 Hadoop大数据处理框架详解
Hadoop大数据处理框架详解








一:Hadoop简介
优点:
1:Hadoop是开源免费的。
2:屏蔽了很多底层的复杂的实现,提供了方便用户操作的接口。
3:支持在Hadoop上多种语言开发应用
两大核心:分布式文件存储:HDFS 分布式文件处理:MapReduce
Hadoop成名原因:2008年4月利用910个结点的集群对1TB的数据进行排序,只用了209秒。引起大企业和高效对Hadoop进
行引入和研究。
特性:
1:高可用性 采用冗余副本的机制对数据进行备份,发生故障的机器不会影响数据的正常服务。
2:高效性:利用集群的优势,对大数据量的数据进行并行处理。
3:高扩展性:可以对集群的结点进行增加。
4:高容错性:当有系统发生故障的时候,能够提供正常服务。
Hadoop应用:
在企业中的应用可以用一张图表示:
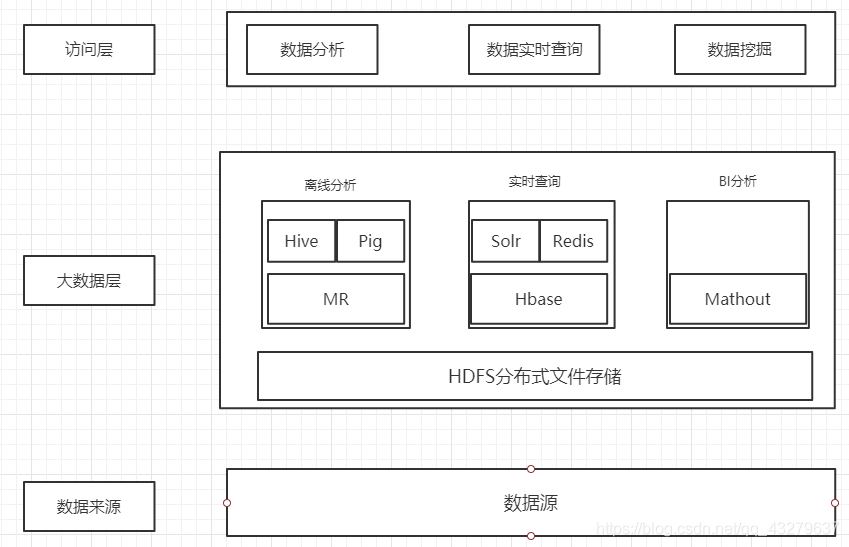
二:Hadoop项目结构
Hadoop的项目结构可以用下面这张图来理解
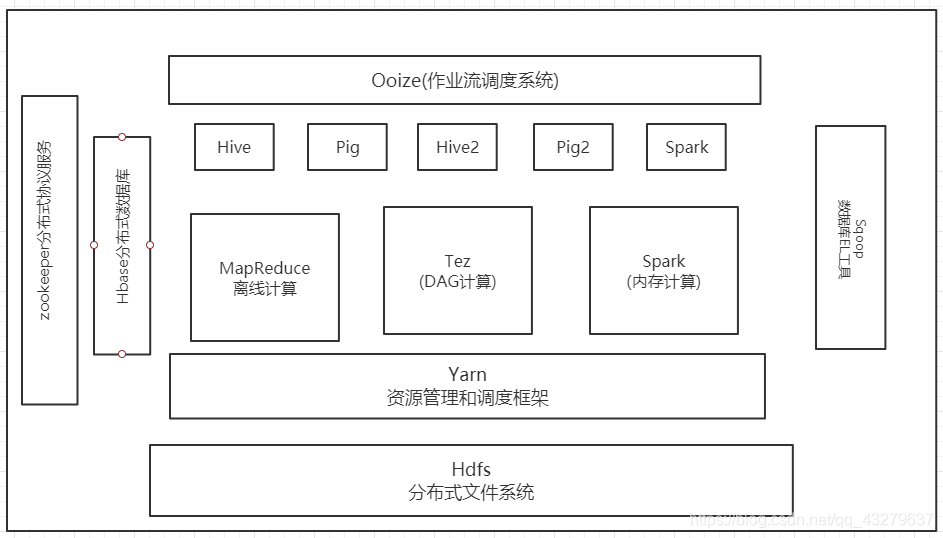
Hadoop2.0版本的框架图
1:最底层是Hdfs分布式文件存储,存储数据之后要对海量数据进行处理。
2:Yarn框架对资源进行调度。Yarn负责计算资源。包括内存,cpu,带宽等资源。
3:上层是具体的计算工作。
MapReduce:负责离线批处理计算,调用map,reduce处理数据。基于磁盘计算。处理的数据要写到磁盘中,处理后的
数据写到分布式文件系统中。
Tez:把Mapreduce作业进行分析优化,构建成一个有向无环图,获得最好的处理效率。确定工作的顺序,放置工作重复。
Spark:调用map,reduce处理数据。基于内存计算
Hive:实现数据仓库的功能。数据仓库是对大量的存储在数据流中的历史数据进行数据分析,做出企业的决策。可以通过
SQL语句对数据进行查询分析,Hive可以把你的SQL语句变成一系列的MapReduce作业去执行,批量处理作业。
Pig:流数据处理。提供类似于SQL的语法,Pig Latin。把这种语句嵌套到大型应用之中去。不采用MapReduce是因为需要
写很多代码,定义函数,定义变量等。但是采用pig这种轻量级的脚本语言,可以写一句执行一句。比较方便。
Ooize:工作流管理工具。控制作业的执行流程,先进行一个计算,在调用另一个计算。
zookeeper:提供分布式协调一致性,分布式锁,集群管理等。
Hbase:随机读写的面向列存储的分布式数据库。之后的文章会详细介绍。
Flume:流式数据库分析。比如记录用户信息的点击流,实时分析的话需要Flume记录用户行为信息。
Sqoop:提供数据的导入导出。关系型的数据导入到Hadoop方向上。把Hadoop方向上的数据导入到关系型的数据库
三:Hadoop集群的部署和使用
Hdfs分布式文件系统的结点:
NameNode(名称结点):充当一个目录的作用,外部访问数据的时候,先会访问NameNode数据节点,确定被划分的文
件具体存储在哪个文件系统中(即哪个DataNode)
DataNode(数据结点):存储数据的结点,一个集群一般会有若干个数据节点。
SecondaryNameNode:HDFS1.0中是冷备份,当NameNode down了之后需要一定的时间去恢复数据,不能立刻顶上去。
HDFS2.0中是热备份,当NameNode down了之后可以迅速代替NameNode工作
MapReduce的核心组件:
JobTracker:相当于一个作业管家,管理作业。把大作业拆分成一个个小作业,分发到不同机器上执行。
TaskTracker:每个执行小作业的机器会有TaskTracker执行作业。
企业在选择机器:
DataNode:
磁盘:4TB到8TB的磁盘空间
cpu:cpu至少需要2.5G HZ ,两个四核CPU 。
内存16-24个G 的机器。
NameNode:
需要在内存中保存元数据的映射表,需要很大的内存。
磁盘:4TB到8TB的磁盘空间。
cpu:两个四核或八核CPU 。
内存:16-72G的内存。内存需要通道优化,二通道到三通道的优化。
NameNode和JobTracker可以根据集群大小决定是否放在一个机器上。
一般集群会有很多机架。一个机架会有三四十台机器。机架内部几乎用1GB的交换机进行连接。机架和机架之间用更高的
交换机进行连接。
Hadoop部署在云环境的话比如部署在购买的百度云,阿里云等。直接通过远程登录的方式访问Hadoop集群


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









