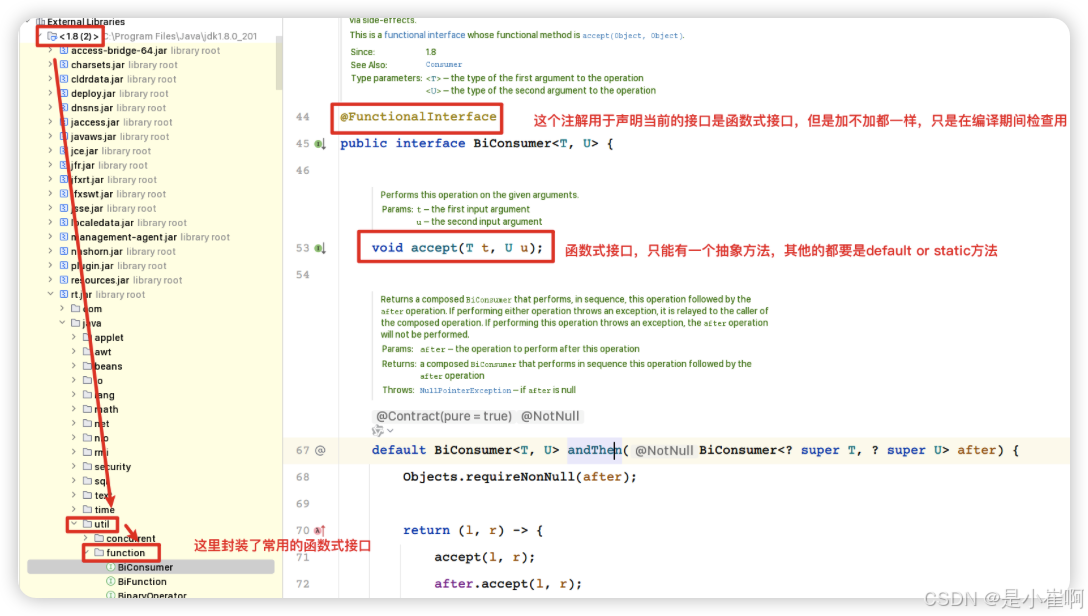
同时,也可以用@FunctionalInterface注解来将一个接口声明函数式接口,不过这个注解加不加,都不影响表达式的执行,仅仅只是起到编译校验的作用
@FunctionalInterface
public interface A {
void a(); // 这个接口只有一个抽象方法,所以编译能正常通过
default void b() {}
}
@FunctionalInterface
public interface B {
void a();
void b(); // 这个接口有多个抽象方法,所以编译会提示错误。
}
接着来看看java.util.function包下提供的函数式接口,这里列几个常用:
| 接口 | 描述 | 抽象方法 | 示例 |
|---|---|---|---|
| Supplier[供给] | 没有入参,返回一个结果【我什么都不要,还给你提供】 | get() | () -> {return 0;}; |
| Function[加工] | 单个入参,返回一个结果【你给我一个,我返给你一个】 | apply(t) | i -> {return i * 100;}; |
| Consumer[消费] | 单个入参,没有返回结果【你给我一个,但是我什么都不给你】 | accept(t) | str -> System.out.println(str); |
| Predicate[断言] | 单个入参,返回一个布尔值结果【我拿你入参进行断言判断】 | test(t) | str -> {return str.isEmpty();} |
当然,还有一系列和命名上述类似,但是以Bi……开头的函数式接口,例如BiFunction,其实这就是前面的增强版,只是支持两个入参罢了。
我们该如何使用JDK自带的这些函数式接口呢?假设要实现两个数字的加减乘除计算。
如果用之前的思维来实现:
- 要么就分别定义加、减、乘、除四个方法
- 要么就传一个运算符,在用
if或switch判断,以此实现不同的计算逻辑
但现在可以用lambda表达式来换一种实现方式:
/*
* 计算两个数字的方法
* 参数x, y分别就是两个要操作的数据
* BiFunction<Integer, Integer, Integer> calculateModel -> 函数式接口
* BiFunction<Integer, Integer, Integer> 前两个参数是入参,最后一个是返回结果,所以加减乘除都要对应的返回结果
* 只需要用lambda表达式,声明函数体就可以了
**/
public static int calculate(int x, int y, BiFunction<Integer, Integer, Integer> calculateModel) {
// 使用apply方法 -> lambda表达式
return calculateModel.apply(x, y);
}
/**
* 加减乘除
*/
public static void main(String[] args) {
int a = 4;
int b = 2;
// 加法计算
int result1 = calculate(a, b, (x, y) -> x + y);
System.out.println("两数之和:" + result1);
// 减法计算
int result2 = calculate(a, b, (x, y) -> x - y);
System.out.println("两数之差:" + result2);
// 乘法计算
int result3 = calculate(a, b, (x, y) -> x * y);
System.out.println("两数之积:" + result3);
// 除法计算
int result4 = calculate(a, b, (x, y) -> x * y);
System.out.println("两数之商:" + result4);
}
函数式接口和lambda表达式结合,能使得程序更加灵活,允许将一个函数作为参数传递
每种表达式的写法,就是某个函数式接口的实现,所以每个表达式都需要特定函数式接口进行对应
而function包中提供给我们这么多函数式接口,就是为了让我们写Lambda表达式更加方便。
但是作为表达式,它的写法、入参数量、返回结果多种多样,当遇到特殊情况没有现场的函数式接口时
这时就需要你自己定义特定的函数式接口,然后才能写对应的Lambda表达式。
3:函数引用
函数引用是Java提供的另一个语法糖,函数引用语法能让你的代码更简洁
3.1:方法引用
Consumer<String> print = (String param) -> {
System.out.println(param);
};
print.accept("崔海达");
看上述案例,这个表达式的作用为是打印接收到的参数,按之前说的简化方式,可以改成:
Consumer<String> print = param -> System.out.println(param);
但其实上述这种写法还能继续精简,变成下面这样:
Consumer<String> print = System.out::println;
这就是方法引用,为啥可以这么写呢?
因为System.out.println()方法的入参数量、入参类型、返回类型(Void),和当前lambda表达式的参数列表完全一致,因此可以直接简写为::
User user = new User();
// 正常:Consumer<String> setValue = name -> user.setName(name);
Consumer<String> setValue = user::setName; // setName 方法引用
setValue.accept("cui haida"); // name = "cui haida"
上面这个例子中,user是User类的一个实例对象,setName是这个实例的一个方法,写法为:实例对象名::实例方法名,这被称为实例对象的方法引用。
除开实例对象+实例方法可以这么写之外,类+静态方法、类+实例方法都是可以的,如下:
// 静态方法引用
// lambda写法:Function<Long, Long> f = x -> Math.abs(x);
Function<Long, Long> f = Math::abs; // 类名::静态方法名
Long result = f.apply(-3L);
// 实例方法引用
// lambda写法:BiPredicate<String, String> b = (x,y) -> x.equals(y);
BiPredicate<String, String> b = String::equals; // 类名::实例方法名
b.test("a", "b");
3.2:构造函数引用
前面静态方法、实例方法都可以简写,那么构造方法可不可以呢?答案也是可以,格式为:类名::new
//Function<Integer, StringBuffer> fun = n -> new StringBuffer(n);
Function<Integer, StringBuffer> fun = StringBuffer::new; // 构造函数引用
StringBuffer buffer = fun.apply(10);
Function接口的apply()方法接收一个Integer参数,并且返回一个StringBuffer对象
这与StringBuffer类的一个构造方法StringBuffer(int capacity)对应【一样的入参,出参 <- 可以引用】,所以同样可以简写。
除开基本的引用对象外,数组对象也是可以的:
// Function<Integer, int[]> fun = n -> new int[n];
Function<Integer, int[]> fun = int[]::new;
int[] array = fun.apply(10); // 表示创建一个长度为10的int数组。
三:Stream流最佳实践
Stream流可以说是Java8最大特性之一
Stream流是对JDK集合框架体系的增强,它提供了声明性、可并行化、函数式风格的集合操作,专注于对集合对象进行各种非常便利、高效的聚合操作
能用极少的代码,完成之前版本中需要写大量for、if才能完成的集合处理逻辑,能使代码更加清晰、简洁和易于维护
不过想用好Stream流的前提是熟悉lambda表达式,因为Stream需要借助于Lambda来提高编程效率和程序可读性
1:初识Stream流
在日常工作中我们也用过Stream,不过许多人仅仅只停留在基本的map()、collect()、filter()这类操作
Stream保留了函数式编程经典的链式编码风格,即可以将所有代码写成一行,通过.不断拼接各类流操作。
而实际上,Stream也是按流水线(管道)模式工作,如下:
Stream不同的API就好比工厂流水线上的一道道工序,处理集合内的元素时,就好比一个个货物,会挨个经过各道工序处理
当然,既然是流水线,那肯定有开始和结束的“工序”,所以Stream流中的API总共分为三大类:
- 开始操作:好比流水线的开头,创建一个
Stream流; - 中间操作:
Stream流中间的工序,经过一个中间函数后,流并不会中断,可以继续经过其他工序 - 终止操作:类似于流水线的最后一道工序,经过本道工序后,流就结束了
1.1:开始操作
创建一个Stream流被称为获取数据源,而获取的方式有很多,最常用的就是从集合或数组中生成:
| 创建方式 | 说明 |
|---|---|
Collection.stream() | 通过Collection的子类创建流 |
Collection.parallelStream() | 通过Collection的子类创建并行流 |
Arrays.stream(array) | 通过数组创建流 |
Stream.of(T t) | 通过Stream类的api创建流 |
Stream.concat(Stream a, Stream b) | 合并两个流为一个新的流 |
Stream.empty() | 创建一个没有任何元素的空流 |
所谓的创建流,就是获得一个Stream对象,当然还有另外的方式,但是其他的方式使用的场景不多。
1.2:中间操作
当Stream流对象被创建出来后,在后面就可以跟零或多个中间操作
这些中间操作可以对流中的元素进行处理,处理后又会返回一个新的流交给下道工序使用,API清单如下:
| 方法 | 描述 |
|---|---|
filter() | 可以按照指定要求过滤出符合条件的元素 |
limit() | 截取操作,只保留流中前N个元素 |
skip() | 跳跃操作,跳过流中前N个元素 |
map() | 映射操作,将流中每个元素转变为其他类型 |
flatMap() | 多重映射,同map()作用,但是一对多映射 |
distinct() | 去重操作,相同元素只保留流中出现的第一个 |
peek() | 遍历操作,类似于循环,但不会终止流 |
sorted() | 排序操作,可以根据指定规则对流内元素排序 |
其实中间操作还可以细分为有状态、无状态两类操作,所谓的有状态,就是每处理一个元素,必须要知道流中其他元素的状态,如sort()、distinct()方法
无状态即不需要知道流中其他元素的状态,每个元素都可以独立处理,如map()、filter()方法
总之,如果这个方法的作用机理是当前元素和其他元素有关联,就是有状态的,反之就是没有状态的
Stream流中所有中间操作都是惰性的,比如ids.stream().sorted()这行代码,并不会触发流的遍历动作,只有真正出现终止操作时才会遍历处理流
public static void main(String[] args) {
List<Integer> idList = Arrays.asList(2, 3, 1, 5, 4);
idList.stream().sorted();
System.out.println(idList); // 还是[2, 3, 1, 5, 4],因为流没有终止操作,不会执行
}
1.3:终止操作
厂里打螺丝的流水线也会有尽头,Stream流亦不例外,而会导致流结束的操作,则被称之为终止操作。
切记!一个流只能执行一个终止操作,当执行一个终止操作后,流对象就走到了生命尽头,所以终止操作一定要是流的最后一个动作!
