 Linux基础与实践:Vi/Vim编辑器、任务调度与磁盘管理
Linux基础与实践:Vi/Vim编辑器、任务调度与磁盘管理





 本文概述了Linux基础,涉及vmtools工具、远程登录、Vi/Vim编辑器(含快捷键)以及关机、重启操作。深入讲解了文件目录、时间日期、搜索查找、压缩解压等指令的使用,实践部分涵盖任务调度、磁盘分区与挂载技巧。此外,还介绍了GPU设置和占有量控制的方法。
本文概述了Linux基础,涉及vmtools工具、远程登录、Vi/Vim编辑器(含快捷键)以及关机、重启操作。深入讲解了文件目录、时间日期、搜索查找、压缩解压等指令的使用,实践部分涵盖任务调度、磁盘分区与挂载技巧。此外,还介绍了GPU设置和占有量控制的方法。
linux基础
1. Linux基础
学习Linux需要一个环境,我们需要创建一个虚拟机,然后在虚拟机( VM: virtual machine)上安装一个linux (CentOS)系统来学习.
终端的使用: 点击鼠标右键,即可选择打开终端,并可以配置相关的背景色.
字体缩放快捷键:
ctrl +shift +'+': 放大字体ctrl + '-'缩小字体
1.1 vmtools工具
vmtools安装后,可以让我们在windows下更好的管理vm虚拟机.
- 可以直接粘贴命令在windows和centos系统之间
- 可以设置windows和centos的共享文件夹
1.2 远程登录
- 远程登录到linux的软件XShell5: 如果希望安装好Xshell5可以远程访问Linux系统的话,需要有一个前提,Linux启用了SSHD服务,该服务会监听22号端口.
- 远程上传、下载的文件 xFtp5: Xftp 是一个基于windows平台的功能强大的SFTP、FTP文件传输软件.使用了xftp以后,windows用户能安全地在linux和windows PC之间传输文件.
1.3 Vi和Vim编辑器
所有的linux系统都会内建vi文本编辑器,Vim具有程序编辑的能力,可以看作Vi的增强版本,可以主动的以文字颜色辨别语法的正确性,方便程序设计.代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用.
1.3.1 三种常见模式
- 正常模式: 以vim打来一个文件就直接进入一般模式.在这个模式中,你可以使用「上下左右」按键来移动光标,你可以使用「删除字符」或「删除整行」来处理文件内容,也可以使用「复制、粘贴」来处理文件数据.
- 插入模式: 按i、l、o、O、a、A、r、R等任何一个字母之后才会进入编辑模式,一般来说按i即可
- 命令行模式: 在这个模式当中,可以提供你相关的指令,完成读取、存盘、替换、离开Vim、显示行号等动作则是在此模式中达成的.
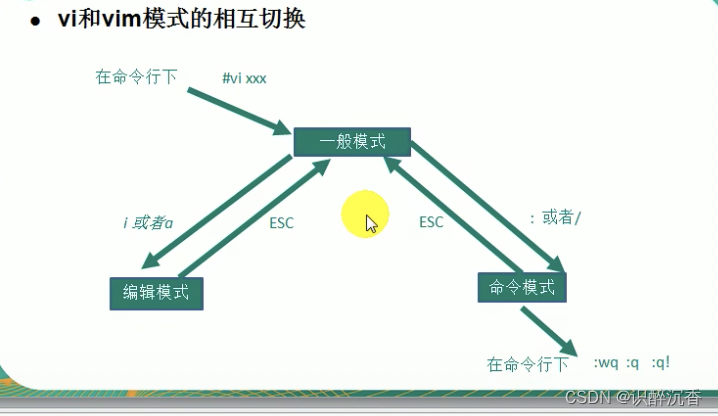
使用 vim python.py 新建打开文件 ----> 使用插入模式i进入编辑 ---->最后使用ESC进入命令行模式 wq 保存退出
1.3.2 Vi和Vim快捷键
- 拷贝当前行向下n行
nyy粘贴p - 删除当前行向下的n行
ndd - 查找
/关键字,回车查找,输入n就是查找下一个 - 设置文件的行号
: set nu,取消文件的行号:set nonu - 文档的最末行
G和最首行gg - 撤销
u - 将光标移动到第n行
:set nu—>n—>shift +g
1.4 关机、重启、用户注销
shutdown -h now: 表示立即关机halt关机reboot重启系统sync: 把内存的数据同步到磁盘
注意细节: 不管是重启系统还是关闭系统,首先要运行sync命令,把内存中的数据写到磁盘中.
