







 该博客介绍了如何使用Python的tqdm库为图片下载添加进度条功能。通过结合requests库获取图片数据,利用tqdm显示下载进度,实现了从网页抓取图片并保存到本地的同时,展示清晰的下载进度。代码示例中详细展示了如何处理图片的下载过程,包括设置用户代理、解析HTML、获取图片信息以及使用tqdm进行进度跟踪。
该博客介绍了如何使用Python的tqdm库为图片下载添加进度条功能。通过结合requests库获取图片数据,利用tqdm显示下载进度,实现了从网页抓取图片并保存到本地的同时,展示清晰的下载进度。代码示例中详细展示了如何处理图片的下载过程,包括设置用户代理、解析HTML、获取图片信息以及使用tqdm进行进度跟踪。
接着上一个项目改进加一个进度条
代码
import requests
import os
from bs4 import BeautifulSoup
def fetch(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
res = requests.get(url=url,headers=headers)
res.encoding = res.apparent_encoding
html = res.text
soup = BeautifulSoup(html, 'lxml')
parse(soup)
def parse(soup):
all = soup.select('.g-gxlist-left >ul > li')
for div in all:
#图片名字
txt = div.find('a', class_='m-name').get_text()
#print(txt)
# 段落
text_p = div.find('p').get_text()
#print(text_p)
# 喜欢人数
love = div.find('em', class_='u-like').get_text()
#print(love)
# 发布时间
fbu = div.find('em', class_='u-date').get_text()
#print(fbu)
#图片
div_img = div.find('img').get('src')
#print(div_img)
img(div_img,txt)
def img(div_img,txt):
#打印图片地址
# print(div_img)
#图片二进制地址
img_data = requests.get(url=div_img).content
#print(img_a)
#图片名称
img_name = txt
#print(img_name)
# 新建一个文件夹保存所有图片
if not os.path.exists('./tu/'):
os.mkdir('./tu/')
# 图片存储路径
imgpath = './tu/' + img_name + '.jpg'
with open(imgpath,'wb') as f:
f.write(img_data)
print(img_name,'下载成功')
pass
def main():
url = 'https://www.qqtn.com/qm/weimeiqm_1.html'
fetch(url)
if __name__ == '__main__':
main()
图片
图片二进制

