









留个笔记自用
DeepLO: Geometry-Aware Deep LiDAR Odometry
做什么
Lidar Odometry激光雷达里程计,里程计作为移动机器人相对定位的有效传感器,为机器人提供了实时的位姿信息。移动机器人里程计模型决定于移动机器人结构和运动方式,即移动机器人运动学模型。
简单来说,里程计是一种利用从移动传感器获得的数据来估计物体位置随时间的变化而改变的方法

用建图的方式来理解,要实现机器人的定位与导航,就需要知道机器人走了多远,往哪走,也就是初始位姿和终点位姿,只有知道了里程计,才能准确将机器人扫描出来的数据进行构建。
做了什么
这里提出了一种无监督的激光雷达里程计方法
主要使用了一种NICP-like损失,这种损失是根据前述计算的,而激光雷达里程计的输入就是前后两帧,因此整体训练是无监督的方式进行
怎么做
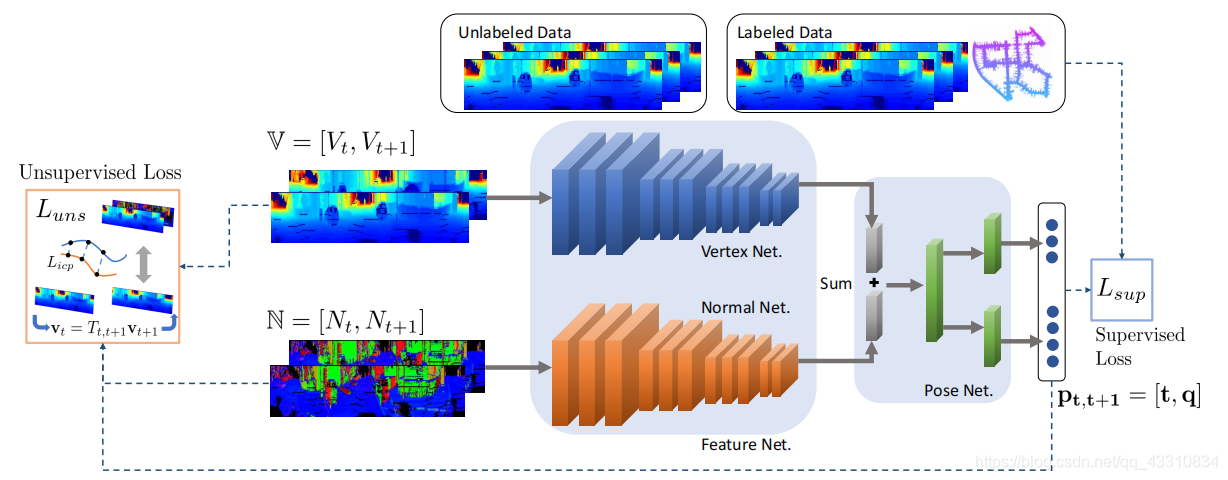
整体结构分为两个部分,特征提取网络FeatureNet部分和位姿网络PoseNet部分组成,前者主要是获取两帧点云的点云集特征,后者是根据这两个特征差获得相对位姿运动,也就是最终输出的目标。
首先是输入数据处理,这里采用的方法与LO-NET的方法非常相似,将点云根据位置进行投影

这里的px、py、pz代表的就是p点的三维坐标
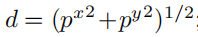
这里的d就是常见的深度值,fh和fv是点p的水平角和竖直角,δh和δv是水平和竖直的像素分辨率。整体来说这里文章写的有点不太理解,文章中用的水平分辨率是δu,但式子中却不是,并且也没具体说明各个值的由来。但总的简单来说,这里就是根据点云集中各个点云的三维坐标等信息将点投影至一个2D平面上。
最后整合输入为
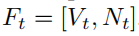
Ft就是表示第t帧的网络输入,V是投影出来的2D平面结果,N是点云集的逐点法向量结果。
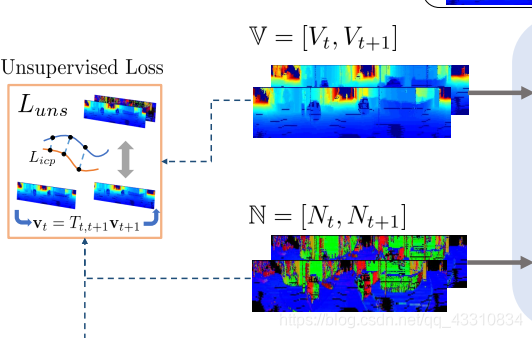
这里采用的求法向量的方法是另外一篇论文《NICP: Dense normal based point
cloud registration》里的方法,也就是NICP,这是一个基于ICP的法向量计算算法

