







论文《A Multi-Type Transferable Method for Missing Link Prediction in Heterogeneous Social Networks》阅读
论文概况
本文是2023年TKDE上的一篇论文,该篇文章聚焦捕获不同链路类型之间共享的特征,提出了MTTM模型。
Introduction
异构社交网络以多种交互类型为特征,给缺失链接预测带来了新的挑战。大多数深度学习模型倾向于捕获特定类型的特征,以最大限度地提高特定链接类型的预测性能。然而异构社交网络中缺失链接的类型是不确定的;这限制了现有深度学习模型的预测性能。
学习链路类型之间的可转移特征表示的挑战:
- 第一个挑战是通过删除特定类型的特征来捕获不同链路类型上的共享特征。** 共享特征和类型特定特征共存于不同链路类型对应的特征表示中。很难区分共享特征和特定类型特征**。
- 第二个挑战是根据链路类型之间学习的可转移特征表示来预测丢失的链接。不同类型的链路表示之间的差异在训练阶段是可变的,并且很难提供不同链路类型之间共享特征的准确表征。
为了解决上述挑战,作者提出了一种用于异构社交网络中缺失链接预测的多类型可转移方法(MTTM),由生成预测器和判别分类器组成。
- 生成预测器可以提取链路样本的特征并预测链路是否存在。为了很好地概括不同的链路类型,需要通过捕获共享特征来对生成预测器进行链接类型之间可转移特征表示的训练。
- 判别分类器旨在帮助生成预测器 判断 学习到的特征表示是否可迁移。
受对抗性网络的启发:
- 生成预测器试图学习链路类型之间的可转移特征表示,以欺骗判别分类器。
- 判别分类器旨在基于学习到的特征表示来区分链路样本的类型,避免被生成预测器欺骗。判别分类器的相应损失可用于评估生成预测器中学习到的特征表示符合可转移特征表示的程度。
- 最后,集成的 MTTM 应用生成预测器和判别分类器之间的博弈来预测异构社交网络中的缺失链路。
对抗性神经网络:对抗性神经网络由生成模型和判别模型组成。生成模型的任务是生成与现实应用程序中的原始数据相似的自然且真实的实例。同时,判别模型旨在尝试确定给定的生成实例是否看起来真实。这两种模式一直相互冲突。通过对抗性训练,生成模型和判别模型不断发展。对抗性神经网络已被用于不同应用领域的许多任务。
Method