同时切记,终止操作的出现,才会触发流真正的遍历过程,并生成最终的结果
| 方法 | 描述 |
|---|---|
foreach() | 遍历流中的每一个元素 |
forEachOrdered() | 按顺序遍历流中的每一个元素 |
iterator() | 将流对象转变为迭代器对象 |
toArray() | 将流转变为数组 |
collect() | 将流转变为指定的集合对象,业务中最常用 |
anyMatch() | 判断流中是否有一个元素满足给定条件 |
allMatch() | 判断流中所有元素是否都满足给定条件 |
noneMatch() | 判断流中所有元素是否都不满足给定条件 |
reduce() | 对流中的所有元素执行累积操作 |
findAny() | 获取流中任意一个满足条件的元素 |
findFirst() | 获取流中第一个满足条件的元素 |
count() | 统计流中最终的元素数量 |
max() | 获取流中最大的元素 |
min() | 获取流中最小的元素 |
同样值得说明的是,终止操作也可以分为短路、非短路两类
- 短路操作是指不需要处理完所有元素就可以结束流,如
findFirst()、anyMatch()方法;短路操作的效率更高,毕竟无需遍历流中所有元素 - 非短路操作则需要完整处理整个流,如
allMatch()、foreach()等
终止操作就是流的最后一道工序,执行完后会自动关闭流,无需手动关闭
Stream<Panda> stream = pandas.stream();
long count = stream.count(); // 此时stream流已经关闭了
Object[] array = stream.toArray(); // 再次通过stream.xxx已经报错了
1.4:IDEA中调试
IDEA 2019之后支持Stream-Trace功能,能清晰观察到每一步操作的具体过程(也支持链路式断点,即写在一行里也支持分开打断点)
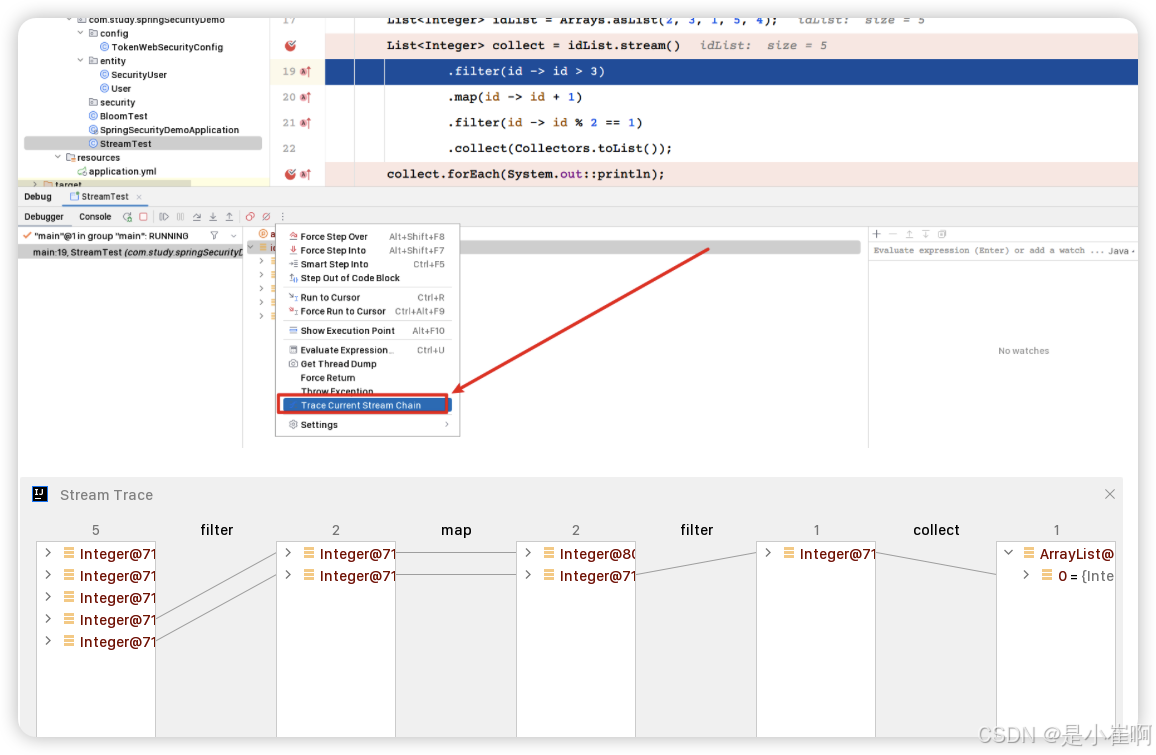
2:实战演练一下
/*
* 熊猫实体类
**/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Panda {
// 熊猫编号
private Long id;
// 熊猫姓名
private String name;
// 熊猫性别,0:雄性,1:雌性
private Integer sex;
// 熊猫年龄
private Integer age;
// 熊猫身高
private BigDecimal height;
}
/*
* 熊猫视图类
**/
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode(callSuper = true)
public class PandaVO extends Panda {
// 最喜欢的食物
private ZhuZi favoriteFood;
}
2.1:基本打印,计数示例
先来看个简单的,就是打印输出pandas集合中的每个元素,用stream一行代码搞定:
pandas.stream().forEach(panda -> {
System.out.println(panda);
});
// 或者可以简化为:
pandas.stream().forEach(System.out::println);
这就是stream+lambda的简洁性,一行代码清晰干脆。
其实中间的.stream()也可以去掉,因为Java8中为所有集合类都增加了forEach()方法。
统计pandas集合中雄性大熊猫的数量:
long malePandaNum = pandas.stream()
.filter(panda -> 0 == panda.getSex())
.count();
这里的filter()相当于之前的if,只有满足给定条件的元素,才会被转接给下道工序
而count()则是对每个元素计数,最终得到了符合条件的元素数量
再来继续加深印象,新的需求要获得雌性大熊猫中最小的年龄,实现如下:
Optional<Panda> femalePandaMinAge = pandas.stream()
// 先过滤出所有雌性大熊猫
.filter(panda -> 1 == panda.getSex())
// 再根据年龄字段求出最小的值
.min(Comparator.comparing(Panda::getAge));
这也是个很简单需求,那如果我想要获取所有雌性大熊猫,并保存成另一个集合呢?
