






Spring生命周期
扫描并且得到所有的BeanDefinition
Spring会先扫描整个容器中可以成为Bean对象的那些实体类,扫描流程从ClassPathBeanDefinitionScanner.doscan方法进入
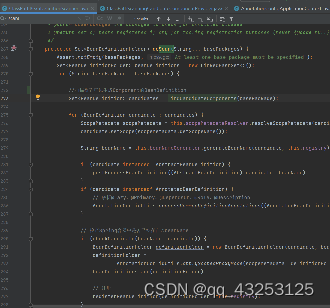
得到BeanDefinition:根据ComponentScan传入的扫描路径,通过findCandidateComponents(basePackage)方法扫描传入路径下并且生成该路径下所有BeanDefinition,然后将其注入到BeanDefinitionMap中进行缓存,用于后续的Bean对象的生成
findCandidateComponents(basePackage):扫描得到可以生成Component的BeanDefinition,该方法中的scanCandidateComponents(basePackage)方法会根据传入的路径得到其对应的resource资源,然后使用MetaDataReader(元数据读取器)解析Resource对象,通过isCandidateComponent方法走includeFilters和excludeFilters(黑名单)的判断,只有经过了这层筛选,然后才会生成ScannedGenericBeanDefinition(),然后会对BeanDefinition中的属性值做初始化设置,比如是否添加了@Primary注解,@Lazy注解,通过解析这些注解将其注入到该BeanDefinition对象所对应的属性值中,用于后续Bean生成;完成这些步骤之后通过DefaultListableBeanFactory.registerBeanDefinition(definitionHolder, this.registry)->this.beanDefinitionMap.put(beanName, beanDefinition)将其缓存到BeanDefinitionMap中