文章提出了一种用于异构社交网络中缺失链路预测的多类型可转移方法(MTTM),该方法利用对抗性神经网络来保持针对类型差异的鲁棒性。
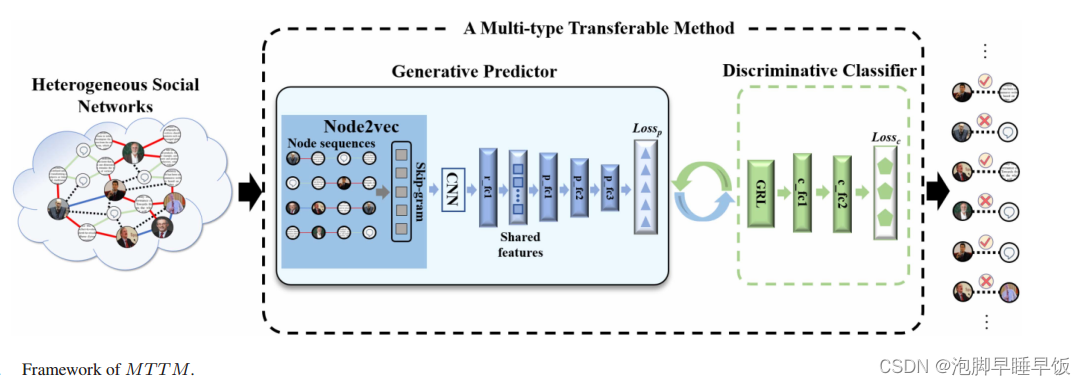
A.生成预测器
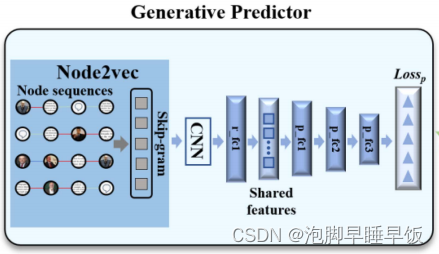
生成预测器:根据学习到的特征表示进行链路预测。
为了提取链接类型之间的共享特征,使用node2vec作为核心模块,以减少异构社交网络的类型异构性带来的额外语义信息。
f(u) 作为从节点 u 到其由 node2vec 表示的特征的映射函数。对于链路 e = (u, v),首先分别获得节点 u 和 v 的特征表示 f(u) 和 f(v)。那么,链路样本e的初始特征表示表示如下
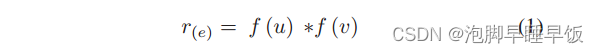
将输入的链路样本集表示为 S。为了训练生成预测器以获得泛化能力,S 在训练阶段需要包含不止一种类型的链路样本。为了保持实际应用中输入的灵活性,S 在预测阶段可以包含一种或多种类型的链路样本。为了表示S中所有链接样本的初始特征表示,我们定义初始表示集RF如下。
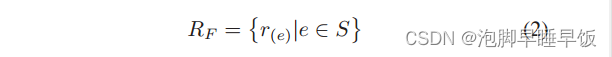
添加卷积神经网络和全连接层,以基于 RF 中的初始特征表示聚合可转移的特征表示。θr用来表示这个过程中要学习的参数。
RF = {r(e)|e ∈ S} ,r(e)表示S中链路样本e的聚合特征表示。用于训练。
进一步使用 Gp(S; θr, θp) 来表示生成预测器。
采用具有 softmax 函数的三个全连接层来区分缺失链接和不存在链接。 θp 代表它们包含的参数。对于给定的链接样本 e,生成预测器的输出可以表示如下。
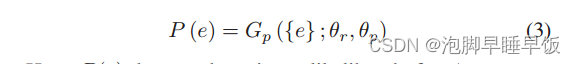
这里,P(e)表示e的存在可能性。 P(e) 值较大意味着链路样本 e 很可能是缺失样本。对于给定的链路样本集S,我们通过交叉熵定义生成预测器的预测损失如下。
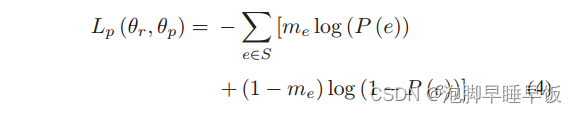
这里,me ∈ {0, 1}。 me = 1 表示链接样本e为正;否则,me = 0。为了提高准确率,生成预测器的首要任务是最小化预测损失。寻求最优参数 ˆθr 和 ˆθp 的过程可以表示如下。