List<Panda> femalePandas = pandas.stream()
// 先找出所有雌性大熊猫
.filter(panda -> 1 == panda.getSex())
// 将过滤后的元素输出到另一个集合
.collect(Collectors.toList());
2.2:map & flatMap
在平时工作中,如果我们要批量提取集合中的某个字段去做批量查询,这该怎么办呢?如下:
List<Long> pandaIds = pandas.stream()
// 只保留熊猫的编号
.map(Panda::getId)
// 将得到的编号统一输出到另一个集合
.collect(Collectors.toList());
上面这种方式能十分快捷的将一个集合中,所有元素的某个字段值提取出来。
当然,map()的作用是映射,你也可以将Panda对象转变成其他对象,比如开发中的实体类集合转VO类集合
// 定义一个竹子实例
ZhuZi zhuZi = new ZhuZi(1L, "黄金竹子");
List<PandaVO> pandaVos = pandas.stream()
// 先过滤出所有雌性大熊猫
.filter(panda -> 1 == panda.getSex())
// 再将过滤后的每个Panda对象,转变成PandaVO对象
.map(panda -> {
// 这里可以转变成任意类型的对象
PandaVO pandaVO = new PandaVO();
pandaVO.setId(panda.getId());
pandaVO.setName(panda.getName());
pandaVO.setSex(panda.getSex());
pandaVO.setAge(panda.getAge());
pandaVO.setHeight(panda.getHeight());
pandaVO.setFavoriteFood(zhuZi);
return pandaVO;
})
// 将每个转变后的PandaVO对象放入另一个集合
.collect(Collectors.toList());
上面就是过滤+映射结合的例子,其实并不难理解,主要搞明白“映射”的概念即可
而flatMap()要求返回的是stream流对象,所以需要将List转变成流,最后collect()时,会拼接每个流对象,然后输出到一个集合
List<Panda> newPandas = pandas.stream()
// 进行一对多映射处理
.flatMap(panda -> {
// 先创建一个新的Panda集合(可以是其他类型)
List<Panda> pandaList = new ArrayList<>();
// 往集合里添加元素(这里实际可以是多个)
pandaList.add(panda);
// 将新的集合转变成stream流
return pandaList.stream();
})
// 将所有元素输出到新的集合中
.collect(Collectors.toList());
2.3:peek
好了,再来看个需求,有时候我们在处理集合数据时,可能想先遍历一次所有元素,为每个元素进行一些特殊处理后,再执行其他操作。
但map()方法会改变对象类型,forEach()方法会导致流结束掉,这时就不得不再开启一个新的流,有没有好方法呢?有,来看:
pandas.stream()
// 遍历处理每个元素,给每个熊猫的姓名加个前缀
.peek(panda -> {
panda.setName("熊猫:" + panda.getName());
})
// 再遍历打印输出每个元素
.forEach(System.out::println);
如果存在上面我说的需求,就可以使用peek()方法,该方法属于中间操作,不会导致流关闭、不会改变元素类型
一定要注意,这是一个中间方法,如果不写终止操作,不会使得peek执行:
pandas.stream().peek(System.out::println); // 这个不会执行sout
2.4:其他API介绍
/*
* 获取集合中为雌性、且年龄小于3的前两只熊猫
**/
List<Panda> limitPandas = pandas.stream()
// 过滤掉雄性、并且年龄小于3的熊猫
.filter(panda -> 1 == panda.getSex() && panda.getAge() > 3)
// 只保留前两个符合条件的元素
.limit(2)
// 将得到的元素输出到另一个集合
.collect(Collectors.toList());
/*
* 跳过前两只熊猫,并根据年龄排序(倒序)
*/
List<Panda> skipDescPandas = pandas.stream()
// 跳过前两只熊猫
.skip(2)
// 根据年龄字段排倒序(升序去掉.reversed()即可)
.sorted(Comparator.comparing(Panda::getAge))
// 输出到另一个集合
.collect(Collectors.toList());
/*
* 如果雄性熊猫中,有一只年龄大于3岁,则输出一句话
**/
boolean flag = pandas.stream()
// 过滤掉雌性熊猫
.filter(panda -> 0 == panda.getSex())
// 判断雄性熊猫中是否有一只年龄大于3岁
.anyMatch(panda -> panda.getAge() > 3);
/**
* 求和所有雌性熊猫的身高
* 有人或许想着用sum()方法,但这个方法只存在于IntStream这类流对象、或者先调用mapToInt()这类方法才行
* 但目前身高字段是BigDecimal类型,这个类型也是开发中经常用到的,这时我们就可以用到reduce()方法对所有元素执行积累运算
*/
BigDecimal femaleTotalHeight = pandas.stream()
// 过滤出所有雌性大熊猫
.filter(panda -> 0 == panda.getSex())
// 只保留年龄字段
.map(Panda::getHeight)
// 对年龄字段求和(第一个参数为默认值,也可以理解成初始值,没有元素时就返回这个)
.reduce(BigDecimal.ZERO, BigDecimal::add);
3:Collectors转换器
Stream中collect()操作大量使用到了Collectors这个类,这个类比较大,能帮我们实现特别多的需求
Collector也叫收集器,主要配合collect方法一起使用,可以对流中的元素进行各种汇总操作,如转换、统计、分组、分区等等
这是Stream流中最重要的一个类,下面来看看它的API,
元素汇总:
| 方法 | 说明 |
|---|---|
toCollection() | 将流的元素汇总成一个Collection集合 |
toList() | 将流的元素汇总成一个List集合; |
toSet() | 将流的元素汇总成一个Set集合; |
toMap() | 将流的元素汇总成一个Map集合; |
toConcurrentMap() | 将流的元素汇总成一个ConcurrentMap集合。 |
数据统计相关方法:
| 方法 | 说明 |
|---|---|
counting() | 统计流中的元素的数量 |
summingInt() | 对流内int元素求和(类似方法还有~Long()、~Double()) |
averagingInt() | 对流内int元素求平均值(类似方法还有~Long()、~Double()); |
maxBy() | 获取流内元素指定字段的最大值 |
minBy() | 获取流内元素指定字段的最小值 |
summarizing() | 汇总统计流内int元素的数量、综合,以及最大、最小、平均值 |
分组、分区和连接
| 方法 | 说明 |
|---|---|
groupingBy() | 根据指定字段对流内的元素进行分组 |
partitioningBy() | 根据某个条件将流内所有元素分成两个区 |
joining() | 使用给定的字符,将流内所有元素连接成一个字符串 |
3.1:元素汇总示例
所谓的元素汇总,即是指将流内元素转换成特定集合,toCollection()、toList()、toSet()这三个不讲了,参数都不用传直接调用即可,特别简单
下面重点来看转Map。
日常开发中,我们经常会遇到一个需求:以集合元素的某个字段作为Key,将List集合转换为Map集合,而这个需求在Stream里面很容易就能实现:
/*
* 以熊猫编号作为Key,熊猫姓名作为Value,将pandas集合转变成Map
**/
Map<Long, String> pandaIdMap = pandas.stream()
// 第一个参数代表Key,第二个参数代表Value
.collect(Collectors.toMap(Panda::getId, Panda::getName));
那再变换一个需求,我现在想以熊猫编号作为Key,整个熊猫对象作为Value
Map<Long, Panda> pandaMap = pandas.stream()
.collect(Collectors.toMap(Panda::getId, Function.identity()));
这段代码和前一段的区别就是,代表Value的参数不一样了
Function是个函数式接口,Function.identity()表示传入什么就返回什么,而流中每个元素都是Panda对象,所以返回的也是panda对象

再来看个问题,如果我要以年龄作为Key,整个对象作为Value呢?
Map<Integer, Panda> pandaAgeMap = pandas.stream()
.collect(Collectors.toMap(Panda::getAge, Function.identity()));
试着运行一下这句代码,会发现执行报错提示Duplicate key,为什么?因为年龄中有重复的值,所以Key冲突了,这怎么办?
Map<Integer, Panda> pandaMap = pandas.stream()
.collect(Collectors.toMap(
// 以年龄作为Key
Panda::getAge,
// 以整个对象作为Value
Function.identity(),
// 如果出现冲突,用新值覆盖老值
(oldPanda, newPanda) -> newPanda)
);
这时需要我们传入第三个条件,当出现键冲突时,用新值覆盖老值即可,当然,你要保留老值的话,箭头后面填oldPanda即可
3.2:数据统计示例
这里就快速过一下,毕竟比较简单:
/*
* 求和流内的元素(collect()前面可以拼其他API)
**/
Long count = pandas.stream().collect(Collectors.counting());
/*
* 求和所有雌性熊猫的总年龄
**/
Integer totalAge = pandas.stream()
// 过滤出所有雌性熊猫
.filter(panda -> 1 == panda.getSex())
// 提取出每只熊猫的年龄
.map(Panda::getAge)
// 对每只熊猫的年龄进行求和
.collect(Collectors.summingInt(age -> age));
/*
* 求出所有雄性熊猫的平均年龄
* */
Double avgAge = pandas.stream()
.filter(panda -> 0 == panda.getSex())
.map(Panda::getAge)
// 对熊猫的年龄进行求平均值
.collect(Collectors.averagingInt(age -> age));
/*
* 获取年龄最大的熊猫
* */
Optional<Panda> maxAge = pandas.stream().