2. 使用指令
2.1 文件目录类
| 命令 | 功能 | 备注 |
|---|---|---|
pwd | 显示当前工作目录的绝对路径 | |
ls | 查看当前目录的所有内容信息 | -a 显示全部 -l 以列表的方式显示信息 |
ls a* | 列出当前目录下以字母a开头的文件 | ls -l *.doc :列出当前目录下以.doc 结尾的所有文件 |
cd | 切换路径 | 1. cd - 当前目录和上一个目录来回切换 2. cd / 回到根目录 3. cd ~ 返回家目录 |
mkdir -p | 创建文件夹 | -p:递归创建 |
rmdir | 删除空目录 | 如果需要删除非空目录,需要使用rm -rf |
touch | 创建文件 | 可以一次性创建多个文件 touch a.txt b.txt |
cp | 复制文件/文件夹 | cp -r -v :-r 拷贝文件夹,-v:显示进度 cp -r test/ zhuht/ |
rm | 移除文件或目录 | -r :递归删除整个文件夹 -f: 强制删除不提示 |
mv | 移动/重命名 | 同一路径下,相当于重命名 |
cat | 只能查询当前文件的最后一屏幕 | -n显示行号 |
more | 展示第一页 | space下一页,enter 下一行,按q键退出,通常情况下两个结合使用cat -n /etc/profile | more |
less | 展示第一页 | pagedown下一页,pageup 上一页,按q键退出 |
> | 输出重定向 | ls -l > a.txt 列表的内容写入文件a.txt中 cat a.txt > b.txt 将a.txt的内容写到b.txt文件中 |
>> | 追加 | ls -al >> a.txt 列表的内容追加到文件a.txt的末尾 echo "内容" >>文件 |
echo | 输出内容到控制台 | echo $PATH 输出环境变量 |
head | 查看前多少行 | head -n 5 文件 查看文件头5行内容 |
tail | 输出文件中尾部内容 | -f 参数用于查看最新日志,实时追踪该文档的所有更新,tail -n 5 文件 查看文件后5行内容 |
ln | 软连接也叫符号连接,类似于window里的快捷方式,主要存放了链接其他文件的路径 | ln -s [原文件或目录] [软链接名] 删除软链接 rm -rf 软链接名 |
| history | 查看已经执行过历史命令,也可以执行历史指令 |
2.2 时间日期类
| 指令 | 功能 | 备注 |
|---|---|---|
date | 显示当前时间 | |
date +%Y | 显示当前年份 | |
date +%m | 显示当前月份 | |
date "+%Y-%m-%d %H:%M:%S" | 显示年月日时分秒 | |
data -s 字符串时间 | 设置当前系统时间 |
2.3 搜索查找类
| 指令 | 功能 | 备注 |
|---|---|---|
find [搜索范围] [选项] | 从指定目录向下递归地遍历其各个子目录,将满足条件的文件或者目录显示在终端 | 选项说明: -name<查询方式>: 按照指定的文件名查找模式查找文件; -user<用户名> 查找属于指定用户名所有文件; -size<文件大小>: 按照指定的文件大小查找文件 |
locate | 可以快速定位文件路径 | 由于locate指令集于数据库进行查询,所以第一次运行前,必须使用updatedb |
grep | 在文件中过滤查找 | -n显示匹配行及行号 -i忽略字母大小写 |
| | 管道:表示将前一个命令的处理结果输出传递给后面的命令处理 | cat hello.txt | grep yes |
应用实例
find . -name *.png
find . !-name *.png 找出当前目录不是以png 结尾的文件
find /var -mtime -5 查找在/var 下找更改时间在5天以内的文件
find . -type f -size -200M 查找小于200M的文件
2.4 压缩和解压类
| 指令 | 功能 | 备注 |
|---|---|---|
gzip | 用于压缩文件,原文件不保存 | gzip 文件 只能将文件压缩为*.gz文件 |
gunzip | 文件解压 | |
zip | 压缩文件或目录 | -r 压缩目录 zip -r mypackage.zip /home/ |
unzip | 解压 | -d 解压目录 unzip -d /opt/tmp/ mypackage.zip |
tar | 打包指令,最后打包后的文件是.tar.gz文件 | 选项: -c : 产生.tar打包文件; -v:显示详细信息; -f:指定压缩后的文件名;-z:打包同时压缩;-x解压.tar文件 |
tar -zcvf a.tar.gz a1.txt a2.txt # 压缩文件
tar -zxvf a.tar.gz # 解压文件
3. 实操
3.1 任务调度
任务调度: 是指系统在某个时间执行的特定的命令或程序. crontab进行定时任务的设置.