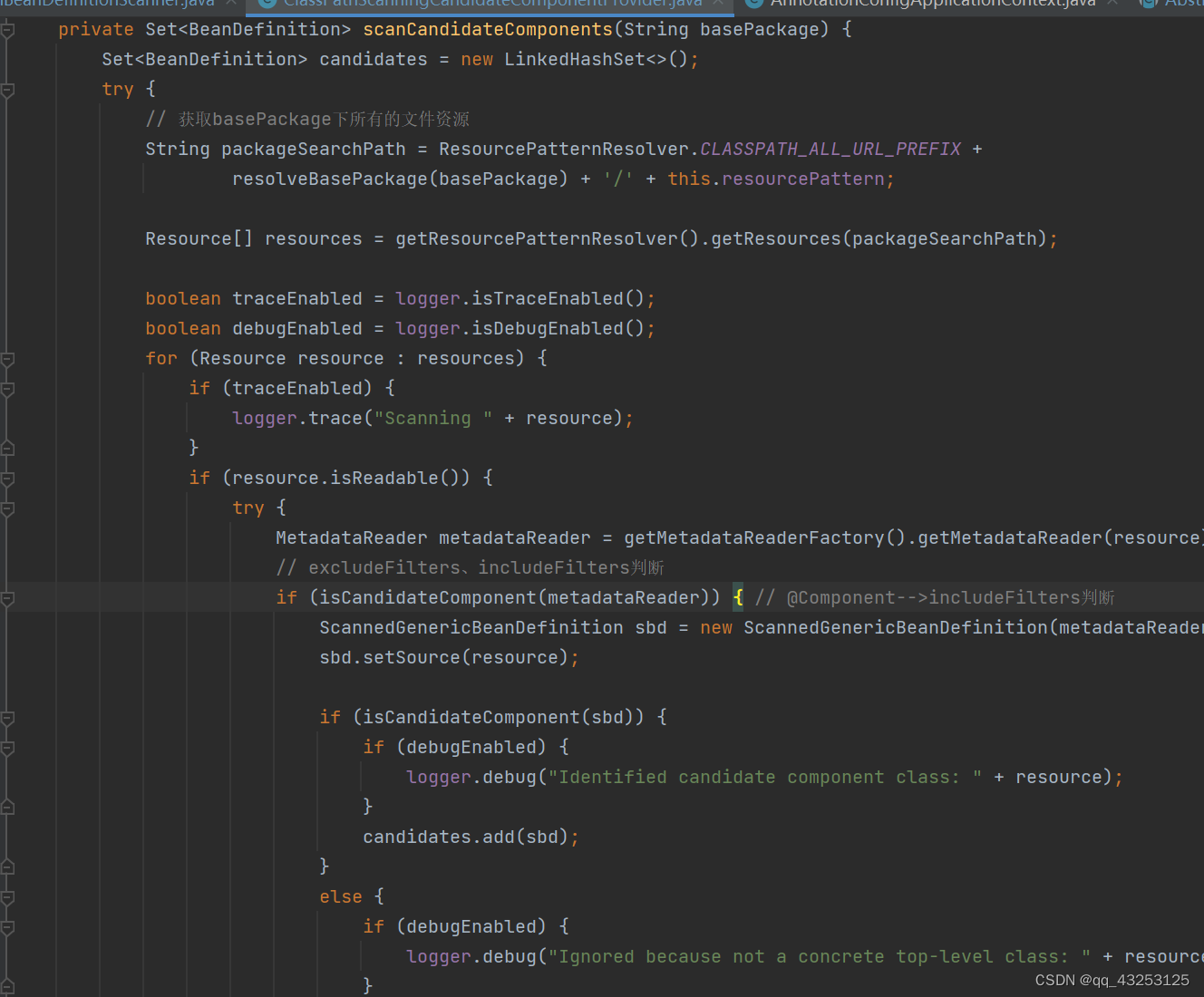
通过doScan得到了所有我们需要的BeanDefinition,这样就拥有了生成Bean对象的条件,然后我们再去初始化Bean
初始化所有非拦截的单例Bean
AnnotationConfigApplicationContext.refresh()→finishBeanFactoryInitialization(beanFactory)→beanFactory.preInstantiateSingletons():该方法会初始化所有非懒加载的单例Bean
该方法中会先根据BeanDefinition是否拥有父BeanDefinition合并生成最终的BeanDefinition(会继承父BeanDefinition中的属性)
继承规则:如果子BeanDefinition中没有该属性,则会继承父中的属性,最终会生成一个BeanDefinition缓存到mergedBeanDefinitions中,注意这边不会在原有的BeanDefinition上所修改,他会新生成一个对象
AbstractBeanFactory.getMergedBeanDefinition
mbd = ((RootBeanDefinition) bd).cloneBeanDefinition();克隆得到新对象
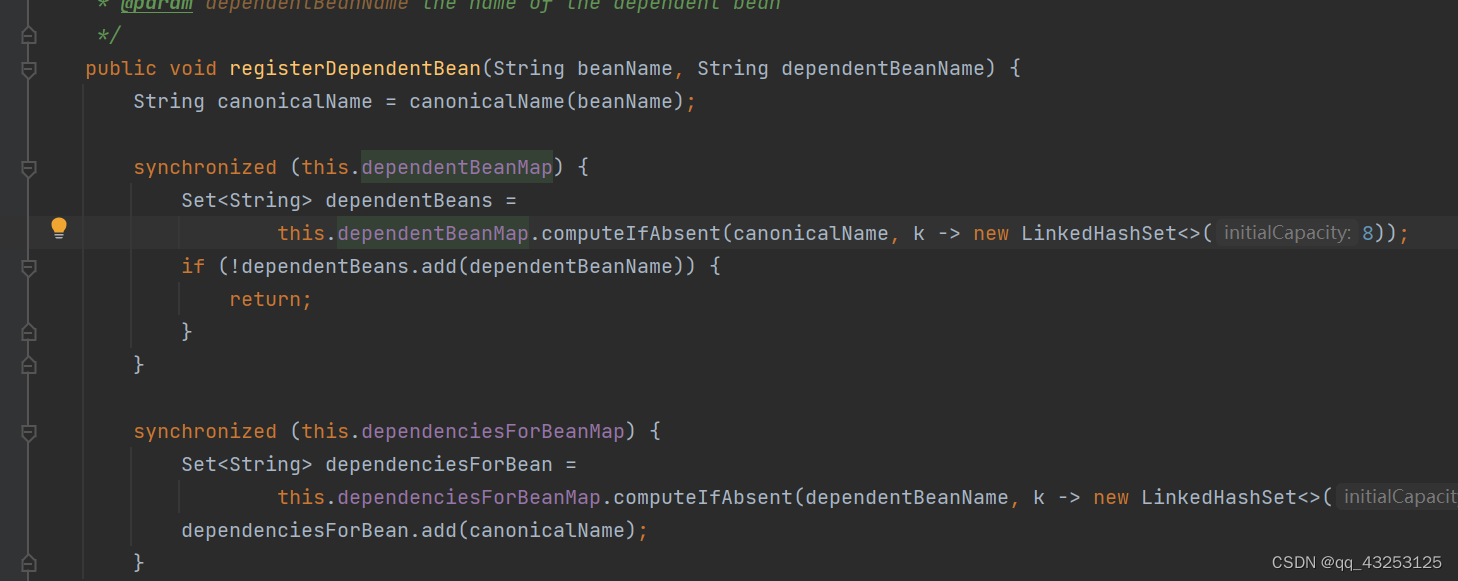
this.mergedBeanDefinitions.put(beanName, mbd);然后将其缓存到合并Map中