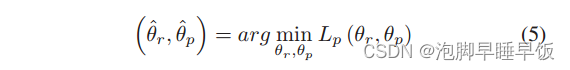
(5) 中预测损失的直接最小化通过捕获 RF 中的类型特定特征和共享特征来提高可辨别表示的学习性能。
然而,异构社交网络中缺失链接预测的挑战在于缺失链接的类型是不确定的,每个缺失链接可能属于历史类型或新类型。基于可区分表示的深度学习模型没有足够的泛化能力,无法在不同的链接类型上实现普遍的性能提升。特别是,如果没有足够的泛化能力,这些模型很难对训练集中未覆盖的新链接类型取得良好的预测性能。为了提高缺失链路的预测性能,我们受到启发**,学习可转移的特征表示**,以便在历史类型和新类型之间很好地泛化。因此,我们需要使生成预测器能够学习更通用的特征表示,这些特征表示可以从一种链路类型转移到其他链路类型。此类特征表示应捕获链路类型之间的共享特征并删除其特定于类型的特征。为了实现这一点,我们需要以下判别分类器来帮助生成预测器判断 学习到的特征表示是否符合可转移特征表示的标准。在判别分类器的帮助下,我们可以用经过认证的 RF 来训练生成预测器,进一步获得预测缺失链接的泛化能力。
B.判别分类器
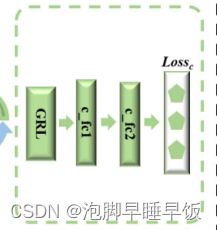
判别分类器是一个神经网络,由两个具有相应激活函数的全连接层组成。我们使用 Gc( RF ; θr, θc) 来表示判别分类器,其中 θc 表示要学习的参数, RF 和 θr 来自生成预测器。判别分类器的作用是判断中学习到的特征表示是否可迁移。为了实现此任务,判别分类器被设计为区分链路类型,并尝试根据 RF 中学习到的特征表示来预测链接样本的准确类型。
通过交叉熵定义判别分类器的分类损失如下。
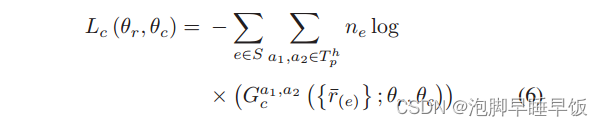
这里,T h p 包含了 S 中链路样本的类型,
Ga1,a2 c ({r¯(e)}; θr, θc) 表示将链接样本 e 的链接类型分类为 a1, a2 在T h p 的概率。
若e的正确链接类型为a1,a2,ne = 1;否则,ne = 0。
当Lc(θr,θc)值较小时,判别分类器获得更好的性能将S中的链接样本分类为正确的类型。最小化该损失 Lc(θr,θc) 后的判别分类器的参数表示如下。
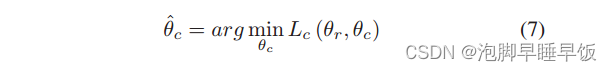
