






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
摘要
本周的学习内容主要分为两部分,文献阅读和tensorboard画图实践。其中文献为深度残差学习,文中提出了残差学习的思路与方法,有效地解决了因为网络深度增加导致的网络退化,学习到了残差学习解决网络退化和冗余层的问题细节。在使用tensorboard画图实践上,学习使用scalar画了简单的折线图以及CNN的损失函数图形,除此之外还使用graph画出来CNN的结构图。
Abstract
This week’s learning content is mainly divided into two parts, literature reading and Tensorboard drawing practice. Among them, the literature focuses on deep residual learning, which proposes ideas and methods for residual learning, effectively solving the problem of network degradation caused by increasing network depth. We have learned the details of residual learning in solving network degradation and redundant layers. In drawing practice, I learned to use scalar to draw simple line diagrams and CNN loss function graphs. In addition, I also used graph to draw the structure diagram of CNN.
文献阅读:用于图像识别的深度残差学习
Title:Deep Residual Learning for Image Recognition
Author:Kaiming He , Xiangyu Zhang , Shaoqing Ren , Jian Sun
From:2016 IEEE Conference on Computer Vision and Pattern Recognition
1、研究背景
在图像分类领域,深度卷积神经网络已经到来了一系列的突破。深度网络以端到端多层的方式自然地集成了低/中/高级别特征和分类器,并且特征的“级别”可以通过增加网络层的数量来丰富,近年来的实验表明,神经网络的深度是十分重要的。随着神经网络的层数不断叠加出现了梯度消失/爆炸和网络退化的问题出现,前者导致的网络无法收敛的问题已经通过正则化方法解决,但是对于网络退化的问题的解决方法还没有一个普遍适用的方法。
2、研究目的
对于图像识别,如果特征提取得越多,对于识别准确率则会越高,神经网络的深度对于特征的提取有着重要意义。随着神经网络的深度不断加深,会出现网络退化的情况,对于该问题还没有一个普遍适用的方法。为了解决网络退化的问题,提出了一个深度残差学习框架结构。
3、研究思路
3.1、提出假设
假如将每层都映射成残差映射,而不是直接映射成底层映射,会有一个更简单而且更好的优化过程。于是在形式上,将所需的底层映射表示为 H(x) ,让堆叠的非线性层映射成 F(x)= H(x) − x ,这样原始的底层映射就能写成 H(x) = F(x) + x 。这样的残差映射转换可以通过一种名为"快速连接"的方式来实现,其可以直接跳过一层甚至是多层的运算转化,这样的转化方式既不增加额外的参数也不增加计算复杂度,这样整个网络结构就能通过随机梯度下降的方法来实现端对端的优化,也能通过常见的数据集来实现。残差映射的“快速连接”实现结构如下图所示。
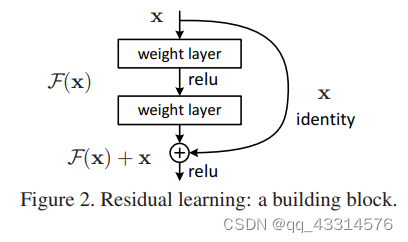
3.2、试验验证
通过在 ImageNet 训练集和 CIFAR-10 训练集中进行实验可以得出假设是成立的,甚至在许多图像识别的比赛当中都获得了第一名的成绩。其中在 ImageNet 训练集中,ResNet 与对应的“plain”网络(不使用“快速连接”结构,仅仅是堆叠层网络)相比不仅更容易优化,而且更低的训练错误,最重要的是随着网络深度的增加,其整体的正确率会更好。同样的现象也出现在了 CIFAR-10 训练集中,在该训练集中甚至成功地训练出了超过100层的网络结构,甚至探索了超过1000层网络结构的可行性。