而NICP算法就是在ICP的基础上同时进行点云匹配与运动估计交叉迭代优化,它充分利用实际曲面的特征来对错误点进行了滤除,主要使用的特征为法向量和曲率。在误差项里除了考虑了点到对应点切面的距离,还考虑了对应点法向量的角度。NICP
也像传统的法向量计算一样,需要用点邻域进行曲面模拟,这里采用的邻域的是在映射图像上与该点映射距离近的,也就是直接算平面直线距离,一个圆形范围
然后对比了一下这种点映射方法和其他映射方法的好坏区别
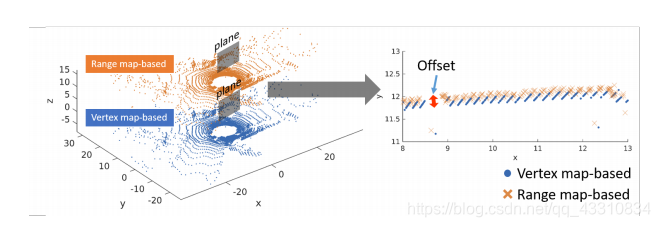
这里的方法是蓝色方法,Vertex map,橙色的方法是Range map,这里的range map的意思就是LO-NET用的方法LO-NET
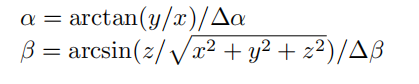
这里说它映射的时候就不会产生离散化偏移,也就是角度离散化,其实主要是这里的δ计算时考虑到了高度问题
解决了输入问题,接下来就是具体的网络结构部分
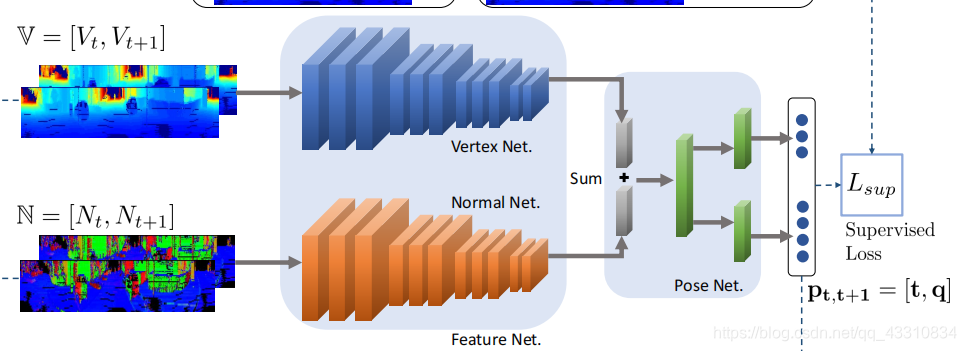
首先是第一部分,FeatureNet,FeatureNet由两个子模块组成,分别是VertexNet和NormalNet,从名字上就很好理解,就是用前面得到的整合输入F(2D点映射平面和法向量)作为分别的输入,VertexNet主要作用是根据平面的区别来计算逐点的平移特征,NormalNet是根据法向量区别来计算逐点的旋转特征,这俩都输出一个长维向量,叠加后作为最终的输出特征,也就是两帧之间的平移+旋转变换特征。
这个特征向量提取出来后,输入第二部分PoseNet,根据该输入和LO-NET一样,输出一个3D向量代表平移,4D元数代表旋转,这就是最终需要的位姿回归。
文中提到的是这俩网络组成都比较简单,基本都用残差块也就是Resnet那个和全连接组成,具体细节没有提及,就理解成一个像resnet一样的多层全连接就行,估计具体方法并不复杂。
接下来就是主要部分LOSS部分,这里给出了两种方式,一种监督学习,一种无监督学习
首先是无监督学习方式
对于每一个在t+1帧点云中的点vt+1,都可以理解成是由t帧点云的某个点vt所转换而成的,这个好理解,可以定义
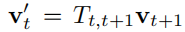
这里的Tt,t+1是一个4×4的旋转矩阵(常见的三维旋转矩阵,前面3×3是旋转,最后一竖列是平移),这个是网络得到的输出值计算得到,这里的vt‘就是假设存在该旋转矩阵的情况下对每个t+1时刻的点进行逆变换的,正常情况来说这里得到的应该就是vt,接下来用这样得到的点进行前面的V投影和N计算
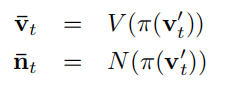
V就是前面的2D平面投影,N就是法向量计算,这样的话这里得到的新的v和t就应该是t+1时刻逆转换而得到的v和t,或者说尽可能的相似,于是就定义loss