合并完属性之后,会根据是否实现了FactoryBean接口再做分支判断,如果是FactoryBean,那么真实会存两份数据,一份存于singletonObjects中,一份会存于FactoryBean所对应的Map中(存放FactoryBean所实现的getObejcts方法返回的对象)
最终都会调用getBean方法去创建Bean
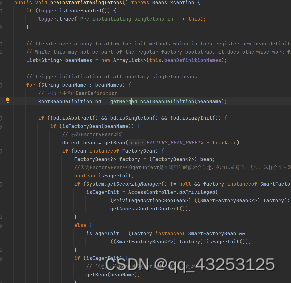
doGetBean()
getBean方法中主要大致主要分为以下几个分支
先去单例池中拿数据,如果拿到了,解析得到真实名字,因为@Bean注解中会有别名的东西 ,会将别名缓存到aliasMao中,如果是的话,通过传入的别米娜得到真实的BeanName,然后去单例池中拿对象,通过得到的对象判断是否是FactoryBean,如果是那么再去判断传进来的名字是否是&开头的名字,如果不是的话,那么会去调用FactoryBeanMap中存的对象,也就是FactoryBean.getObject()中返回的对象;
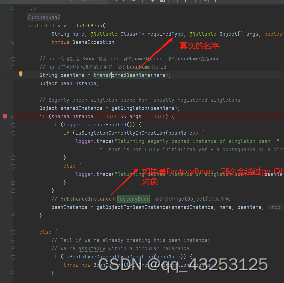
else分支:
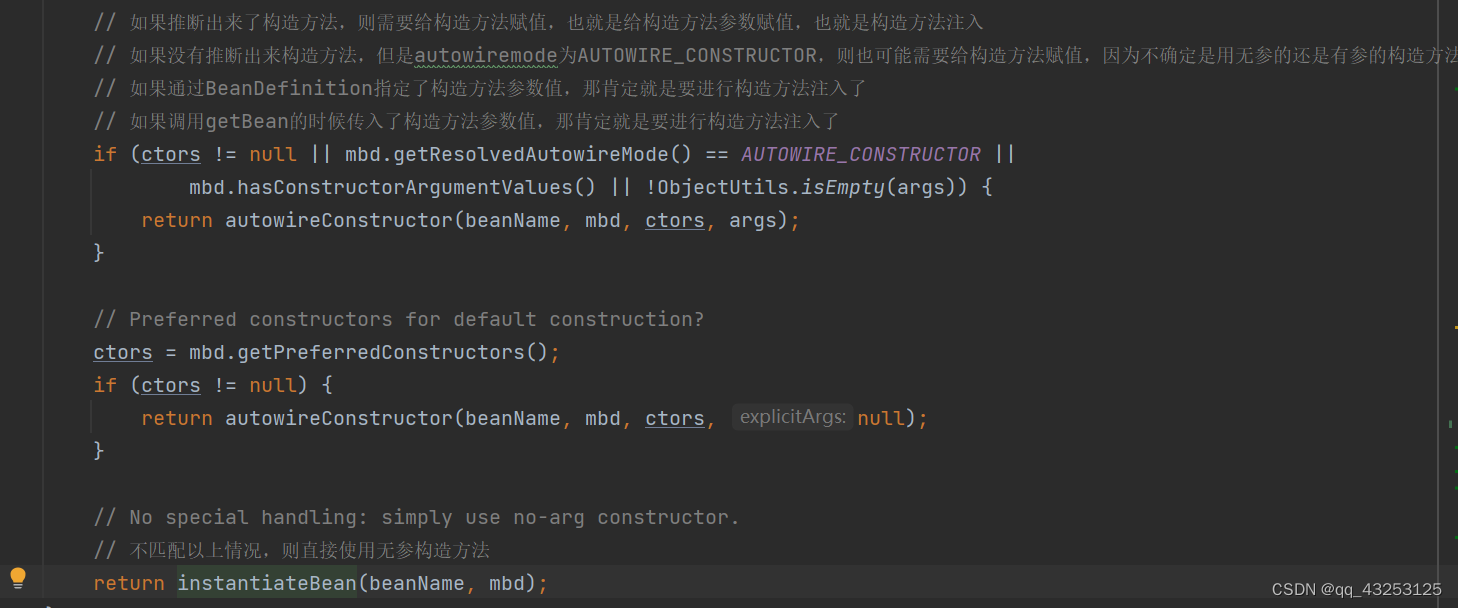
1.也就是说还没有在单例池中缓存数据,那么会先合并父子容器,因为每个BeanFactory也都会有其Parent属性,如果在当前容器中找不到Bean对象,那么会去父容器中找;
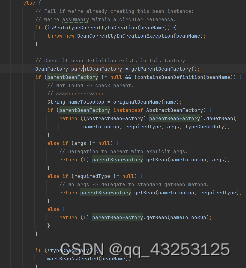
2.然后会根据MergedBeanDefinition去生成对应的Bean,再过程中,会先去判断次BeanDefinition是否是抽象的(类似于模板,这些BeanDefinition可以被继承属性但不能生成Bean对象),并且也会判断该BeanDefinition中是否有dependsOn属性(对应@DependsOn注解),如果存在的话,则会去先生成DependsOn注解所写的对象,意思就是该对象想创建的话,必须先创建dependsOn注解中的对象,如果A和B互相依赖的话,Spring并不会处理这种情况下的循环依赖,会直接报错,如果正常逻辑走通,那么会将其存入到两个缓存Map中,代表A依赖了B,B被A依赖