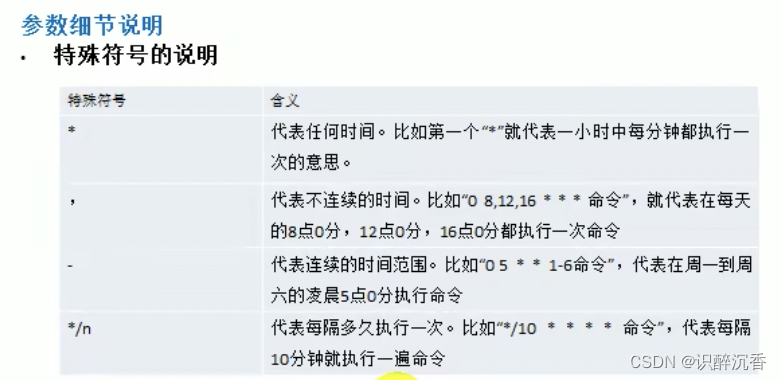
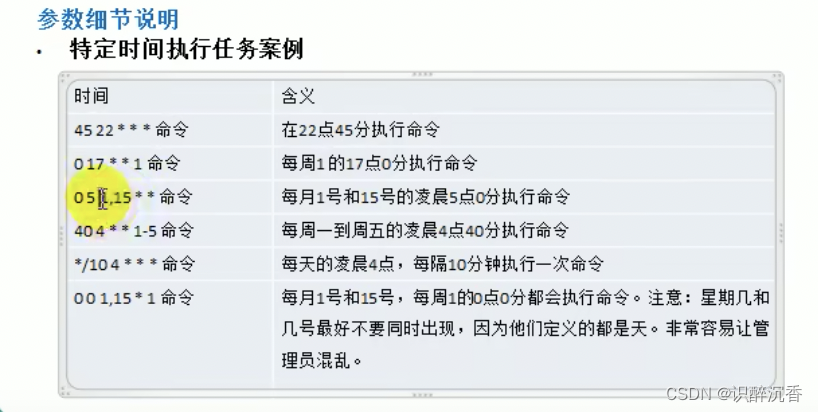
基本语法: crontab [选项]
crontab -e: 编辑crontab定时任务crontab -l: 查询crontab任务crontab -r: 删除当前用户所有的crontab任务service crond restart: 重启任务调度
简单的任务可以不用写脚本,可以直接在crontab中加入任务即可,例子步骤:
crontab -e进入任务编辑模式*/1*****ls -l /etc >> /tmpto.txt- 当保存退出后就生效
或者编写shell脚本:
- 先编写一个文件: mytask.sh ,内容
data>> /tmp/mydate - 给
mytask.sh一个可以执行权限chomd 744 mytask.sh crontab -e*/1***** mytask.sh

3.2 Linux磁盘分区、挂载
3.2.1磁盘情况查询
- 查询系统整体磁盘使用情况, 基本语法:
df -lh - 查询指定目录的磁盘占用情况:
du -ach /目录其他参数-s:指定目录占用大小汇总-h带计量单位-a含文件--max-depth =1字目录深度-c列出明细的同时,增加汇总值
工作实用指令:
-
ls -l /home | grep "^_" | wc -l统计文件数量 -
ls -l /home | grep "^d" | wc -l统计目录数量 -
ls -lR /home | grep "^_" | wc -l统计文件个数,包括子文件夹里的 -
tree: 以树状显示目录结构 -
echo:
将会在终端中显示的参数指定的文件,通常和重定向一起使用。 -
set命令:
用于设置所使用shell的执行方式,可依照不同的需求来做设置,set -x :执行指令后,会先显示该指令及所下的参数。
- 变量:
访问变量值:只需在变量名前加一个$
a=“hello world”
#打印变量的a的值
echo -e “A is : $a\n”
num=1
echo "this is the ${num}st"
a=10
b=20
if [ $a == $b ]
then
echo "a 等于 b"
elif [ $a -gt $b ]
then
echo "a 大于 b"
elif [ $a -lt $b ]
then
echo "a 小于 b"
else
echo "没有符合的条件"
fi
字符串比较
= 等于,如:if [ "$a" = "$b" ]
== 等于,如:if [ "$a" == "$b" ],与=等价
注意:==的功能在[[]]和[]中的行为是不同的,如下:
1 [[ $a == z* ]] # 如果$a以"z"开头(模式匹配)那么将为true
2 [[ $a == "z*" ]] # 如果$a等于z*(字符匹配),那么结果为true
3
4 [ $a == z* ] # File globbing 和word splitting将会发生
5 [ "$a" == "z*" ] # 如果$a等于z*(字符匹配),那么结果为true
整数比较
-eq 等于,如:if [ "$a" -eq "$b" ]
-ne 不等于,如:if [ "$a" -ne "$b" ]
-gt 大于,如:if [ "$a" -gt "$b" ]
-ge 大于等于,如:if [ "$a" -ge "$b" ]
-lt 小于,如:if [ "$a" -lt "$b" ]