4、相关知识
4.1、什么是残差学习
- 残差学习就是一个重构函数的过程,将原来x需要变成H(x)函数的过程,转化为x变成残差函数F(x) + x的过程,其中F(x) = H(x) - x ,重构后的残差函数在优化速度、退化问题上都有着明显的提高。
假如非线性层能大致接近复杂函数,那么其也是可以通过变化而转化成残差函数H(x) - x (前提是输入和输出都是一个维度的,H(x) 为最终转化的函数)。相比让各层直接转化为 H(x) ,转化成F(x) = H(x) + x 对于解决优化过程出现退化现象有着明显的提升效果,除此之外,尽管H(x)和F(x)两者都与最终设想的函数十分接近,但是后者比前者更容易优化。
4.2、退化问题
假设现已经训练出一个目前最优的网络结构,其层数只有18层。然后在探索最优网络结构的过程中却设计出了34层网络结构,这样看多出来的16层其实是冗余的,于是想让这冗余的16层的输入与输出完全一样,从而也能达到最优效果。但是往往模型很难将这16层实现恒等映射,所以其性能肯定是比最优化的18层网络结构性能差,这就是随着网络深度增加,模型会产生退化现象。但是这个现象不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
4.3、残差学习的思路
由上面的退化问题可以知道,为了消除冗余层的负面作用,需要让这些冗余层实现恒等映射,即要让H(x) = x,因为模型中会有许多的非线性映射,这样的恒等映射有点难以实现,但是假如将H(x) 变成 F(x) + x,求解器就就只需通过将多重非线性层的权重降为0来实现恒等映射,即让F(x) 中的权值设为0。通过残差学习,能有效地解决非线性层向恒等映射的转化,这样神经网络的深度也能够不断地加深,提取更多的特征进行学习,从而实现整个网络模型准确率的提升。
4.4、Shortcuts实现恒等映射
Shortcuts的是实现其实就是上面3.1的图中结构,通过多个ReLu层的转化,最后加上x便实现H(x) = F(x) + x 的转化。需要注意的是转化工程需要经过两层的ReLu转化,否则其就相当于一个简单的线性函数,没有验证过其对整个网络优化的作用。当然这样的转化还分为两种情况。
- x与F(x) 的维度相同时:整个转化表达式为下图所示,对于F其需要经过多个ReLu层来转化,假如经过两个ReLu层 F = W2
σ
\sigma
σ(W1x),其中的
σ
\sigma
σ就表示为接下来的ReLu操作。
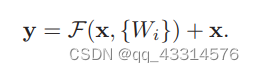
- x与F(x) 的维度不相同时:整个转化表达式为下图所示,对于F的处理情况与上一种情况处理类似,但是因为x的维度与F不相同,需要对x进行维度转化。转化过程也是十分简单,只需通过简单的矩阵相乘就能实现,Ws就是转化矩阵,其仅仅启维度转化的作用。
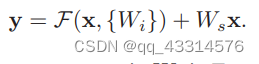
4.5、网络结构
- Plain网络:是基于VGG网络的灵感来设计的,大部分卷积层都有3x3的过滤器以及两个设计规则,i)对于输出相同的特征图尺寸,每层就拥有相同数量的过滤器;ii)对于减半的特征图尺寸,则需要增加一倍的过滤器来保存信息。其次每次通过步长为2的缩减采样。最后通过一个全局的平均池化层以及一个全连接的softmax层得到最后的结果。
- Residual网络:是在Plain网络的基础上增加Residual block来实现的,是Plain的Residual对应版本。其中Residual block是由两层卷积层通过快捷连接层构成的一个残差块。当网络中有维度变化的时候,有两个处理方法,i)通过补充0来扩充维度;ii)通过投影快捷方式来扩充维度,就是下图虚线部分。
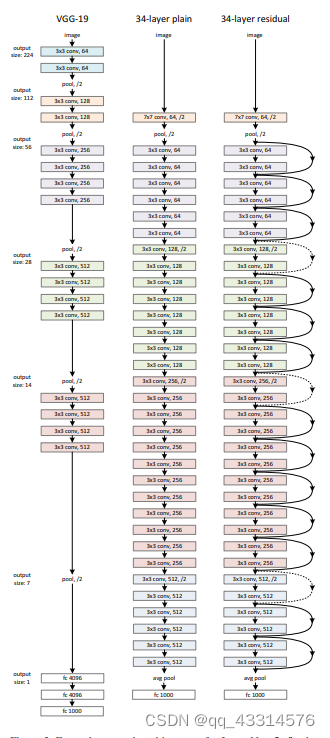
5、文献贡献
深度残差学习的提出解决了探寻能解决问题的最优化模型中出现的退化现象,能有效地解决因为层数增加而导致整个模型性能下降的问题,这样能够向更深层次网络出发,因为随着网络深度的提升,整个网络能提取的特征能更多,更有利于网络的学习。
6、额外学习
6.1、为什么残差学习可以解决梯度消失?
