







 博客围绕蚂蚁森林数据展开,介绍了datediff、regexp_replace等函数。包含两个问题:一是统计10月1日累计申领“p002 - 沙柳”排名前10的用户信息及与后一名的差距;二是查询2017年连续三天及以上每天减碳超100g的用户流水,给出了多种SQL解法。
博客围绕蚂蚁森林数据展开,介绍了datediff、regexp_replace等函数。包含两个问题:一是统计10月1日累计申领“p002 - 沙柳”排名前10的用户信息及与后一名的差距;二是查询2017年连续三天及以上每天减碳超100g的用户流水,给出了多种SQL解法。
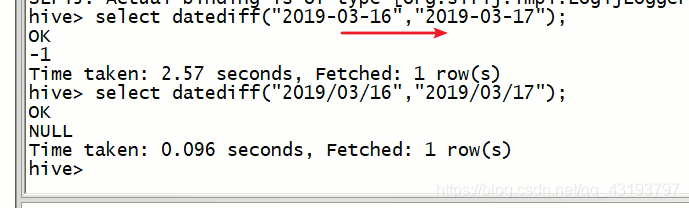
datediff函数
regexp_replace()

substring
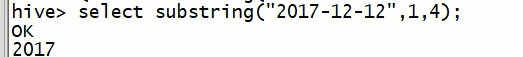
函数准备介绍:
dateddiff:求两个时间的差值
regexp_replace:替换符号
to_date:将字符串转换成时间
date_sub:求一个时间与数字之间的差值
round:四舍五入
floor:向下取整
ceil:向上取整
题目:
背景说明:
以下表记录了用户每天的蚂蚁森林低碳生活领取的记录流水。
table_name:user_low_carbon
user_id data_dt low_carbon
用户 日期 减少碳排放(g)
蚂蚁森林植物换购表,用于记录申领环保植物所需要减少的碳排放量
table_name: plant_carbon
plant_id plant_name low_carbon
植物编号 植物名 换购植物所需要的碳
----题目
1.蚂蚁森林植物申领统计
问题:假设2017年1月1日开始记录低碳数据(user_low_carbon),假设2017年10月1日之前满足申领条件的用户都申领了一颗p004-胡杨,
剩余的能量全部用来领取“p002-沙柳” 。
统计在10月1日累计申领“p002-沙柳” 排名前10的用户信息;以及他比后一名多领了几颗沙柳。
得到的统计结果如下表样式:
user_id plant_count less_count(比后一名多领了几颗沙柳)
u_101 1000 100
u_088 900 400
u_103 500 …
1.创建表
create table user_low_carbon(user_id String,data_dt String,low_carbon int) row format delimited fields terminated by '\t';
create table plant_carbon(plant_id string,plant_name String,low_carbon int) row format delimited fields terminated by '\t';
2.加载数据
load data local inpath "/opt/module/data/low_carbon.txt" into table user_low_carbon;
load data local inpath "/opt/module/data/plant_carbon.txt" into table plant_carbon;
3.设置本地模式
set hive.exec.mode.local.auto=true;
(1)统计在10月1日前每个用户减少碳排放量的总和(取前11名)
select user_id,sum(low_carbon) sum_carbon
from user_low_carbon
where datediff(regexp_replace(data_dt,"/","-"),"2017-10-1")<0
group by user_id
order by sum_carbon desc
limit 11;t1
(2)取出申领胡杨的条件
select low_carbon from plant_carbon where plant_id="p004";t2
(3)取出申领沙柳的条件
select low_carbon from plant_carbon where plant_id="p002";t3
(4)求出能申领沙柳的棵数
select user_id,floor((t1.sum_carbon-t2.low_carbon)/t3.low_carbon) treeCount from t1,t2,t3;t4
select
user_id,
floor((t1.sum_carbon-t2.low_carbon)/t3.low_carbon)
treeCount
from (select user_id,sum(low_carbon) sum_carbon
from user_low_carbon
where datediff(regexp_replace(data_dt,"/","-"),"2017-10-1")<0
group by user_id
order by sum_carbon desc
limit 11)t1,
(select low_carbon from plant_carbon where plant_id="p004")t2,
(select low_carbon from plant_carbon where plant_id="p002")t3;t4
u_007 66
u_013 63
u_008 53
u_005 46
u_010 45
u_014 44
u_011 39
u_009 37
u_006 32
u_002 23
u_004 22
(5)求出前一名比后一名多几棵
select user_id,treeCount,treeCount-(lead(treeCount,1) over(order by treeCount desc))
from t4
limit 10;
//先执行order by 再执行的lead
select user_id,treeCount,treeCount-(lead(treeCount,1) over(order by treeCount desc))
from (select
user_id,
floor((t1.sum_carbon-t2.low_carbon)/t3.low_carbon)
treeCount
from (select user_id,sum(low_carbon) sum_carbon
from user_low_carbon
where datediff(regexp_replace(data_dt,"/","-"),"2017-10-1")<0
group by user_id
order by sum_carbon desc
limit 11)t1,
(select low_carbon from plant_carbon where plant_id="p004")t2,
(select low_carbon from plant_carbon where plant_id="p002")t3)t4
limit 10;
u_007 66 3
u_013 63 10
u_008 53 7
u_005 46 1
u_010 45 1
u_014 44 5
u_011 39 2
u_009 37 5
u_006 32 9
u_002 23 1
2、蚂蚁森林低碳用户排名分析
问题:查询user_low_carbon表中每日流水记录,条件为:
用户在2017年,连续三天(或以上)的天数里,
每天减少碳排放(low_carbon)都超过100g的用户低碳流水。
需要查询返回满足以上条件的user_low_carbon表中的记录流水。
例如用户u_002符合条件的记录如下,因为2017/1/2~2017/1/5连续四天的碳排放量之和都大于等于100g:
seq(key) user_id data_dt low_carbon