分类损失 Lc(θr, ˆθc) 可以间接评估 RF 中学习到的特征表示符合可转移特征表示的程度。
当 Lc(θr, ˆθc) 值越大,分类性能越差时, RF 中学习到的特征表示可以更好地符合可转移特征表示的标准。
因此,我们需要在训练阶段通过寻找最优参数 θr 来最大化 Lc(θr, ˆθc),这有助于RF 中的特征表示符合可转移特征表示的标准。
生成预测器 Gp(S; θr, θp) 尝试学习可转移的特征表示,通过捕获共享特征删除类型特定的特征来欺骗判别分类器 Gc( ¯ RF ; θr, θc) Gc( ¯ RF ; θr, θc) 试图通过发现 ¯ RF 中的类型特定特征来识别链路类型,从而不被欺骗。基于极小极大博弈,综合损失函数定义如下
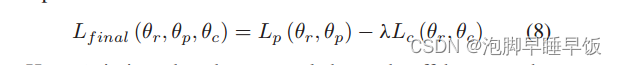
这里引入 λ 来控制预测损失和分类损失之间的权衡,寻求的参数集就是综合损失函数的鞍点。
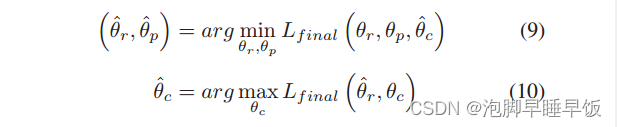
在生成预测器和判别分类器之间添加了梯度反转层(GRL)。
基于GRL,生成预测器中的特征提取过程与判别分类器具有相反的目标,即降低分类性能并混淆链接类型。
GRL 将梯度乘以−λ 并在反向传播阶段将结果传递到前一层。引入学习率 η ,θr 的更新可以表示如下。
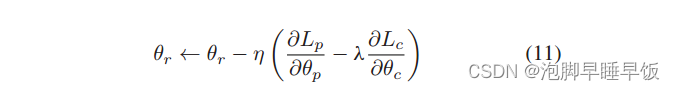
实验
学习可迁移特征表示的重要性
为了证明在训练阶段学习可转移特征表示的重要性,我们设计了所提出的 MTTM 的变体进行比较。
为了使我们提出的 MTTM 能够学习可转移特征表示,我们需要判别分类器通过(10)的最大化过程来决定提取的特征是否符合可转移特征表示的标准。然而,即使没有这种最大化过程,我们仍然可以根据异构社交网络的初步特征表示来预测异构社交网络中缺失的链接。
因此,我们设计了所提出模型的一个变体,名为 MTTM1−。 MTTM 和 MTTM1− 之间的唯一区别是 MTTM1− 没有考虑判别分类器中(10)的最大化过程。然后我们进行 MTTM 和 MTTM1− 来预测 Facebook 和 DBLP 上缺失的链接。对 40 次独立运行进行平均,MTTM 和 MTTM1− 之间的性能比较直方图如图 2 所示。
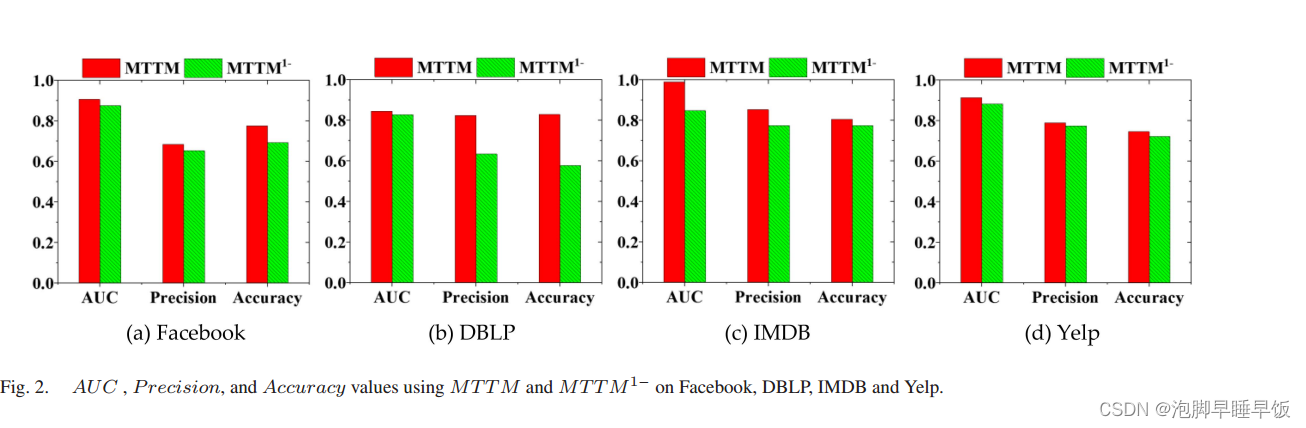
