






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
摘要
在本次的机器学习课程中学习的内容主要是Self-Supervised Learning,在这其中包含着许多的模型,以BERT以及GPT最为著名,这节的学习便是以BERT为主。在BERT的学习中,学习到了其大致的工作原理,在四种任务中的工作流程。此外还了解了BERT的Adapator的适应性。在GPT的学习中学习中,了解到庞大的参数量、训练任务目标以及相应的训练方式。
Abstract
The main content of this machine learning course is Self Supervised Learning, which includes many models, with BERT and GPT being the most famous. This section focuses on BERT. In BERT’s learning, I learned its general working principle and workflow in four tasks. In addition, I also learned about the adaptability of BERT’s adapter. In the learning of GPT, one learns about a large number of parameters, training task objectives, and corresponding training methods.
一、Self-Supervised Learning — BERT
1、什么是Self-Supervised
说起 Self-Supervised 就必须与 Supervised 作为对比,Supervised 是对一个输入x经过模型处理得出一个结果y,而这个结果与现实中已经标记好的结果进行比较。Self-Supervised 则是由机器自己来做 Supervised,主要就是将输入分成两部分,其中一部分作为输入,另外一部分作为Supervised 标签,输入经过处理后得到的结果与自定义标签进行比较,希望训练出的结果与自定义标签越接近越好。
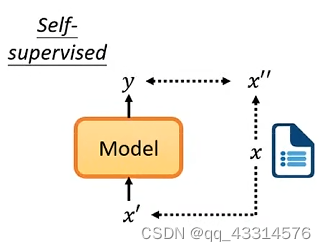
2、Self-Supervised 的原理
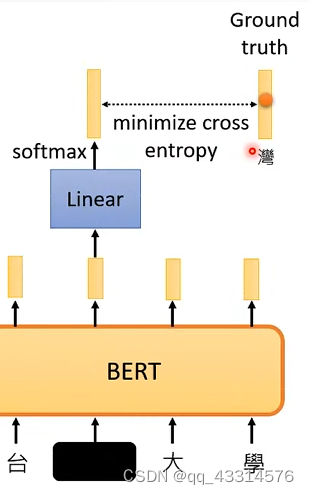
BERT是Self-Supervised 的典型例子,以BERT的一次工作过程作为例子。如下图所示,假如BERT要对一文字向量进行处理,在处理之前会先对文字向量做出隐藏处理,该隐藏字符只有BERT是不知道的,训练者是知道其内容,作为结果标签。经过BERT处理、softmax处理、cross entropy处理之后得出最后的结果与已知道的结果标签进行比较,希望该输出结果能与结果标签越接近越好,这整个过程也就是Self-Supervised 的过程。需要注意的是对文字向量做隐藏式处理有两种方法,一、对其进行MASK处理,就是利用一些特殊标记进行标记处理;二、使用随机字符进行隐藏。
3、Downstream Tasks
BERT最基本的功能除了上述所讲的处理Masking Input 的填空题之外还有另外一个最基础的功能就是Next Sentence Prediction,就是判断两个输入的文字向量是否可以连接在一起。BERT实现的这两个基础功能看似很简单,但是可以以此作为基础完成以下几种Downstream Tasks。 BERT的结构是十分巨大的,参数无比的多,训练时间也是难以想象。
3.1、Sentence的Sentiment Analysis
对BERT输入 [CLS] 标签以及一串文字向量,经过处理后得到一个向量,再经过Linear Regression处理后得到最终的分类结果。其中Linear单元是和BERT看作是一个整体来调整的,Linear单元是利用随机数初始化的,但是BERT是一个经过Pre-train处理的结构,是一个”会做填空题“的BERT单元。使用这样的Pre-train的BERT原因是能明显提高整个模型的准确性。
3.2、Sentence的词性分析
对BERT输入 [CLS] 标签以及一串文字向量,经过处理后得到与文字向量一一对应的向量,再经过Linear regression处理得到与文字向量对应的词性结果。