// 根据年龄字段先排序,接着获取年龄最大的熊猫
collect(Collectors.maxBy(Comparator.comparing(Panda::getAge)));
/*
* 获取所有熊猫年龄的汇总统计数据
* */
IntSummaryStatistics statistics = pandas.stream()
.map(Panda::getAge)
.collect(Collectors.summarizingInt(stats -> stats));
3.3:连接、分组与分区示例
在平时我们或许需要将一个Long集合转变成每个元素以,逗号隔开的字符串,这时就会用到循环拼接,而Stream中却很简单
/*
* 将所有熊猫ID以,拼接成字符串
* */
String pandaIds = pandas.stream()
// 先将熊猫编号转为字符串
.map(panda -> Long.toString(panda.getId()))
// 再使用收集器为每个元素之间拼接,逗号
.collect(Collectors.joining(","));
这个很简单就不过多解释,下面来看看类似于SQL里的group分组,比如根据熊猫年龄分组:
Map<Integer, List<Panda>> ageGroup = pandas.stream()
// 对流内元素进行分组
.collect(Collectors.groupingBy(
// 根据年龄字段分组
Panda::getAge,
// 相同组的元素归纳到一个集合
Collectors.toList())
);
套入前面的统计方法,我们还能得出每个分组的数量:
Map<Integer, Long> ageGroupCount = pandas.stream()
.collect(Collectors.groupingBy(
// 根据年龄字段分组
Panda::getAge,
// 统计每组的元素数量
Collectors.counting())
);
最后再聊下分区,比如根据熊猫的性别分区,代码如下:
Map<Boolean, List<Panda>> pandaPartition = pandas.stream()
// 根据熊猫性别分区,sex == 0代表雄性(true),反之为false
.collect(Collectors.partitioningBy(panda -> 0 == panda.getSex()));
这个分区和分组有点类似,只不过是个Boolean类型的Key,意味着最多就两个分区,理解了分组,就自然理解了分区
4:Stream并行流
并行流,说人话就是:用多线程去执行某个流操作
List<Panda> femalePandas = pandas.parallelStream()
.filter(panda -> 1 == panda.getSex())
.collect(Collectors.toList());
也就是把stream()方法换成parallelStream()就可以了,你无需多写一行多线程的代码,并发流模式就能够充分利用多核处理器的优势
并行流底层会使用Fork/Join线程池来拆分任务和加速处理过程。
正因如此,Stream可以算是一个函数式语言 + 多核时代综合影响出现的产物,对比传统的循环、迭代器处理集合数据,Stream流显得更为现代化与高效。
不过使用parallelStream要注意的问题是:它底层是使用的ForkJoin,而ForkJoin里面的线程依赖于ForkJoinPool来运行
在Java8中为ForkJoinPool添加了一个静态通用线程池(commonPool),这个线程池用来处理那些没有被显式提交到任何线程池的任务。
它拥有的默认线程数量等于运行计算机上的处理器数量
为此要记住,目前Java进程里所有使用parallelStream的地方,实际上是公用的同一个ForkJoinPool!这意味着什么?
意味着虽然parallelStream提供了更简单的并发执行的实践,但并不意味着更高的性能,在某些场景下反而会存在风险。
比如CPU资源紧张,并行流只会加剧CPU资源竞争,而不会带来性能提升。
又或者大量底层都使用到了并行流或者CompletableFuture,那公共线程池反而会因为任务堆积导致执行缓慢。
四:空指针天敌-Optional
空指针异常(NPE),是程序开发中出现频次最高的Bug,什么情况下会出现空指针异常呢?
User user = null;
System.out.println(user.getName());
上面这段代码就会抛出空指针异常,因为user这个变量指向的是null,而getName()方法又属于实例对象的成员,实例对象都不存在,null.getName()自然会抛出空指针异常。
为了避免NPE出现,我们在编码过程中,每次使用不确定的数据来源时,如数据库查询结果、外部传入的参数等,都得先套个if判断。
以前,Google公司著名的Guava项目,为了尽量减少空值判断的if数量,在该类库中引入了Optional类,通过使用检查空值的方式来防止NPE。受到Guava的“启发”,Java8中也吸纳了Optional类作为标准JDK的一部分
Optional实际上是个容器,它可以保存一个指定类型的值,或者保存null
Optional提供了许多避免、检测空值的API,从而减少显式进行空值检测的if数量,先来看看创建Optional对象的方法
| 方法 | 描述 |
|---|---|
Optional.of(T value) | 创建一个Optional对象,值不能为空,否则会抛出NPE |
Optional.ofNullable(T value) | 创建一个Optional对象,允许值为空 |
Optional.empty() | 创建一个代表空的Optional对象 |
再来看看Optional的其他常用方法:
| 方法 | 描述 |
|---|---|
isPresent() | 判断op对象是否包含值,有值返回true |
ifPresent(Consumer<? super T> consumer) | 如果op对象包含值,则执行给定lambda表达式 |
filter(Predicate<? super T> predicate) | 过滤op对象的值是否满足给定条件 |
map(Function<? super T, ? extends U> mapper) | 将op对象包含的值,转变为新的值 |
flatMap(Function<? super T, Optional< U > > mapper) | 作用同map(),更强大,支持一对多 |
orElse(T other) | 如果op对象的值为空,则返回给定的other对象 |
orElseGet(Supplier<? extends T> other) | 如果op对象的值为空,则执行给定的lambda并返回 |
orElseThrow(Supplier<? extends X> exceptionSupplier) | 如果值为空,则执行lambda抛出给定异常 |
之前面对NPE问题,可能需要这么解决
/*
* 获取名字长度
* */
public static int getNameLength(ZhuZi zhuZi) {
if (Objects.nonNull(zhuZi)) {
String name = zhuZi.getName();
if (name != null && !name.isEmpty()) {
return name.length();
}
}
return 0;
}
现在使用Optional则可以改成:
public static int getNameLength(ZhuZi zhuZi) {
return Optional.ofNullable(zhuZi)
.map(ZhuZi::getName)
.filter(name -> !name.isEmpty())
.map(String::length)
.orElse(0);
}
其实这样看起来代码量差不多,不过好处在于Optional可以一行代码写完,更符合函数式编程的风格。
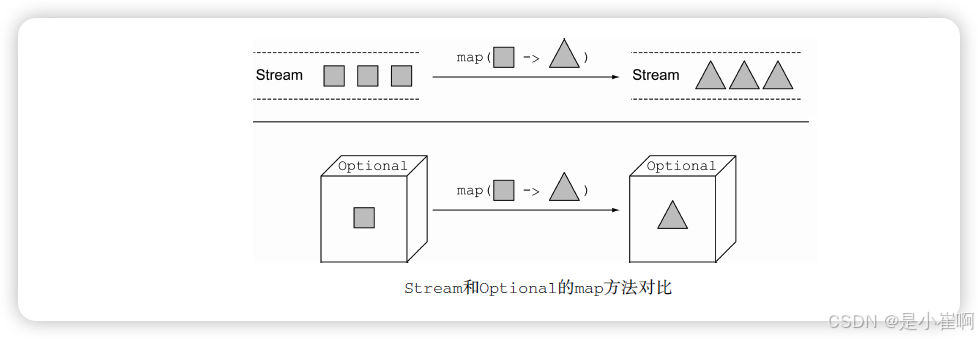
当然,有时候还会有些作用,比如下述场景:
public ZhuZi getZhuZiByXXX() {
// 从数据库根据条件查询数据集合
ZhuZi zhuZi = db.selectByXXX();
return Optional.ofNullable(zhuZi).orElse(new ZhuZi());
}
比如这个从数据库查询数据的场景,如果数据库未查询到数据,就会返回一个null,这时外部直接使用就会出现NPE,为此,我们通过Optional包一层,如果为空则手动new一个对象出去,方能有效避免NEP出现
不过这种方式治标不治本,毕竟new出去的ZhuZi对象,所有字段都是null,外部使用时,一不留神或许还会继续出现NEP,所以Optional只适用于部分场景,日常开发中要不要用,就取决于自己的习惯
为什么还是要慎用Optional呢?因为如果不清楚其中的关系,还是会被绕进去导致代码报错
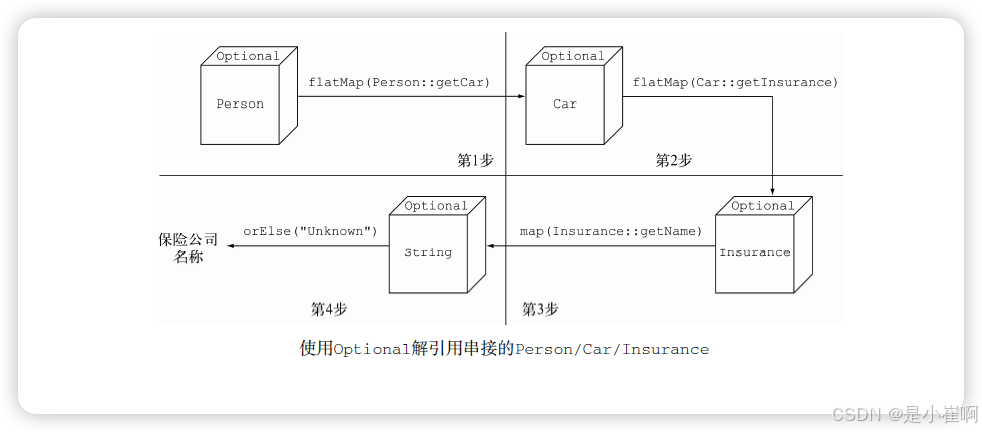
public String getCarInsuranceName(Person person) {
return person.getCar().getInsurance().getName();
}
你的第一反应可能是我们可以利用map重写之前的代码,
Optional<Person> optPerson = Optional.of(person);