3.最终经过前面的一系列校验之后就会去创建Bean,Spring中经常会使用这种得不到就传入Lambda表达式去创建对象的格式
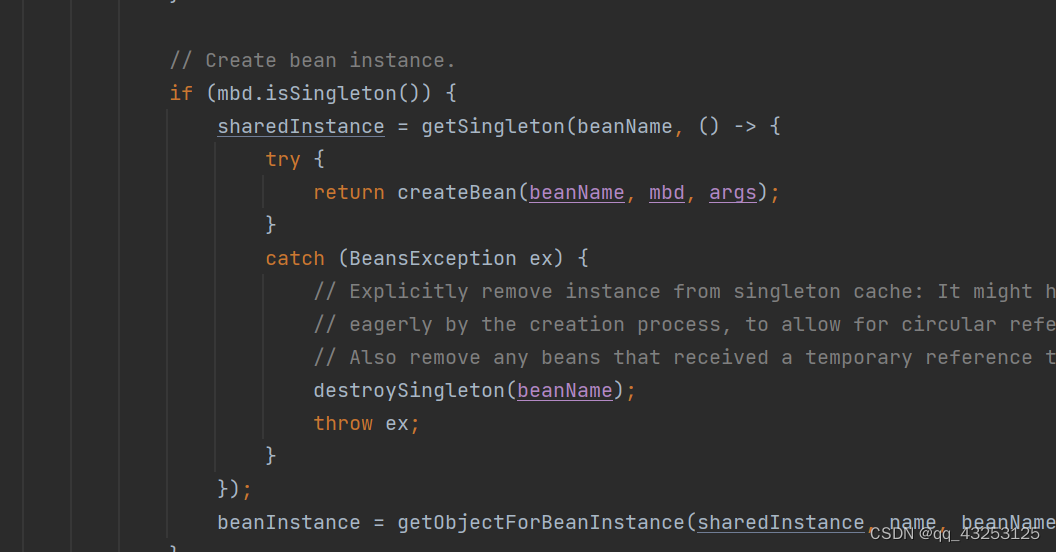
createBean():创建Bean
创建Bean的流程主要分为以下几个步骤
1.resolveBeforeInstantiation(beanName, mbdToUse);实例化前
2.createBeanInstance(beanName, mbd, args);实例化
3.applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);寻找注入点
4.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)实例化后
5.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);属性填充
6.applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);初始化前
7.invokeInitMethods(beanName, wrappedBean, mbd);初始化
8.applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);初始化后
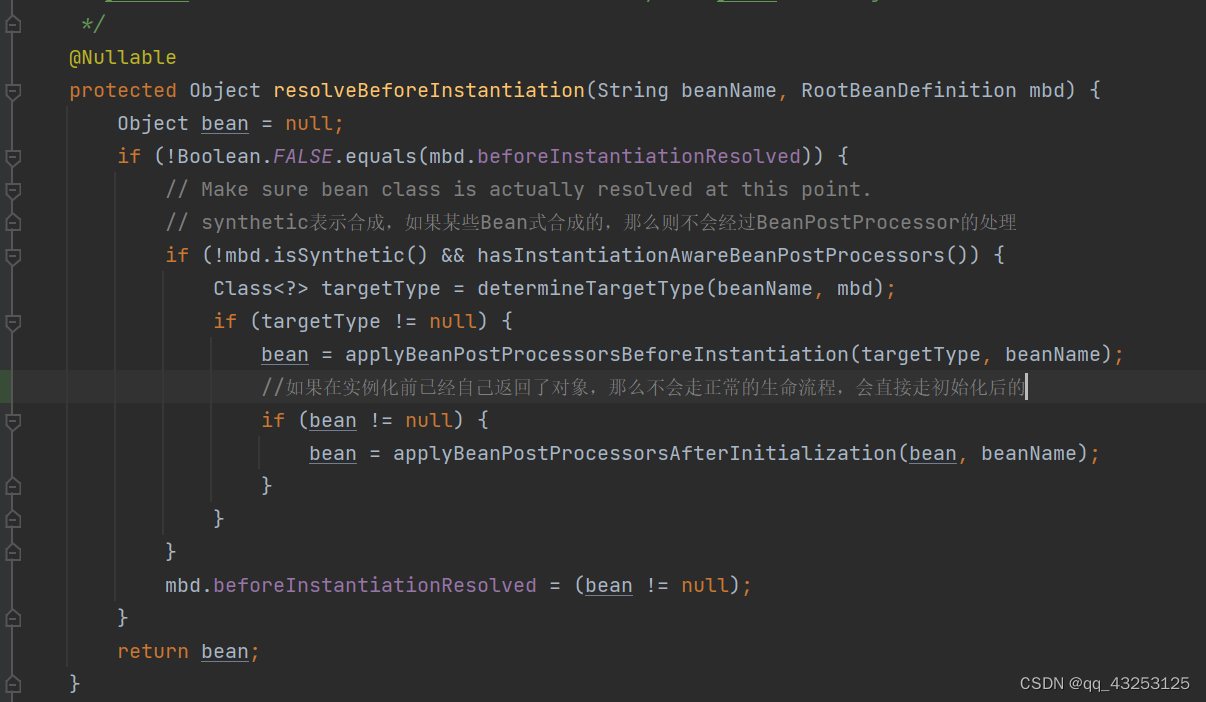
实例化前:
实例化前可以自己去生成Bean对象,如果这样设置了,那么就不会走Bean的生命周期了,会直接跳到初始化后那块,主要处理逻辑