-le 小于等于,如:if [ "$a" -le "$b" ]
大于(需要双括号),如:(("$a" > "$b"))
>= 大于等于(需要双括号),如:(("$a" >= "$b"))
Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
-eq 等于则为真
-ne 不等于则为真
-gt 大于则为真
-ge 大于等于则为真
-lt 小于则为真
-le 小于等于则为真
xargs 是给命令传递参数的一个过滤器,也是组合多个命令的一个工具。
xargs : 可以将管道或标准化输入stdin数据转化成命令行参数,也能够从文件的输出中读取数据
xargs: 也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行
find /sbin -perm+700 | ls -l
find /sbin -perm=700 | xargs ls -l
find . -name '*.py' | grep test 是将前面命令的标准输出作为标准输入传给grep test,那么grep 是从这些标准输入寻找test字符,最终选择出文件名
find . -name "*.py" | xargs grep test find 得到的文件名成为参数传给grep,grep按照正常的使用方式各文件中搜索字符串。
shell 指令
表示注释指令
;连续指令
$ 变量替换
$? 回传值:0成功 1失败 : 用于检查子进程的执行状态
$1就是代表你输入bai的第一个参数
$1 :表示为位置参数,表示传入的第一个参数
$#: 添加到Shell的参数个数
test.sh -f test 输入命令tesh.sh 填入的参数是 -f 和 test两个 ${1} 表示第一个参数
shell语句if [ ! -e "filename" ]
-e表示只要filename存在,bai则为真,不管dufilename是什么类型,
-e filename 如果bai filename存在,则为真
-d filename 如果 filename为目录,则为真
-f filename 如果 filename为常规文件,则为真
-L filename 如果 filename为符号链接,则为真
-r filename 如果 filename可读,则为真
-w filename 如果 filename可写,则为真
-x filename 如果 filename可执行,则为真
-s filename 如果文件长度不为0,则为真
-h filename 如果文件是软链接,则为真
将history命令执行的结果保存到history.log文件中
[root@gxzs-solr1 ~]# history > history.log (history.log 文件 会自动生成)
[root@gxzs-solr1 ~]# cat history.log
标准输入(stdin) 0 < 或 << System.in /dev/stdin -> /proc/self/fd/0 -> /dev/pts/0
标准输出(stdout) 1 >, >>, 1> 或 1>> System.out /dev/stdout -> /proc/self/fd/1 -> /dev/pts/0
标准错误输出(stderr) 2 2> 或 2>> System.err /dev/stderr -> /proc/self/fd/2 -> /dev/pts/0
` 指令:
执行结果能赋值给一个变量。它也被称为后引号(backquotes)或是斜引号(backticks).