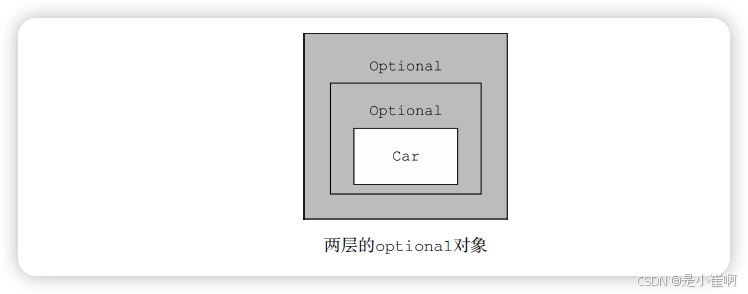
Optional<String> name = optPerson.map(Person::getCar) // 这个getCar返回的是Optional<Car>,使得map结果是Optional<Optional<Car>>
.map(Car::getInsurance) // 它对getInsurance的调用是非法的,因为最外层的optional对象包含了另一个optional对象的值,而它当然不会支持getInsurance方法
.map(Insurance::getName);
不幸的是,这段代码无法通过编译。
optPerson是Optional<Person>类型的变量, 调用map方法应该没有问题。
但getCar返回的是一个Optional<Car>类型的对象,这意味着map操作的结果是一个Optional<Optional<Car>>类型的对象。
因此,它对getInsurance的调用是非法的,因为最外层的optional对象包含了另一个optional对象的值,而它当然不会支持getInsurance方法。
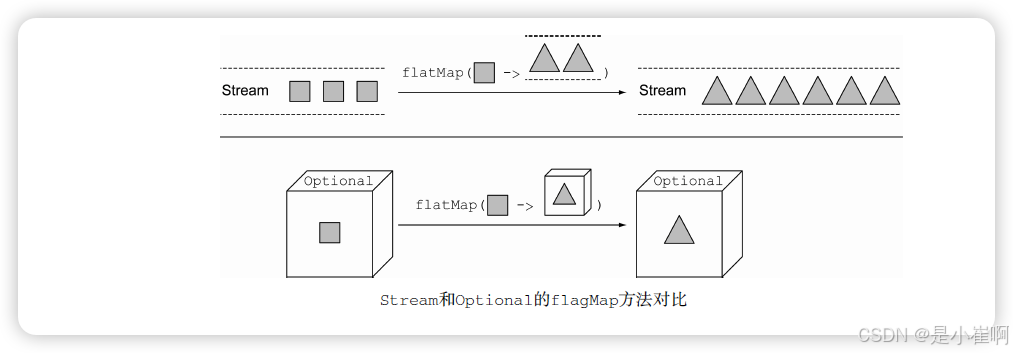
flatMap方法解决这个问题。
使用流时,flatMap方法接受一个函数作为参数,这个函数的返回值是另一个流。
这个方法会应用到流中的每一个元素,最终形成一个新的流的流。但是flagMap会用流的内容替换每个新生成的流。
换句话说,由方法生成的各个流会被合并或者扁平化为一个单一的流。这里你希望的结果其实也是类似的,但是你想要的是将两层的optional合并为一个。
public String getCarInsuranceName(Optional<Person> person) {
return person
.flatMap(Person::getCar) // 链接Optional对象,形成Optional<Optional<Car>> -> flatMap -> Optional<Car>
.flatMap(Car::getInsurance) // 链接Optional对象,形成Optional<Optional<Insurance>> -> flatMap -> Optional<Insurance>
.map(Insurance::getName) // 拿到name
.orElse("Unknown"); // 否则返回的是Unknow
}
五:更强大的日期类型
在Java8之前与日期时间相关的API,标准的java.util.Date存在许多问题,以及后来的java.util.Calendar设计的过于复杂,几乎让Java处理日期时间更加困难,二者有如下劣势:
Date和Calendar的设计都存在问题Date:它时间点是从格林时间开始的偏移量,导致它既不是纯粹的日期类,也不是存粹的时间类Calendar:试图将日期、时间的计算、格式化、解析等功能都聚集在一起,使得API过于复杂
Date和Calendar都是可变对象,多线程环境存在线程安全问题,需要额外加锁避免并发问题Date本身不包含时区信息,处理不同时区要进行额外转换,Calendar时区的时区处理API比较复杂Date并未提供日期格式化相关的API,想要将日期转变为特定格式,需依赖SimpleDateFormat类Date和Calendar缺乏某些特定的功能,如闰秒的处理、更大的日期范围、更细的时间维度、时区转换能力等
综上,对日期与时间的操作,一直是令Java开发者痛苦的地方之一,日常工作中想要快速、便捷的使用日期/时间格式,不得不自己封装工具类
这种情况造就了一个可替换标准日期/时间处理、且功能非常强大的Java API的诞生:Joda-Time。
正因如此,Java8中再一次对日期/时间相关的标准API动刀,通过发布新的Date-Time API(JSR310)来进一步加强对日期与时间的处理。
当然Java8引入的java.time包,很大程度上受到Joda-Time的影响,并且”吸取“了其精髓并加以改进(实际上连类的命名都一模一样)。
1:LocaleXXX
LocaleDate只持有ISO-8601格式的日期部分,并且没有时区信息,通常用于表示生日等不需要时间的值
常用API清单如下:
// 获取当前日期
LocalDate now = LocalDate.now();
// 根据给定年月日创建一个日期对象
LocalDate date = LocalDate.of(25, 5, 2024);
// 根据给定字符串解析一个日期对象
LocalDate parseDate = LocalDate.parse("2024-05-25");
// 获取年份,类似的API还有getMonth、getDayOfMonth
int year = now.getYear();
// 获取日期是一年的第几天,类似的API还有getDayOfWeek、getDayOfMonth
int dayOfYear = now.getDayOfYear();
// 在给定日期的增加一天,类似的API还有plusMonths、plusYears、plusWeeks
LocalDate plus1Days = now.plusDays(1);
// 在给定日期上减去一天,类似的API还有minusMonths、minusYears、minusWeeks
LocalDate minus1Days = now.minusDays(1);
// 判断两个日期是否相同,true相同,false代表不同
boolean isEquals = now.equals(date);
// 比较两个日期大小,前者小于后者返回-1,相等返回0,大于返回正整数
int x = now.compareTo(date);
// 将日期转换为指定格式的字符串
String format = now.format(DateTimeFormatter.ofPattern("yyyy年MM月dd日"));
下面来看看LocaleTime。LocaleTime只持有ISO-8601格式的时间部分,也没有时区信息
常用API清单如下:
// 获取当前时间
LocalTime now = LocalTime.now();
// 根据给定时分秒创建时间对象
LocalTime time = LocalTime.of(11, 11, 11);
// 将给定字符串解析成时间对象
LocalTime parseTime = LocalTime.parse("11点11分11秒", DateTimeFormatter.ofPattern("HH点mm分ss秒"));
// 获取小时数,类似的API:getMinute(分)、getSecond(秒)、getNano(纳秒)
int hour = now.getHour();
// 增加一小时,类似的API:plusMinute、plusSecond、plusNano
LocalTime plusHours = now.plusHours(1);
// 减少一小时,类似的API:minusMinute、minusSecond、minusNano
LocalTime minusHours = now.minusHours(1);
// 判断两个时间是否相同,true相同,false代表不同
boolean isEquals = time.equals(now);
// 比较两个时间大小,前者小于后者返回-1,相等返回0,大于返回正整数
int x = time.compareTo(now);
// 将时间转换为指定格式的字符串
String format = now.format(DateTimeFormatter.ofPattern("HH点mm分ss秒"));
其实java.time包下每个Local开头的类,内部API的命名大致相同,这极大程度上降低了使用门槛,只要学会其中一种类型,其他的都能照葫芦画瓢
LocaleDateTime代表ISO-8601格式、无时区信息的日期与时间
如果某个字段需要保留日期、时间信息,比如注册时间,就可以使用这个类型,它是LocaleDate与LocaleTime功能的缝合者,具备这两者的大多数API
这里主要说些这块不同的:
// 创建两个日期-时间对象
LocalDateTime now = LocalDateTime.now();
LocalDateTime dateTime = LocalDateTime.of(2024, 5, 25, 11, 11, 11);
// 判断前面的时间是否大于后面的时间
boolean after = now.isAfter(dateTime);
// 判断前面的时间是否小于后面的时间
boolean before = now.isBefore(dateTime);
// 设置特定的小时,类似的API:withYear、withMonth、withMinute、withSecond、withNano
LocalDateTime withHour = now.withHour(11);
// 将日期设置为当前年的第一天
LocalDateTime withDayOfYear = now.withDayOfYear(1);
// 将设置日期设置为当前月的第二天
LocalDateTime withDayOfMonth = now.withDayOfMonth(2);
2:Instant-时间点(时间戳)
Instant是time包中专门用来表达时间戳的类,你可以将其看待成Date类的增强版【Date其实就是时间戳】,因为它最细维度能支持到纳秒级别
常用的API如下:
// 获取当前时间戳(纳秒级)
