






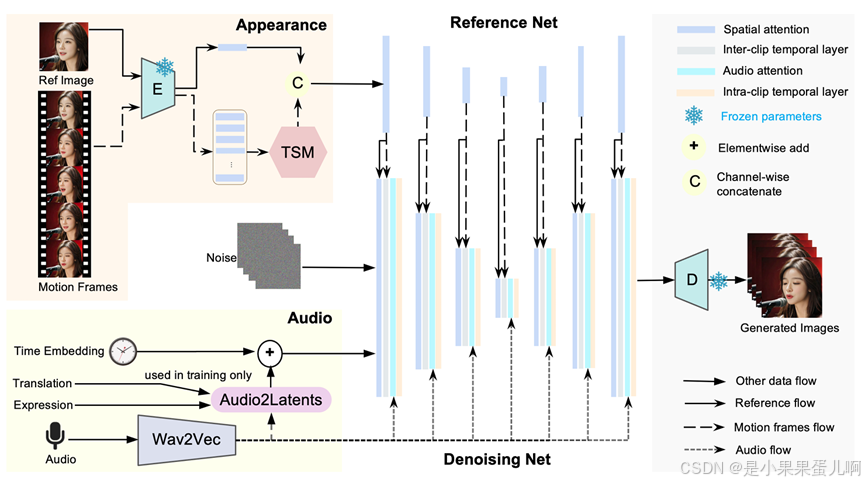
图2展示了Loopy的框架。该框架移除了现有方法中常用的脸部定位器(face locator)和速度层(speed layer)模块。相反,它通过提出的跨剪辑/内剪辑时间层(inter/intra-clip temporal layer)和音频到潜在变量模块(audio-to-latents module)实现了灵活且自然的运动生成。
上图中的各个模块解释:
1. 输入部分
3. 时间段模块(TSM)
4. 参考网络(Reference Net)
5. 去噪网络(Denoising Net)
6. 数据流和操作
7. 输出部分
8. 训练和推理
-
Ref Image(参考图像):输入的参考图像通过编码器 E 转换为潜在表示 C。
-
Motion Frames(运动帧):从之前的视频片段中提取的运动帧,用于提供运动信息。
-
Audio(音频):输入的音频信号通过 Wav2Vec 模块提取特征,并通过 Audio2Latents 模块转换为潜在表示。
-
2. 编码器和特征提取
-
编码器 E:将参考图像和运动帧转换为潜在表示 C。
-
Wav2Vec:从音频中提取特征,用于后续的音频条件处理。
-
Audio2Latents:将音频特征转换为潜在表示,用于与运动信息结合。
-
TSM(Temporal Segment Module):将运动帧分割成多个时间段,提取代表性运动帧,用于扩展跨剪辑时间层的覆盖范围。
-
参考网络:处理参考图像和运动帧的潜在表示,提取特征用于后续的时间注意力计算。
-
冻结参数(Frozen parameters):参考网络中的某些参数在训练过程中保持冻结,不参与更新。
-
去噪网络:核心模块,负责生成最终的视频帧。输入包括噪声、时间嵌入、参考特征、运动帧特征和音频特征。
-
跨剪辑时间层(Inter-clip temporal layer):处理跨剪辑的时间关系,结合运动帧和当前剪辑的特征。
-
内剪辑时间层(Intra-clip temporal layer):处理当前剪辑内部的时间关系,专注于当前剪辑的特征。
-
空间注意力(Spatial attention):处理空间特征,增强图像的细节。
-
元素级加法(Elementwise add):将不同特征进行逐元素相加,融合信息。
-
通道级拼接(Channel-wise concatenate):将不同特征在通道维度上拼接,增加特征的维度。
-
其他数据流(Other data flow):表示其他数据的流动,如噪声和时间嵌入。
-
参考流(Reference flow):表示参考图像特征的流动。
-
运动帧流(Motion frames flow):表示运动帧特征的流动。
-
音频流(Audio flow):表示音频特征的流动。
-
生成图像(Generated Images):去噪网络的输出,通过解码器 D 转换为最终的视频帧。
-
时间嵌入(Time Embedding):在训练过程中使用,提供时间步的信息。
-
翻译(Translation):在训练过程中使用,可能用于数据增强。
-
表情(Expression):在训练过程中使用,可能用于控制生成的表情。
-
音频注意力(Audio attention):将音频特征与去噪网络的特征结合,增强音频与运动的关联。
Loopy的框架和流程详细描述
1. 概述
Loopy框架基于Stable Diffusion(SD)构建,并使用其初始化权重。SD是一个基于潜在扩散模型(Latent Diffusion Model, LDM)的文本到图像扩散模型。它使用预训练的VQ-VAE将图像从像素空间转换到潜在空间。在训练过程中,图像首先被转换为潜在变量,即 z0=E(I)。然后根据去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM)在潜在空间中添加高斯噪声 ϵ 到潜在变量 z0,经过 t 步后得到噪声潜在变量 zt。去噪网络以 zt 为输入,预测噪声 ϵ。训练目标可以表示为:
![]()
其中,ϵθ 表示去噪网络,c 表示文本条件嵌入,在Loopy中,它包括音频、运动帧和其他影响最终生成的附加信息。
2. 输入和输出
在Loopy中,去噪网络的输入包括噪声潜在变量 zt、参考潜在变量 cref(通过VQ-VAE编码的参考图像潜在变量)、音频嵌入 caudio(当前剪辑的音频特征)、运动帧 cmf(前序剪辑的图像潜在变量序列)和时间步 t。在训练过程中,还涉及额外的面部运动相关特征:当前剪辑的面部关键点序列 clmk、头部运动方差 cmov 和表情方差 cexp。输出是预测的噪声 ϵ。
3. 双U-Net架构
去噪网络采用双U-Net架构,包括一个额外的参考网络模块,该模块复制了原始SD U-Net结构,但使用参考潜在变量 cref 作为输入。参考网络与去噪U-Net并行运行。在去噪U-Net的空间注意力层计算中,参考网络中相应位置的关键和值特征与去噪U-Net的特征在token维度上拼接,然后进行注意力模块计算。这种设计使去噪U-Net能够有效地结合参考图像特征。
4. 跨剪辑/内剪辑时间层设计
Loopy使用两个时间注意力层:跨剪辑时间层和内剪辑时间层。
-
跨剪辑时间层:处理运动帧潜在变量和噪声潜在变量之间的跨剪辑时间关系。
-
内剪辑时间层:专注于当前剪辑噪声潜在变量的时间关系。
跨剪辑时间层首先处理前序剪辑的运动帧潜在变量 cmf 和当前剪辑的噪声潜在变量。这些潜在变量通过参考网络进行特征提取,并在每个残差块中,将参考网络的特征 xcmf 与去噪U-Net的特征 x 在时间维度上拼接,并添加可学习的时间嵌入。然后在时间维度上计算自注意力。
内剪辑时间层的输入仅包括当前剪辑的噪声潜在变量特征,不包括运动帧潜在变量特征。通过分离双时间层,模型可以更好地处理跨剪辑时间关系中不同语义时间特征的聚合。
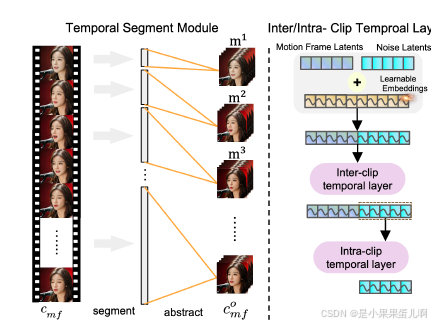
5. 时间段模块
为了增强跨剪辑时间层的能力,Loopy引入了时间段模块。该模块不仅扩展了跨剪辑时间层覆盖的时间范围,还考虑了不同剪辑与当前剪辑距离的变化信息。时间段模块将原始运动帧分割成多个段,并从每个段中提取代表性运动帧来抽象该段。基于这些抽象的运动帧,重新组合以获得后续计算的运动帧潜在变量。
时间段模块的输出 comf 可以定义为:

与现有方法(Emo, Hallo, Echomimic、V-express)通过单一时间层同时处理运动帧潜变量和噪声潜变量不同,Loopy 采用了两种时间注意力层:片段间时间层和片段内时间层(the inter-clip temporal layer and the intra-clip temporal layer)。片段间时间层处理运动帧潜变量和噪声潜变量之间的跨片段时间关系,而片段内时间层则专注于当前片段内噪声潜变量的时间关系,见下图的右边部分。
首先,我们引入了片段间时间层,它收集来自前一个片段的 m 个图像潜变量,称为运动帧潜变量 cmf 。与 cref 类似,这些潜变量通过参考网络逐帧处理以提取特征。在每个残差块中,从参考网络获得的特征 xcmf 与来自去噪 U-Net 的特征 x 在时间维度上进行拼接。为了让模型区分 cref 和 cmf ,我们添加了可学习的时间嵌入(在图2中没有体现, 在图3中有体现)。然后我们引入了片段内时间层,它的的不同之处在于其输入不包括来自运动帧潜变量,它仅处理当前片段的噪声潜变量的特征。