与MTTM1−相比,MTTM表现出明显的性能提升。这强烈表明学习可转移特征表示对于提高异构社交网络中缺失链接的预测性能非常重要且有益。如图2所示,在Facebook、DBLP、IMDB和Yelp的数据集上,MTTM在AUC、精度和准确度方面总是获得比MTTM1−更大的评估值。基于生成预测器和判别分类器之间的极小最大两人游戏,MTTM 能够学习可以从一种链接类型转移到其他链接类型的通用链接表示。生成预测器试图捕获链接类型之间的共享特征来欺骗判别分类器,而判别分类器则试图区分链接类型以免被欺骗。相比之下,如果没有(10)的最大化过程,MTTM1−专注于学习不可转移的类型特定特征,这使得它失去了抵抗预测过程中缺失链接的类型不确定性的泛化能力。因此,受益于可转移特征表示的学习,MTTM 有理由实现比 MTTM1− 更好的预测性能。
参数分析
训练集和测试集的分裂在MTTM的绩效评估中起着至关重要的作用。本节讨论了R的设置对MTTM预测性能的影响。为了获得可控的划分,我们调整样本比率r以分析MTTM的性能变化。随着r值的变化,MTTM在Facebook和DBLP上获得的AUC,P回调和准确性值的变化如图3所示。
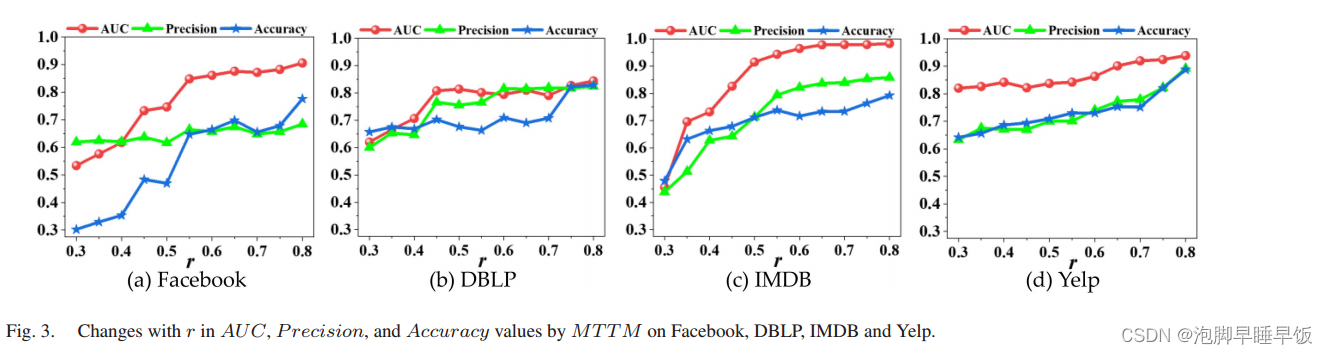
如图3所示,**训练集和测试集的分配很重要,**并且会影响MTTM的预测性能。观察结果的两个方面可以概括如下。 (1)随着R值的增加,添加更多的正样品和负样品以扩大训练集的大小,从而有效地促进了测试集中MTTM的预测性能。因此,在四个数据集上,AUC,p恢复和准确性值总是在增加。 (2)在大多数情况下,随着R的增加,AUC,P恢复和准确性值的生长速度降低。当R值在一定程度上增加时,MTTM可以在训练阶段获得足够数量的标记链接样本,并且增加新标记的链接样本无法显着提高其性能。
案例分析
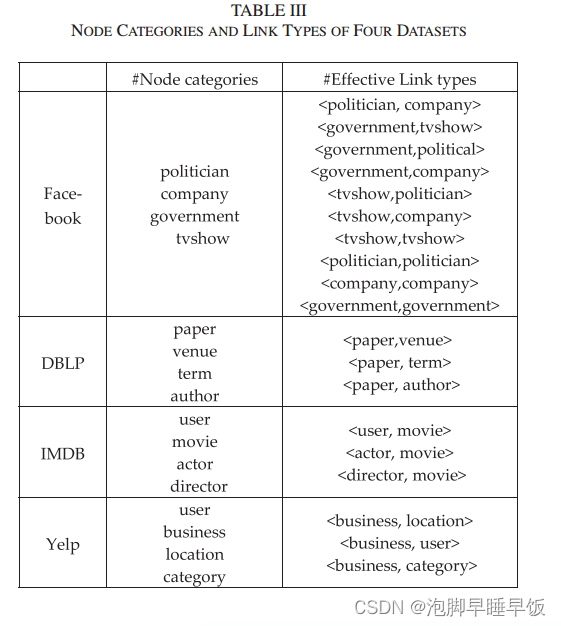
本节中,为了分析缺失链路类型对链路预测的影响,我们设计案例进行如下对比实验。为了保证链接类型设置的灵活性,我们使用Facebook的数据集,有10种有效的链接类型作为一个案例。实验设计如下。首先,我们使用 Tv 来表示有效链接类型的集合。对于每个数据集,我们随机选择 2/ 3 × |Tv| Tv 中的链路类型构造历史链路类型集合T h p ,其他链路类型用于构造新的链路类型集合T n p 。