Instant now = Instant.now();
// 从将毫秒级时间戳转换为纳秒级时间戳,基准为格林威治开始时间(1970-01-01 00:00:00)
Instant ofEpochSecond = Instant.ofEpochMilli(11);
// 在时间戳的基础上增加10秒,类似API:plusMillis(毫秒)、plusNanos(纳秒)
Instant plusSeconds = now.plusSeconds(10);
// 在时间戳的基础上减少10秒,类似API:minusMillis(毫秒)、minusNanos(纳秒)
Instant minusSeconds = now.minusSeconds(10);
// 将时间戳转换为毫秒级时间戳
long epochMilli = now.toEpochMilli();
// 获取当前时间戳的秒数
long epochSecond = now.getEpochSecond();
除开上述方法外,java.time包中都有的方法,如isAfter()、isBefore()、compareTo()、equals()等都有,作用也类似
3:ZoneId、ZonedDateTime
ZoneId是Java8引入的java.time包中的一个类,用于表示时区标识符,时区是地球上用于确定本地时间的地理区域
ZoneId的常用方法如下:
// 获取系统默认时区
ZoneId defaultZoneId = ZoneId.systemDefault();
// 获取Java中所有的可用时区
Set<String> availableZoneIds = ZoneId.getAvailableZoneIds();
// 获取一个特定的时区(上海)
ZoneId shanghaiZoneId = ZoneId.of("Asia/Shanghai");
ZonedDateTime是带时区信息的LocalDateTime类型
如果你需要特定时区的日期/时间,那么ZonedDateTime是你的不二选择,它需要与ZoneId结合起来一起使用:
// 获取默认时区的日期-时间对象
ZonedDateTime now = ZonedDateTime.now();
// 获取特定时区的日期-时间对象
ZonedDateTime zonedDatetimeFromZone = ZonedDateTime.now(ZoneId.of("America/Los_Angeles"));
// 获取now对象的时区
ZoneId zone = now.getZone();
至于ZonedDateTime的其他方法,与LocalDateTime完全相同,然后就能操作特定时区的内容了
4:Clock、Duration、Period
Clock类允许获取基于时区的当前时间,并支持创建自定义的时钟实例,以满足特定的应用程序需求
// 协调世界时,又称为世界统一时间、世界标准时间、国际协调时间
Clock utc = Clock.systemUTC();
// 获取特定时区的Clock对象
Clock shanghai = Clock.system(ZoneId.of("Asia/Shanghai"));
// 获取默认时区的当前时间戳(纳秒级)
Instant instant = utc.instant();
上述案例中,我们指定了上海时区,然后就可以获取到上海时区的当前时刻、日期与时间
Clock可以用来替换System.currentTimeMillis()与TimeZone.getDefault()。
Period可以使两个日期间的计算变得十分简单,Duration可以使两个时间类型的计算很简单,下面来看两个例子:
// 创建两个日期时间实例
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime from = LocalDateTime.parse("2024-04-26 11:11:11", formatter);
LocalDateTime to = LocalDateTime.parse("2024-05-27 12:12:12", formatter);
Duration duration = Duration.between(from, to);
System.out.println("两个时间相差天数:" + duration.toDays());
System.out.println("两个时间相差分钟数:" + duration.toMinutes());
System.out.println("两个时间相差秒数:" + duration.getSeconds());
System.out.println("两个时间相差毫秒数:" + duration.toMillis());
// 获取两个日期实例
LocalDate fromDate = from.toLocalDate();
LocalDate toDate = to.toLocalDate();
Period period = Period.between(fromDate, toDate);
System.out.println("两个时间天数之差:" + period.getDays());
System.out.println("两个时间月数之差:" + period.getMonths());
System.out.println("两个时间年数之差:" + period.getYears());
不过值得说明的是,Period只会计算两个日期每个单位上的差值,如上面的2024-04-26和2024-05-27天数之差会等于1,而并非预期中的31天
time包下的所有类,创建出的实例都是不可变的,比如你用plusHours()方法,将天数往后推一天,这时会产生一个新的LocalDateTime对象
而并不会在原对象的基础上进行修改
这种机制能在多线程环境下,保证进行各类API操作的安全性
六:优雅的异步API-CompletableFuture
最近这些年,两种趋势不断地推动我们反思我们设计软件的方式。
- 第一种趋势和应用运行的硬件平台相关,
- 第二种趋势与应用程序的架构相关,尤其是它们之间如何交互。
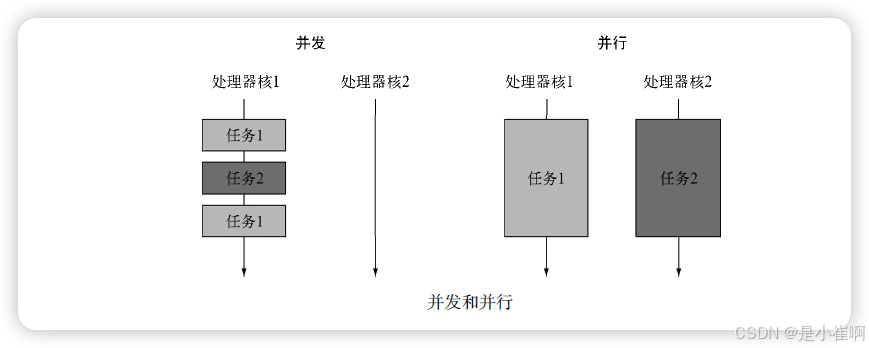
我们注意到随着多核处理器的出现,提升应用程序处理速度最有效的方式是编写能充分发挥多核能力的软件。
现在,很少有网站或者网络应用会以完全隔离的方式工作。
更多的时候,我们看到的下一代网络应用都采用“混聚”(mash-up)的方式:它会使用来自多个来源的内容,将这些内容聚合在一起,方便用户的生活。
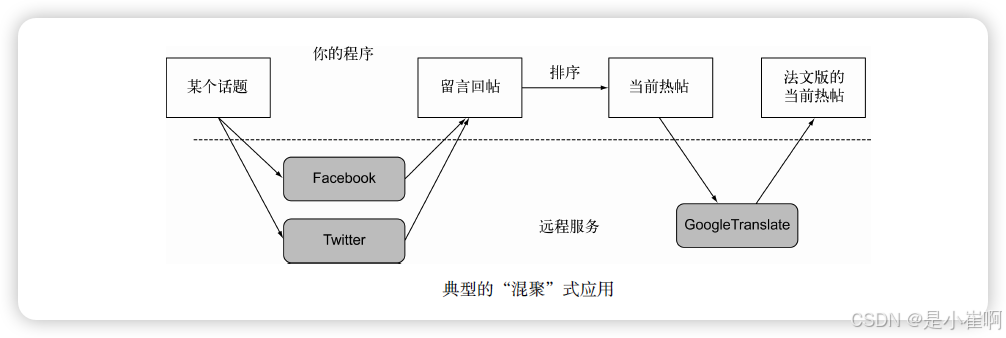
要实现类似的服务,你需要与互联网上的多个Web服务通信。可是,你并不希望因为等待某些服务的响应,阻塞应用程序的运行,浪费数十亿宝贵的CPU时钟周期。
这些场景体现了多任务程序设计的另一面。
分支/合并框架以及并行流是实现并行处理的宝贵工具;它们将一个操作切分为多个子操作,在多个不同的核、CPU甚至是机器上并行地执行这些子操作。
与此相反,如果你的意图是实现并发,而非并行,或者你的主要目标是在同一个CPU上执行几个松耦合的任务,充分利用CPU的核,让其足够忙碌,从而最大化程序的吞吐量,那么你其实真正想做的是避免因为等待远程服务的返回,或者对数据库的查询,而阻塞线程的执行,浪费宝贵的计算资源,因为这种等待的时间很可能相当长。
Future接口,尤其是它的新版实现CompletableFuture,是处理这种情况的利器。
1:Future接口
1.1:Future接口介绍
Future接口在Java 5中被引入,设计初衷是对将来某个时刻会发生的结果进行建模。
它建模了一种异步计算,返回一个执行运算结果的引用,当运算结束后,这个引用被返回给调用方。
在Future中触发那些潜在耗时的操作把调用线程解放出来,让它能继续执行其他有价值的工作,不再需要呆呆等待耗时的操作完成。
打个比方,你可以把它想象成这样的场景:
你拿了一袋子衣服到你中意的干洗店去洗。干洗店的员工会给你张发票,告诉你什么时候你的衣服会洗好(这就是一个Future事件)。
衣服干洗的同时,你可以去做其他的事情。
Future的另一个优点是它比更底层的Thread更易用。
要使用Future,通常你只需要将耗时的操作封装在一个Callable对象中,再将它提交给ExecutorService,就万事大吉了。
// 创建一个线程池
ExecutorService executor = Executors.newCachedThreadPool();
Future<Double> future = executor.submit(new Callable<Double>() {
public Double call() {
return dosomething();
}
});
//异步操作进行的同时,你可以做其他的事情
doSomethingElse();
l
try {
//获取异步操作的结果,如果最终被阻塞,无法得到结果,那么在最多等待1秒钟之后退出
Double result = future.get(1, TimeUnit.SECONDS);
} catch (ExecutionException ee) {
// 计算抛出一个异常
} catch (InterruptedException ie) {
// 当前线程在等待过程中被中断
} catch (TimeoutException te) {
// 在Future对象完成之前超过已过期
}
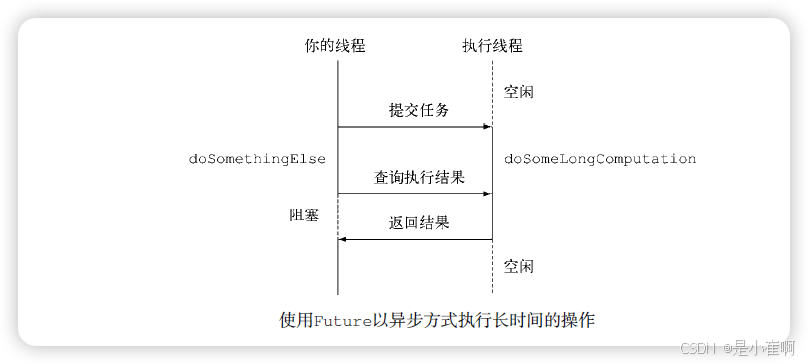
如果该长时间运行的操作永远不返回了会怎样?