由于单独设计了一个片段间时间层,Loopy 能更好地建模片段之间的运动关系。为了进一步增强这一能力,我们还引入了时间分段(temporal segment)模块来选取运动帧,图 2 中没有绘制时间分段模块。该模块不仅扩展了片段间时间层覆盖的时间范围,还考虑了由于不同片段与当前片段的距离不同而导致的信息变化,如图 3 所示。时间分段模块包含segment和abstract两个步骤,segment步骤将原始运动帧划分为多个段,abstract步骤从每个段中提取代表性的运动帧以摘要该段。基于这些摘要出来的运动帧,我们重新组合它们以获取运动帧潜变量(motion frame latents)。
6. 音频条件模块
对于音频条件,首先使用wav2vec进行音频特征提取。然后将wav2vec网络的每层隐藏状态拼接以获得多尺度音频特征。对于每个视频帧,将前后两帧的音频特征拼接,形成当前帧的5帧音频特征,作为音频嵌入 caudio。
在每个残差块中,使用交叉注意力,其中噪声潜在变量作为查询,音频嵌入 caudio 作为键和值,计算注意力音频特征。然后将该特征添加到自注意力获得的噪声潜在变量特征中,得到新的噪声潜在变量特征。
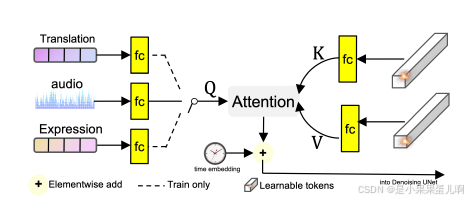
此外,引入音频到潜在变量模块(Audio-to-Latents module),将音频和面部运动相关特征(如关键点、头部运动方差、表情运动方差)映射到共享的运动潜在变量空间。这些潜在变量作为最终条件特征,增强音频和肖像运动之间关系的建模。具体来说,维护一组可学习的嵌入。对于每个输入条件,使用全连接层将其映射为查询特征,而可学习的嵌入作为键和值特征,通过注意力计算获得新特征,即运动潜在变量。这些运动潜在变量替换输入条件,用于后续计算。
7. 训练策略
-
条件掩码和dropout:在Loopy框架中,涉及多种条件,包括参考图像 cref、音频特征 caudio、前序帧运动帧 cmf 和表示音频和面部运动条件的运动潜在变量 cml。由于这些条件之间的信息重叠,为了更好地学习每个条件的唯一信息,在训练过程中使用不同的掩码策略。音频特征和运动潜在变量以10%的概率被掩码为全零特征。对于参考图像和运动帧,设计了特定的dropout和掩码策略。参考图像有15%的概率被丢弃,这意味着去噪U-Net在自注意力计算中不会拼接参考网络的特征。当参考图像被丢弃时,运动帧也会被丢弃。此外,运动帧有独立的40%概率被掩码为全零特征。
-
多阶段训练:采用两阶段训练过程。第一阶段,模型在没有时间层和音频条件模块的情况下进行训练。模型的输入是目标单帧图像的噪声潜在变量和参考图像潜在变量,专注于图像级别的姿态变化任务。完成第一阶段后,进入第二阶段,模型初始化为第一阶段的参考网络和去噪U-Net,然后添加跨剪辑/内剪辑时间层和音频条件模块进行完整训练,以获得最终模型。
-
推理:在推理过程中,使用多条件的类自由引导(class-free guidance)。具体来说,进行三次推理运行,不同之处在于是否丢弃某些条件。最终噪声 efinal 计算为:
-
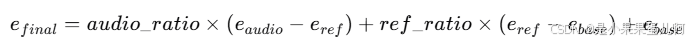 e 其中,eaudio 包括所有条件 cref、caudio、cmf、cml,但将 caudio 掩码为全零特征;eref 将 caudio 掩码为全零特征;ebase 将 caudio 掩码为全零特征,并在去噪U-Net的自注意力中移除参考网络特征的拼接。这种方法允许我们在参考图像的遵循程度和音频的对齐程度方面控制模型的最终输出。音频比率设置为5,参考比率设置为3。使用DDIM采样和25步去噪完成推理。
e 其中,eaudio 包括所有条件 cref、caudio、cmf、cml,但将 caudio 掩码为全零特征;eref 将 caudio 掩码为全零特征;ebase 将 caudio 掩码为全零特征,并在去噪U-Net的自注意力中移除参考网络特征的拼接。这种方法允许我们在参考图像的遵循程度和音频的对齐程度方面控制模型的最终输出。音频比率设置为5,参考比率设置为3。使用DDIM采样和25步去噪完成推理。 -
