







 本文介绍了一个Linux脚本,通过任务并行和CPU亲和性设置,实现快速生成大量文件并按核数分组,有效提升服务器资源利用率。展示了如何使用awk和shell脚本批量创建、压缩、移动和解压文件,以提高工作效率。
本文介绍了一个Linux脚本,通过任务并行和CPU亲和性设置,实现快速生成大量文件并按核数分组,有效提升服务器资源利用率。展示了如何使用awk和shell脚本批量创建、压缩、移动和解压文件,以提高工作效率。
涉及知识点:
操作系统 Linux(centos 7)
1.本程序最终希望实现的功能是:在我们平时工作中,有的时候我们需要自动产生大量的文件,比如说我们使用高斯交作业,有些输入文件可以通过程序来自动产生,那么我就希望能够有一个程序能够批量产生大量的文件,并且在产生了这些文件以后,能够自动分组,分组的目的就是希望能够充分利用当前服务器的核数来进行计算。
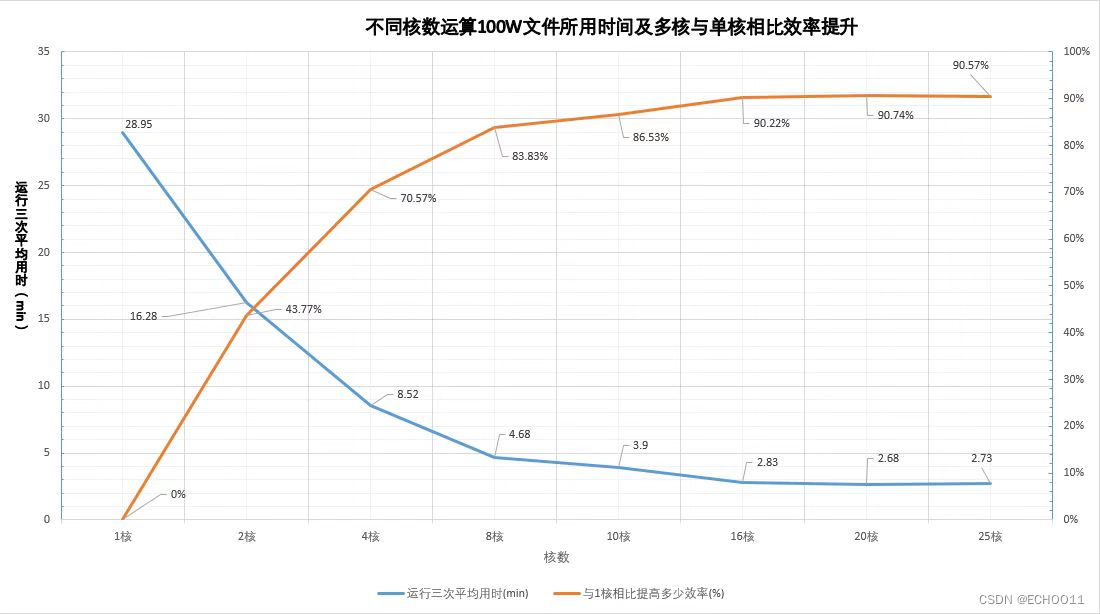
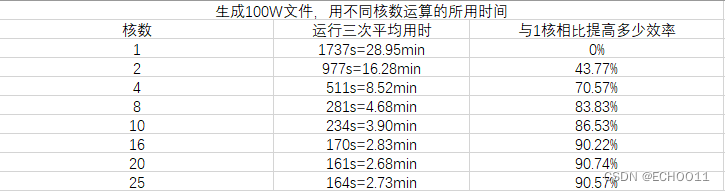
2.当前这个程序能够实现的是,比如我们的服务器有64核,我可以分配CPU核数来进行并行操作,想要产生100W个文件,我将其分成8组,也就是说一组使用8核来产生——解压——移动12.5W文件,最终通过时间对比,发现效率大大增加。
仅生成100W文件(不包含解压与移动),用不同数量核数的效率如下图所示:
2.代码展示
第一部分先展示最核心的代码段:
starttime=`date +'%Y-%m-%d %H:%M:%S'` #计算所用时间
for((i=1;i<=1;i++))
do
taskset -c $i sh ./generate_$i.sh& #指定核数计算
done
wait #等待结束后再进行下一步
for((i=1;i<=1;i++))
do
taskset -c $i sh ./tar_$i.sh&
done
wait
for((i=1;i<=1;i++))
do
taskset -c $i sh ./mv_$i.sh&
done
wait
for((i=1;i<=1;i++))
do
cd group_$i
tar -xzvf group_$i.tar.gz
cd ..
done
wait
gawk -f ./clear.awk
endtime=`date +'%Y-%m-%d %H:%M:%S'`
start_se 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