为了处理这种可能性,虽然Future提供了一个无需任何参数的get方法
推荐使用重载版本的get方法,它接受一个超时的参数,通过它,你可以定义你的线程等待Future结果的最长时间
1.2:Future接口的局限性
很难表述Future结果之间的依赖性
它没法直接对多个任务进行链式、组合等处理,需要借助并发工具类才能完成,实现逻辑比较复杂。
从文字描述上这很简单,“当长时间计算任务完成时,请将该计算的结果通知到另一个长时间运行的计算任务,这两个计算任务都完成后,将计算的结果与另一个查询操作结果合并”。
但是,使用Future中提供的方法完成这样的操作又是另外一回事。这也是我们需要更具描述能力的特性的原因,比如:
-
将两个异步计算合并为一个——这两个异步计算之间相互独立,同时第二个又依赖于第一个的结果。
-
等待Future集合中的所有任务都完成。
-
仅等待Future集合中最快结束的任务完成(有可能因为它们试图通过不同的方式计算同一个值),并返回它的结果。
-
通过编程方式完成一个Future任务的执行(即以手工设定异步操作结果的方式)。
-
应对Future的完成事件(即当Future的完成事件发生时会收到通知,并能使用Future计算的结果进行下一步的操作,不只是简单地阻塞等待操作的结果)。
新的CompletableFuture类(它实现了Future接口)如何利用Java 8的新特性以更直观的方式将上述需求都变为可能。
Stream和CompletableFuture的设计都遵循了类似的模式:它们都使用了Lambda表达式以及流水线的思想。
2:CompletableFuture
2.1:简介和源码
而CompletableFuture是对Future的扩展和增强。【实现了Future & CompletionStage】
CompletableFuture实现了Future接口,并在此基础上进行了丰富的扩展,完美弥补了Future的局限性
同时CompletableFuture实现了对任务编排(实现了CompletionStage)的能力。
借助这项能力,可以轻松地组织不同任务的运行顺序、规则以及方式。从某种程度上说,这项能力是它的核心能力。
而在以往,虽然通过CountDownLatch等工具类也可以实现任务的编排,但需要复杂的逻辑处理,不仅耗费精力且难以维护。
CompletionStage接口定义了任务编排的方法,执行某一阶段,可以向下执行后续阶段,异步执行的。
默认线程池是ForkJoinPool.commonPool(),但为了业务之间互不影响,且便于定位问题,强烈推荐使用自定义线程池。
// CompletableFuture中默认线程池如下:
// 根据commonPool的并行度来选择,而并行度的计算是在ForkJoinPool的静态代码段完成的
private static final boolean useCommonPool = (ForkJoinPool.getCommonPoolParallelism() > 1);
private static final Executor asyncPool = useCommonPool ? ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
ForkJoinPool中初始化commonPool的参数
static {
// initialize field offsets for CAS etc
try {
U = sun.misc.Unsafe.getUnsafe();
Class<?> k = ForkJoinPool.class;
CTL = U.objectFieldOffset
(k.getDeclaredField("ctl"));
RUNSTATE = U.objectFieldOffset
(k.getDeclaredField("runState"));
STEALCOUNTER = U.objectFieldOffset
(k.getDeclaredField("stealCounter"));
Class<?> tk = Thread.class;
……
} catch (Exception e) {
throw new Error(e);
}
commonMaxSpares = DEFAULT_COMMON_MAX_SPARES;
defaultForkJoinWorkerThreadFactory =
new DefaultForkJoinWorkerThreadFactory();
modifyThreadPermission = new RuntimePermission("modifyThread");
// 调用makeCommonPool方法创建commonPool,其中并行度为逻辑核数-1
common = java.security.AccessController.doPrivileged
(new java.security.PrivilegedAction<ForkJoinPool>() {
public ForkJoinPool run() { return makeCommonPool(); }});
int par = common.config & SMASK; // report 1 even if threads disabled
commonParallelism = par > 0 ? par : 1;
}
2.2:CompletableFuture功能
2.2.1:常用方法
依赖关系
thenApply():把前面任务的执行结果,交给后面的FunctionthenCompose():用来连接两个有依赖关系的任务,结果由第二个任务返回
and集合关系
thenCombine():合并任务,有返回值thenAccepetBoth():两个任务执行完成后,将结果交给thenAccepetBoth处理,无返回值runAfterBoth():两个任务都执行完成后,执行下一步操作(Runnable类型任务)
or聚合关系
applyToEither():两个任务哪个执行的快,就使用哪一个结果,有返回值acceptEither():两个任务哪个执行的快,就消费哪一个结果,无返回值runAfterEither():任意一个任务执行完成,进行下一步操作(Runnable类型任务)
并行执行
allOf():当所有给定的 CompletableFuture 完成时,返回一个新的 CompletableFutureanyOf():当任何一个给定的CompletablFuture完成时,返回一个新的CompletableFuture
结果处理
whenComplete():当任务完成时,将使用结果(或 null)和此阶段的异常(或null如果没有)执行给定操作exceptionally():返回一个新的CompletableFuture,当前面的CompletableFuture完成时,它也完成
2.2.2:异步操作
CompletableFuture提供了四个静态方法来创建一个异步操作:
// 以Runnable函数式接口类型为参数,没有返回结果
// 使用没有指定Executor的方法时,内部使用ForkJoinPool.commonPool() 作为它的线程池执行异步代码,这个线程池默认创建的线程数是 CPU 的核数
public static CompletableFuture<Void> runAsync(Runnable runnable)
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor)
// 以Supplier函数式接口类型为参数,返回结果类型为U,因为Supplier有返回值
// 使用没有指定Executor的方法时,内部使用ForkJoinPool.commonPool() 作为它的线程池执行异步代码,这个线程池默认创建的线程数是 CPU 的核数
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier)
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
如果所有CompletableFuture共享一个线程池,那么一旦有任务执行一些很慢的 I/O 操作,就会导致线程池中所有线程都阻塞在 I/O 操作上,从而造成线程饥饿,进而影响整个系统的性能。强烈建议你要根据不同的业务类型创建不同的线程池,以避免互相干扰
// 没有返回值的异步任务
Runnable runnable = () -> System.out.println("无返回结果异步任务");
// 这个将使用默认的线程池ForkJoinPool.commonPool()
CompletableFuture.runAsync(runnable);
// 有返回值的异步任务
CompletableFuture<String> future = CompletableFuture.supplyAsync( () -> {
System.out.println("有返回值的异步任务");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Hello World";
});
String result = future.get();
2.2.3:结果获取和处理
join()和get()方法都是用来获取CompletableFuture异步之后的返回值。
- join()方法抛出的是uncheck异常(即未经检查的异常),不会强制开发者抛出。
- get()方法抛出的是经过检查的异常,ExecutionException, InterruptedException 需要用户手动处理(抛出或者 try catch)
结果处理,当CompletableFuture的计算结果完成,或者抛出异常的时候,我们可以执行特定的 Action。主要是下面的方法:
public CompletableFuture<T> whenComplete(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action)
public CompletableFuture<T> whenCompleteAsync(BiConsumer<? super T,? super Throwable> action, Executor executor)
- Action的类型是
BiConsumer<? super T,? super Throwable>,它可以处理正常的计算结果,或者异常情况。 - 方法不以Async结尾,意味着Action使用相同的线程执行,而Async可能会使用其它的线程去执行
- 如果使用相同的线程池,也可能会被同一个线程选中执行。
- 这几个方法都会返回CompletableFuture,当Action执行完毕后它的结果返回原始的CompletableFuture的计算结果或者返回异常
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
if (new Random().nextInt(10) % 2 == 0) {
int i = 12 / 0;
}
System.out.println("执行结束!");
return "test";
});
// 任务完成或异常方法完成时执行该方法
// 如果出现了异常,任务结果为null
future.whenComplete(new BiConsumer<String, Throwable>() {
@Override
public void accept(String t, Throwable action) {
System.out.println(t+" 执行完成!");
}
});
// 出现异常时先执行该方法
future.exceptionally(new Function<Throwable, String>() {
@Override
public String apply(Throwable t) {
System.out.println("执行失败:" + t.getMessage());
return "异常xxxx";
}
});
future.get();
2.3:应用场景
2.3.1:结果转换
将上一段任务的执行结果作为下一阶段任务的入参参与重新计算,产生新的结果。
thenApply
thenApply接收一个函数作为参数,使用该函数处理上一个CompletableFuture调用的结果,并返回一个具有处理结果的Future对象。
public <U> CompletableFuture<U> thenApply(Function<? super T,? extends U> fn)
public <U> CompletableFuture<U> thenApplyAsync(Function<? super T,? extends U> fn)
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
int result = 100;
System.out.println("第一次运算:" + result);
return result;
}).thenApply(number -> {
int result = number * 3;
System.out.println("第二次运算:" + result);
return result;
});
thenCompose
thenCompose的参数为一个返回CompletableFuture实例的函数,该函数的参数是先前计算步骤的结果。
public <U> CompletableFuture<U> thenCompose(Function<? super T, ? extends CompletionStage<U>> fn);
public <U> CompletableFuture<U> thenComposeAsync(Function<? super T, ? extends CompletionStage<U>> fn) ;
CompletableFuture<Integer> future = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(30);
System.out.println("第一次运算:" + number);
return number;
}
})
// 上一次的结果
.thenCompose(new Function<Integer, CompletionStage<Integer>>() {
@Override
public CompletionStage<Integer> apply(Integer param) {
// 对其执行Function型函数式接口,就是给一个参数param,返回一个值U -> ComplationStage