例子:
A=ls -l
把ls -l的结果赋给A ls -l 作为命令来执行。
awk:一种处理文本文件的语言,一种文本分析工具
逐行扫描文件,从第一行到最后一行,寻找匹配特定模式的行,并在这些行上进行操作 -F 指定分隔符
awk 一次从文件中读取一条记录,并将记录储存在字段变量0中 'pattern {action}'
awk '/^$/ {print "Blink line"}' text.txt /^$/ 通过正则表达式匹配空白行,动作为打印Blink line
awk -f awk.sh text 提前编辑一个awk 脚本,通过-f 调用
cat awk.sh
'/^$/ {print "blink line"}'
echo hello the world | awk "{print $1,$2,$3 }"
echo hello the world | awk "{print NF}" NF 改行字段的个数
echo hello the world | awk "{print $NF}" 取最后一个字段
每行按 tab分割,输出文本的1,4 项
awk '{print "%-8s %-10s\n",$1,$4}' log.txt
过滤第一列等于2的行
awk '$1==2 {print $1 ,$3}' log.txt
awk '$1==2 && $2=="Are" {print $1,$2,$3}' log.txt
awk '$0=NR"\t"$0' file_name
$0=NR表示给文件赋值行号
"\t" 标识行号和其他文件用\t分隔
结尾$0代表文件的其他内容
使用正则,字符串匹配
#输出第二列包含"th",并打印第二列与第四列
awk '$2 ~ /th/ {print $2 ,$4}' log.txt ~ 表示模式开始 , //中是模式
忽略大小写
awk 'BEGIN{IGNORECASE=1} /this/' log.txt
模式取反 !
awk '$2 !~ /th/ {print $2,$4}' log.txt
awk 条件及循环语句
- if 条件判断格式
if(表达式)
action 1
else
action 2
或者 if(表达式)action 1; else action 2
df | grep 'boot' | awk '{if ($4 <20000) print "Alart" ; else print "ok"}' 判断boot分区可用容量小于20M时报警,否则显示OK
df :命令用于统计目前在linux系统上文件系统磁盘使用统计情况
- 循环
while(条件)
动作
x=1
while (i<10){
print S i
}
awk 'i=1 {} BEGIN {while (i<10) {++i ; print i}}' text.txt # BEGIN END 等为执行模式
sort
awk -F "|" "{print $6 $1 $4}" access.log | awk -F "time=" "{print $2}" | sort -k1nr | head -3
uniq
如果需要统计哪些接口每天的请求量最多,只需要引入uniq命令
我们可以通过grep -v HEAD access.log | awk -F "|" "{print $4}" 来筛选所有的url ,uniq 命令可以删除相邻的相同的行,而-c 可以输出每行出现的而次数
所以我们先把 url 排序以让相同的 url 放在一起,然后使用 uniq -c 来统计出现的次数:
grep - v HEAD access.log | awk -F "|" '{print $ 4}' |sort |uniq -c
接下来再 sort 即可:
grep -v HEAD access.log | awk -F "|" "{print $4}" | sort |uniq -c |sort -k1nr | head -3
应用实例
INPUT1=`${BIN_HADOOP} fs -ls ${USER_BEHAVIOR_PATH} | grep -E "/[0-9]{8}$" | tail -1 | awk -F ' ' '{print $NF}'`
++ /usr/bin/hadoop fs -ls /user/pub/LogServer
++ grep -E '/[0-9]{8}$'
++ awk -F ' ' '{print $NF}'
++ tail -1
+ INPUT1=/user/pub/LogServer/20200816
将执行情况保存日志
sh book_embedding.sh > log/book_embedding.log.2020090111 2>&1 &
测试集文件生成
hadoop中mapper or reducer函数的测试:
head -10 user_seq_graph.txt > input.txt
python3 bin/sim_test.py < test/input.txt
python3 bin/sim_test.py < test/input.txt > test/output.txt
vi test/output.txt
文件合并
cat file1.txt file2.txt > file.txt
cat file1.txt >> file2.txt
左右合并
paste
统计某个目录下的文件或目录个数: find -type f/d | wc-l
正则表达式:
^ 只匹配行首
$ 只匹配行尾
"^$"匹配空行
"^.$"匹配包含一个字符的行
. 匹配任意单字符
* 匹配0个或多个单字符
日常工作:
- 查看python版本:
which python - 切换python 版本:
source ../python.xxx/bin/activate - screen :