指标。我们使用 IQA 指标评估图像质量,使用 VBench 的平滑指标评估视频运动,并使用 SyncC 和 SyncD指标评估音视频同步。对于 CelebvHQ 和 RAVDESS 测试集,这些测试集有相应的GT视频,我们还将计算 FVD、E-FID和 FID 指标进行比较。此外,为了比较肖像的全局运动(记作 Glo)和动态表情(记作 Exp),我们基于鼻子和上半脸的关键点计算了方差值,特地排除了嘴部区域。我们还计算了真实视频的值作为比较的参考。对于缺乏GT视频的openset testset,我们进行了主观评估。邀请了十位经验丰富的用户评估六个关键维度:身份一致性、视频合成质量、音频情感匹配、运动多样性、运动的自然性和口型同步准确性。在每种情况下,参与者需要识别每个维度中表现最佳的方法。
根据论文中的实验结果和分析,Loopy方法在多个方面表现出色,具体性能总结如下:
1. 整体性能
-
高质量的视频生成:Loopy在多个测试集上表现出色,生成的视频在图像质量、运动平滑性、音频同步等方面均优于现有方法。
-
鲁棒性强:在不同类型的输入图像(真实人物、动漫、侧面脸、不同材质的人形工艺品)和音频(演讲、唱歌、说唱、情感丰富的语音)下,Loopy均能稳定生成高质量的视频。
2. 具体指标
2.1 图像质量
-
IQA(图像质量评估):Loopy在CelebV-HQ和RAVDESS测试集上的IQA指标均高于其他方法,表明生成的图像质量更高。
-
CelebV-HQ:Loopy的IQA为3.780,优于Hallo(3.505)、VExpress(2.946)和EchoMimic(3.307)。
-
RAVDESS:Loopy的IQA为4.506,优于Hallo(4.393)、VExpress(3.690)和EchoMimic(4.504)。
-
2.2 音频同步
-
Sync-C 和 Sync-D:Loopy在音频同步指标上表现良好,生成的视频与音频同步效果更佳。
-
CelebV-HQ:Loopy的Sync-C为4.849,Sync-D为8.196,优于其他方法。
-
RAVDESS:Loopy的Sync-C为4.814,Sync-D为7.798,优于其他方法。
-
2.3 运动平滑性
-
Smooth:Loopy生成的视频在运动平滑性上接近真实视频,优于其他方法。
-
CelebV-HQ:Loopy的Smooth为0.9949,接近真实视频的0.9964。
-
RAVDESS:Loopy的Smooth为0.9923,接近真实视频的0.9917。
-
2.4 运动多样性
-
Glo(全局运动)和 Exp(表情运动):Loopy在全局运动和表情运动的多样性上表现优异,生成的视频更具动态感。
-
CelebV-HQ:Loopy的Glo为2.233,Exp为0.452,优于其他方法。
-
RAVDESS:Loopy的Glo为2.962,Exp为0.343,优于其他方法。
-
2.5 情感表达
-
E-FID:Loopy在情感表达指标上优于其他方法,生成的视频在情感表达上更接近真实视频。
-
RAVDESS:Loopy的E-FID为3.132,优于Hallo(3.785)、VExpress(3.901)和EchoMimic(3.350)。
-
3. 用户主观评价
-
Openset 测试集:在用户主观评价中,Loopy在多个维度上均获得最高评分,包括身份一致性、视频合成质量、音频情感匹配、运动多样性、运动自然性和唇部同步准确性。
4. 消融研究
-
关键组件的有效性:通过消融研究,验证了Loopy中关键组件(如跨剪辑/内剪辑时间层和音频到潜在变量模块)的有效性。这些组件显著提升了视频生成的质量和稳定性。
-
长期运动依赖的影响:通过调整时间段模块的参数(如 stride 和 expand ratio),Loopy能够更好地捕捉长期运动依赖,生成更自然的运动。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