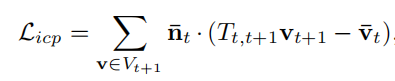
这里括号内的意思就是对t+1时刻的点进行逆转换,用逆转换的点坐标减去上面计算得到的坐标,再乘上法向量,其实计算的就是对应点之间的法向量距离之和
简单来说,Licp用一句话概括的意思就是将t+1时刻的点根据网络输出投影到t时刻,然后用得到的新点云计算和真正的t时刻点云的差距,这是一个没有label的过程,不过这里还是感觉写的有点奇怪,到底有没投影到2D平面进行计算,这里说的π函数的意思是投影函数,但又用了V和N,总的来说理解大致做法就行。
除此之外,还提出了一个视场损失LFOV,这个LOSS起到了一个正则化的作用
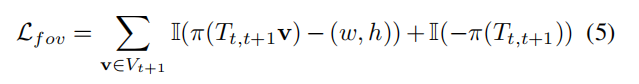
这里的II指的是heaviside函数,就是常用的0-1函数
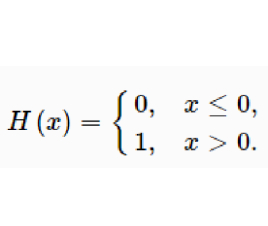
这里的w和h是平面的长和宽,简单来说,这里的意思就是希望预测的旋转量也就是Tt,t+1始终要落在合理范围内,也就是平面大小范围内,这是一个约束LOSS
最后将LOSS合并
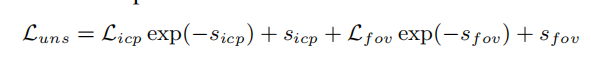
这里的S是比例因子,就是多LOSS聚合时ax+by的a和b,这里是采用的exp的方式控制LOSS均衡
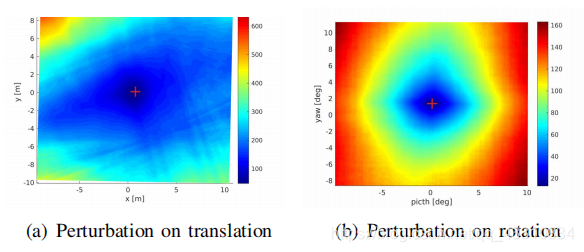
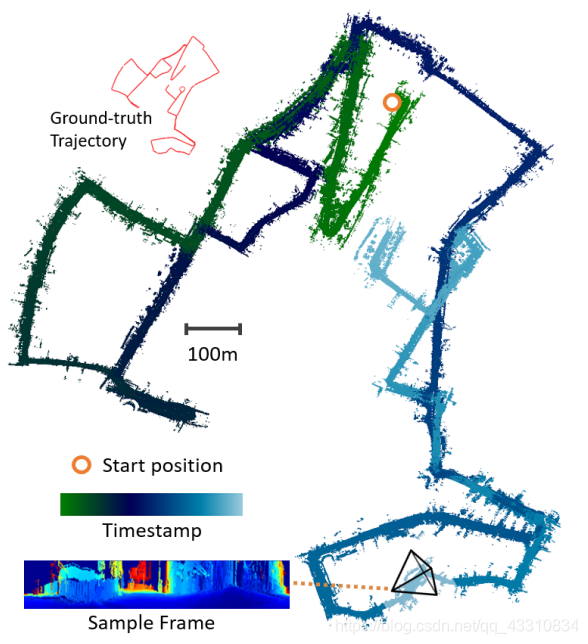
perturbation的意思是扰动,这里的红十字就是GT的位置,从图上颜色的渐变性可以看到这种无监督的方式是可训练的,GT周围是凸的
然后是第二种训练方式,监督式学习
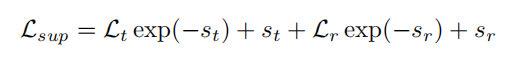
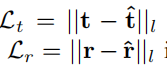
这里的t和r就是3D平移向量和4D旋转元数,s跟前面同样是均衡因子,由于存在GT的情况的话是存在这两者输出的Label,所以直接根据欧式距离来和网络输出的两个预测值进行计算LOSS就行
总结
1.文章声称是第一个用无监督学习来做这块的,但是我总感觉这种逆变化的做法算是比较常见的,可能在这方面没有涉及,并且也没用数学证明的方式证明有效,仅仅用画图的方式
2.这里采用的输入方式和LO-NET一样都是使用了映射的方式,但我始终感觉这种方式消耗资源过大,既然都要求法向量感觉可以试试跟PCT一样邻居embedding的方法。这两篇文章做法也是非常类似,不过好像都没提供源码,都不给试试和改进的机会。个人感觉这两篇能修改的地方主要是输入的嵌入方式和两个不同Net的交互性,当然LSTM这种也是很容易想到的

















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