-m:即使目前已在作业中的screen作业,仍强制建立新的screen作业
-r: 恢复离线的screen作业
-R:先试图恢复离线的作业。若找不到离线的作业,即建立新的screen作业。 - 查看cpu的使用情况:
free -mh - 查看gpu的使用情况:
gpuinfo - 查看进程:
ps -aux | gerp "xxx.sh" - 查看目录下的文件大小:
du -sh * | sort -nr |head或du -sh folder - 查看磁盘的使用情况:
df -Th env查看当前进程中的环境变量,top查看进程,占据的cpu大小scp -r -Pnohup不挂断执行命令:
nohup java -jar app.jar >log 2>&1 & 最后一个&表示把条命令放到后台执行 tail -f nohup.out监视日志- 分屏:
sp水平分屏 (当前文件的上下分屏),ctrl+ww屏切换,退出全部分屏qall,vsp:垂直分屏 - cut 截取文件某些列
可以指定分割方式 -d 为自定义分割方式cut -d " " -f 2 test.txt - sed 文本编辑工具
#删除文件中的第i行
sed -i '1d' xx.csv
#截取文件的第50到100行
sed -n '50,100p' xxx.txt
#将文件中的空格替换成 \t
cat xx.txt | sed 's/ /\t/g'
- cat books/* | grep “内容” 返回内容出自拿一本书
cat ../infer2/book.list | awk '{print "hadoop fs -get rd/tts/txt/*/"$1".txt ./"}' > d.sh
- test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三方面的测试
if test $[num1] -eq $[num2]
if test -e ./file_path # -e 文件存在则为真, -d 如果文件存在且为目录则为真
快捷键
history :用户历史敲下的命令
ctrl +a 光标移动到行首
ctrl +e 光标移动到行尾
字符的删除:
ctrl +h 删除前面的字符
ctrl+b删除光标覆盖的字符
ctrl+u 删除光标前面的字符
more/less enter 一行行继续 space 一页页的显示,按q键结束
创建硬链接: ln 不加参数 -s,只能对文件创建硬链接,无法对目录创建硬链接
ln train.txt train.hard 硬链接不占磁盘空间
软连接:是一个就快捷方式,文件、目录均可以
光标的移动h j下 k 上 l
移动到行首 0
移动到行尾 $
移动到当前文件的头部 gg
尾部G
移动到500 行 500+G
删除
删除字符 x
删除前面字符X
删除单词 dw (注意:删除的是光标后面的单词)
删除光标前面的内容 d0 后面的内容d$ (或D)
删除当前行dd 删除多行 ndd
撤销 u 反撤销ctrl +r
复制粘贴
删除其实是剪切 然后 粘贴 p在下一行粘贴 P在当前行粘贴
复制: yy一行 nyy复制多行
替换单个当前字符 r
缩进向右>>
向左缩进<<
查看函数 ,跳转 shift +k
编辑模式
a 在光标之后插入内容 A 在行尾部插入内容
i 在 前面 I 行首
o创建新的一行(下一行) O 上一行
s 删除光标后面一个字符,编程插入模式 S 删除一行变为插入操作
替换
替换光标所在行,
:/s替换把内容/新内容
:/s替换把内容/新内容/g 替换本行所有
替换文本中所有行第一个匹配内容
:%s/旧内容/新内容
替换所有 :%s/旧内容/新内容/g
替换几行中的 :m,n/s/old_str/new_str/g
工作 :check 产出结果,产出文件数量不足的,重新跑任务
for i in `hadoop fs -ls rd/tts/nlp/output| awk '$6>="2020-10-17" {print $8}'` | awk -F "/" 'print$5'
do
cnt=`hadoop fs -ls rd/tts/nlp/output/$i | wc -l`
if [ $cnt -lt 18 ]
then
echo "重跑${$i}"
hadoop fs -rm -r rd/tts/nlp/output/$i
sh ctl.sh "all"
fi
done
从集群上下载list 中的所有资源
#方法一
mkdir books
cat tmp.txt | \
while read line_bid
do
bid=${line_bid}
hadoop fs -get rd/tts/txt/${bid}/${bid}.txt
done
#方法二:for 循环
curDIr=path
bookDir=""
for i in `cat ${curDir}/bookid_list.txt | awk '{print$1}'`
do
hadoop fs -get rd/tts/txt/${bookid}/${booklid}.txt ${bookDir}
done
运行不同的脚本生成系列文件,并将文件传输到集群中
curDir="data/rd/zhuhongtao/infer3"
PYTHON_ENV="/data/rd/zhujun/python3.7.4/bin/python"
mkdir -p ${curDir}/data
function put2hadoop(){
bookid="${1}"
localDir="${cirDir}/data/${bookid}"
hadoopDir="rd/tts/nlp/output/${bookid}"
hadoop fs -mkdir ${hadoopDir}