因为梯度消失的情况是反向传播过程中,因为某个权值过小而导致整个梯度值趋近于0的情况。当H(x) 变成了F(x) + x,不论权值怎么小,对x的求导总是存在1来限制整体的梯度过小的情况出现。
6.2、为什么残差学习可以解决网络退化问题?
网络退化的原因主要是因为非线性的冗余层过多导致的,为了解决冗余层过多的情况,整体的思路是通过恒等映射来实现的。但是因为现有的网络层都是非线性结构的,难以实现恒等变化,于是通过公式转化H(x) = F(x) + x ,来调节F(x)中的权值便能实现H(x) = x 的恒等映射,从而有效地解决了网络退化的问题。
TensorBoard画图实践
1、什么是TensorBoard
TensorBoard 是一组用于数据可视化的工具。它包含在流行的开源机器学习库 Tensorflow 中。TensorBoard算是包含在 TensorFlow中的一个子服务。 TensorFlow 库是一个专门为机器学习应用程序设计的开源库。 其包含以下服务:
- 可视化模型的网络架构
- 跟踪模型指标,如损失和准确性等
- 检查机器学习工作流程中权重、偏差和其他组件的直方图
- 显示非表格数据,包括图像、文本和音频
- 将高维嵌入投影到低维空间
2、安装与使用
因为TensorBoard是TensorFlow中的一个子服务,因此要完整使用其相关的功能就得先安装TensorFlow,于是使用Anaconda构建的虚拟环境来安装相关服务,在相关的Anaconda虚拟环境下安装TensorFlow使用以下代码:
pip install tensorflow
pip install tensorboard #单独安装tensorboard
要启动TensorBoard,需要在Anaconda构建的虚拟环境下使用以下命令来启动
tensorboard --logdir xxx #xxx为创建的数据记录文件log的名称,如打开名称为test的记录文件为 tensorboard --logdir test
运行TensorBoard,需要导入以下包,才可以正确导入相关的类库
from torch.utils.tensorboard import SummaryWriter
由于本人使用的编译器为PyCharm,需要导入相关的虚拟环境才可以正常使用,导入Anaconda虚拟环境的步骤如下:
Files >> Setting >> Project >> Python interpreter >> Add interpreter >> Add location interpreter >> 选择创建虚拟环境下的python.exe
在PyCharm 中启动 tensorboard 只需在其下方的Terminal中输入上述代码便可顺利启动,顺利启动的情况如下图:
3、简单CNN代码的实现