InstantiationAwareBeanPostProcessor.postProcessBeforeInstantiation():可以由用户自己去实现这个接口,然后重写这个方法
实例化:
createBeanInstance中的主要逻辑会去推断他的构造方法,以及调用@Bean对应的BeanDefinition去生成Bean
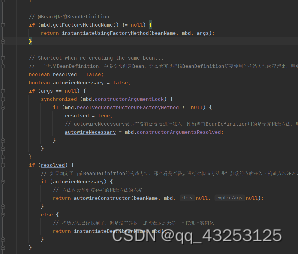
寻找注入点
applyMergedBeanDefinitionPostProcessors:实例化出对象之后就得去给这个对象的属性赋值,在赋值之前得先去找到这些属性该对应的赋什么值,@Resouce和@Autowired锁对应的实现类是下面两个
AutowiredAnnotationBeanPostProcessor->@Autowired
CommonAnnotationBeanPostProcessor->@Resource
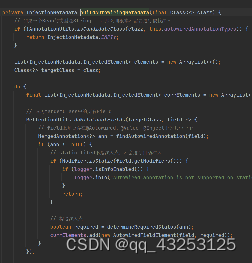
这边以AutowiredAnnotationBeanPostProcessor举例子,每个对象中的属性包括有加了@Value,@Autowired,@inject注解的属性或者在方法中也可以加@Autowired注解,如果在方法中加了注解,那么会将方法参数当成一个注入点
所以总体会生成大致两种类型,
currElements.add(new AutowiredFieldElement(field, required));//属性对应
currElements.add(new AutowiredMethodElement(method, required, pd));//方法参数对应
在找到这些注入点之后会将其缓存到currElements中,后续在属性填充的时候会再拿出来进一步操作