3.3、Sentence的前提假设分析
对BERT输入 [CLS] 标签、两串文字向量以及夹在两串文字向量中间的[SEP]标签,两文字向量中一个是前提,另外一个是假设,判断两者是否有前后推断关系。数据经过BERT处理后得到对应的向量,其中对[CLS]标签的输出向量进行Linear regression处理得到最后的判断结果。
3.4、Extraction-based Question Answering
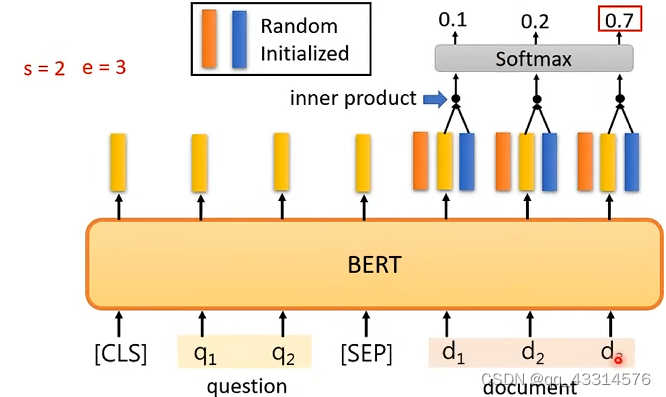
对BERT输入 [CLS] 标签、两串文字向量以及夹在两串文字向量中间的[SEP]标签,两文字向量中一个是原文,另外一个是问题,BERT要根据问题在原文中寻找到相应的答案位置,该位置信息用数字来表示。如下图所示,经过BERT处理后得到一系列对应的向量,其中原文的结果向量需要与两个随机初始化的向量进行inner product以及Softmax处理,最后得到开头与结束的数字位置的几率。
4、BERT Pre-training a seq2seq model
要利用BERT来预训练出seq2seq模型的主要思路就是,将输入的文字向量进行重组,经过处理得出的最后结果与原来的未重组之前的文字向量进行比较,使两者之间越接近越好。重组的方法有以下几种,一、MASK;二、删除;三、对称变换;四、旋转;五、其它文本插入。
5、BERT的输出向量
- 含义:由上面的学习可以知道,文字向量经过BERT处理会得到一系列的向量,这个向量的内容表示的是什么含义呢?这里的向量为一个embedding,含义表示为在一个多维空间的一个点,相近含义的词会彼此离得更近,需要注意的是相同的词含义却不同的词在这个多维空间中的位置不会是重叠的,因此可以将其理解为一个词意空间向量点。
- 由来:因为要表示某个词的含义需要考虑很多的因素,除了考虑字本身含义还需要其考虑在某个词组、句子中的含义,只有这样才能准确地描述其含义,才能在多维的词意空间中准确表示出来。因此要得出这样的结果,每个词向量都需要与上下文进行对比处理才能得到最终的结果。这样的处理与word embedding模型处理很相似,BERT便是该模型的进阶版。
6、BERT的特殊使用
现在有这样的实验,假如将DNA序列、氨基酸序列以及音乐序列拟变为一组文字序列,让BERT对这些文字序列进行处理竟然能得到一个不错的预测结果,这可以侧面说明尽管是一些乱序的序列BERT也能大概理解。另外一个就是对不同语言的识别处理,利用英文的QA来训练中文的QA竟然也有一个不错的结果,当然从多维词意向量维度上看,两者还是有些许去别的,从Muti-BERT的角度上看两者之间其实是有一个词意转化的过程,只要训练出平均的英语向量维度然后再加上与语文向量维度的距离,便能通过英语QA训练出较好的中文QA结果。
7、BERT的 Adaptor
一个完整的BERT模型是分为两个部分,一部分是Pre-trained模型,另外一部分是具体任务模型,将这两部分合起来就是一个Fine-tune模型。对于Fine-tune模型的训练是可以有两种方法,将两部分分开训练或者是两部分一起训练。对于后者的话,对于不同任务可能就需要训练不一样的Pre-trained模型来适应不同的情况,这样会显得十分麻烦。改进的方法就是将其分开来训练,而且Pre-trained模型还可以继续分成两个部分,一个是纯Pre-trained模型以及对于不同任务而不同的适配器,以适应不同的具体任务。
二、Self-Supervised Learning — GPT
1、GPT的任务目标
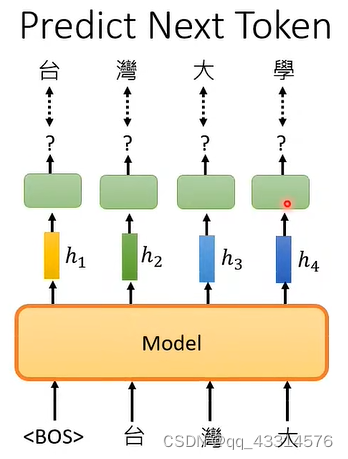
GPT的任务目标精简地来看就是“预测”,就是模型对输入的token进行处理后,对该token的下一目标进行预测,然后对生成的目标作为输入,不断地进行预测,直到结束的token为止,这样整个工作过程就完成了。
2、GPT的训练方式
GPT的训练思路主要有三个思路,Few-shot、One-shot以及Zero-shot三种方式,这三种方式的区别也就是训练材料的不同,顾名思义Few也就是有些许的训练资料,根据这些训练资料来让机器学习对这些输入的回答进行预测。One则是只用一个资料,Zero则是没有资料进行训练,难度是一点点地增加的,当然随着模型的增加,每一种方式都是在逐渐增加的。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