首先要实现CNN,需要有一定的数据集来巡林,于是得在tensorVision的datasets中下载MINST训练集,给神经网络导入病并加载相关的训练集和测试集,代码如下:
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
]) ## 加载MNIST数据集,将数据归一化到[0,1]区间内
trainset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
testset = datasets.MNIST(root='./data', train=False , transform=transform, download=True)
testloader = DataLoader(testset, batch_size=64, shuffle=False) #导入训练集和测试集
定义卷积神经网络,需要导入torch中的nn库来实现相关的卷积神经网络定义,其代码如下:
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(10, 20, 5)
self.fc = nn.Linear(320, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 320)
x = self.fc(x)
return x
初始化模型,为了能顺利地训练出一个性能较好的卷积神经网络,就需要定义一个损失函数,通过查看损失函数的值来对整个模型进行优化,于是还需要定义一个优化器,这里选用随机梯度下降优化器SGD,最后通过10的epoch的时间对卷积神经网络进行训练。代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
# 初始化模型,损失函数和优化器
model = ConvNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(trainloader):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
4、Scalar函数的画图方法
使用scalar画图的方法为使用tensorboard中的SummaryWriter库中的add_scalar函数,将数据记录到Summary中,函数的定义如下:
def add_scalar(
self,
tag, #定义的scalar名称
scalar_value, #需要记录保存的数值
global_step=None, #全局步骤数的记录
walltime=None,
new_style=False,
double_precision=False,
):
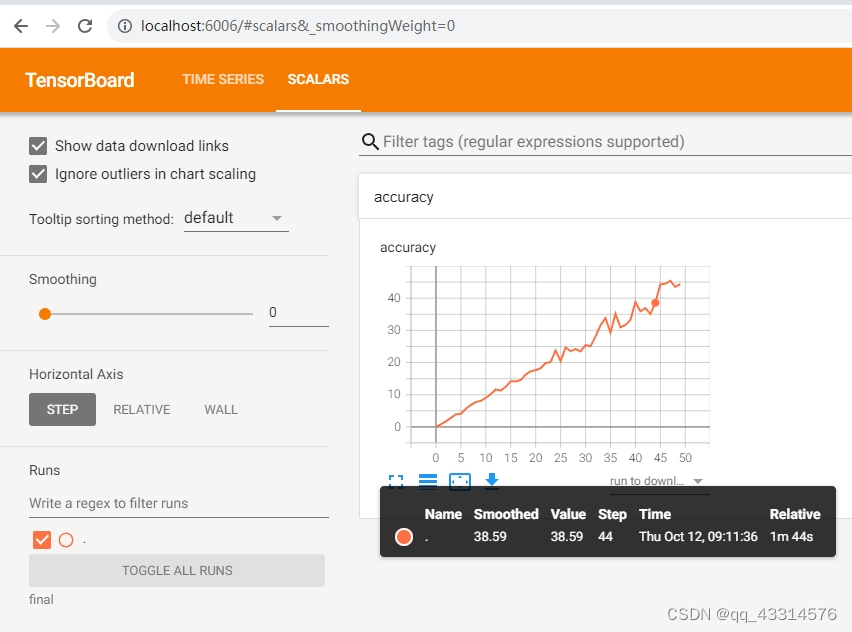
简单的随机曲线记录,代码如下:
writer = SummaryWriter(log_dir='final') #定义一个SummaryWriter对象wirter,将记录数据保存到final文件夹中
for i in range(50): #定义50次的生成,即记录数据50次
writer.add_scalar(tag="accuracy", scalar_value=i * random.uniform(0.8, 1), global_step=i) #将随机生成的数据记录到Summary中
time.sleep(2 * random.uniform(0.5, 1.5)) #定义每一步的时间暂停时间
最后记录的生成结果如下图所示:
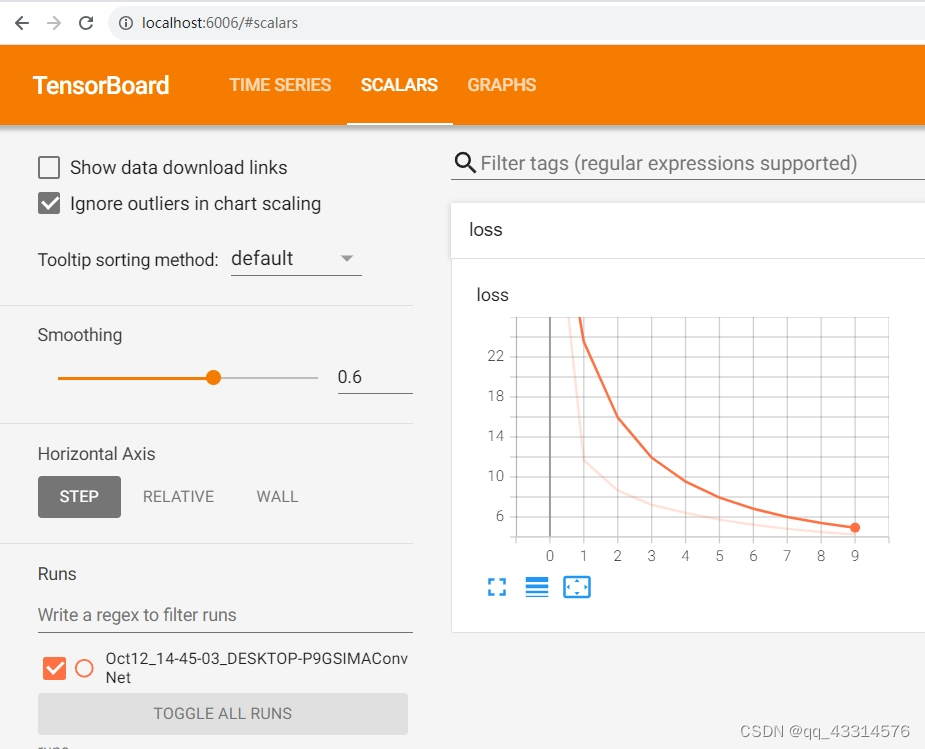
因为训练后的CNN对MINST数据集已经达到一个很高的准确率,损失函数值较小,于是对上述实现的简单CNN的损失函数值 x 100进行记录,代码如下:
writer = SummaryWriter(log_dir='runs')
writer.add_scalar(tag="loss" , scalar_value=running_loss/ len(trainloader) * 100 , global_step=epoch)
经过10次的epoch训练,最后记录的生成结果如下图所示:
5、Graph函数的框架图方法
使用Graph画图的方法为使用tensorboard中的SummaryWriter库中的add_graph函数,将数据记录到Summary中,函数的定义如下:
def add_graph(
self,
model, #所要生成模型图的模型
input_to_model=None, #输入到模型的数据
verbose=False,
use_strict_trace=True
):
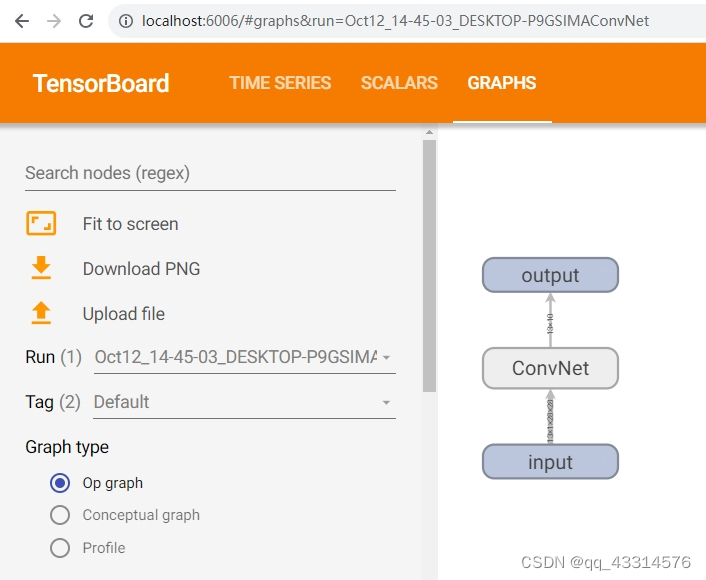
使用Graph函数画出CNN模型图,代码如下:
dummy_input = torch.rand(13,1,28,28) #构建张量数据
with SummaryWriter(comment='ConvNet') as w: 画出构建的名为ConvNet模型
w.add_graph(model , (dummy_input,))
最后的生成结果如下图所示:
总结
在看过几篇论文之后,发现能学习到许多课堂上没学习过的先进知识,极大丰富了我对人工智能学习的认识。在这次的学习中,见识到创新型的残差学习对深度学习的影响,仅仅是一点的思路改变便能产生巨大影响,这让我大受鼓舞,希望未来能想到改进思路写出高水平论文。当然这次最重要的是接触到了tensorboard自动画图工具,顺利地了解其scalar和graph函数方法,希望未来能继续使用其创造出更多不可思议的神经网络模型图。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