最终会封装currElements将其放入injectionMetadataCache中->return InjectionMetadata.forElements(elements, clazz); this.injectionMetadataCache.put(cacheKey, metadata);
实例化后:实例化后用的很少,我也不知道干啥用
属性填充:
属性填充可以认为就是Spring的依赖注入,我们通常用的就是在属性上加注解以此来标识这个属性会去自动的被赋值,在Spring中还有一种方法可以去自动注入值,
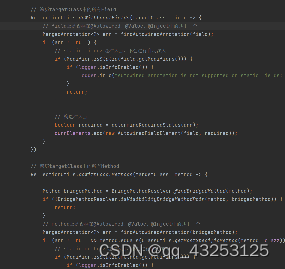
@Bean(autowire = Autowire.BY_NAME/Autowire.BY_TYPE),在@Bean中有这样一个属性,会对应Spring以下的代码。如果走的是name分支,那么会去找到当前Bean中所有的set方法, 比如setName,会将name作为名字去Spring的单例池中寻找名字为name的Bean,然后将其注入到set方法对应的参数中,如果是type,那么会根据方法所对应的参数类型寻找,然后再去注入到set方法的参数中,这种写法因为会覆盖所有的set方法,所以不能人为的控制哪些属性需要被注入,哪些不需要,后面就逐渐被@Autowired等注解代替;
通过这种方式注入的属性并不会直接注入,pvs.add(propertyName, autowiredArgument),而是会将其缓存到pvs中,最后才会去注入,这种方式如果核@Autowired的情况冲突了,那么以这种方式为主,他会覆盖@Autowired注解和@Resource注解等注入的值
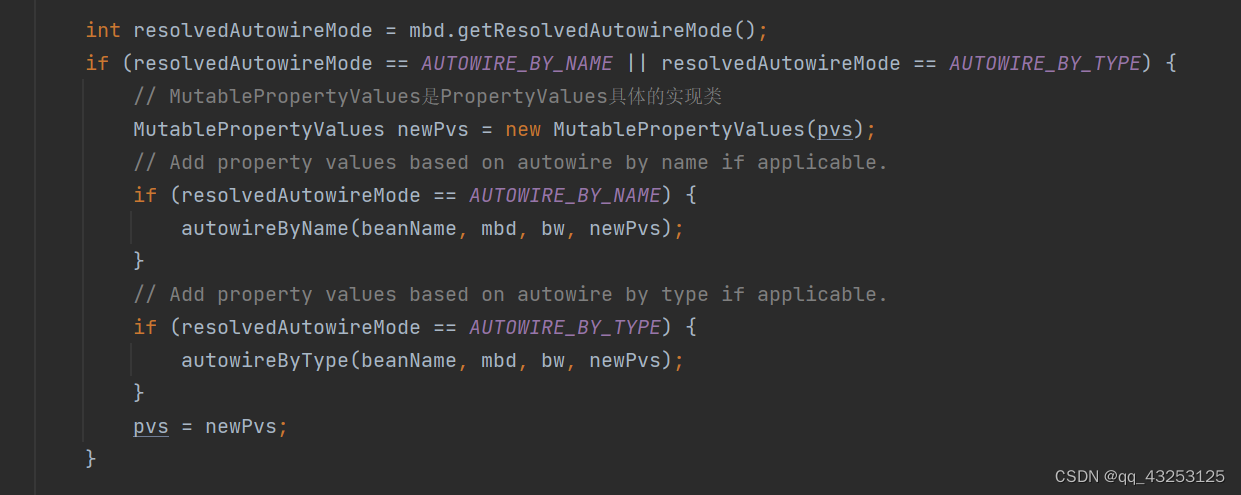
在applyMergedBeanDefinitionPostProcessors中寻找到对应的注入点之后,会将其缓存,缓存之后的属性会在