xxxxx10 u_002 2017/1/2 150
xxxxx11 u_002 2017/1/2 70
xxxxx12 u_002 2017/1/3 30
xxxxx13 u_002 2017/1/3 80
xxxxx14 u_002 2017/1/4 150
xxxxx14 u_002 2017/1/5 101
备注:统计方法不限于sql、procedure、python,java等
(1)求出2017年超过100g的用户&时间
select user_id,data_dt,sum(low_carbon) sum_carbon
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100;t1
(2)计算每一行数据跟前后各两行的时间差
select user_id,data_dt,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc),"/","-")) lag2,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc),"/","-")) lag1,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc),"/","-")) lead1,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc),"/","-")) lead2
from (select user_id,data_dt,sum(low_carbon) sum_carbon
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1;t2
select user_id,data_dt,
lag(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc) lag2,
lag(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc) lag1,
lead(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc) lead1,
lead(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc) lead2
from (select user_id,data_dt,sum(low_carbon) sum_carbon
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1;t2
select user_id,data_dt,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag2,"/","-")) lag2Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag1,"/","-")) lag1Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead1,"/","-")) lead1Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead2,"/","-")) lead2Count
from (select user_id,data_dt,
lag(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc) lag2,
lag(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc) lag1,
lead(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc) lead1,
lead(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc) lead2
from (select user_id,data_dt,sum(low_carbon) sum_carbon
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1)t2;
(3)
select user_id,data_dt,
lag(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt) lag2,
lag(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt) lag1,
lead(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt) lead1,
lead(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt) lead2
from (select user_id,data_dt,sum(low_carbon) sum_carbon
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1;t2
select user_id,data_dt,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag2,"/","-")) lag2Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag1,"/","-")) lag1Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead1,"/","-")) lead1Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead2,"/","-")) lead2Count
from (select user_id,data_dt,
lag(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc) lag2,
lag(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc) lag1,
lead(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt desc) lead1,
lead(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt desc) lead2
from (select user_id,data_dt,sum(low_carbon) sum_carbon
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1)t2;t3
(3)求出连续3天及以上的数据
select user_id,data_dt
from t3
where (lag2=2 and lag1=1) or (lag1=1 and lead1=-1) or(lead1=-1 and lead2=-2);
select user_id,data_dt
from (select user_id,data_dt,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag2,"/","-")) lag2Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lag1,"/","-")) lag1Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead1,"/","-")) lead1Count,