hadoop fs -rm ${hadoopDir}/*
hadoop fs -put ${localDIr}/* ${hadoopDir}
hadoop -rf ${localDir}
}
function parseInput(){
if [ $1 == "bookid:*" ]
then
echo "${1}" | awk -F ":" '{print $NF}'
elif [ $1 =="all" ]
then
ls ${curDir}/../books/
fi
}
function nlpDataFlow(){
parseInput $1 |\
while read line_bid
do
bookid=`echo "${line_bid}" | awk -F "." '{print $1}' `
ret=`echo "${bookid}" | awk 'if ($1~/^[0-9]+$/) {print "1"} else {print "0"}'`
if [$ret ==1]
then
echo "handle: ${bookid}"
else
echo "warning ${bookid}"
continue
fi
rm -rf ${curDir}/data/${bookid}
mkdir -p ${cuirDir}/data/${bookid}
echo "\t [get parser]"
${PYTHON_ENV} get_parser.py -b "${bookid}"
echo "\t [get snrs]"
${PYTHON_ENV} get_snrs.py -b "${bookid}"
echo "\t [get genders]"
python get_sex.py -b "${bookid}"
echo "\t [get speakers]"
python speakers.py -b "${bookid}"
echo "\t put results to hadoop"
put2haoop ${bookid} > ./hadoop.op.log 2>&1
done
}
if [ $# -lt 1}
then
echo -e "Usage:$0 <all| bookid:>"
exit -1
else
nlpDataFlow ${1}
fi
shell 编程中 0 代表True ,其他值代表false
比较两个文件是否有差异:
cmp prog.o.bak prog.o 文件相同,则不显示信息,文件不同,则显示第一个不同的位置
diff 以逐行的方式,比较文本文件的异同处。
设想我们有一个程序,需要在不同的参数下执行很多次,我们希望能够批量进行提交。我们希望这些任务是按照队列排队提交的,每次只执行3个。
#允许同时跑的任务数为THREAD_NUM
THREAD_NUM=3 #todo: revise me
args="""
北京 20200101
上海 20200202
深圳 20200303
广州 20200404
南京 20201001
天津 20200901
武汉 20201101
南昌 20200809
成都 20200901
""" #todo: revise me
#指定分隔符
IFS='
'
array=(${args})
#定义描述符为9的FIFO管道
mkfifo tmp
exec 9<>tmp # <> 读写方式, linux每一个打开文件都会关联一个文件描述符,需要的时候我们可以使用exec命令指定一个大于3的数字作为文件
rm -f tmp
'''
# echo "hello" > &4 向文件描述符中输入内容只是用> 和>>
exec 4 > /tmp/abc
echo "123" >&4
echo "456" >&4
则每次执行完脚本后/tmp/abc文件内容都是123\n456
'''
#预先写入指定数量的空格符,一个空格符代表一个进程
for ((i=0;i<$THREAD_NUM;i++))
do
echo >&9
done
for arg in ${array[@]}
do
#控制进程数:读出一个空格字符,如果管道为空,此处将阻塞
read -u9 # read 重定向时读取一行数据
{
#打印参数
#echo ${arg}
#此行代码指定任务提交方法
python task.py ${arg} #todo : revise me!
#每执行完一个程序,睡眠3s
sleep 3
#控制进程数:一个任务完成后,写入一个空格字符到管道,新的任务将可以执行
echo >&9
}&
done
wait
echo "全部任务执行结束"
GPU的设置和占有量控制
1.在终端执行程序时指定GPU
CUDA_VISIBLE_DEVICES=0 python your_file.py # 指定GPU集群中第一块GPU使用,其他的屏蔽掉
2.在Python代码中指定GPU
import os
os.environ["CUDA_VISIBLE_DEVICES"] ="0" # 指定第一个GPU
3.设置定量的GPU使用量
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.9 # 占用GPU90%的显存
session = tf.Session(config=config)
4.设置最小的GPU使用量
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
python -u xxx.py -u: 会强制其标准输出也同标准错误一样不通过缓存直接打印到屏幕


















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