接下来,我们使用 T h p 中链接类型的链接样本来构建训练集和测试集。此外,为了在测试集中实现可控的类型不确定性,我们控制 T n p 中新链接类型上链接样本的添加。我们构造新的样本集 SΔ ,其中 T n p 中链接类型上的观察到的链接被视为其正样本,而相同链接类型内的等效未观察到的链接被随机选择为其负样本。
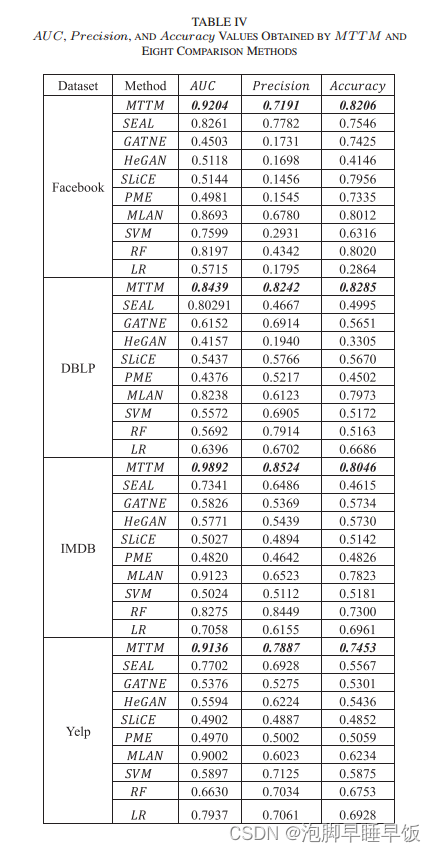
根据上述步骤,训练集和测试集中不存在SΔ中的链接样本类型。我们设定一个比率 Ψ 并随机选择 Ψ|SΔ |将 SΔ 中的样本链接到测试集中。随着 xi 值的增加,测试集中新类型上的链路样本增多,测试集中缺失链接的类型不确定性增加。我们调整比率 xi 并使用 AUC 来评估 MTTM 和八种比较方法的整体性能。 MTTM和八种比较方法的AUC值变化如图4所示。
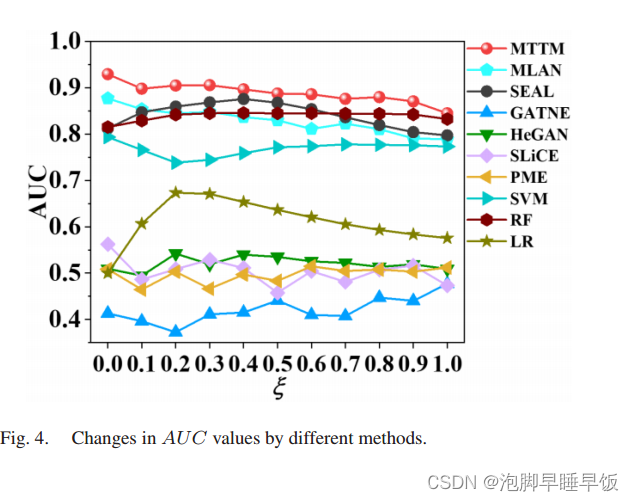
如图 4 所示,在不同的 xi值下,我们提出的 MTTM 的整体预测性能始终优于八种比较方法。这证实了我们提出的 MTTM 对于抵抗预测过程中缺失链接的类型不确定性的干扰具有鲁棒性。
由于训练集中经过验证的链接样本数量有限,Σ值的增加导致测试集上的链接样本数量增加,从而降低了所有方法的整体预测性能。虽然MTTM和八种比较方法的AUC值随着 Ψ值的逐渐增大而逐渐减小,MTTM的AUC值始终高于八种比较方法的AUC值。与比较方法不同,MTTM 试图通过捕获共享特征并删除特定于类型的特征来学习可转移的特征表示,这使其能够泛化以统一的方式预测不同类型上的缺失链接。
总结
文章提出正式认识到缺失链路的类型的不确定性对链路预测的挑战,并提出了一种多类型可转移方法来解决它。文章提出的方法是在生成预测器和判别分类器之间的极小最大对抗的基础上构建的。
生成预测器旨在根据学习到的链路表示来预测未观察到的链路是否为缺失链接。它试图捕获链路类型之间的共享特征来欺骗判别分类器,而判别分类器则试图区分不同的链接类型以免被欺骗。因此,MTTM 有效地学习可转移的特征表示,以提高异构社交网络中缺失链路的预测性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