datediff(regexp_replace(data_dt,"/","-"),regexp_replace(lead2,"/","-")) lead2Count
from (select user_id,data_dt,
lag(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt) lag2,
lag(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt) lag1,
lead(data_dt,1,"1970/01/01") over (partition by user_id order by data_dt) lead1,
lead(data_dt,2,"1970/01/01") over (partition by user_id order by data_dt) lead2
from (select user_id,data_dt,sum(low_carbon) sum_carbon
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1)t2)t3
where (lag2Count=2 and lag1Count=1) or (lag1Count=1 and lead1Count=-1) or(lead1Count=-1 and lead2Count=-2);
u_002 2017/1/2
u_002 2017/1/3
u_002 2017/1/4
u_002 2017/1/5
u_005 2017/1/2
u_005 2017/1/3
u_005 2017/1/4
u_008 2017/1/4
u_008 2017/1/5
u_008 2017/1/6
u_008 2017/1/7
u_009 2017/1/2
u_009 2017/1/3
u_009 2017/1/4
u_010 2017/1/4
u_010 2017/1/5
u_010 2017/1/6
u_010 2017/1/7
u_011 2017/1/1
u_011 2017/1/2
u_011 2017/1/3
u_013 2017/1/2
u_013 2017/1/3
u_013 2017/1/4
u_013 2017/1/5
u_014 2017/1/5
u_014 2017/1/6
u_014 2017/1/7
解法2:
4 1 3
5 2 3
6 3 3
7 4 3
9 5 4
10 6 4
12 7 5
13 8 5
14 9 5
(1)求出2017年超过100g的用户&时间
select user_id,data_dt,sum(low_carbon) sum_carbon,
rank() over(partition by user_id order by data_dt) rank
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100;t1
(2)求出时间与rank之间的差值
select user_id,data_dt,
date_sub(regexp_replace(data_dt,"/","-"),rank)
from t1;
select user_id,data_dt,
date_sub(regexp_replace(data_dt,"/","-"),rank) sub
from (select user_id,data_dt,sum(low_carbon) sum_carbon,
rank() over(partition by user_id order by data_dt) rank
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1;t2
(3)求出连续3天及以上的数据
select user_id,data_dt,
count(*) over(partition by user_id,sub) threeDays
from t2;t3
select user_id,data_dt
from t3
where threeDays>=3;
select user_id,data_dt
from (select user_id,data_dt,
count(*) over(partition by user_id,sub) threeDays
from (select user_id,data_dt,
date_sub(regexp_replace(data_dt,"/","-"),rank) sub
from (select user_id,data_dt,sum(low_carbon) sum_carbon,
rank() over(partition by user_id order by data_dt) rank
from user_low_carbon
where substring(data_dt,1,4)="2017"
group by user_id,data_dt
having sum_carbon>100)t1)t2)t3
where threeDays>=3
order by user_id,data_dt;
u_002 2017/1/2
u_002 2017/1/3
u_002 2017/1/4
u_002 2017/1/5
u_005 2017/1/3
u_005 2017/1/2
u_005 2017/1/4
u_008 2017/1/4
u_008 2017/1/6
u_008 2017/1/5
u_008 2017/1/7
u_009 2017/1/4
u_009 2017/1/2
u_009 2017/1/3
u_010 2017/1/4
u_010 2017/1/5
u_010 2017/1/6
u_010 2017/1/7
u_011 2017/1/2
u_011 2017/1/1
u_011 2017/1/3
u_013 2017/1/2
u_013 2017/1/3
u_013 2017/1/4
u_013 2017/1/5
u_014 2017/1/5
u_014 2017/1/6
u_014 2017/1/7
前置函数:
datediff:求两个时间的差值
regexp_replace:替换符号
to_date:将字符串转换成时间
date_sub:求一个时间与数字之间的差值
round:四舍五入
floor:向下取整
ceil:向上取整
substring
set hive.exec.mode.local.auto=true;
map(user_id_data_dt,(data_dt,sum_carbon))
grouping(user_id)
ArrayList list = new ArrayList();
reduce(user_id_data_dt,values Iterate(data_dt,sum_carbon)){
date1 = 0;
for(value:values){
if(date1=="0"){
list.add(data_dt);
date1 = data_dt;
}else{
if(data_dt-date1=?1){
list.add(data_dt);
date1 = data_dt;
}else{
if(list.size>=3){
context.write;
list.clear;
date1=data_dt;
}else{
list.clear;
date1=data_dt;
}
}
}
}
list.size>?3;
list.clear;
}

















 2938
2938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