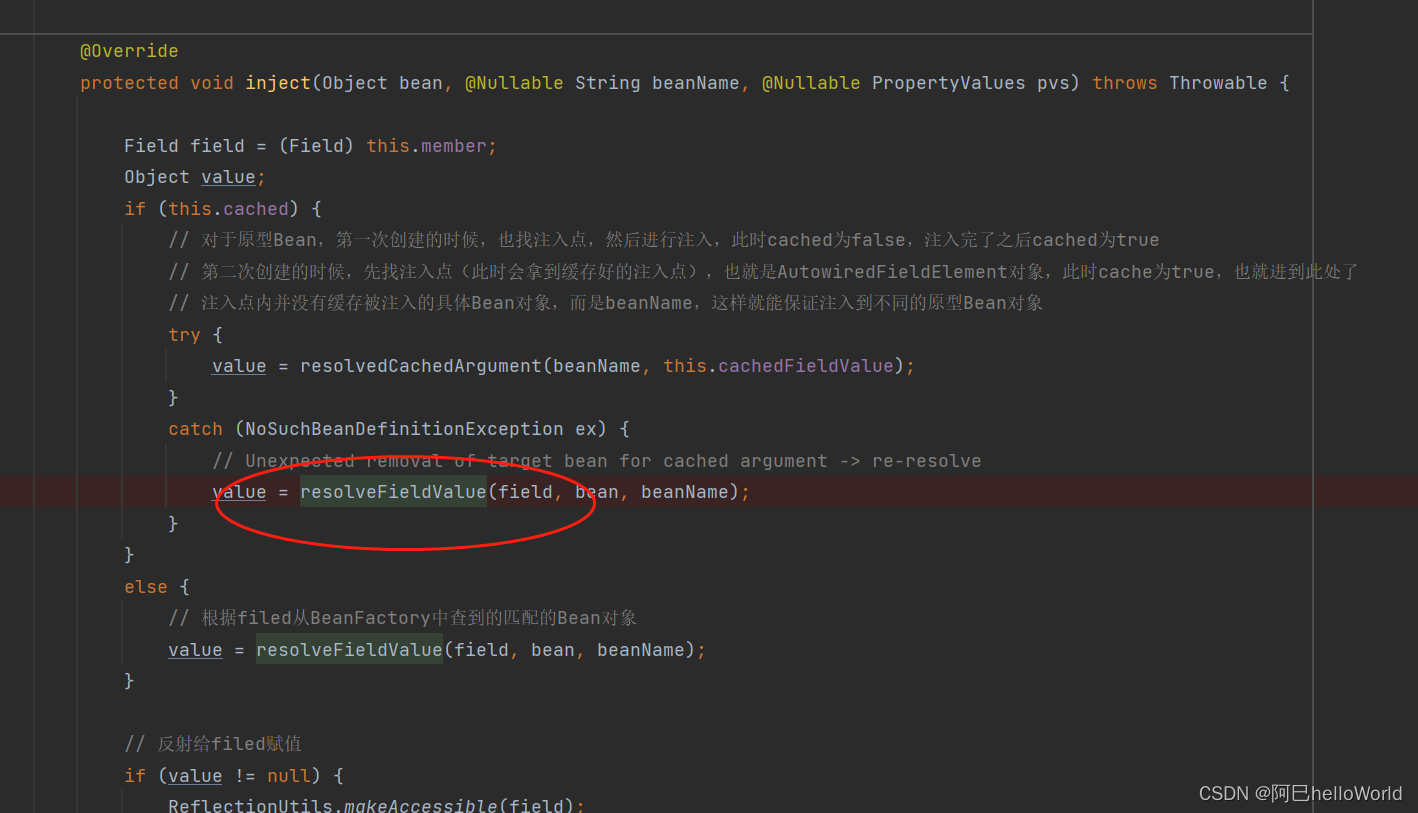
AutowiredAnnotationBeanPostProcessor.postProcessProperties其中去赋值,底层会去调用
AutowiredAnnotationB eanPostProcessor.inject去完成注入,在inject方法中尤为重要的是resolveFiedValue方法,底层会调用到this.beanFactory.resolveDependency:此方法会为你找到唯一适配的Bean对象,如果找到的Bean对象有多个,会先去判断是否有Primary注解,是否有Priority权限排序,最后再根据name匹配的方式确定唯一Bean
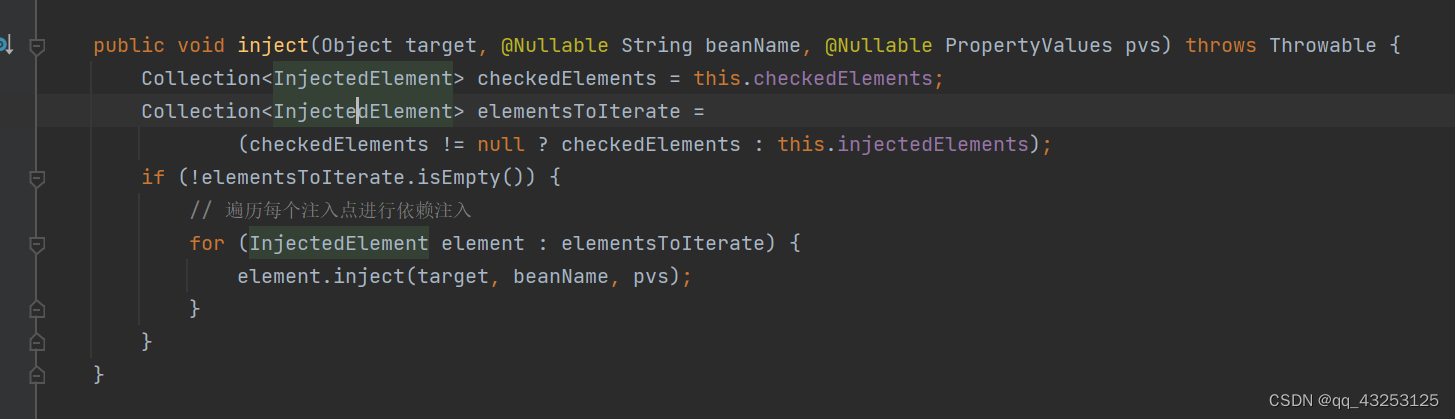
 通过上述的依赖注入,实际上已经形成一个可用的Bean了,但是可能会通过set方法自动注入,上述会去缓存到pvs中,那么这种情况会在applyPropertyValues(beanName, mbd, bw, pvs);中去处理
通过上述的依赖注入,实际上已经形成一个可用的Bean了,但是可能会通过set方法自动注入,上述会去缓存到pvs中,那么这种情况会在applyPropertyValues(beanName, mbd, bw, pvs);中去处理

实例化完之后,就会进行对象的初始化,主要分为初始化前,初始化,初始化后三个步骤,初始化和初始化前我用的比较少,这边不做细解,初始化后的可以去通过动态代理为其生成代理对象,然后去做动态代理的增强
在生成代理对象之后会去判断当前正在生成的Bean是否是跟切面类有关的这些类型,isInfrastructureClass(bean.getClass()),如果是的话就不会再去创建了。