// 函数体如下,这个函数体返回CompletionStage<Integer>
return CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = param * 2;
System.out.println("第二次运算:" + number);
return number;
}
});
}
});
thenApply 和 thenCompose的区别:
- thenApply转换的是泛型中的类型,返回的是同一个CompletableFuture;
- thenCompose将内部的CompletableFuture调用展开来并使用上一个CompletableFutre调用的结果在下一步的CompletableFuture调用中进行运算,是生成一个新的CompletableFuture。
2.3.2:结果消费
与结果处理和结果转换系列函数返回一个新的CompletableFuture不同,结果消费系列函数只对结果执行Action,而不返回新的计算值。
根据对结果的处理方式,结果消费函数又可以分为下面三大类:
- thenAccept():对单个结果进行消费
- thenAcceptBoth():对两个结果进行消费
- thenRun():不关心结果,只对结果执行Action
thenAccept
观察该系列函数的参数类型可知,它们是函数式接口Consumer,这个接口只有输入,没有返回值。
public CompletionStage<Void> thenAccept(Consumer<? super T> action);
public CompletionStage<Void> thenAcceptAsync(Consumer<? super T> action);
CompletableFuture<Void> future = CompletableFuture
.supplyAsync(() -> {
int number = new Random().nextInt(10);
System.out.println("第一次运算:" + number);
return number;
}).thenAccept(number -> System.out.println("第二次运算:" + number * 5));
thenAcceptBoth
thenAcceptBoth函数的作用是,当两个CompletionStage都正常完成计算的时候,就会执行提供的action消费两个异步的结果。
public <U> CompletionStage<Void> thenAcceptBoth(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action);
public <U> CompletionStage<Void> thenAcceptBothAsync(CompletionStage<? extends U> other,BiConsumer<? super T, ? super U> action);
CompletableFuture<Integer> futrue1 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(3) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务1结果:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(3) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务2结果:" + number);
return number;
}
});
// 都正常完成计算的时候,就会执行提供的action消费两个异步的结果。
futrue1.thenAcceptBoth(future2, new BiConsumer<Integer, Integer>() {
@Override
public void accept(Integer x, Integer y) {
System.out.println("最终结果:" + (x + y));
}
});
thenRun
thenRun也是对线程任务结果的一种消费函数,与thenAccept不同的是,thenRun会在上一阶段CompletableFuture计算完成的时候执行一个Runnable
Runnable并不使用该CompletableFuture计算的结果。
public CompletionStage<Void> thenRun(Runnable action);
public CompletionStage<Void> thenRunAsync(Runnable action);
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
int number = new Random().nextInt(10);
System.out.println("第一阶段:" + number);
return number;
}).thenRun(() -> System.out.println("thenRun 执行"));
2.3.3:结果组合
thenCombine
合并两个线程任务的结果,并进一步处理。
public <U,V> CompletableFuture<V> thenCombine(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn);
public <U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn);
public <U,V> CompletableFuture<V> thenCombineAsync(CompletionStage<? extends U> other,BiFunction<? super T,? super U,? extends V> fn, Executor executor);
CompletableFuture<Integer> future1 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
System.out.println("任务1结果:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
System.out.println("任务2结果:" + number);
return number;
}
});
// 合并两个线程的结果
CompletableFuture<Integer> result = future1.thenCombine(future2, new BiFunction<Integer, Integer, Integer>() {
@Override
public Integer apply(Integer x, Integer y) {
return x + y;
}
});
System.out.println("组合后结果:" + result.get());
2.3.4:任务交互
线程交互指将两个线程任务获取结果的速度相比较,按一定的规则进行下一步处理。
applyToEither
两个线程任务相比较,先获得执行结果的,就对该结果进行下一步的转化操作。
public <U> CompletionStage<U> applyToEither(CompletionStage<? extends T> other,Function<? super T, U> fn);
public <U> CompletionStage<U> applyToEitherAsync(CompletionStage<? extends T> other,Function<? super T, U> fn);
CompletableFuture<Integer> future1 = CompletableFuture
.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务1结果:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务2结果:" + number);
return number;
}
});
// 谁先完事,谁执行
future1.applyToEither(future2, new Function<Integer, Integer>() {
@Override
public Integer apply(Integer number) {
System.out.println("最快结果:" + number);
return number * 2;
}
});
acceptEither
两个线程任务相比较,先获得执行结果的,就对该结果进行下一步的消费操作。
public CompletionStage<Void> acceptEither(CompletionStage<? extends T> other,Consumer<? super T> action);
public CompletionStage<Void> acceptEitherAsync(CompletionStage<? extends T> other,Consumer<? super T> action);
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一阶段:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(10) + 1;
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二阶段:" + number);
return number;
}
});
future1.acceptEither(future2, new Consumer<Integer>() {
@Override
public void accept(Integer number) {
System.out.println("最快结果:" + number);
}
});
runAfterEither
两个线程任务相比较,有任何一个执行完成,就进行下一步操作,不关心运行结果。
public CompletionStage<Void> runAfterEither(CompletionStage<?> other,Runnable action);
public CompletionStage<Void> runAfterEitherAsync(CompletionStage<?> other,Runnable action);
CompletableFuture<Integer> future1 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(5);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务1结果:" + number);
return number;
}
});
CompletableFuture<Integer> future2 = CompletableFuture.supplyAsync(new Supplier<Integer>() {
@Override
public Integer get() {
int number = new Random().nextInt(5);
try {
TimeUnit.SECONDS.sleep(number);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("任务2结果:" + number);
return number;
}
});
// 有任何一个执行完成,就进行下一步操作
future1.runAfterEither(future2, new Runnable() {
@Override
public void run() {
System.out.println("已经有一个任务完成了");
}
}).join();
anyOf/allOf
anyOf()的参数是多个给定的CompletableFuture,当其中的任何一个完成时,方法返回这个CompletableFuture。
allOf方法用来实现多 CompletableFuture 的同时返回。
public static CompletableFuture<Object> anyOf(CompletableFuture<?>... cfs)
public static CompletableFuture<Void> allOf(CompletableFuture<?>... cfs)
Random random = new Random();
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(random.nextInt(5));
} catch (InterruptedException e) {
e.printStackTrace();
}
return "hello";
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(random.nextInt(1));
} catch (InterruptedException e) {
e.printStackTrace();
}
return "world";
});
// 有一个返回就行了
CompletableFuture<Object> result = CompletableFuture.anyOf(future1, future2);
CompletableFuture<String> future1 = CompletableFuture.supplyAsync(() -> {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("future1完成!");
return "future1完成!";
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
System.out.println("future2完成!");
return "future2完成!";
});
// 要同时返回
CompletableFuture<Void> combindFuture = CompletableFuture.allOf(future1, future2);
try {
combindFuture.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