下载图片保存文件
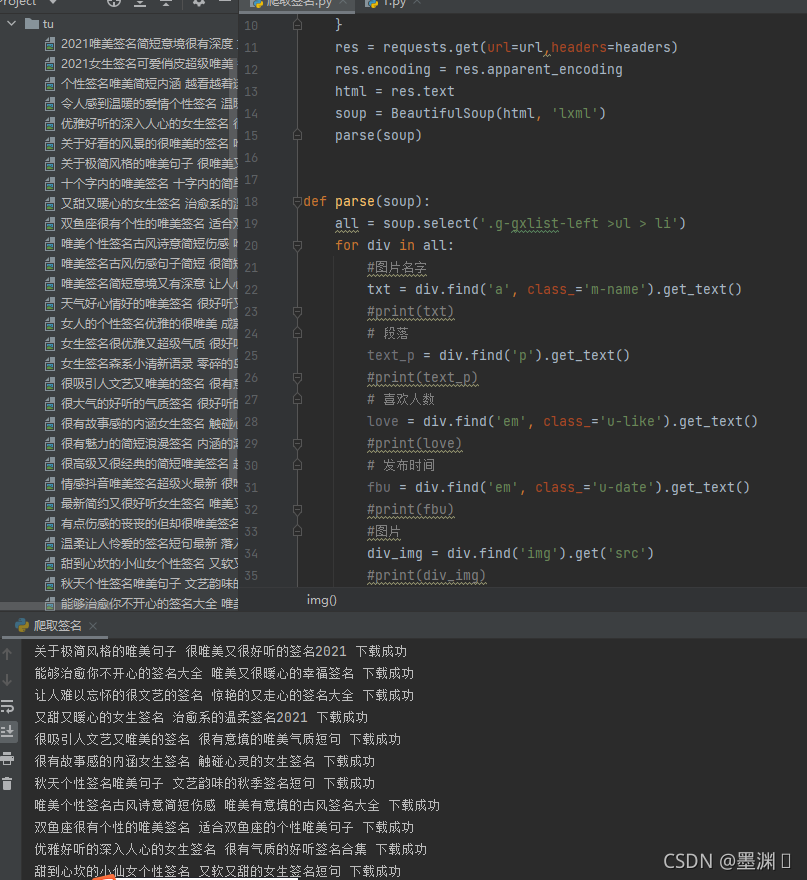

加了一个代码
import requests
import os
from bs4 import BeautifulSoup
from tqdm import tqdm
def fetch(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
res = requests.get(url=url,headers=headers)
res.encoding = res.apparent_encoding
html = res.text
soup = BeautifulSoup(html, 'lxml')
parse(soup)
def parse(soup):
all = soup.select('.g-gxlist-left >ul > li')
for div in all:
#图片名字
txt = div.find('a', class_='m-name').get_text()
#print(txt)
# 段落
text_p = div.find('p').get_text()
#print(text_p)
# 喜欢人数
love = div.find('em', class_='u-like').get_text()
#print(love)
# 发布时间
fbu = div.find('em', class_='u-date').get_text()
#print(fbu)
#图片
div_img = div.find('img').get('src')
#print(div_img)
img(div_img,txt)
def img(div_img,txt):
# 图片名称
img_name = txt
response = div_img
response = requests.get(response,stream=True)
print(response.headers)
data_size = int(response.headers['Content-Length']) / 1024 / 1024 # 字节/1024/1024=MB
# 新建一个文件夹保存所有图片
if not os.path.exists('./tu/'):
os.mkdir('./tu/')
# 图片存储路径
imgpath = './tu/' + img_name + '.jpg'
with open(imgpath,'wb') as f:
for data in tqdm(iterable=response.iter_content(1024 * 1024), total=data_size, desc=f'正在下载{img_name}', unit='MB'):
f.write(data)
pass
def main():
url = 'https://www.qqtn.com/qm/weimeiqm_1.html'
fetch(url)
if __name__ == '__main__':
main()
tqdm库比较简单易懂的使用方法
使用tqdm必须知道的几个常见参数:
iterable:可迭代的对象 默认None
total:进度条总长度大小(int or float)默认None
desc:进度条的前缀内容(str)默认None
unit:进度条的单位(str)默认 it ,实际表带为 it/s
1.response.get(stream=True) 这一点必须为True,其详细解释请查iter_content函数的说明,或者找其他资料理解
2.iter_content(chunk_size) chunk_size参数的理解见下图
#进度条
from tqdm import tqdm
#进度条代码部分
# 图片名称
img_name = txt
response = div_img
response = requests.get(response,stream=True)
print(response.headers)
data_size = int(response.headers['Content-Length']) / 1024 / 1024 # 字节/1024/1024=MB
# 新建一个文件夹保存所有图片
if not os.path.exists('./tu/'):
os.mkdir('./tu/')
# 图片存储路径
imgpath = './tu/' + img_name + '.jpg'
with open(imgpath,'wb') as f:
for data in tqdm(iterable=response.iter_content(1024 * 1024), total=data_size, desc=f'正在下载{img_name}', unit='MB'):
f.write(data)
pass
参考文章
https://blog.youkuaiyun.com/xyl192960/article/details/113695405
总结
项目 主要难点就是创建文件路径并保存 到指定路径
要了解os 模块的基本用法
# 新建一个文件夹保存所有图片
#如果没有则在当前路径创建一个文件
if not os.path.exists('./tu/'):
os.mkdir('./tu/')

















 1817
1817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