主要逻辑在于这一行,getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null),Aop简单可以理解成一个PointCut和一个Adcive组成的Advisor,Advice是增强逻辑,PointCut就是要切入的地方;
所以这一行是在根据Pointcut进行匹配
AopUtils.findAdvisorsThatCanApply(candidateAdvisors, beanClass);->canApply(candidate, clazz)->AopUtils.canApply(Pointcut pc, Class<?> targetClass, boolean hasIntroductions)
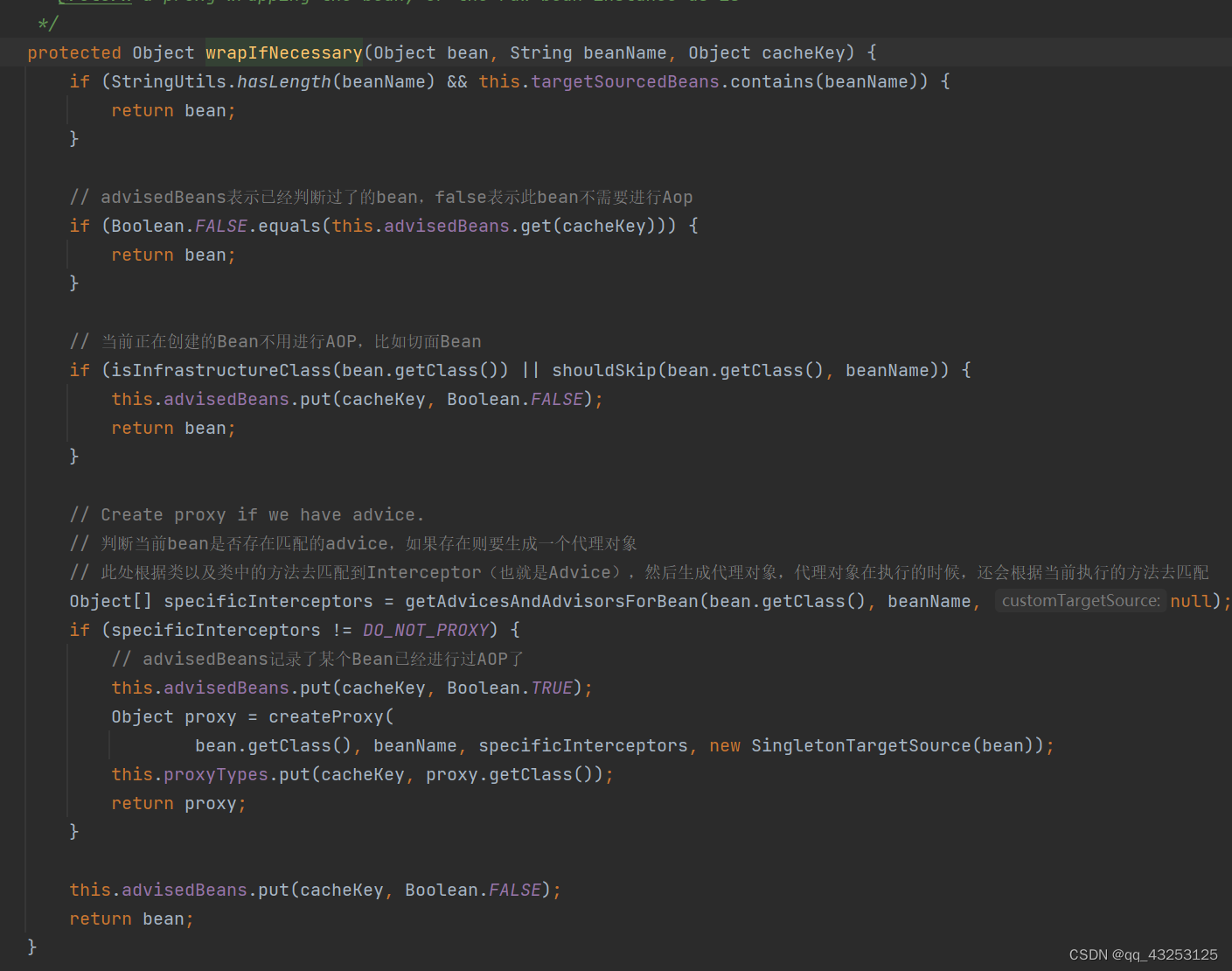
会先去找到所有的Advisor,然后根据其匹配规则去进行逐个匹配
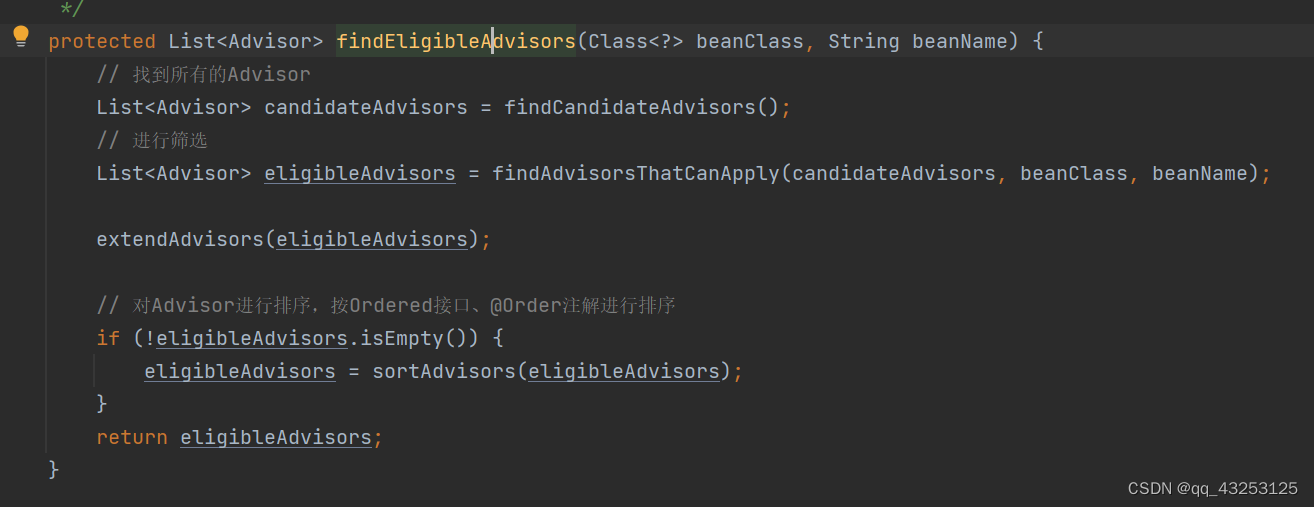
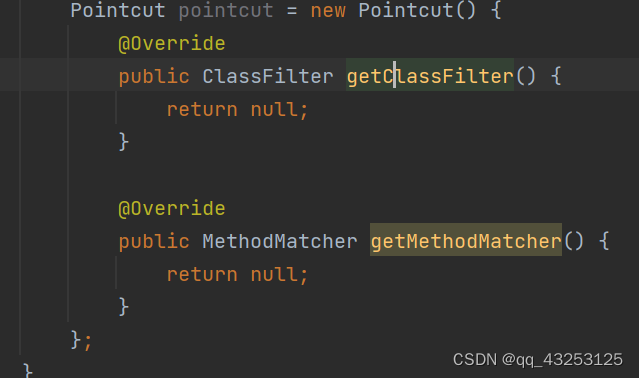
整个PointCut中需要重写两种方法,getClassFilter和getMethodMatcher,只有这两种方法都返回true的情况下,才会去生成代理对象,筛选完成之后会形成一条链路
AbstractAdvisorAutoProxyCreator.findEligibleAdvisors
return advisors.toArray();
经过上述筛选之后如果返回的不是空值,那么会将其记录在advisedBeans中,并且会去调用底层的proxyFactory.getProxy(classLoader)生成代理对象


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









